-
How to check Stationarity of Data in Python
Stationarity of data is based on following 3 criteria - Have constant mean, Have constant variance, Auto covariance doesn't depend on time
Nishtha 19 Oct, 2024
-
A Beginners Guide to Multi-Processing in Python
Explore multi-processing concepts in data science, learn Python implementations using Process and Pool classes, and compare its performance.
Karthik 16 Jan, 2025
-
Introduction Support Vector Machines (SVM) with Python Implementation
SVM (Support Vector Machine)is a supervised learning algorithm that can be used for both classification and regressions, soft margin svm.
Dishaa 09 Dec, 2024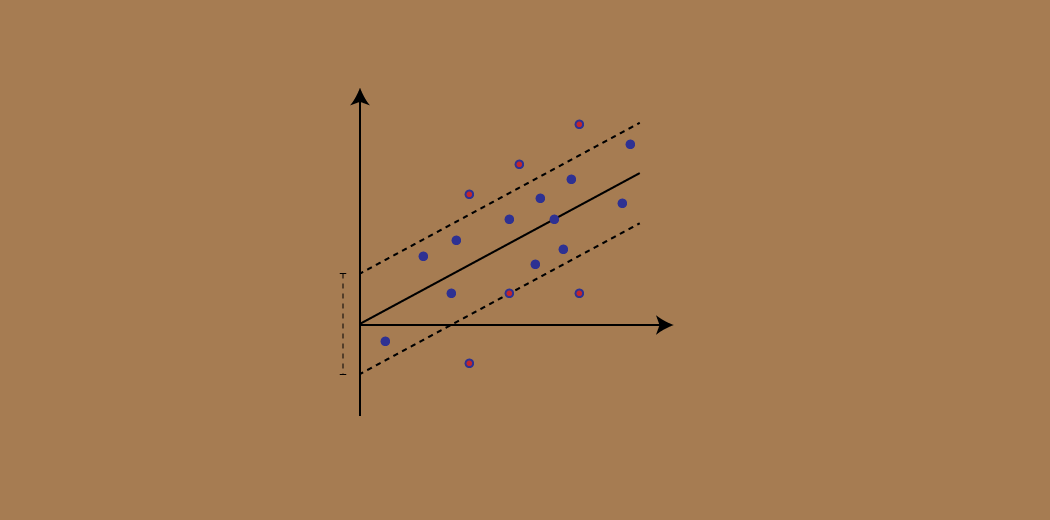
-
Logistic Regression in Python: Beginner’s Step by Step Guide
Logistic Regression in python is one of the most popular Machine Learning Algorithms, used in the case of predicting various categorical.
Pranshu Sharma 06 Feb, 2024
-
Google Earth Engine Machine Learning for Land Cover Classification (with Code)
In this article, we will discuss specifically Machine Learning for land cover classification based on satellite images in Python
rendyk 24 Apr, 2021
-
A broader understanding of ML and types of regression
Machine learning is taking over the world. Lets understand Machine Learning and Types regression algorithms for data science.
YAMINI 24 Apr, 2021
-
Top 8 Hidden Python Packages For Machine Learning in 2021
We are going to cover some hidden gems of python packages that are unknown to the data science world and does our work smoothly
Akshay 24 Apr, 2021
-
Q – Learning Algorithm with Step by Step Implementation using Python
Explore Q-learning, its algorithm, and applications in robotics. Learn how to train models and find shortest paths in a warehouse scenario.
Lakshmi 14 Jan, 2025
-
You Cannot Miss These 8 Python Libraries
In this detailed article, we introduce you to 8 Python libraries which you should try at least once in your development journey.
Kaustubh Gupta 23 Apr, 2021
-
Time Series Analysis: Forecast COVID-19 Vaccination Rate
A simple time series analysis to forecast the COVID-19 Vaccination Rate in various countries is described in this article in Python
Dayana 23 Apr, 2021
