Modern AI systems struggle with memory. They often forget past interactions or rely on Retrieval-Augmented Generation (RAG), which depends on constant access to external data. This becomes a limitation when building assistants that need both historical context and a deeper understanding of users.
MemPalace offers a different approach, enabling structured, persistent memory with higher precision and consistency. In this article, we explore how it improves AI memory systems and how you can implement it effectively.
Table of contents
- What is MemPalace?
- The Core Idea: Verbatim Memory vs Summarization
- Deep Dive Into: MemPalace Architecture
- How MemPalace Works (End-to-End Flow)
- Context Injection into LLMs
- How to Use MemPalace with in Agentic Frameworks (LangGraph)
- MemPalace vs Traditional Memory Systems
- Future of AI Memory Systems
- Conclusion
- Frequently Asked Questions
What is MemPalace?

MemPalace is an open-source, local-first memory system that stores conversations and project data in their original form. Each message is treated as a distinct memory unit, enabling persistent, structured recall.
Its design follows a hierarchical “palace” model: Wings for people or projects, Rooms for topics, Halls for memory types, and Drawers for transcripts, with Closets for summaries.
How It Differs from Traditional Memory Systems
Traditional systems like RAG pipelines or vector databases focus on retrieval efficiency, which results in reduced context richness. They divide data into segments, create embeddings, and obtain similar segments during the inference process.
MemPalace uses a distinct method to store information:
- The system keeps complete information in its original form instead of using only its embedding.
- The system establishes a hierarchical structure, which enhances its ability to understand context.
- The system uses a combination of symbolic structure and vector search to connect two different systems of knowledge.
The system achieves superior reasoning capabilities and better traceability features through its hybrid framework when compared to conventional memory systems.
The Core Idea: Verbatim Memory vs Summarization
Most agent memory tools use an LLM to summarize or extract key facts from conversations. The tools Mem0 and Zep analyze chat content to create brief reports which include essential facts and user preferences. The solution results in the loss of both contextual information and subtle details. As an LLM must decide what’s “important” and discard the rest.
MemPalace takes the opposite approach: “store everything”. The system keeps a complete record of all messages between users and assistants. The system keeps all data intact without any form of summarization or deletion. The method of unprocessed data storage provides important advantages which include:
- Complete context: The system maintains complete access to all conversation details which enables the AI to reconstruct the entire dialogue.
- Higher recall: The complete word database of MemPalace enables the system to achieve outstanding accuracy in retrieving information. Its raw mode achieves 96.6% recall@5 results on LongMemEval which contains 500 questions.
- Traceability: The system maintains everything so users can check answers against original chat logs.
Deep Dive Into: MemPalace Architecture
The design of MemPalace uses the ancient mnemonic method of loci as its foundation. The system creates a multi-tiered framework which enables users to easily locate and access stored memories. The memory palace system establishes its hierarchical structure and data processing system through the following overview.
