This article was published as a part of the Data Science Blogathon

In this blog, We are going to talk about some of the advanced and most used charts in Plotly while doing analysis. All you need to know is Plotly for visualization!
Table of content
- Description of Dataset
- Data Exploration
- Data Cleaning
- Data visualization
- The questions which we are going to answer with the charts
- Correlation between the features
- Most watched shows on the Netflix
- Distribution of Ratings
- Which has the highest rating Tv show or Movies
- Finding the best Month for releasing content
- Highest watched genres on Netflix
- Released movie over the years
Data for EDA of Netflix Data with Plotly
We are going to work on the Netflix movies and TV Show dataset you can find this dataset on Kaggle. If you like to see the whole notebook you can visit it here(https://www.kaggle.com/kashishrastogi/guide-for-plotly-for-beginners). Netflix is an application that keeps growing exponentially whole around the world and it is the most famous streaming platform.
Let’s create an EDA through this data with beautiful charts and visuals to gain some insights.
Importing library
import pandas as pd import plotly.express as px import plotly.graph_objects as go from plotly.subplots import make_subplots import plotly.figure_factory as ff
Let’s see the Netflix data
import pandas as pd
df = pd.read_csv('netflix_titles.csv')
print(df.head(3))Dataset
Description of Netflix Dataset
This dataset contains data collected from Netflix of different TV shows and movies from the year 2008 to 2021.
- type: Gives information about 2 different unique values one is TV Show and another is Movie
- title: Gives information about the title of Movie or TV Show
- director: Gives information about the director who directed the Movie or TV Show
- cast: Gives information about the cast who plays role in Movie or TV Show
- release_year: Gives information about the year when Movie or TV Show was released
- rating: Gives information about the Movie or TV Show are in which category (eg like the movies are only for students, or adults, etc)
- duration: Gives information about the duration of Movie or TV Show
- listed_in: Gives information about the genre of Movie or TV Show
- description: Gives information about the description of Movie or TV Show
Data Exploration
Exploring the data
df.info()
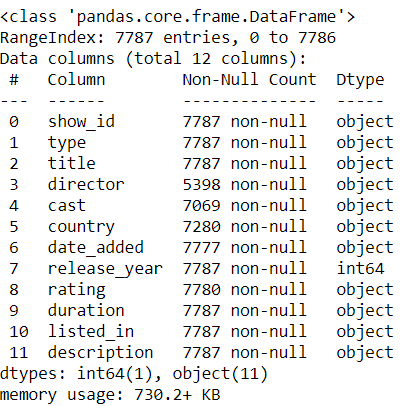
Finding if the dataset contains null values
df.isnull().sum()
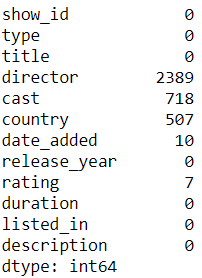
Finding how many unique values are there in the dataset
df.nunique()
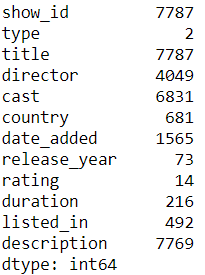
Data Cleaning
Dropping the cast and director features because we are not going to use those features right now.
df = df.dropna( how='any',subset=['cast', 'director'])
Replacing null values with ‘missing’
df['country'].fillna('Missing',inplace=True)
df['date_added'].fillna('Missing',inplace=True)
df['rating'].fillna('Missing',inplace=True)
df.isnull().sum().sum()
Converting into a proper date-time format and adding two more features year and month.
df["date_added"] = pd.to_datetime(df['date_added']) df['year_added'] = df['date_added'].dt.year df['month_added'] = df['date_added'].dt.month
Finding seasons from durations
df['season_count'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" in x['duration'] else "", axis = 1)
df['duration'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" not in x['duration'] else "", axis = 1)
Renaming the ‘listed_in’ feature to the genre for easy use.
