This article was published as a part of the Data Science Blogathon
Introduction
In this article we will be discussing Binary Image Classification with Tensorflow with a twist, instead of working on an ad-hoc approach, we will be using TensorFlow Datasets (Data Pipelines available to us by the TensorFlow community).
The article is divided into 2 parts as a complete guide, although each of them separately is enough to understand the concepts mentioned in them and puts no such pressure to follow both, It’s just advisable.
Part 1 Discusses the Data Pipeline and Training the model
Part 2 will pick after Part 1 and use Regularization and Data augmentation on Streaming data to overcome overfitting.
The Table of Contents:
- Data Pipeline
- Extract, Transform, Load (ETL)
- Tensorflow Datasets
- Horses-or-Human dataset
Data Pipeline:
This terms simply means that a series of steps/ actions are included between the raw input data and the output data we get out of it. If I mean to apply some preprocessing on my data before using it, I can use data pipelines to get me the data after applying the preprocessing.
Making it more clear, think of it as an automation mechanism to avoid manual fixed preprocessing steps and letting data transform automatically with steps defined in a data pipeline.
Extract, Transform, Load (ETL):
This combination of words on a high level informs us about the functioning of a data pipeline, although there are more complexities involved. As a first-timer, it is more than enough to understand. Extract means retrieving the data from the data source.
Transform means applying all the steps involved in the specific data pipeline and convert that data into what you require.
Load means taking the output data from transform and use that data into a model to start training or inference.
TensorFlow Datasets:
This is the name given to Data pipelines available to us by the TensorFlow community, which we can use in our TensorFlow code and make more robust and production-ready Machine Learning or Deep Learning models.
Horses-or-Human dataset:
This is the dataset we will be using in our code. The dataset is created by Laurence Moroney containing 300×300 images distributed between two classes (Horses and Humans). Know more about the data here: Dataset
Let’s Code:
You need to first install tensorflow datasets as a package, using this command:
!pip install tensorflow-datasets
Then import all the required Libraries:
import numpy as np import matplotlib.pyplot as plt import tensorflow as tf import tensorflow_datasets as tfds
Extract Phase:
As mentioned above, here we will extract the data from tensorflow datasets server and view some information about it.
train_dataset,info = tfds.load('horses_or_humans', with_info = True, split='train', as_supervised=True)
val_dataset,val_info = tfds.load("horses_or_humans", with_info=True, split='test', as_supervised=True)
‘info‘ and ‘val_info‘ both give the same information in the below-mentioned format because they both point towards the same dataset, the number of images in train_dataset and val_dataset is mentioned under the “split” key as train and test respectively.
NOTE: train_dataset and val_dataset are tf.data.Dataset objects
print(info)
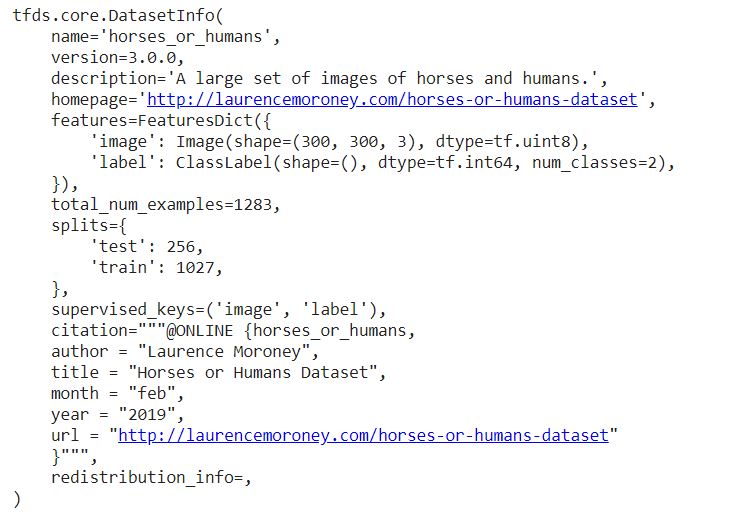
It was that simple to get the already splitted data into train and test set through TensorFlow Datasets.
Transform Phase
Now let us move on to the Transform Phase, where we apply preprocessing steps to change the resultant data. In our case, we are only applying shuffling and batching of the train data and only batching of the validation data.
train_dataset = train_dataset.shuffle(100).batch(32) val_dataset = val_dataset.batch(32)
Here I have applied functional chaining to get the final output in a single line (batch() after shuffle()). shuffle(BUFFER_SIZE) is a function to shuffle the data where BUFFER_SIZE signifies the space available for shuffling, more space leads to better shuffling and vice versa.
batch(batch_size) is a function to subset the data into batches of size -> batch_size; for a single training step and improve the learning through mini-batch gradient descent.
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=8, kernel_size = 3, input_shape = [300,300,3], activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(filters = 16, kernel_size = 3, activation = 'relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(filters = 32, kernel_size = 3, activation = 'relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=64, activation = 'relu'),
tf.keras.layers.Dense(units = 2, activation='softmax')
])
model.summary()
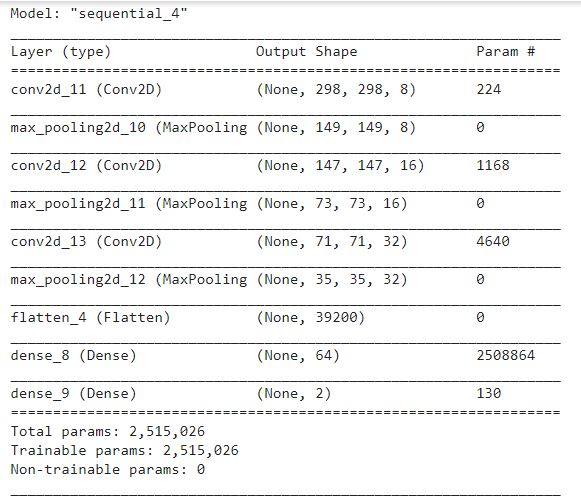
The Last step that comes after transformation is using the data AKA Load Phase. Let us load the data like in any other model and simple train our Convolutional Neural Network on the train_dataset.