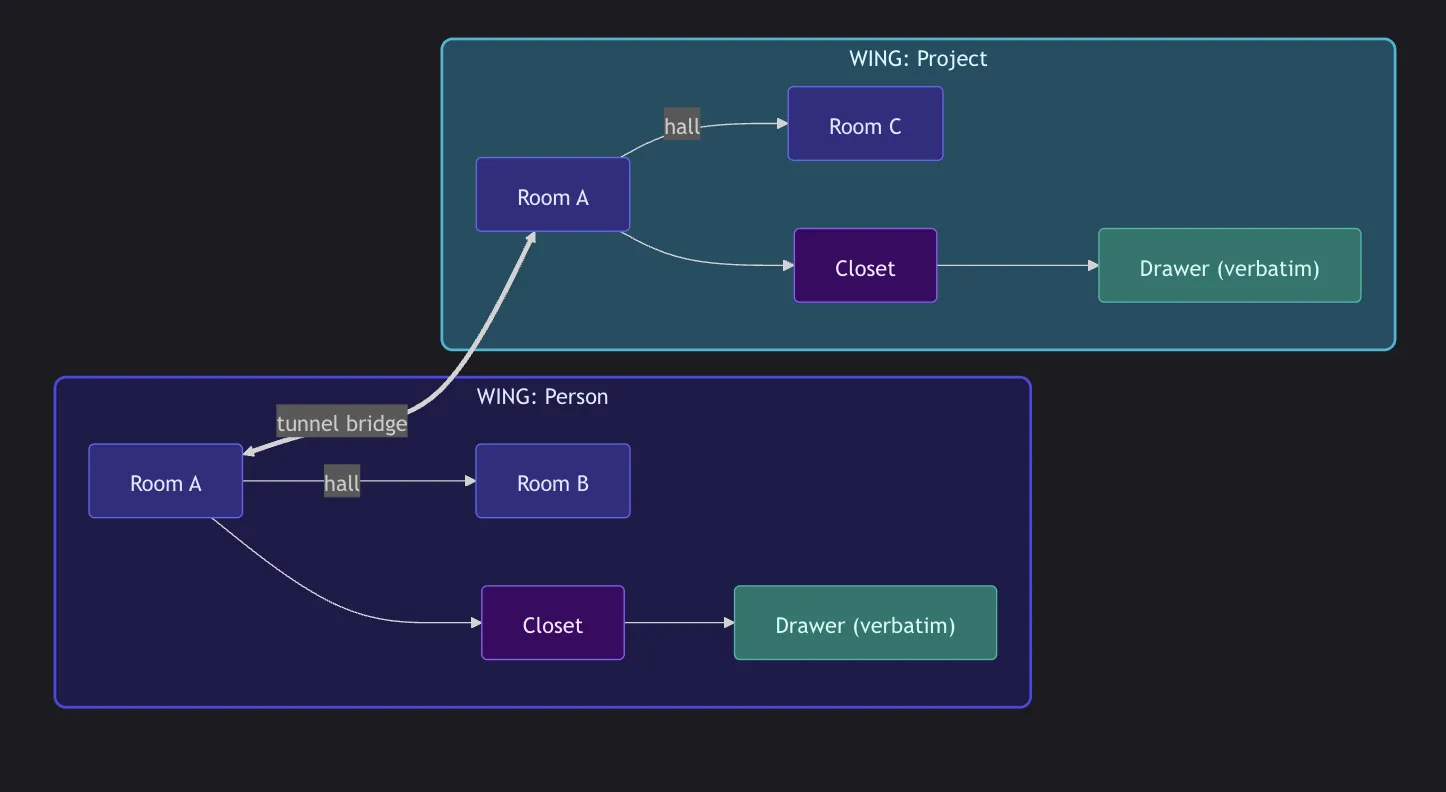
The “Palace” Hierarchical Memory Design
- Wings (Project-Level Segmentation): Wings define primary divisions which encompass entire domains or projects. This enables you to separate your memories into two categories which include personal memories and team-based memories. Topics within a wing become organized into specific Rooms after the definition of wings.
- Rooms (Topic-Level Organization): Rooms function as spaces that connect all subjects which exist within a wing. The “Work” wing contains three separate rooms which are named “Meetings” and “Projects” and “Emails”. Each document or conversation gets assigned to a specific wing and room combination.
- Halls (Memory Types: Facts, Events, Preferences): Across all wings, there are common Halls which classify memory types. MemPalace defines halls like hall_facts, hall_events, hall_discoveries, hall_preferences, and hall_advice. For instance, a project decision (“switch to GraphQL”) goes into the hall_facts of its room; a meeting summary goes into hall_events. Halls let you retrieve all “facts” from any wing or restrict to a wing-specific hall.
- Drawers (Raw Verbatim Storage): Every memory chunk exists within a specific Drawer. A drawer contains a text file which contains the complete transcript of a chat or email or code file which exists exactly as it was recorded. Drawers function as unaltered archives which save their contents in their original form. MemPalace establishes additional Closets which accompany each drawer when you choose to activate compression.