df = df.rename(columns={"listed_in":"genre"})
df['genre'] = df['genre'].apply(lambda x: x.split(",")[0])
df.head()
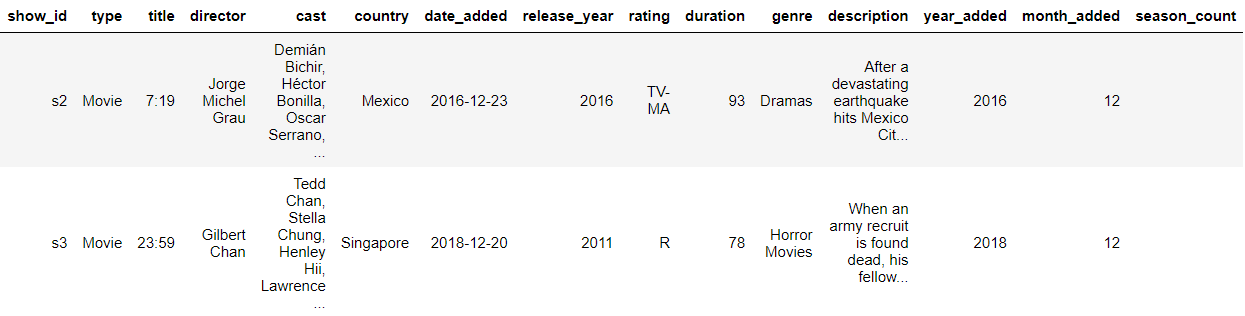
After data cleaning the dataset look like this
Let’s see the distribution of data
df.describe(include='O')
Now let’s start the fun and gain some insights from the data.
Data Visualization
Now if we look at the data, we have some questions ready like
- What is the ratio of Movie and TV Shows on Netflix
- Distribution of Rating in Netflix
- Which has the highest rating Tv Shows or Movies on Netflix
There are many more questions that we can answer we will see them in further blogs.
Chart 1
Viewing the correlation between the features.
# Heatmap
# Correlation between the feature show with the help of visualisation
corrs = df.corr()
fig_heatmap = ff.create_annotated_heatmap(
z=corrs.values,
x=list(corrs.columns),
y=list(corrs.index),
annotation_text=corrs.round(2).values,
showscale=True)
fig_heatmap.update_layout(title= 'Correlation of whole Data',
plot_bgcolor='#2d3035', paper_bgcolor='#2d3035',
title_font=dict(size=25, color='#a5a7ab', family="Muli, sans-serif"),
font=dict(color='#8a8d93'))
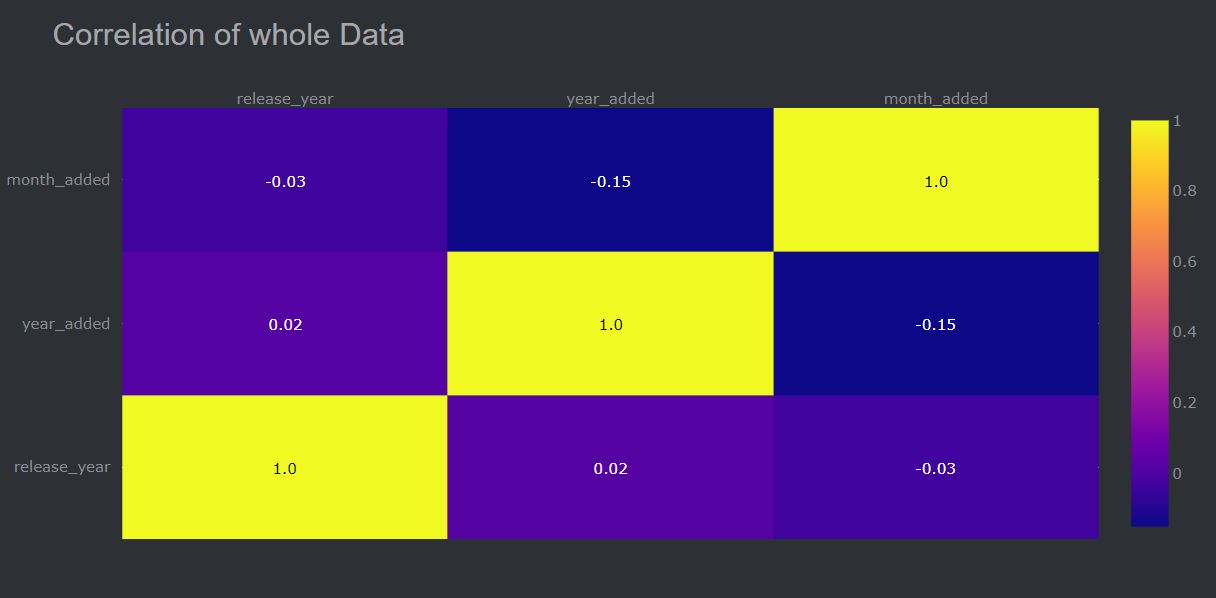
HeatMap in Plotly
Chart 2
Our first chart will tell us about the most-watched show on Netflix.
