This article was published as a part of the Data Science Blogathon.
Introduction
ETL pipelines look different today than they used to decades ago. Much of the architecture and data surrounding ETL have changed. Many companies still believe in creating their own framework for data pipelining and not utilize the existing tools even though that requires a wide range of skills. The traditional way of performing ETL is by doing it manually with code and it is not a single person job. Traditional ETL might be considered a bottleneck, but that doesn’t mean it’s invaluable. Let’s understand the current scenario here!
ETL in a nutshell
As data enthusiasts, we all must have frequently come across this term while dealing with data on an everyday basis right? Typically Data engineers handle all this work this but even data analysts, data scientists, and business intelligence engineers are required to have hands-on experience. Not all companies will provide clean data to directly perform analytics and reporting, some will expect to collaboratively work with Data engineers in creating scalable and efficient end-end data pipelines.
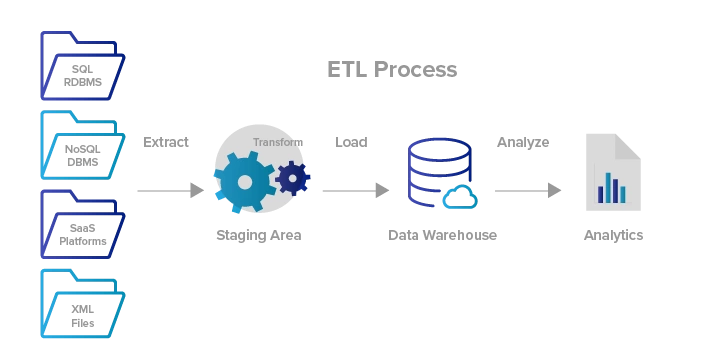
Why is it so hyped?
Large companies especially hire ETL developers, ETL specialists who only manage data integration and design the data storage for them. The 3 step process looks simple but behind the scenes, there are hundreds of extremely cumbersome things to handle the extraction of data from various sources especially the data itself has become much bigger and messier.
It is the most challenging part of the entire data pipeline and cannot afford to mishandle crucial information before going to the next step. After transforming the clean and validated data into the desired form, it is safe to store it in the data warehouse for analytics and data modeling purposes. Various risks are involved during the initial stages of the production phase and that’s why they are paid more. Knowing the data in and out is the basic foundation for any data-related role and it is mandatory to have a basic idea of using the data smartly with the available resources.
How to perform ETL?
There are different workflows in data pipelining and can be done in 2 ways:
- ETL tools
- Talend
- Informatica
- Alteryx
- SSIS
- Amazon Redshift
- Xplenty
- QlikSense
- Coding
- Python
- R
- SQL
- Java
- Apache Pig
No-code ETL vs Manual ETL
A no-code ETL platform requires little to no coding. Tools provide user-friendly GUIs with various functionalities to create a data map. Once the data map is complete, the teams just have to run the process and the server will do its job. The process is easy to understand by the clients and easy to maintain. It is scalable and saves a lot of time and money for the companies handling real-time datasets. The logic is reusable for any data source and there are custom data manipulation features. There are subscriptions and pay-per-use ETL services to run on a cloud server with millions of data. So, the company needs to choose the tool wisely according to the use-case and requirements of the customer.
Even non-technical employers need to be trained to schedule the workflows, jobs, and tasks in order to get acquainted with the tool. There are companies encouraging no-code practices to develop various products.
“According to the IT research firm Forrester, the low-code development platform market will reach a value of $21.2 billion by 2022, growing at an annual rate of 40 percent. What’s more, 45 percent of developers have already used a low-code platform or expect to do so in the near future.” [1]
Coding your own extraction pipeline is tempting but difficult at the same time. Writing python scripts to extract, transform and load data even in a cloud environment is adapted by many companies. Any type of customizations to the code can be made if something is not available in the existing ETL solution. Coding our own ETL can be a huge benefit in terms of performance optimization and flexibility. If there is an expert data engineer on board who knows ETL processes, it is possible to fine-tune the ETL process to run as smoothly as possible. Tedious coding is useful in self-services where one can independently perform data preprocessing.
Issues? Changing the code and maintaining scripts can be a huge problem if the ETL doesn’t function well for complex schemas. Automating the manual ETL requires other tools like Selenium, Windows Task scheduler to automatically run scripts on a daily/weekly basis to store data in excel or a database. Hence they are built for a specific set of users and data operations.
Do you love playing with dirty data and clean it?
If you like experimenting with data manually by checking all the errors and normalizing the data then implementing various python and R packages is a good way to go. Even writing SQL queries can be interesting and challenging to extract information from messy data. This can help to deeply understand the logic behind data wrangling from scratch rather than starting off with a tool first.
Bottom Line: It all depends on various parameters like the size of data, memory, and budget to choose the optimal solution for business problems. Also, the choice of ETL approach varies with technical and non-technical expertise level in a company.
Final thoughts
This is a quite debatable topic and both have their advantages and disadvantages. ETL tools are not dead but also not preferable by all. One might end up now with an unnecessary overhead of using an ETL tool where it’s not needed, that also hosts business logic that is not transferable outside of the ETL tool. But the skills developed while creating ETL pipelines using Python or SQL will always stick together in coming years.
Current ETL tools might go out of fashion and adapting to new ones can be difficult for some people. So even tools can become a hassle for a company if not utilized properly. Irrespective of no-code or manual ETL, the whole process itself is complicated but also very interesting to learn.
Which one is your favorite? Do let me know in the comments!
Thank you for reading this article.
Reference
[1] How low-code platforms are transforming software development
About the author:
Saloni Somaiya works as a Data Scientist at a healthcare startup in the United States. She pursued Masters in Information Systems from Northeastern University, Boston. She enjoys reading articles and exploring new technologies. She is willing to contribute more to Data Analytics and Science field.
LinkedIn: https://www.linkedin.com/in/saloni-somaiya/
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Thank you for the post. Coming from a non-data science background but as someone who has heard the terms but never worked in Data Warehousing this was a good comparison and overview of No-code ETL vs Manual ETL.
or you can combine both approaches, ETL and coding in a tool like Omniscope Evo