- Closets (Compressed Representations): A closet contains the AAAK-compressed summary (or “summary”) which represents that drawer. Closets direct users to their original drawer content which functions as a compact index. MemPalace uses the drawers themselves for retrieval purposes, but this function exists as its default feature.
Storage and Retrieval Pipeline
MemPalace’s pipeline consists of two main components which operate as writing memory for ingestion and as reading memory for query-time retrieval.
- Verbatim Storage (Ingestion): Whenever a conversation or file is mined, MemPalace writes each message as a new Drawer entry in its database. The text goes straight into a vector store (default: ChromaDB) without LLM filtering. In contrast to extractive systems like Mem0, MemPalace simply saves the raw content. Metadata like wing, room, and hall tags are attached so later queries can filter by context.
- Vector Search with ChromaDB: For retrieval, MemPalace leverages semantic vector search. Each drawer is embedded (using the default model) and stored in ChromaDB. When you query MemPalace, the system vectorizes your query and finds the most similar drawers by cosine similarity. This usually returns matches in milliseconds.
- Metadata Layer (Knowledge Graph): Beyond raw text, MemPalace builds a temporal knowledge graph in local SQLite. Each fact (subject–predicate–object) is stored with validity windows (start/end dates). This includes:
- Temporal relationships
- Entity linking
- Context dependencies
Compression Mechanism (AAAK)
MemPalace provides an optional compression function which it designates as AAAK. AAAK functions as a special shorthand system which enables users to store extensive information through minimal token usage. The system performs lossy compression because its primary mechanism uses regular expressions to transform words into abbreviations while selecting key sentences for extraction, which results in approximately 30 times reduction of tokens.
- Lossless Compression Strategy: The long-term goal of AAAK is to be “lossless” in content. The ideal encoding should let you reconstruct every factual assertion. AAAK should provide complete evidence of who performed which actions at which times for which reasons. The design constraints forbid proprietary tokenizers or embeddings AAAK must work across any model.
- Token Efficiency and Context Injection: The long-term goal of AAAK is to be “lossless” in content. The ideal encoding should let you reconstruct every factual assertion. AAAK should provide complete evidence of who performed which actions at which times for which reasons. The design constraints forbid proprietary tokenizers or embeddings AAAK must work across any model.
How MemPalace Works (End-to-End Flow)
The system enables AI agents to maintain permanent memory elements which users can search at any time. The system transforms spoken dialogue into vector representations which it saves in ChromaDB. The agent accesses its essential memories when it requires specific information instead of using its complete memory database.
Data Ingestion (Conversation Mining)
Data ingestion is the first step. MemPalace listens to every turn of a conversation and captures user messages, AI responses, and metadata. It then prepares this raw text for storage.
- Chunking: MemPalace splits long messages into 512-token chunks with 64-token overlaps. This prevents context loss at chunk boundaries.
- Metadata tagging: Each chunk gets a role (user or assistant), a turn number, a session ID, and a timestamp.
- Deduplication: MemPalace uses deterministic IDs like session-turn-N. Re-saving the same turn simply overwrites the existing record.
Memory Indexing and Structuring
The system processes data through its ingest process which produces vector embeddings for each data segment. The system uses a sentence-transformer model which converts text into a high-dimensional numerical vector. ChromaDB stores this vector together with the original text and its accompanying information.
The indexing process has two key components:
- The Vector Store: ChromaDB organizes its embeddings through an HNSW (Hierarchical Navigable Small World) index system. The structure enables users to perform fast approximate nearest-neighbor searching. The system locates semantically matching memories within a few milliseconds by searching through its database of stored memory chunks.
- The Metadata Layer: The index stores vector data together with its associated metadata dictionary. The user can choose to filter results based on any database field during query execution. The user can choose to filter results between summary-type chunks and specific session turns from a particular session. The system uses structured filtering methods to achieve both quick and exact data retrieval.
Query-Time Retrieval and Ranking
The system transforms user messages into query vectors which MemPalace uses to find the most similar database entries through its search of ChromaDB. The system only displays results for chunks that exceed the minimum score threshold of 0.70.