The reason for plotting the chart?
Which will tell us about what the audience prefers to watch. So Netflix can decide what type of content they should publish to make the audience happy.
fig_donut = px.pie(df, names='type', height=300, width=600, hole=0.7, title='Most watched on Netflix', color_discrete_sequence=['#b20710', '#221f1f']) fig_donut.update_traces(hovertemplate=None, textposition='outside', textinfo='percent+label', rotation=90) fig_donut.update_layout(margin=dict(t=60, b=30, l=0, r=0), showlegend=False, plot_bgcolor='#333', paper_bgcolor='#333', title_font=dict(size=25, color='#8a8d93', family="Lato, sans-serif"), font=dict(size=17, color='#8a8d93'), hoverlabel=dict(bgcolor="#444", font_size=13, font_family="Lato, sans-serif"))
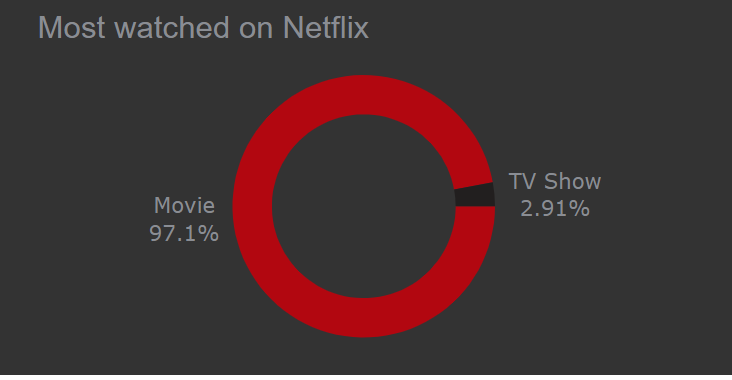
Donut chart in Plotly
Well, audience prefers Movies over TV Show as 97% audience like Movies.
Chart 3
Distribution of Rating and finding what audience prefer to watch.
The reason for plotting the chart?
To know which type of content is most watched by the audience so that Netflix can decide what type of content to be released next. It helps Netflix to understand the most and least favourite content watched by an audience.
