This article was published as a part of the Data Science Blogathon.
Introduction
YARN stands for Yet Another Resource Negotiator, a large-scale distributed data operating system used for Big Data Analytics. Initially, it was described as “Redesigned Resource Manager” as it separates the processing engine and the management function of MapReduce. Apart from resource management, Yarn also performs various jobs, including job Scheduling, workload management, management of high availability features of Hadoop, implementation of security controls, and maintaining a multi-tenant environment. Furthermore, to make the system more efficient, YARN allows various data processing engines like graph processing, interactive processing, stream processing, and batch processing to run and process data stored in HDFS (Hadoop Distributed File System).
Why YARN?
Hadoop version 1.0, also known as MRV1(MapReduce Version 1), is a proficient data computational tool that performs processing and resource management functions. MRV1 has a single master named job tracker, which performs job scheduling, resource allocation, and job monitoring. It assigns maps and reduces tasks known as task trackers on several subordinate processes. Job trackers get the periodic progress report from the task trackers. Due to a single job, this design resulted in a scalability bottleneck. As a result, Hadoop 1. x had more limitations like delays in batch processing, inefficient utilization of computational resources, scalability issues, etc.
Moreover, it limits only MapReduce for processing big datasets. In 2012, Yahoo and Hortonworks introduced YARN in Hadoop version 2.0 to overcome all these shortcomings. The intention behind YARN is to reduce the overhead of MapReduce by taking over the job of Resource Management and Job Scheduling. With YARN, Hadoop can now run non-MapReduce jobs within the Hadoop cluster. With MapReduce batch tasks, YARN can now run stream data processing and interactive querying.
Features of YARN
YARN is a popular tool due to the following features:
-
Highest Scalability: The architecture of the Resource manager of YARN architecture allows Hadoop to manage thousands of nodes and clusters according to the user requirements.
-
High-degree Compatibility: YARN supports the applications created via the map-reduce framework without disruptions; that’s why it shows compatibility with Hadoop 1.0.
-
Better Cluster Utilization: YARN supports efficient and dynamic utilization of cluster resources in Hadoop, enabling better cluster utilization.
-
Multi-tenancy: YARN is a versatile technology that allows multiple engine access and gives the benefit of multi-tenancy.
Architecture and components of Hadoop YARN
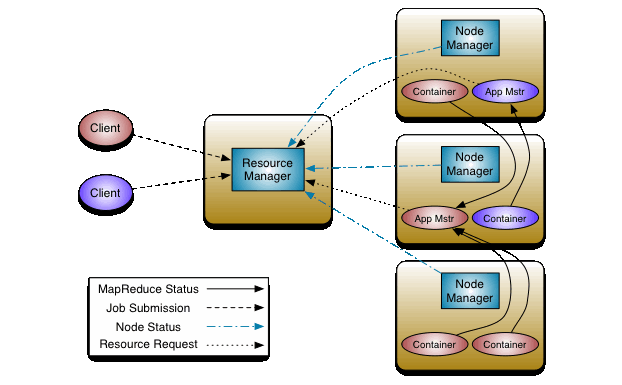
source:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/YARN.html
Resource Manager
Resource Manager, the master daemon of YARN, is responsible for the management of global assignments of resources like CPU and memory with several other applications. With the goal of maximum cluster utilization, it keeps all resources in use against various constraints such as capacity guarantees, fairness, and SLAs. On receiving the processing requests, it forwards parts of requests to the corresponding node manager where the actual processing takes place and allocates resources for the completion of the request accordingly. It is used as the arbitrator of the cluster resources for job scheduling and deciding the allocation of the available resources for competing jobs. It consists of two parts:
-
Scheduler: The scheduler performs scheduling based on the requirement of resources by the allocated applications. It distributes resources to the running applications depending upon the ordinary constraints of capacities, queues, etc. It does not monitor or track applications, hence known as a pure scheduler. Scheduler doesn’t ensure restarting failed tasks either due to hardware failure or application failures. To partition the cluster resources among various queues and applications, it has a pluggable policy plug-in. Examples of the plug-in are Capacity Scheduler and the Fair Scheduler, which are current MapReduce schedulers.
-
Application Manager: It is an interface that manages a list of applications that have been submitted, are currently running, or are finished. The Application Manager manages running Application Masters in the cluster by accepting job submissions and negotiating the Resource Manager’s first container. In addition, it performs multiple tasks like starting Application Master and monitoring and restarting the Application Master container on different nodes in case of failures.
Node Manager
It is the slave daemon of Yarn whose primary goal is to keep up-to-date with the Resource Manager. The responsibility of the node manager is to manage application containers assigned to it by the resource manager. It monitors containers’ resource usage(memory, CPU) and reports it to the Resource Manager. In addition, the yarn Node Manager registers with the Resource Manager to track the health of the node on which it is running and sends the heartbeats with the node’s health status. The node manager is also responsible for performing the log management and killing/destroying the container as directed by the Resource Manager.
Containers
The Containers are a collection of physical resources like RAM, CPU core, memory, and disks on a single node. The containers are monitored by Node Manager and scheduled by Resource Manager. The job of the container is to grant the right to an application to use a definite amount of resources(memory, disk, CPU, etc.) on a particular host. A Container Launch context which is Container Life Cycle (CLC), manages the YARN containers. CLC is a record that carries information like a map of environment variables, security tokens, dependencies stored in remotely accessible storage, the command required to create the process, and the payload for Node Manager services.
Application Master
An application is nothing but a single job submitted to a framework, and each application has a specific Application Master associated with it, which is a framework-specific entity. The chief responsibilities of the application master include negotiating resources with the resource manager, tracking the status, and monitoring the progress of a single application. It manages faults and works with the Node Manager to monitor and execute the component tasks. The application master sends a Container Launch Context(CLC) which includes everything an application needs to run and requests the container from the node manager. Once the application is started, it periodically sends heartbeats to the resource manager to check the health and update records based on its resource demands.
Application Workflow in Hadoop YARN
Perform the following steps to run an application through Hadoop YARN.

source: https://www.softwaretestinghelp.com/what-is-hadoop-yarn/
Step1:- Apply:
The client connects with the Resource Manager to submit the YARN application.
Step 2:- Container allocation:
To launch the Application Manager, the Resource Manager searches for a Node Manager and allocates the container.
Step 3:- Registration:
In this step, the Application Master registers itself with the resource master.
Step 4:- Negotiation:
From the Resource Manager, the application master negotiates the containers.
Step 5:- Notification:
Application Manager gives notification to the Node Manager for launching containers.
Step 6:- Execution:
Application code either gets executed in the container it is currently running, or it can request more containers from the resource manager.
Step 7:- Status Monitoring
To monitor the application’s status, the client contacts the Resource Manager or monitors the status of the Application Manager.
Step 8:- Disconnected
Once the processing is complete, the Application Manager gets disconnected from the Resource Manager.
YARN Command Line Interface
Mostly YARN commands are available for admins, but there are a few commands which developers can also run. These are:
-
Help
To get a list of all commands available in the YARN cluster.
Syntax:
-yarn -help
-
Version
To get the current version of YARN you are working with.
Syntax:
-yarn -version
-
Application id
To print the logs of a particular application id.
Syntax:
- yarn logs -applicationId
Conclusion
YARN is one of the most powerful concepts of Hadoop 2. x. This article has seen all the important concepts of the YARN with good examples of how they work with applications. Key learnings are:
-
We discuss the Yarn and its features.
-
Then, learned about the architecture and components of YARN.
-
Also, learned how an application workflows in Hadoop YARN.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