The retrieval pipeline applies three filters in order:
- Session filter: The system limits results to the present session because it uses the current
session_id. Cross-session bleed does not occur. - Type filter: The system allows users to choose whether they want summary chunks or raw turn chunks for obtaining high-level context.
- Score threshold: The system removes results which do not meet the established minimum similarity requirement. This prevents irrelevant memories from polluting the context.
Context Injection into LLMs
MemPalace does not stuff the entire conversation history into the prompt. The system creates a structured block which contains the top-K retrieved chunks and adds it before the system prompt. The LLM sees only relevant past context not every turn.
The injected context block looks like this:
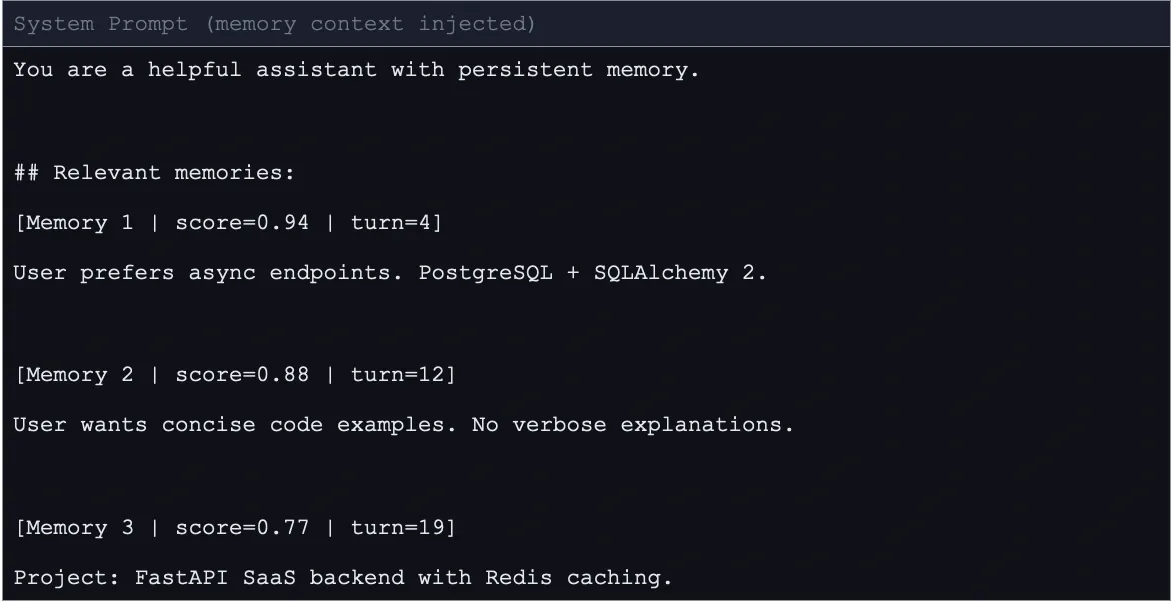
Each memory block includes a similarity score and turn number. The LLM receives provenance information through this mechanism. The user can select between two memory options which contain score values of 0.94 and 0.71 respectively. The injection adds zero overhead to ChromaDB because it utilizes results which the system retrieved during the search process.
How to Use MemPalace with in Agentic Frameworks (LangGraph)
LangGraph enables you to construct agents through state machines which operate with nodes that execute single tasks and edges which determine movement between nodes. MemPalace operates through two specialized nodes which include a retrieval node that connects to the chat node and a saving node that connects to the chat node. The system provides LangGraph agents with permanent memory storage which users can search through.
The section provides a guide which explains how to complete each integration step. The section provides complete Python code together with the terminal output that should appear at each development stage.
Step 1: Install packages
MemPalace, LangGraph, ChromaDB, and the sentence-transformer library should be installed in a Python virtual environment.
