This article was published as a part of the Data Science Blogathon.
Introduction
Have you ever encountered an “out-of-memory” error while working on a dataset? It’s pretty frustrating, right? Sometimes even after successfully loading and reading data, you run out of memory amid data processing operations! Ever wondered what may be the reason behind this and how to avoid this? Then, you are in the right place. One of the reasons may be that your data is sparse.
Understanding and processing the dataset is as significant as a modeling in any machine learning problem. Because, in reality, datasets are far from ideal. They may have missing values, they may be skewed or imbalanced, or they may be sparse. Handling these problems is an essential pre-processing step before proceeding to data visualization, modeling and results. In this guide, I’ll be focusing on the sparse features problem. You’ll learn what sparse datasets are, what challenges arise due to them, and various methods to tackle them. Grab a cup of coffee and gear up!
What are Sparse Datasets?
The features of a dataset can be sparse or dense. If the data stored for a particular feature contains mostly zeroes, it is referred to as a sparse feature. If the feature is populated mostly with non-zero values, it is dense. Most machine learning algorithms are developed for dense features. Hence, we may need some extra techniques to handle the sparse features. A dataset with a significant number of sparse features is denoted as a sparse dataset. It is also a common mistake to confuse sparse values with missing values.
How are Sparse Values Different From Missing Values?
When the dataset has no value in some columns/features, it is called null or missing values. It may occur due to multiple reasons like unavailability of data due to specific reasons or random irregularities in data collection. These values are unknown to us, and we often try to fill these null spaces with mean or imputed values.
Consider a categorical column “Known Language” in a dataset storing information about Tourists attending a fest. This column has many categories, like ‘English,’ ‘Tamil,’ “Urdu,” “Telugu,” and so on. Let’s say there are around 48 language options. While using Machine learning models on datasets, we often have to perform one-hot encoding on categorical features. If we do one hot encoding on this high cardinality column, the feature would be a sparse matrix where most values are zeros. One or two of the 48 columns will have the value 1, and the rest will be zero. These can be referred to as “sparse” features, where we already know that most values are zeroes. I hope you got the difference between sparse data and missing data.
Challenges of Using Sparse Datasets
-