df_rating = pd.DataFrame(df['rating'].value_counts()).reset_index().rename(columns={'index':'rating','rating':'count'})
fig_bar = px.bar(df_rating, y='rating', x='count', title='Distribution of Rating',
color_discrete_sequence=['#b20710'], text='count')
fig_bar.update_xaxes(showgrid=False)
fig_bar.update_yaxes(showgrid=False, categoryorder='total ascending', ticksuffix=' ', showline=False)
fig_bar.update_traces(hovertemplate=None, marker=dict(line=dict(width=0)))
fig_bar.update_layout(margin=dict(t=80, b=0, l=70, r=40),
hovermode="y unified",
xaxis_title=' ', yaxis_title=" ", height=400,
plot_bgcolor='#333', paper_bgcolor='#333',
title_font=dict(size=25, color='#8a8d93', family="Lato, sans-serif"),
font=dict(color='#8a8d93'),
legend=dict(orientation="h", yanchor="bottom", y=1, xanchor="center", x=0.5),
hoverlabel=dict(bgcolor="black", font_size=13, font_family="Lato, sans-serif"))
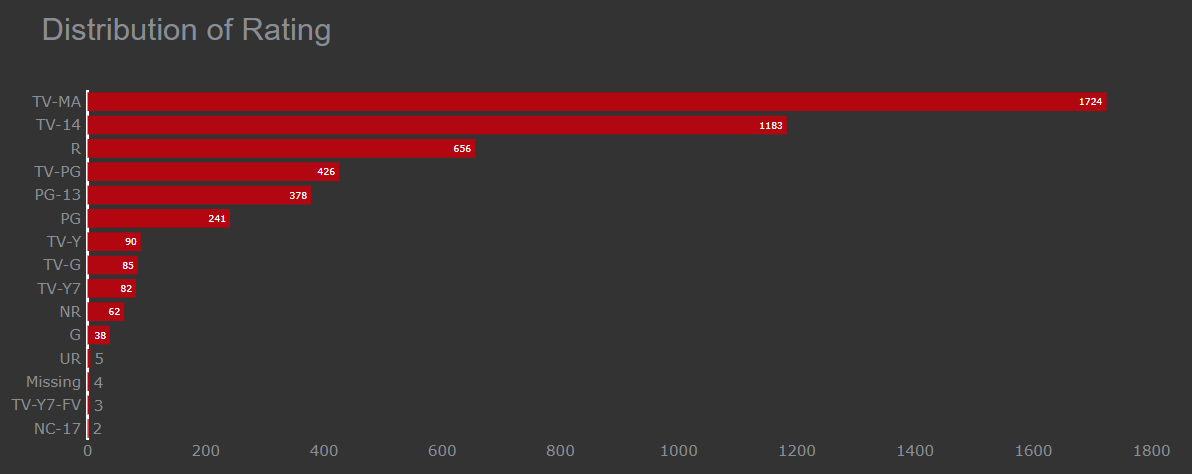
Bar chart in Plotly
Interpreting the chart
The audience prefers TV-MA and TV-14 shows more and the least preferred rating shows are Nc-17. Most of the content watched by the audience is for a mature audience. The TV-MA rating is a type of rating given by the TV parental guidelines to a television program.
The second largest type of rating watched by the audience is TV-14 which is inappropriate for children younger than age 14. The conclusion is drawn here is most of the audience is of mature age. For more tricks and tips to make the bar chart interesting give a look here.
Chart 4
We will see which has the highest rating TV Shows or Movies.
The reason for plotting the chart?
I have used a bidirectional bar chart here to show the comparison between the TV shows and Movies vs Ratings. Creating two different bar charts one for TV Show and another for Movie doesn’t make sense but combining a user can easily understand the difference.
# making a copy of df
dff = df.copy()
# making 2 df one for tv show and another for movie with rating
df_tv_show = dff[dff['type']=='TV Show'][['rating', 'type']].rename(columns={'type':'tv_show'})
df_movie = dff[dff['type']=='Movie'][['rating', 'type']].rename(columns={'type':'movie'})
df_tv_show = pd.DataFrame(df_tv_show.rating.value_counts()).reset_index().rename(columns={'index':'tv_show'})
df_tv_show['rating_final'] = df_tv_show['rating']
# making rating column value negative
df_tv_show['rating'] *= -1
df_movie = pd.DataFrame(df_movie.rating.value_counts()).reset_index().rename(columns={'index':'movie'})
Here for the bi-directional chart, we will make 2 different data frames one for Movies and another one for TV Shows having ratings in them.