Verify all packages installed correctly:
import mempalace
import langgraph
import chromadb
print(f'MemPalace: {mempalace.__version__}')
print(f'LangGraph: {langgraph.__version__}')
print(f'ChromaDB: {chromadb.__version__}')Output:
MemPalace: 3.3.3
LangGraph: 1.1.10
ChromaDB: 1.5.8
Step 2: Configure environment variables
Create a .env file at the root of your project. The variables determine both the location where ChromaDB stores its data and the specific embedding model which MemPalace will utilize.
OPENAI_API_KEY=sk-...
MEMPALACE_DB_PATH="./chroma_palace"
MEMPALACE_COLLECTION="agent_memory"
MEMPALACE_EMBED_MODEL="all-MiniLM-L6-v2"
Step 3: Initialize the MemPalace
This will create the ChromaDB client connection and prepares the embedding function and creates a MemPalace instance. The collection is created by executing the program once. The program automatically loads the existing collection during all following executions. Put the below piece of code in palace_init.py.
import os
from dotenv import load_dotenv
import chromadb
from chromadb.utils import embedding_functions
from mempalace import MemPalace, PalaceConfig
load_dotenv()
# 1. Persistent ChromaDB client
chroma_client = chromadb.PersistentClient(
path=os.getenv('MEMPALACE_DB_PATH', './chroma_palace')
)
# 2. Sentence-transformer embedding function
embed_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name=os.getenv('MEMPALACE_EMBED_MODEL', 'all-MiniLM-L6-v2'),
device='cpu' # switch to 'cuda' if a GPU is available
)
# 3. Get or create a named collection
collection = chroma_client.get_or_create_collection(
name=os.getenv('MEMPALACE_COLLECTION', 'agent_memory'),
embedding_function=embed_fn,
metadata={'hnsw:space': 'cosine'}
)
# 4. Configure MemPalace
config = PalaceConfig(
max_memories=5000,
similarity_threshold=0.75,
chunk_size=512,
chunk_overlap=64,
top_k=5,
)Output:
# First run (empty palace):
Palace ready. Memories stored: 0
# Subsequent runs (data persists):
Palace ready. Memories stored: 243
Step 4: Define AgentState and the chat node
LangGraph transfers a state dictionary through its node connections. The AgentState TypedDict requires four specific fields which include the message list, the injected memory context, a turn counter, and the session ID. The chat node reads from this state and writes back to it. Put this in agent.py
from __future__ import annotations
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, END
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
class AgentState(TypedDict):
messages: List[BaseMessage]
memory_context: str # retrieved memories, injected into system prompt
turn_count: int # tracks turns for auto-save trigger
session_id: str
llm = ChatOpenAI(model='gpt-4o-mini', temperature=0.7)
def build_system_prompt(memory_ctx: str) -> str:
base = 'You are a helpful assistant with persistent memory.\n'
if memory_ctx:
return base + f'\n## Relevant memories:\n{memory_ctx}\n'
return base
def chat_node(state: AgentState) -> AgentState:
system = build_system_prompt(state['memory_context'])
response = llm.invoke([
{'role': 'system', 'content': system},
*state['messages']
])
return {
**state,
'messages': state['messages'] + [AIMessage(content=response.content)],
'turn_count': state['turn_count'] + 1,
}Step 5: Add the retrieval search hook
The retrieve node runs before every chat turn. The system takes the most recent human message and uses it to search ChromaDB through MemPalace. The output results from this process are stored in memory_context. The chat node then sees that context in its system prompt. Put this in search_hooks.py
from langchain_core.messages import HumanMessage
from palace_init import palace
from agent import AgentState
def retrieve_memories_node(state: AgentState) -> AgentState:
messages = state['messages']
if not messages:
return {**state, 'memory_context': ''}
# Use the last human message as the search query
query = ''
for msg in reversed(messages):
if isinstance(msg, HumanMessage):
query = msg.content
break
if not query:
return {**state, 'memory_context': ''}
# Search ChromaDB via MemPalace
results = palace.search(
query=query,
top_k=5,
filters={'session_id': state['session_id']},
min_score=0.70
)
if not results:
return {**state, 'memory_context': ''}
# Format results for the system prompt
ctx_lines = []Output:
[MemPalace] Retrieved 3 memories.