Overfitting: When high cardinality categorical features are one-hot encoded, we end up with a lot of features. In this situation, the model starts overfitting on the features and models the noise also. If you aren’t familiar with this, look at the image below. The aim is to fit a curve separating the blue and red data points, which is done well by the black curve. But the green curve memorizes each and every data point and is a case of overfitting. When a model overfits, its ability to generalize well to new examples reduces.
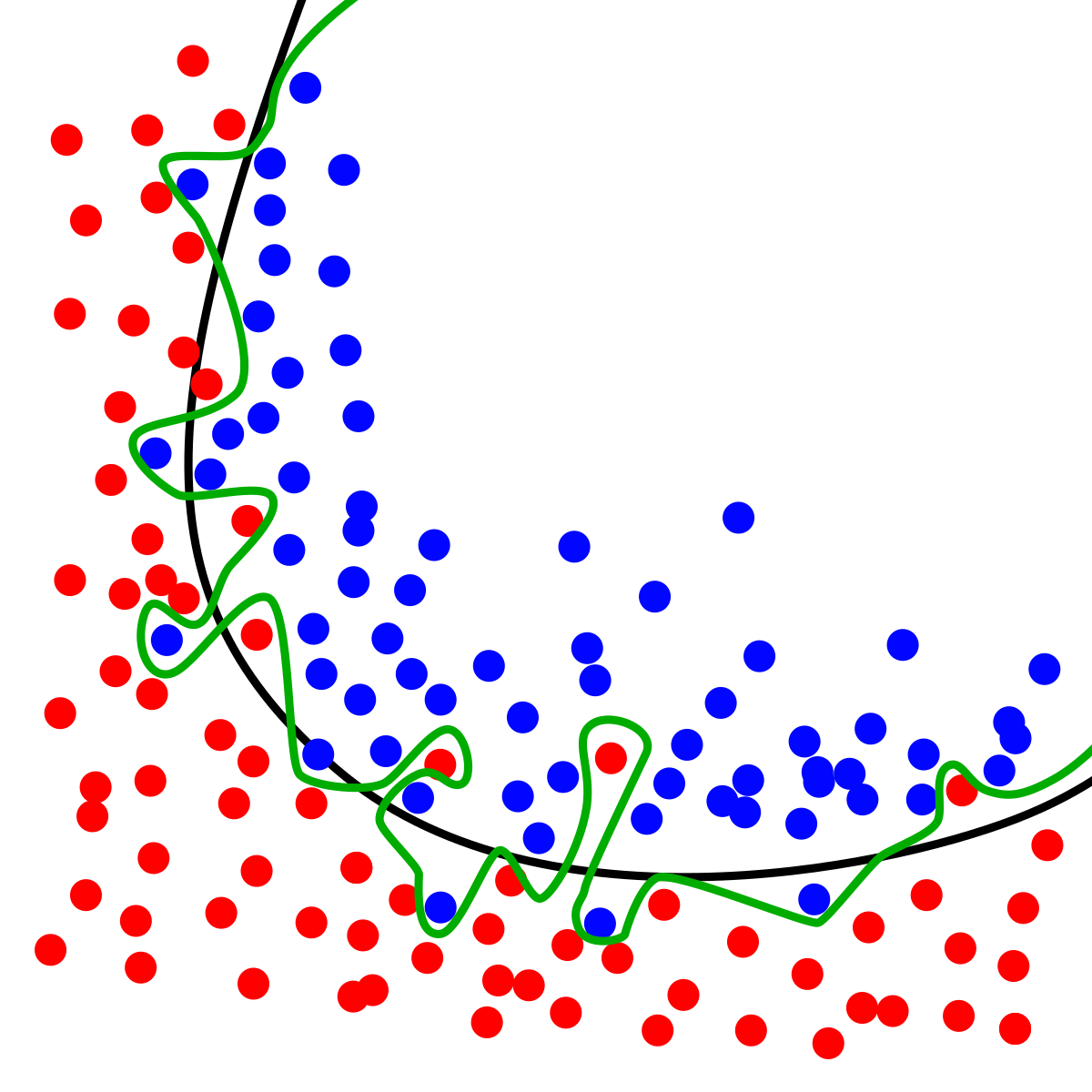
Source: Wikipedia
-
High memory usage: Sparse matrices occupy an enormous amount of memory, and working with them is difficult. If you are working with a large sparse dataset on a simple local machine, you shouldn’t be surprised even if you run out of memory.
-
Computational complexity: When dealing with large sparse matrices, every operation involving them, including simple multiplication, would require heavy computational power. Sometimes, datasets tend to have more than 95% sparsity after one hot encoding. In these cases, the processing power and time taken would be tremendous.
-
Inaccurate results: As discussed, machine learning models are built for dense features in general. So, when we have sparse features and apply these models, they may behave unexpectedly, leading to biased results. Some algorithms may underestimate the predictive power of sparse features, and higher importance might be provided to dense features. This has been observed in the feature selection of tree-based models like random forests, etc.
So, if you treat sparse features just like dense features in a Machine learning pipeline, you may end up with an overfitted biased model that uses up a lot of power & space! Don’t worry, we’ll cover the techniques to avoid this soon. But before jumping to that, let’s know when we can expect these kinds of sparse features in machine learning.
When do we Encounter Sparse Datasets?
There are some cases where input data can be found to have sparse features. The most common root is the one-hot encoding of columns which have a huge number of categories.
Some real-life cases include ratings provided by users for recommendation systems like in the case of Netflix and Amazon Prime or in the case of users’ choices in media recommendation in social media apps.
In the field of Natural Language Processing, many approaches like N-gram (challenges in NLP) and document vectors face the problem of sparse features. Take a look at the below figure. It is a feature matrix where all the unique words in the document are columns. If the word is present in the line, it correspondingly has a value of 1, otherwise stores 0. This leads to a sparse matrix.
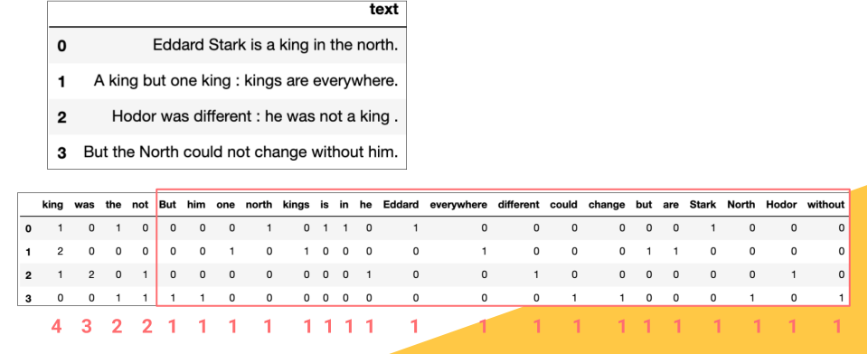
Source: https://knowledge.dataiku.com/latest/courses/nlp-visual/text-cleaning/concept-challenges-nlp.html
Hence, when you are working on these use cases, make sure to deal with sparse features first.