We are making 2 subplots and they are sharing the y-axis.
fig = make_subplots(rows=1, cols=2, specs=[[{}, {}]], shared_yaxes=True, horizontal_spacing=0)
# bar plot for tv shows
fig.append_trace(go.Bar(x=df_tv_show.rating, y=df_tv_show.tv_show, orientation='h', showlegend=True,
text=df_tv_show.rating_final, name='TV Show', marker_color='#221f1f'), 1, 1)
# bar plot for movies
fig.append_trace(go.Bar(x=df_movie.rating, y=df_movie.movie, orientation='h', showlegend=True, text=df_movie.rating,
name='Movie', marker_color='#b20710'), 1, 2)
fig.update_xaxes(showgrid=False)
fig.update_yaxes(showgrid=False, categoryorder='total ascending', ticksuffix=' ', showline=False)
fig.update_traces(hovertemplate=None, marker=dict(line=dict(width=0)))
fig.update_layout(title='Which has the highest rating TV shows or Movies?',
margin=dict(t=80, b=0, l=70, r=40),
hovermode="y unified",
xaxis_title=' ', yaxis_title=" ",
plot_bgcolor='#333', paper_bgcolor='#333',
title_font=dict(size=25, color='#8a8d93', family="Lato, sans-serif"),
font=dict(color='#8a8d93'),
legend=dict(orientation="h", yanchor="bottom", y=1, xanchor="center", x=0.5),
hoverlabel=dict(bgcolor="black", font_size=13, font_family="Lato, sans-serif"))
fig.add_annotation(dict(x=0.81, y=0.6, ax=0, ay=0,
xref = "paper", yref = "paper",
text= "97% people prefer Movies over TV Shows on Netflix.
Large number of people watch TV-MA rating
Movies which are for mature audience."
))
fig.add_annotation(dict(x=0.2, y=0.2, ax=0, ay=0,
xref = "paper", yref = "paper",
text= "3% people prefer TV Shows on Netflix.
There is no inappropriate content for
ages 17 and under in TV Shows."
))
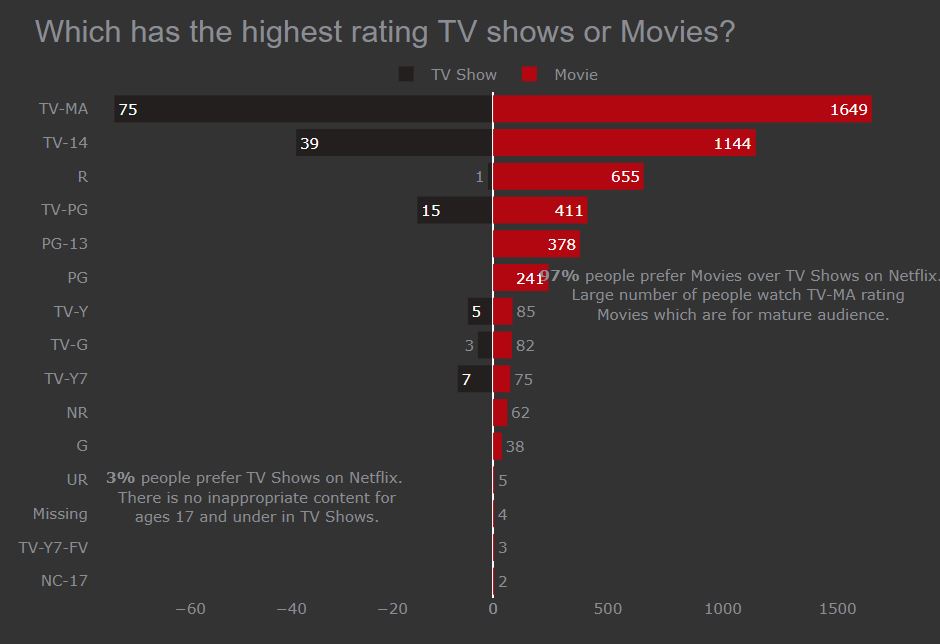
Bi-directional Bar Chart in Plotly
As you see here I have added text into the chart which gives the additional information to the user while reading the charts. It is a good practice to give additional information in the chart if needed.