[Memory 1 | score=0.94 | turn=4]
User prefers async endpoints. PostgreSQL + SQLAlchemy 2.
[Memory 2 | score=0.88 | turn=12]
User wants concise code examples. No verbose explanations.
[Memory 3 | score=0.77 | turn=19]
Project: FastAPI SaaS backend with Redis caching.
Step 6: Auto-save every 15 messages
The save node runs after the chat node according to a conditional edge. When turn_count reaches a multiple of 15, it writes the last 15 messages to ChromaDB with role, turn, and timestamp metadata. The system then resets turn_count to zero. Put this in autosave.py
from datetime import datetime
from langchain_core.messages import HumanMessage, AIMessage
from palace_init import palace
from agent import AgentState
SAVE_EVERY = 15
def save_memories_node(state: AgentState) -> AgentState:
messages = state['messages']
session_id = state['session_id']
batch_start = max(0, len(messages) - SAVE_EVERY)
batch = messages[batch_start:]
docs, metadatas, ids = [], [], []
for i, msg in enumerate(batch):
role = 'human' if isinstance(msg, HumanMessage) else 'ai'
docs.append(msg.content)
metadatas.append({
'session_id': session_id,
'role': role,
'turn': batch_start + i,
'saved_at': datetime.utcnow().isoformat(),
})
ids.append(f'{session_id}-turn-{batch_start + i}')
palace.add_batch(documents=docs, metadatas=metadatas, ids=ids)
print(f' [MemPalace] Saved {len(docs)} messages. Total: {palace.count()}')
return {**state, 'turn_count': 0} # reset counter
def should_save(state: AgentState) -> str:
return 'save' if state['turn_count'] % SAVE_EVERY == 0 else 'end'Output:
# Turn 15 fires the save:
[MemPalace] Saved 15 messages. Total: 15
# Turn 30 fires the save again:
[MemPalace] Saved 15 messages. Total: 30Step 7: Add memory summarization (compression)
The expanding palace construction needs more space because unprocessed materials take up area and building materials become harder to retrieve. The summarize node fires after every save, once the total doc count exceeds a threshold. The process combines 15 previous dialogue segments into a single summary which it creates through LLM technology while it removes all unprocessed material. Put this in summarizer.py
from datetime import datetime
from typing import List
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI
from palace_init import palace
SUMMARIZE_EVERY = 15 # batch window size
COMPRESS_THRESHOLD = 50 # only compress once palace exceeds this
summarizer_llm = ChatOpenAI(model='gpt-4o-mini', temperature=0)
SUMMARY_PROMPT = '''You are a memory compressor for an AI assistant.
Given the conversation excerpt below, produce a dense factual summary.
Preserve all user preferences, decisions, and context.
Write in third person. Aim for 3-6 sentences.
Conversation:
{transcript}
Summary:'''
def _format_transcript(messages: List[BaseMessage]) -> str:
lines = []
for msg in messages:
role = 'User' if isinstance(msg, HumanMessage) else 'Assistant'
lines.append(f'{role}: {msg.content}')
return '\n'.join(lines)
def summarize_and_compress(messages, session_id, batch_start) -> str:
transcript = _format_transcript(messages)
prompt = SUMMARY_PROMPT.format(transcript=transcript)
response = summarizer_llm.invoke([HumanMessage(content=prompt)])
summary_text = response.content.strip()
summary_id = f'{session_id}-summary-turns-{batch_start}-{batch_start + len(messages)}'
palace.add_batch(
documents=[summary_text],
metadatas=[{
'session_id': session_id,
'type': 'summary',
'turn_start': batch_start,
'turn_end': batch_start + len(messages),
'saved_at': datetime.utcnow().isoformat(),
'raw_turns': len(messages),
}],
ids=[summary_id],
)The process begins with 15 raw chunks which the LLM transforms into 3-6 sentence summaries. The process results in a single summary chunk. ChromaDB deletes the 15 originals. The process results in a storage reduction of approximately 93 percent while maintaining the original meaning of the content. Now we’ll create a summarizer node which will decide when the agent will provide summary.