How to Deal with Sparse Features?
We have now looked into what sparse features are, what problems they cause, and when we could expect them. It’s high time we dive into how to handle them. You can try multiple approaches based on your data and use case.
To provide hands-on learning of some methods, I’ll be using the Netflix Prize Dataset. This was released by Netflix as a part of a competition to build recommendation systems. You can download it from Kaggle easily.
In this dataset, you have the variable “Cust_ID,” unique to each visitor of Netflix, and a “Movie_Id” variable, a unique ID provided to all movies on Netflix. The rating provided by the customer for a particular movie is stored in the variable “Rating.” Other files have corresponding information about the movie title, description, and genre to build recommendation engines. For our use case, I’ll be loading only these three variables, as shown in below code snippet.
# Importing libraries
import pandas as pd
import numpy as np
# Load the data
df = pd.read_csv('../input/combined_data_1.txt', header = None, names = ['Cust_Id', 'Rating'], usecols = [0,1]
,nrows=999999)
df['Rating'] = df['Rating'].astype(float)
df['Movie_Id'] = movie_np.astype(int)
df['Cust_Id'] = df['Cust_Id'].astype(int)
df.head()
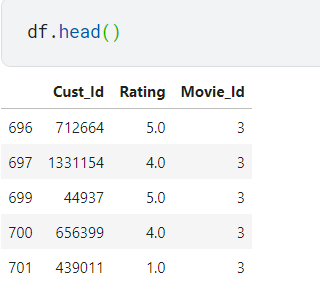
Source: Image from Author’s Kaggle Notebook
Note that I have loaded only a limited set of rows and not the entire dataset for my use case.
Let’s jump to the first method.
Using Pandas Sparse Structures
The idea is that if most of our data is just zeros, why should we store all of them? Instead, we need to store the non-zero values and the positions of these data points. This is called storing data as a sparse structure. Lucky for us, Pandas provide a simple way to store sparse structures.
Let us start to check the memory occupied by this data frame we have loaded. Pandas provide an inbuilt function, “memory_usage(),” which can be called on any dataframe.
df.info(memory_usage='deep') Int64Index: 636906 entries, 696 to 999994 Data columns (total 3 columns): Cust_Id 636906 non-null int64 Rating 636906 non-null float64 Movie_Id 636906 non-null int64 dtypes: float64(1), int64(2) memory usage: 19.4 MB
The memory occupied is 19.4 MB. We know that the Movie ID has many categories, and we must do one hot encoding to apply predictive models. Let us check the memory usage after one hot encoding.
one_hot_encoded_df=pd.get_dummies(df,columns=['Movie_Id'],sparse=False) one_hot_encoded_df.info(memory_usage='deep')
Movie_Id_209 636906 non-null uint8 Movie_Id_213 636906 non-null uint8 Movie_Id_215 636906 non-null uint8 . . Movie_Id_225 636906 non-null uint8 dtypes: float64(1), int64(1), uint8(68) memory usage: 55.9 MB
The memory usage has increased to around 56 MB! Remember, this is just a slice of the original Netflix dataset. If you try one hot encoding on the Netflix dataset, your Kernel will run out of memory and crash!
Here comes Pandas sparse structure to our rescue. You can pass the parameter “sparse = True” when you perform one hot encoding. By this, Pandas will store the data frame as a sparse structure (non-zero values).
sparse_df=pd.get_dummies(df,columns=['Movie_Id'],sparse=True) sparse_df.info(memory_usage='deep')
Movie_Id_216 -636906 non-null Sparse[uint8, 0] . . Movie_Id_223 -636906 non-null Sparse[uint8, 0] Movie_Id_225 -636906 non-null Sparse[uint8, 0] dtypes: Sparse[uint8, 0](68), float64(1), int64(1) memory usage: 17.6 MB
The memory used now is just 17.6 MB! We saved storage by almost 3.2x times!
In the above result, you can also notice the changed datatypes of the column ‘Movie_Id’ to Sparse[uint8, 0].
Scipy Sparse Matrices
Scipy is an open-source package like pandas and numpy, which supports data storage as sparse matrices. Scipy provides datatypes that can store them in multiple formats. The sparse data can be stored in scipy as a CSR matrix or a CSC matrix.
Wondering what CSR and CSC formats are?
