This article was published as a part of the Data Science Blogathon
End-to-End Computer Vision Application deals with all the required steps from downloading and preparing the data until the computer vision model is deployed. In this blog post, we’ll go through all the necessary steps required to train an image classification model using a technique called transfer learning which includes downloading data, performing data augmentation, creating data loaders, training the model, and exporting it for further uses.
We are using the fastai library to implement the model pipeline. Fastai is a deep learning library built as a high-level API on top of the PyTorch framework. To get some insight into the library and its usage, please refer to this blog.
Let’s get started.
This tutorial assumes previous knowledge of python3 and some basic knowledge of fastai library. Jupyter Notebook with a GPU is recommended. The same can be accessed through Google Colaboratory which provides a cloud-based jupyter notebook environment with a free Nvidia GPU.
Install required libraries
Let’s install the fastai library in colab. It might prompt to restart the runtime after installing. Also, install the nbdev package which is used to get documentation of fastai functions.
!pip install fastai --upgrade !pip install nbdev
Ok now let’s download the data
Download the Data
First, let’s import the vision module from the fastai library. Then let’s download the PETS dataset using fastai’s untar_data method. It returns a PoxiPath object.
# import fastai library from fastai.vision.all import * # Download the data path = untar_data(URLs.PETS)/'images'
The PETS dataset consists of images of Dogs and Cats, and we are training a model to distinguish between cats and dogs. This task is a part of the dogs vs cats Kaggle competition hosted in 2014.
Let’s view some images using the PIL library,
# get all the image paths
img_paths = path.ls()
# Define a utility function to display the image given its path
def show_image(img_path):
print(img_path)
img = PILImage.create(img_path)
img.show()
# Display some random images
show_image(img_paths[100])
show_image(img_paths[1242])
Observe the output and figure out how the classes are differentiated…
Load the Data – DataBlock API
DataBlock is a container that is used to quickly build datasets and dataloaders, given the data path. Let’s take a look at how it is done,
# Define the function to return the label
def is_cat(x):
if x.name[0].isupper():
return 'Cat'
else:
return 'Dog'
# Define the datablock called pets
pets = DataBlock(
blocks = (ImageBlock, CategoryBlock),
get_items = get_image_files,
get_y = is_cat,
splitter = RandomSplitter(valid_pct=0.25, seed=42),
item_tfms = Resize(420),
batch_tfms = aug_transforms(size = 244, mult=1.5)
)
# Define the dataloaders from the pets datablock
dls = pets.dataloaders(path)
# Show some images from the dataloader
dls.show_batch(max_n = 6)
In the above code, we have defined a datablock object called pets. Various arguments in the datablock are as follows:
- blocks: Specify the type of data to be input from the data. In this case, ImageBlock refers to input type as Image and CategoryBlock refers to different categories. When CategoryBlock is specified, fastai automatically does label encoding.
- get_items: Takes a function as a parameter. Here get_image_files specifies to load all the images from the given path/directory.
- get_y: Takes a function as a parameter. It specifies how to get the label of the sample. In this example, we have defined a function that returns whether the image is a cat or dog. According to our dataset, all the cat image names start with a capital letter, and dog images start with small letters.
- splitter: Takes a function as a parameter. Here RandomSplitter is a function that takes validation percent and random seed as inputs and returns splits indices of training and validation datasets.
- item_tfms: This consists of transforms/augmentations that are applied on each item/sample. In this example, we are Resizing every image to 420 x 420.
- batch_tfms: This consists of transforms/augmentations that are applied on every batch. In this example, we are applying a special fastai data augmentation function aug_transforms, and setting the size to 224 and mult to 1.5. In this batch transform, all the images are resized to 224 and all the augmentations are applied on batch with values times 1.5.
We can create the dataloaders from the datablock object by specifying the path. Similarly, we can display some data samples by using the show_batch() method. We can check the classes vocabulary using dls.vocab
Now since our dataloader is ready, we can train the model.
Train the model
Here we are using fastai’s cnn_learner and resnet34 pre-trained model to perform transfer learning and fine-tuning on the PETS dataset. We can also define the metrics i.e. accuracy and error_rate.
Before we fit our model, we should find the ideal learning rate through which the optimization of the loss function will be efficient. Therefore we can use fastai’s lr_find() method to find optimal learning rate.