from agent import AgentState
from palace_init import palace
from summarizer import (
summarize_and_compress,
delete_raw_batch,
SUMMARIZE_EVERY,
COMPRESS_THRESHOLD
)
def summarize_node(state: AgentState) -> AgentState:
if palace.count() < COMPRESS_THRESHOLD:
print(f' [Summarizer] Skipped — {palace.count()} docs in palace.')
return state
messages = state['messages']
session_id = state['session_id']
total_turns = len(messages)
batch_start = max(0, total_turns - SUMMARIZE_EVERY * 2)
batch_end = batch_start + SUMMARIZE_EVERY
batch = messages[batch_start:batch_end]
if not batch:
return state
summarize_and_compress(batch, session_id, batch_start)
delete_raw_batch(session_id, batch_start, batch_end)
print(f' [Summarizer] Palace size after compression: {palace.count()}')
return state
def should_summarize(state: AgentState) -> str:
return 'summarize' if state['turn_count'] == 0 else 'end'Step 8: Assemble the full LangGraph pipeline
The process requires you to merge all nodes into one StateGraph structure The graph flows: retrieve -> chat -> (save | end) -> (summarize | end). The graph maintains operational efficiency because its conditional edges allow nodes to activate only when their respective triggering conditions are met. Now we’ll finally combine all the above nodes into a full_graph.py
from langgraph.graph import StateGraph, END
from agent import AgentState, chat_node
from search_hooks import retrieve_memories_node
from autosave import save_memories_node, should_save
from summarize_node import summarize_node, should_summarize
graph = StateGraph(AgentState)
graph.add_node('retrieve', retrieve_memories_node)
graph.add_node('chat', chat_node)
graph.add_node('save', save_memories_node)
graph.add_node('summarize', summarize_node)
graph.set_entry_point('retrieve')
graph.add_edge('retrieve', 'chat')
# After chat: save if turn_count hit the threshold
graph.add_conditional_edges(
'chat',
should_save,
{
'save': 'save',
'end': END
}
)
# After save: compress if palace is large enough
graph.add_conditional_edges(
'save',
should_summarize,
{
'summarize': 'summarize',
'end': END
}
)
graph.add_edge('summarize', END)
agent = graph.compile()Step 9: Test with a sample conversation
For this we will conduct a 20-turn test conversation to test three functions which include auto-save timing at turn 15 and memory retrieval from turn 10 and subsequent times and the accuracy of cross-session recall results which show similarity scores.
import uuid
from langchain_core.messages import HumanMessage
from full_graph import agent
from palace_init import palace
SAMPLE_TURNS = [
'Hi! I am building a FastAPI backend for a SaaS app.',
'I prefer async endpoints. PostgreSQL is my database.',
'Can you suggest a folder structure for the project?',
'I want to add JWT authentication.',
'Pydantic v2 for validation, SQLAlchemy 2 async ORM.',
'Keep code examples concise — no verbose explanations.',
'What is the best way to handle database migrations?',
'Show me an async endpoint with a DB session dependency.',
'Add rate limiting to the auth routes.',
'How should I structure Pydantic schemas?',
'I also need background tasks for email sending.',
'Use Redis for caching user sessions.',
'What testing framework do you recommend?',
'Help me write a pytest fixture for the DB.',
'Run a final check — is the project structure solid?', # turn 15 -> save
'Now add a websocket for real-time notifications.',
'How do I deploy this to AWS ECS?',
'Add a Dockerfile and docker-compose.yml.',
'Configure CORS for the frontend at localhost:3000.',
'Final review — anything I missed?', # turn 20
]
def run_test():
session_id = str(uuid.uuid4())
state = {
'messages': [],
'memory_context': '',
}Output:
=== Session: a3f9c2d1... ===
Turn 01 | memories=0000 | ctx=False
Turn 02 | memories=0000 | ctx=False
Turn 05 | memories=0000 | ctx=False
[MemPalace] Retrieved 1 memories.