Chart 5
If a producer wants to release a show which month is the best month to release it.
The reason for plotting the chart
The best month to release content so the producer can gain much revenue. Most of the holidays came in December month so to releases a Movie or TV show in December is the best way to earn a lot of profit as the whole family will be spending time with each other and watching shows.
df_month = pd.DataFrame(df.month_added.value_counts()).reset_index().rename(columns={'index':'month','month_added':'count'})
# converting month number to month name
df_month['month_final'] = df_month['month'].replace({1:'Jan', 2:'Feb', 3:'Mar', 4:'Apr', 5:'May', 6:'June', 7:'July', 8:'Aug', 9:'Sep', 10:'Oct', 11:'Nov', 12:'Dec'})
df_month[:2]
Replacing month number to month name for a better visualization
fig_month = px.funnel(df_month, x='count', y='month_final', title='Best month for releasing Content',
height=350, width=600, color_discrete_sequence=['#b20710'])
fig_month.update_xaxes(showgrid=False, ticksuffix=' ', showline=True)
fig_month.update_traces(hovertemplate=None, marker=dict(line=dict(width=0)))
fig_month.update_layout(margin=dict(t=60, b=20, l=70, r=40),
xaxis_title=' ', yaxis_title=" ",
plot_bgcolor='#333', paper_bgcolor='#333',
title_font=dict(size=25, color='#8a8d93', family="Lato, sans-serif"),
font=dict(color='#8a8d93'),
hoverlabel=dict(bgcolor="black", font_size=13, font_family="Lato, sans-serif"))
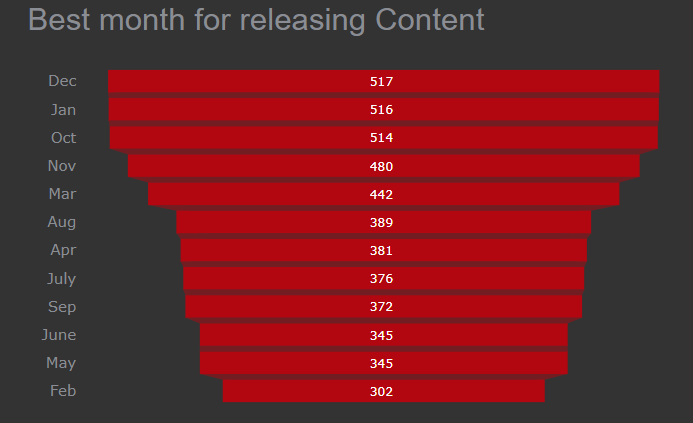
Funnel Chart in Plotly
Ending and starting of the year December and January is the best month to release content. The best 4 months to release content are October, November, December, and January.
Chart 6
Finding the highest watched genres on Netflix
The reason for plotting the chart
To know more about the distribution of genres and see which type of content do audience prefers to watch. So Netflix can decide and take movies or tv shows of the highest watched genres which will benefit Netflix in a long run.
df_genre = pd.DataFrame(df.genre.value_counts()).reset_index().rename(columns={'index':'genre', 'genre':'count'})
fig_tree = px.treemap(df_genre, path=[px.Constant("Distribution of Geners"), 'count','genre'])
fig_tree.update_layout(title='Highest watched Geners on Netflix',
margin=dict(t=50, b=0, l=70, r=40),
plot_bgcolor='#333', paper_bgcolor='#333',
title_font=dict(size=25, color='#fff', family="Lato, sans-serif"),
font=dict(color='#8a8d93'),
hoverlabel=dict(bgcolor="#444", font_size=13, font_family="Lato, sans-serif"))

TreeMap in Plotly
Drama is the highest preferred show by the audience then comes the comedy show and action show, the least preferred show is of LGBTQ movies.
Chart 7
Let’s see how many movies were released over the years with a waterfall chart.