Learning Rate Finder
Choosing an optimal learning rate for training is a must since it results in good & quality training, i.e., convergence. This concept of learning rate finder we introduced by a researcher named Leslie Smith in 2015. It is implemented as follows,
# Define the model using cnn_learner learn = cnn_learner(dls, resnet34, metrics=[accuracy, error_rate]) # Find the optimal lr using lr_find() learn.lr_find()
The output is as follows,
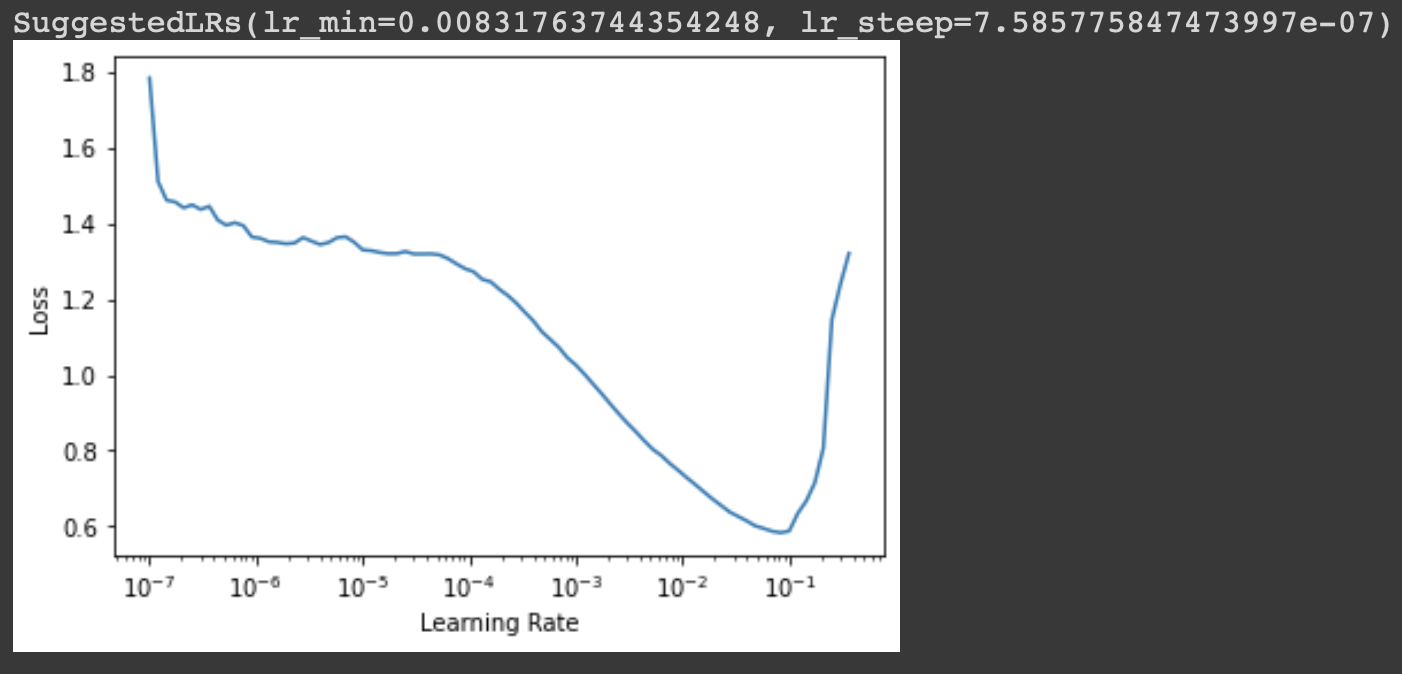
Basically, the idea is to start with a very low learning rate, calculate the loss for a mini-batch & then increase it by a certain percentage or double it. It is tracked for some range or learning rates until the loss becomes worse. So the ideal choice of learning rate would be,
- One order of magnitude less than where the minimum loss was achieved (or)
- The last point where the loss was clearly decreasing i.e slope is steepest
We can know more about any fastai function by using the doc() method. We can find documentation of lr_find using the following:
# Use the doc() method to find the documentation of any fastai method doc(learn.lr_find)
Fit the Model
Now as we know the ideal learning rate to use, we can finally fit our model using the fine_tune method.
# fine tune the model with learning rate and some freeze epochs learn.fine_tune(10, base_lr=3e-3, freeze_epochs=3)
Here we set the freeze_epochs as 3 i.e. number of epochs for which the fine-tuning of the model is done. Then we fit the model for 10 epochs. For more information about fine-tuning and transfer learning refer to this blog. The results of the training are as follows:
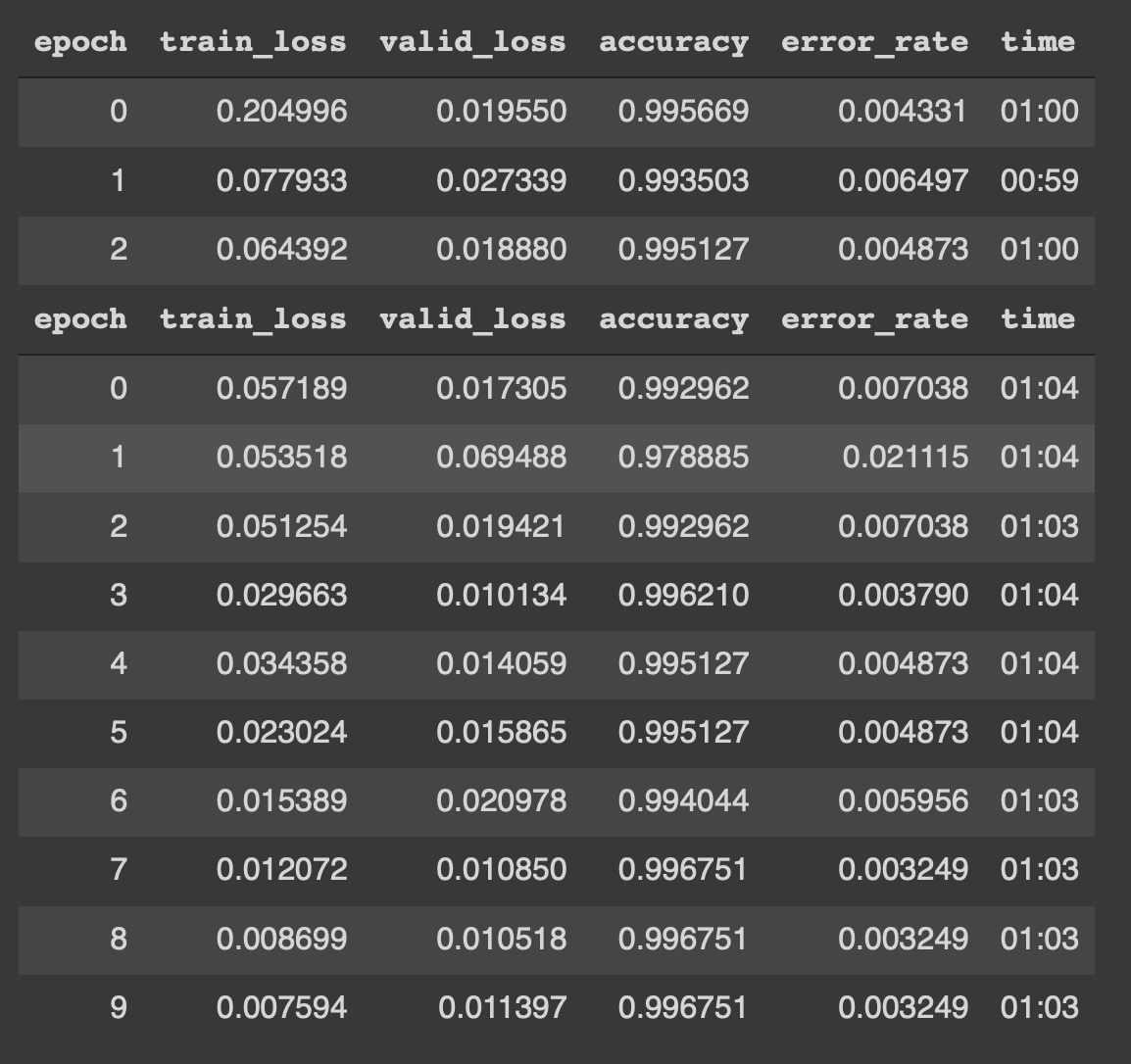
Woah !! It is consistently showing 99.675 % accuracy. This result for the competition is the state-of-the-art result which was impossible to achieve before deep learning.
Now finally let’s interpret the model and plot the confusion matrix.