Turn 10 | memories=0000 | ctx=True
[MemPalace] Saved 15 messages. Total: 15
Turn 15 | memories=0015 | ctx=True <- auto-save fired
[MemPalace] Retrieved 3 memories.
Turn 20 | memories=0015 | ctx=True
Final memories in palace: 15
--- Cross-session recall ---
[0.94] Turn 4: Pydantic v2 for validation, SQLAlchemy 2 async ORM...
[0.91] Turn 1: I prefer async endpoints. PostgreSQL is my database...
[0.77] Turn 11: Use Redis for caching user sessions...
The output shows how the system builds and uses memory step by step. The system starts without memory because it needs to access previous information. The system starts to retrieve helpful data after the dialogue progresses. At turn 15, it saves 15 messages into long-term memory. The system uses its memory after turn 20 to improve its answers. The system demonstrates memory retention by accurately recollecting significant details from previous talks.
MemPalace vs Traditional Memory Systems
| Aspect | MemPalace vs RAG Pipelines | MemPalace vs Vector Databases | MemPalace vs Agent Memory Frameworks |
|---|---|---|---|
| Core Function | RAG retrieves static documents such as PDFs and knowledge bases at query time. | Vector databases store embeddings for similarity search. | Agent memory frameworks store short-term chat memory or key-value data. |
| Memory Type | RAG does not store previous dialogue sessions or track user behavior. | Vector databases provide flat embedding storage without memory structure. | These frameworks usually maintain brief records or essential facts. |
| MemPalace Difference | MemPalace acts as a persistent memory store beyond a single prompt. | MemPalace adds organized spatial elements such as wings, rooms, and halls. | MemPalace can replace commercial memory tools while giving users full control. |
| Key Advantage | RAG can be layered on top of MemPalace as document memory. | Its hierarchy helps users narrow down search results more effectively. | It offers privacy, control, and a local-first alternative to paid services like Letta. |
Future of AI Memory Systems
The demonstration of MemPalace shows how artificial intelligence systems now operate with permanent structured memory because their agents function as ongoing learning systems instead of operating as non-dependent instruments. The architectural development progresses from RAG to new systems which depend on memory as their core element for executing reasoning tasks and managing user interactions.
- Toward Persistent AI Agents: The development of persistent AI agents now enables systems to maintain operational memory which allows them to track their current tasks and activities continuously while waking up with full task knowledge.
- Memory-Centric AI Architectures: The research focuses on developing hybrid systems which combine LLMs for reasoning tasks with memory systems that handle information storage and retrieval and organizational structures.
- Research Directions in Long-Term Memory: The researchers work on developing more efficient compression methods and improved temporal reasoning retrieval systems and scalable knowledge graphs which will be assessed using enhanced evaluation standards.
Conclusion
The organization of MemPalace sets a new standard for AI memory systems by prioritizing fidelity, structure, and long-term retention. Its hierarchical design and exact data preservation overcome limitations of traditional systems like RAG and summarization-based approaches.
Its strength comes from combining AAAK compression, a temporal knowledge graph, and MCP integration. The next step for context-aware agents is building memory systems that preserve full user experiences, not just outputs. MemPalace reflects this shift by enabling extended memory capabilities and marking a significant step toward true AI memory.
Frequently Asked Questions
Q1. What is MemPalace?
A. MemPalace is a local-first memory system that stores complete conversations as structured, persistent memory units for accurate recall and context.
Q2. How is MemPalace different from RAG?
A. Unlike RAG, MemPalace stores full data verbatim and uses hierarchical structure for richer context, better reasoning, and improved traceability.
Q3. Why does MemPalace avoid summarization?
A. It preserves all details by storing raw conversations, ensuring higher recall, complete context, and verifiable memory without losing subtle information.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.