The reason for plotting the chart
We want to see what is the distribution of releases of a movie or tv show in terms of years. Do the releases increase or decrease with the years. We can easily compare if the release of movies is decreasing or increasing by year by year with the help of a waterfall chart.
Code
We will create a data frame that only consists of Movie shows
d2 = df[df["type"] == "Movie"] d2[:2]
We will create a data frame where we will show how many movies were released each year.
col ='year_added'
vc2 = d2[col].value_counts().reset_index().rename(columns = {col : "count", "index" : col})
vc2['percent'] = vc2['count'].apply(lambda x : 100*x/sum(vc2['count']))
vc2 = vc2.sort_values(col)
vc2[:3]
Now let’s make a waterfall chart for easy comparison of all the years
fig1 = go.Figure(go.Waterfall(
name = "Movie", orientation = "v",
x = vc2['year_added'].values,
textposition = "auto",
text = ["1", "2", "1", "13", "3", "6", "14", "48", "204", "743", "1121", "1366", "1228", "84"],
y = [1, 2, -1, 13, -3, 6, 14, 48, 204, 743, 1121, 1366, -1228, -84],
connector = {"line":{"color":"#b20710"}},
increasing = {"marker":{"color":"#b20710"}},
decreasing = {"marker":{"color":"orange"}},
))
fig1.show()
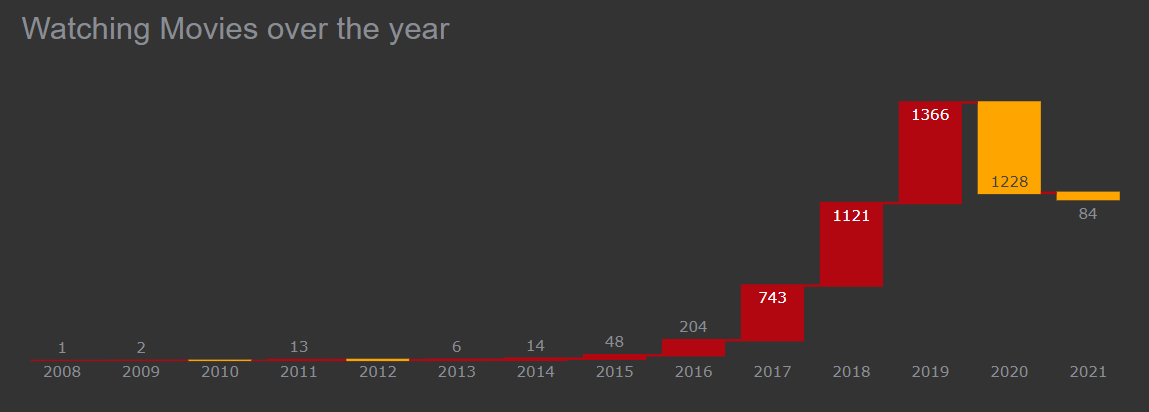
Waterfall chart in Plotly
The highest number of movies were released in 2019 and 2018 due to the covid releasing of movies were significantly dropped.
Note: Here yellow color shows the decrement and the red color shows the increment
Chart 8
What is the impact of Netflix TV Shows or Movies over the years by comparing both.
d1 = df[df["type"] == "TV Show"]
d2 = df[df["type"] == "Movie"]
col = "year_added"
vc1 = d1[col].value_counts().reset_index().rename(columns = {col : "count", "index" : col})
vc1['percent'] = vc1['count'].apply(lambda x : 100*x/sum(vc1['count']))
vc1 = vc1.sort_values(col)
vc2 = d2[col].value_counts().reset_index().rename(columns = {col : "count", "index" : col})
vc2['percent'] = vc2['count'].apply(lambda x : 100*x/sum(vc2['count']))
vc2 = vc2.sort_values(col)
trace1 = go.Scatter(x=vc1[col], y=vc1["count"], name="TV Shows", marker=dict(color="orange"), )
trace2 = go.Scatter(x=vc2[col], y=vc2["count"], name="Movies", marker=dict(color="#b20710"))
data = [trace1, trace2]
fig_line = go.Figure(data)
fig_line.update_traces(hovertemplate=None)
fig_line.update_xaxes(showgrid=False)
fig_line.update_yaxes(showgrid=False)
large_title_format = 'Tv Show and Movies impact over the Year'
small_title_format = "Due to Covid updatation of content is slowed."
