Suppose, you have a dataset of faculty salaries of a university and you are interested in the relationship of salaries with years of experience. How would you address the problem? Multilevel linear regression with years as the dependent variable and salary as the response variable. It’s simple, isn’t it? But what if I tell you that the individual salaries of faculties vary with respective departments. A teacher from Computer Sc might be getting more pay than a sociology teacher. So, we can see that there is an effect of the department on faculty salaries. The statisticians call it the group effect or random effect of groups. Here, the faculties are nested or clustered within the group departments. And if we go a level further and group departments within universities and compare salaries of faculties from different universities the result might be different.
Thus, the data under a group are correlated but an ordinary linear regression assumes the data to be independent. So, we need models that reflect these correlations between observations. If we carry on with the regular regression model we might not get good inference from the data.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Multilevel Modelling?
Multilevel modeling (also known as hierarchical linear modeling or mixed-effects modeling) analyzes data with a hierarchical or nested structure. This technique accounts for data points grouped or clustered within multiple levels, such as individuals within schools, patients within hospitals, or repeated measures within subjects.
It allows for the modeling of variation at different levels of the hierarchy, capturing both within-group and between-group variability. Multilevel modeling proves particularly useful when standard linear regression assumptions do not hold because of correlated data points or when the goal is to understand how group-level factors influence individual-level outcomes.
Advantages of Multilevel Modelling
We can very well use regular regression models in grouped data like the example we gave above by introducing dummy variables. But the multilevel approach has several advantages
Better inferences: A multilevel regression provides better inference from grouped data. A regular regression model does not consider the grouping of data which subsequently leads to underestimation of coefficients and overstatement of coefficient significance.
Fewer parameters: With a regular regression model we need dummy variables to account for groups but with a multilevel regression we will need fewer parameters for the same.
Group effects: Often we are specifically interested in group effects such as the role of schools in determining test outcomes of students. This can not be attained by regular regressions so we use multilevel models.
When do we use Multilevel Modelling?
When individual data is collected from a random sample of clusters (schools, areas, hospitals) at one point in time then observations within these clusters are more likely to be similar. For example, students from different schools might perform differently in a common test while the performances of students from the same school might have some similarities. Here, the schools are clusters and test scores of students are observations nested within schools. If we are fitting a regular regression to model the relationship between test scores and some predictor variable x then we will be discounting the effects of school-level variables let’s say qualifications of teachers. With a simple regression model, there is no way we can estimate how much variation is caused at the students level and how much at the school level.
Need for Multilevel Modelling
Some schools might have better study environments than some others or the faculties of one school are better than others. Introducing random variables for intercepts or coefficients then estimating their variance will fetch us a better idea regarding group effects, this is where multilevel modelling comes into the picture.

image belongs to the author
Multilevel models are also useful in longitudinal studies where researchers take repeated measurements of the same individual over time. In such cases, measurements cluster within each individual. For example, researchers randomly selected a group of boys and recorded their height each year for five years. We can use multilevel models to model the relationship between the person and their height.
What are levels:
In the examples above the students, measurements, schools, groups of boys are levels of a multilevel structure. Generally, variables sampled from a larger population qualify for leveling. Schools represent samples from a larger population of schools, while students at a school form a random sample from a wider population of students. The most fundamental observations fall under level one, with subsequent groups designated as levels 2, 3, and so on. For example,
3 level : Areas, Districts, Provinces
2 level : Schools, Hospitals, individuals
1 level : Students, Faculties, measurements
Types of Multilevel Model
In a simple regression model, we have an intercept term, a predictor variable multiplied by a slope and a residual term. We assume that each observation is independent of others. It looks something like this
yi = β0 + β1xi + ei
Here, the only term that is variable is the residual term ei while the intercept and the slope are fixed. This is mostly sufficient for data where the basic assumption that each observation is independent of others holds. But in the case of nested data, it generalizes for all the groups. We have a single average line for all the groups.
In multilevel models, we will allow the intercept and co-efficient to vary. Not only we will find the regression parameters describing the overall relationships of predictor and response variables but we also go above and beyond to estimate variances of the coefficients allowed to vary across groups at higher levels. Here, we will discuss two multilevel models
- Random Intercept Model
- Random Coefficient Model
Random Intercept Model
In a random intercept model, the intercept term is allowed to vary across the clusters. As the name suggests we will introduce a random variable for the intercept term. The equation looks something like this
yij = β0j + β1xij + eij ….. eq-1
where β0j = β0 + uj ….. eq-2
Here, i = individual observations j = individual clusters
combining both the equations we get,
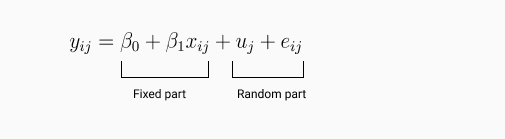
where uj ~ N(0,sigmau2) and eij ~ N(0,sigmae2)
Now, let’s understand how this works. In the random intercept model, we introduced a random variable uj to account for the variance caused by clusters. uj is the random variable responsible for unique intercepts for each group. In simple regression, we have a single line that best fits the data but in a random intercept model, we have different regression lines for different groups along with a common regression line. As the equation suggests we will still calculate the coefficients. We are specifically interested in the calculation of the variance of the random intercept term i.e. sigma2u.