CSR stands for Compressed Sparse Row, where data is stored in the syntax of :
(Row no, column no) value 1
(Row no, column no) value 2
CSC stands for Compressed Sparse Column, where the order is just reversed. There’s a reason why both formats are provided as an option. If you need faster row slicing and vector product calculation, you should use the CSR format. Likewise, choose CSC for faster column slicing. Based on the nature of your sparse matrix, you can decide.
Let’s take a simple look at how to create a sparse matrix using the scipy package, as it may be new to many.
from scipy.sparse import csr_matrix import numpy as np sparse_data = np.array([0, 0, 0, 0, 0, 1, 0, 1, 0 , 0, 2]) print(csr_matrix(sparse_data))
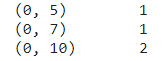
You can also see how it gets stored in the image of the output.
Let us get back to our main goal, how can this help us in sparse datasets?
When working with sparse datasets, convert pandas data frames into scipy sparse matrixes. They take much lower storage and you can perform all mathematical computations much faster. When you reach the modeling stage, libraries like sklearn directly accept sparse matrices. There’s no requirement to convert back, also!
sparse_matrix = scipy.sparse.csr_matrix(df.values)
You must pass the data frame’s value to the csr_matrix() function. You may print out the memory occupied by both and compare them to see the advantage.
Removal of Features
In some cases, the number of features increases significantly after one-hot encoding and creates noise in the dataset. Among these, some features are integral, and we apply the above-discussed methods to retain and use them. But it’s always better to be efficient. You can drop the features which may not provide significant value for the model you want to train.
How are features dropped from sparse datasets?
-
We previously discussed that sparse data is ubiquitous in NLP documents. In these circumstances, rare words that seldom appear in common usage can be dropped while developing text mining models.
-
Generally, we drop variables that have very low variance. By variance, we try to see how a particular feature varies over its population. Features with the same value in all samples are said to have zero variance. The zero variance variables are the first to be dropped, as they create very little impact on the target. If you want to try this, use sklearn ‘s feature selection module’s function “VarianceThreshold.” With this, you can set a variance threshold for selecting features for your model.
-
Lasso regularization can be applied to eliminate some features. Lasso uses the L1 regularization technique, where penalties are applied to the coefficients of model parameters based on the deviation of predictions. When larger penalties occur, some of the coefficients become zero, and the parameter gets dropped out of the mode. You can apply this to select features.
PCA on Features
Principal Component Analysis (PCA) is a method that can be applied to sparse datasets to make them dense. This is a dimensionality reduction method that helps in the selection of features. The large dataset extracts principal components that have most of the variance. This way, we have lesser features but with the least loss of information. As word embedding in Natural Language Processing constitutes high dimensional sparse matrices, PCA can be applied to them. You can read more about this in this research publication.
Feature Hashing
When you have very high dimensional datasets, you can apply feature hashing to reduce the dimension to mid-size. You can decide the number of output features needed in this method. The hash function will bin the sparse features into the specified number.
A major application of this method can be seen in the below image. The problem statement was to build a classification model on protein sequences. As you can guess, protein sequences are sparse matrices! Feature hashing was applied to provide successful and efficient results.

Source: Protein Sequence Classification Using Feature Hashing
Selection of Robust Models
All the methods we covered till now tell you how to manipulate sparse data and apply ML models to it. Now, we see the alternative option. You can choose more robust and adaptive machine learning algorithms for sparse data. One prominent example is the entropy-weighted K-means algorithm. This was developed especially for clustering high dimensional data and provides better results than normal K means. Similarly, a sparse robust regression model was developed, which you can read about here.
Conclusion
I hope you understood the underlying concept of what happens in sparse datasets. Before we wrap up, let us recall the main takeaways from everything we learned.
- The first step is to look for sparsity in the data based on the number of categorical features and data type. Most common instances include NLP text mining, user ratings, and reviews.
- Depending on their relevance, variance, and importance, you can consider dropping features. Feature selection techniques, including setting a variance threshold, can be applied.
- If you can’t drop them, you can make them dense using dimensionality reduction techniques like PCA and feature hashing.
- To store the sparse data affordably and efficiently, use pandas’ sparse structures and scipy sparse matrices.
- The operations also speed up when the sparse data is stored in formats like CSR and COO.
The applications of sparse datasets are immense in today’s world, where text mining is a growing industry. Research is happening as we speak to bring in more innovations in the domain. I have covered all the major methods to handle sparse datasets here. Hope you enjoyed the read!
If you wish to contact me, you can mail me at [email protected].
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