fig_line.update_layout(title=large_title_format + " " + small_title_format,
height=400, margin=dict(t=130, b=0, l=70, r=40),
hovermode="x unified", xaxis_title=' ',
yaxis_title=" ", plot_bgcolor='#333', paper_bgcolor='#333',
title_font=dict(size=25, color='#8a8d93',
family="Lato, sans-serif"),
font=dict(color='#8a8d93'),
legend=dict(orientation="h",
yanchor="bottom",
y=1,
xanchor="center",
x=0.5))
fig_line.add_annotation(dict
(x=0.8,
y=0.3,
ax=0,
ay=0,
xref = "paper",
yref = "paper",
text= "Highest number of Tv Shows were released in 2019 followed by 2017." ))
fig_line.add_annotation(dict
(x=0.9,
y=1,
ax=0,
ay=0,
xref = "paper",
yref = "paper",
text= "Highest number of Movies were relased in 2019 followed by 2020" ))
fig_line.show()
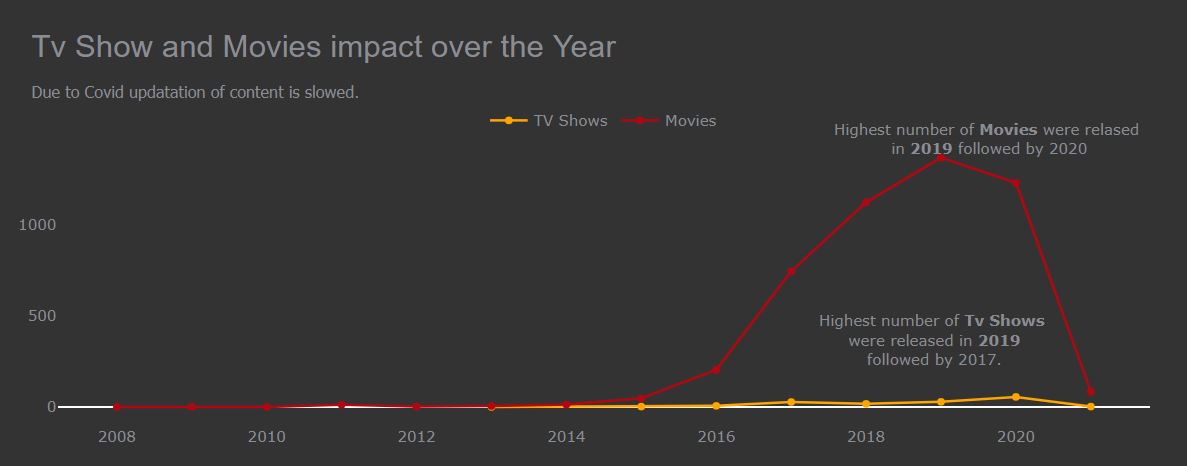
Line Chart in Plotly
After the year 2019 covid came that badly affects Netflix for producing content. Movies have exponential growth from the start but due to covid, it is going downwards.
Conclusion
We explore the Netflix dataset and saw how to clean the data and then jump into how to visualize the data. We saw some basic and advanced level charts of Plotly like Heatmap, Donut chart, Bar chart, Funnel chart, Bi-directional Bar chart, Treemap, Waterfall chart, Line chart.
If you have any questions feel free to write in comments.
References
- Image 1- https://unsplash.com/photos/yubCnXAA3H8
- Dataset – https://www.kaggle.com/shivamb/netflix-shows
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
A student who is learning and sharing with a storyteller to make your life easy.




Dear Kashish, Thank you very much for sharing your knowledge. Helped me a lot! Best regards, Mike Pi Moscow, RU