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy']) history = model.fit(train_dataset, epochs=8, validation_data=val_dataset)
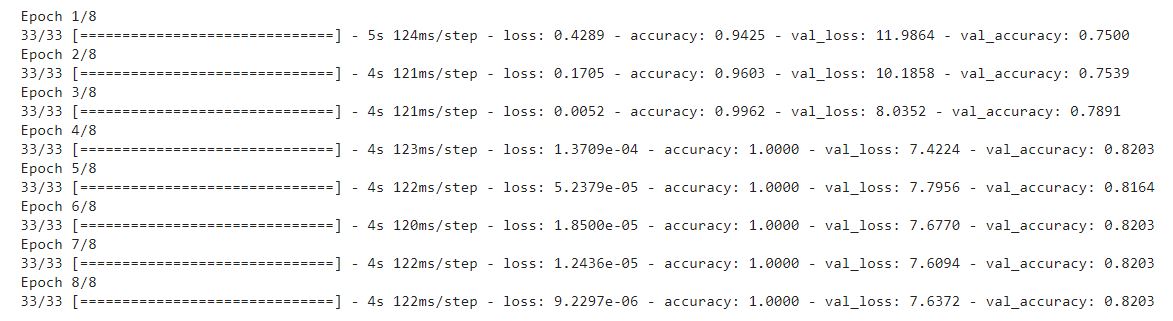
Here I have kept the training small because it is already giving 100% train accuracy and 82% validation accuracy, which gives the traces of overfitting. Let us check and clarify our thought.
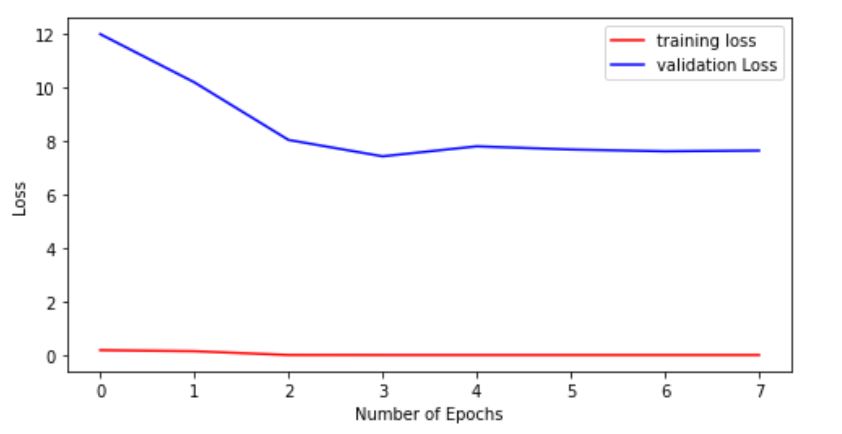
## LOSS PLOT
plt.figure(figsize=(8, 4))
plt.plot(range(8), history.history['loss'], 'r', label='training loss')
plt.plot(range(8), history.history['val_loss'], 'b', label='validation Loss')
plt.legend()
plt.xlabel('Number of Epochs')
plt.ylabel("Loss")
plt.show()
## Accuracy PLOT
plt.figure(figsize=(8, 4))
plt.plot(range(8), history.history['accuracy'], 'r', label='training accuracy')
plt.plot(range(8), history.history['val_accuracy'], 'b', label='validation accuracy')
plt.legend()
plt.xlabel('Number of Epochs')
plt.ylabel("Accuracy")
plt.show()
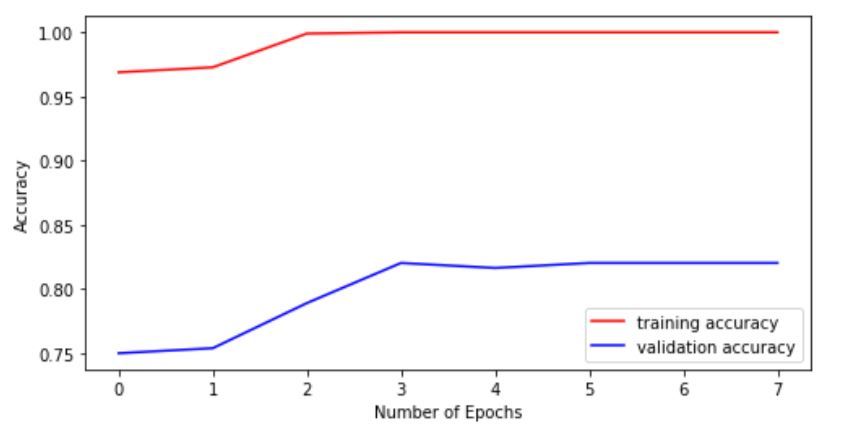
The GAP between the lines of training and validation data in both the plots signifies overfitting, hence clarifying our doubt.
Overfitting can be removed through various methods. (Some of the famous ones are Data Augmentation, using Regularization etc).
Let’s apply some of the methods in part 2 and get a better model.
Gargeya Sharma
B.Tech Computer Science 3rd year, Specialized in Data Science and Deep Learning
Data Scientist Intern at Upswing Cognitive Hospitality Solutions
For more info check out my Github Home Page
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.