# create the interepreation object from our model interep = ClassificationInterpretation.from_learner(learn) # Plot the confusion matrix interep.plot_confusion_matrix()
The confusion matrix:
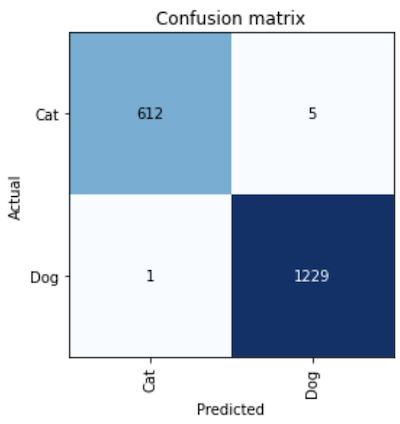
We can see that the model is pretty accurate, only 6 images out of 1847 in the validation set got misclassified.
Export the model
Now we can export our model in form of a pickle file and load later or use it during deployment.
# Export our trained model in form of pickle file learn.export(fname='pets_classifier.pkl')
We can load the model again from the pickle file and perform inference,
# load the model from pickle file
load_inf = load_learner('pets_classifier.pkl')
# Perform some predictions from random images
img1 = img_paths[1034]
show_image(img1)
load_inf.predict(img)
img1 = img_paths[2312]
show_image(img1)
load_inf.predict(img)
Therefore we can use this model in a deployment environment to perform predictions.
You can use the above template for any dataset and perform image classification. Refer to fastai documentation for more information.
Thank You & Happy Deep Learning !!
References:
1. Practical Deep Learning for Coders by Jeremy Howard and Sylvain Gugger
About Me
I’m Narasimha Karthik, Deep Learning Practioner.
Experience in working with PyTorch, Fastai, Tensorflow and Keras frameworks. You can contact me through LinkedIn and Twitter for any projects or discussions. Link of this blog in Github.
Thank you
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Hi,
I am Narasimha Karthik J, a Data Scientist at Boeing Research in Bengaluru. I have experience in fine-tuning language model models (LLMs) for various domain-specific applications and deploying them. Additionally, I am experienced in LLM training, fine-tuning, RAG, and working with the latest frameworks and technologies.
Thanks and Regards,
Narasimha Karthik J


