This article was published as a part of the Data Science Blogathon
The First Step in Data Science

Introduction
Machine Learning seems to be a big fascinating term, which attracts a lot of people towards it, and knowing what all we can achieve through it makes the sci-fi imagination of ours jump to another level. No doubt in it, it is a great field and we can achieve everything from an automated reply system to a house cleaning robots, from recommending a movie or a product to help in detecting disease. Most of the things that we see today have already started using ML to better themselves.
Though building a model is quite easy, the most challenging task is preprocessing the data and filtering out the Data of Use. So, here I am going to address one of the biggest and common issues that we face at the start of the journey of making a Good ML Model, which is The Missing Data.
Missing Data can cause many issues and can lead to wrong predictions of our model, which looks like our model failed and started over again.
If I have to explain in simple terms, data is like Fuel of our Models, if the Fuel is dirty, has impurities or less in quantity it will impact the performance of the vehicle, no doubt vehicle will run with it but the performance that we expect from the vehicle will not be delivered.
Moving On.. There are a lot of steps and processes that we can use to process and identify these missing data, I will be listing here few General issues, how to identify them, and techniques we can use to overcome these issues.
Overview of Missing Data
Before we jump and have a look at the issues that we face with these missing data lets us see How and Why does these Missing Data occur in our Datasets.
Reasons
A few of the main reasons are:-
- Data is Lost:- At times it is possible if the data is stored in systems and due to one of the many systems crashed and we were only able to retrieve parts of it OR if the file was broken which led to the loss of some parts of the data. {Shown in Red Box}
- Data is not captured:- This is one of the most common issues that we face, if we are collecting data from some online forms and a few of the fields are not marked mandatory then there are chances that the user is going to skip those fields. {Shown by Blue Lines}
- Wrong values present in Dataset:- This situation is also quite common when due to improper validations at data source collection we gather wrong data like age as 250 instead of 25, OR incorrect spelling of places, person, etc. It can also occur due to mistakes made by the person taking surveys etc. {Shown in Yellow Highlighted}
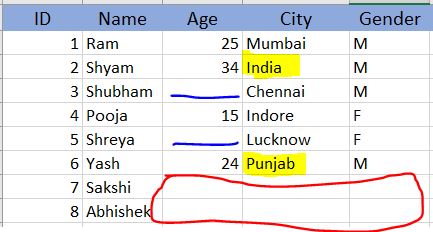
Reasons for Missing Data
Since we have seen these are the most common scenarios that can occur with anyone anytime and can’t be avoided in most situations. So, now the question arises “What is the impact of such missing data?” “How can we overcome these missing data?”. So, now let’s move ahead and see what is the Impact of these Missing Data.
Impact of Missing Data
Though I have shared a brief overview of the impact of the Missing Data in the Introduction. Let’s see more about them.
- Incompatible with most of the Python libraries used in Machine Learning:- Yes, you read it right. While using the libraries for ML(the most common is skLearn), they don’t have a provision to automatically handle these missing data and can lead to errors.
- Distortion in Dataset:- A huge amount of missing data can cause distortions in the variable distribution i.e can increase or decrease the value of a particular category in the dataset.
- Affects the Final Model:- As already stated in the starting, these missing data can cause a bias in the dataset and can lead to a faulty analysis by the model. As the representative power of the samples.
Moving ahead How to rectify Or control these issues, but we need to identify them correctly before that. These missing data are categorized into 3 major categories which are mostly used to identify them.
Types of Missing Data
Missing Data can be classified into the following 3 categories:-
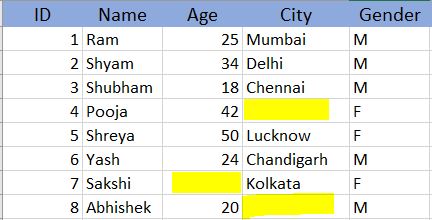
- Missing Completely At Random (MCAR):- This states that the probability of missing the data in the dataset does not depend on any factor and can be the same for all the columns. Also, it states that there is no relation between any observation present or missing in the dataset. {Fig 2.}
Eg. :- Probability of missing email id for a few of the responses in an online form is completely random which could have occurred due to some server or DB-related issues for a few of the responses.
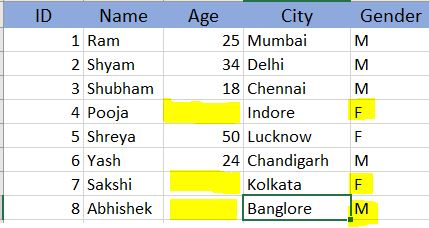
Plus Point:: Even if we plan to disregard such observations it won’t bias our dataset. Yes, it could reduce the size of the dataset thus affecting a bit of the predictive powers of the model but the impact will be negligible. - Missing At Random (MAR):- The basic idea behind this is that the values are missing at random, that is data is missing based on the available information. Females are less likely to share their weight, height, and DoB than Males. Thus, we can find a relation between Gender and Weight/ Height Or DoB. So, the probability of missing data depends on gender. {Fig 1.}
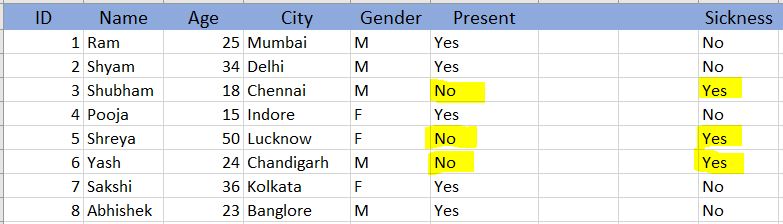
Plus Point:: We can control or predict the variables based on the dependent variable - Missing Not At Random (MNAR):- Anything that does not fall in the above 2 categories automatically falls under this one. This means that the data that is missing depends not only on observed values but also on some unobserved values and these values are introduced based on some mechanism in the dataset like suppose absenteeism of a student can largely depend on his health or family issues but we have not recorded them. {Fig 3.}
Methods to Handle Missing Data
Now, since we know data can be and is missing in our dataset we can employ the below techniques to overcome these:-
- Know the Source:- One of the important steps to overcome/handle these missing data is to “Know the Source” which is how the data was collected, the mechanism used to collect it, and the source from where we are getting the data.
- Knowing the Data:- This step I feel is important and can be a game-changer if we become well versed with the dataset that is known in depth of each column their significance, type to expect in these columns and if possible limits of that column/variable.
- Imputation:- This is the technique that we use to handle the missing data. Since this is a large topic in itself, will be writing a separate blog for these techniques.
Summary
To end with… We have gone through one of the Major Problems in ML i.e Missing Data, how they are introduced in the dataset, what is their impact, and how to identify them.
Hope that helps you…. Until then This is Shashank Singhal, a Big Data & Data Science Enthusiast.
If you liked my article you can follow me HERE
LinkedIn Profile:- www.linkedin.com/in/shashank-singhal-1806
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