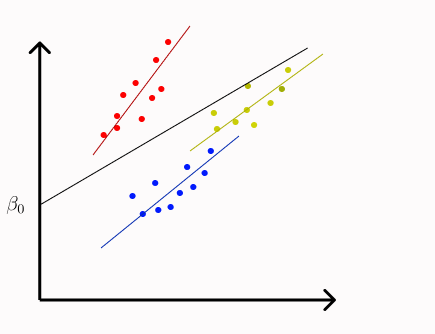
In a simple regression model, we have beta0 as intercept. For the random intercept model, beta0 is still the intercept term for the average regression line but for each group the intercept is beta0 + uj. See below diagram the average intercept is beta0 while for the red group it is bata0+u1. uj is the difference between the intercept beta0 and individual groups.
.png)
image belongs to the author
Random Coefficient Model
Just as we allowed intercepts to randomly vary in a random intercept model, in a random coefficient model we allow the slope to vary across the groups. In some cases, random intercept alone may not be sufficient to explain variability across the groups. So, a random slope model is needed where each group will have different slopes along with different intercepts.
Importance of Varying Slopes
Why is it so? It was observed that explanatory variables might have different effects for each group. Let’s suppose in our school example if admission cutoff is an explanatory variable for test outcome then there might be schools where student scores were highly affected by the previous admission cutoff scores, there might also be some schools, the effect might be less. Here, we can not use the same slope for every group instead each group will have its slope.
The image belongs to the author
Substituting equations we will get
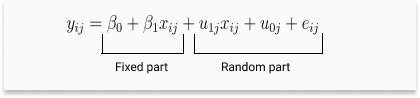
We introduced two random variables u1j and u0j. one for the intercept and the other for the slope. If you haven’t noticed already this uij term is responsible for variation in slopes. And it is the difference between the average slope of the regression line and the slope of the individual groups.
Note that we introduced only two random variables beta0 and beta1 but in reality, we will have to calculate six parameters. beta0 and beta1 as usual, are fixed parts responsible for the overall regression line while for the random part we will be estimating sigma2u0 and sigma2u1 the variances of u0j and u1j and sigmau01– covariance of the slopes and intercepts. It is observed that the slopes and intercepts are linked. When the covariance between these two are positive the regression lines will appear diverging, while negative covariance suggests the lines to be converging and zero covariance would suggest no fixed pattern.
Hypothesis Testing Likelihood Ratio Testing
Hypothesis testing is always an integral part of the interpretation of any model. It is indeed important to know if any parameter is significant or not. The type of statistical test will vary depending on the parameter under observation. We can use regular z-tests and t-tests for our fixed effect parameters. But the test for random effects will require likelihood ratio testing.
Likelihood Ratio Testing:
Interpreting likelihood ratio testing is relatively easier. Let’s suppose we are dealing with a random intercept model. So, to perform an LRT we will fit the model with and without random intercept and calculate the log-likelihood of each model. The formula for likelihood ratio testing is given as
where the numerator is the log-likelihood of equations with fewer parameters (no random intercept parameter) and the denominator is the lo2 Random Coefficient Modelg-likelihood of equations with greater parameters (with random intercept parameter).
The null hypothesis is that model with fewer parameters is best while the alternate is in favour of a random intercept model or model with more parameters. Or we can also put it differently as the null is sigma2u = 0 which means we can ignore the extra parameter. Now with the test statistic in hand, we will compare it to the chi2 distribution where the degree of freedom is the number of extra parameters (params(b) – params(a)). In a random intercept case, this is 1. then divide the corresponding p-value with 2 as sigma2u >= 0. If the p-value is less than alpha we accept alternate and reject the null and if it is above the significance level we will not reject the null hypothesis.
Frequently Asked Questions
Q1. What is a multilevel modeling approach?
A. A multilevel modeling approach is a statistical method that considers data with nested or hierarchical structures, where observations are grouped within different levels. It accounts for within-group and between-group variations, providing insights into how individual-level factors interact with group-level influences. This approach is valuable for analyzing complex data relationships and is used to uncover patterns, relationships, and trends that might be missed by traditional methods.
Q2. What are the different types of multilevel modeling?
A. There are several types of multilevel modeling approaches:
1. Random Intercept Model: It assumes varying intercepts for different groups, capturing the baseline variation between groups.
2. Random Slope Model: This model allows varying slopes for predictors across groups, accounting for how group characteristics affect relationships.
3. Cross-Level Interaction Model: It examines how relationships between variables change across different levels of the hierarchy.
4. Three-Level and Higher-Level Models: Extending beyond two levels, these models account for additional nested structures, such as students within classrooms within schools.
5. Multilevel Structural Equation Modeling: Integrates multilevel analysis with structural equation modeling to study complex relationships among variables.
6. Multilevel Latent Growth Curve Model: Analyzes growth trajectories over time while accounting for both within-person and between-person variability.
These approaches offer flexibility in addressing various research questions within hierarchical data.
Conclusion
In this article, we discussed various facets of multilevel modelling. Multilevel modelling is often used in research-related datasets where a regular regression is not sufficient at explaining variances across groups. There are no hard and fast rules to implement these models every time sometimes a regular regression model might be sufficient to achieve the required result.
Thank you for reading my article on multiple modelling. Hope you liked it. Share your views in the comments below.
Check out our blog for more articles.
Resources: bristol.ac.uk , Coursera
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Meet your author Sunil kumar Dash, a developer and a writer. Has diverse interests in tech, pop culture, wellness, philosophy and Anime. Exploring underrated music is his hobby. And loves to doom scroll Twitter when bored.







Hi Sunil, Thanks for the overview of how does MLM works!! Need your help on following, 1. In LRT section, H0 is considered as sigma2 u >= 0. For LRT, based on content in section, we expect fewer parameter model, does this corresponds to sigma2 u <= 0. How do I get to relation between null hypothesis in LRT and expected sigma2 u. 2. And, I am not able to get in on the requirement of dividing p-value by 2 (in the same LRT section). Please help.