We launched Analytics Professional salary test last week and got awesome response from our audience. People loved it and shared it across social media channels. We got a few requests from people outside India to create some thing similar for other geographies.
Given the response, I thought it would be interesting to share the story about creating this web application. Following reasons make it a very interesting read:
- The story tells how we created and implemented a predictive model in a span of 3 days – something which should excite the data scientists and a few entrepreneurs alike. If you are some one like me – it could be a gold mine!
- This is a nice case study for people looking for applications of data science. We will discuss the challenges in cleaning the data, mining the insights and then implementing them in a fast paced environment.
- The story also gives a peek inside how we work at Analytics Vidhya. This is probably the first time, I am putting it out in the open. So for those of you , who have been following us for some time – you would know what is the back end engine like!

Where it all started?
Less than a week ago, Sunil, Sahil, Manish & I were sitting and sipping our ‘chai’ (Indian white tea) in scorching Delhi heat. A walk to the tea stall after our lunch is almost a part of our daily routine now! Manish took his sip and then looked at Sunil & me with his trademark smile. The look in his eyes told us that he was about to give a suggestion (in form of a question) – this was typical Manish.
Only this time, we would implement and go live with his idea in next 3 days!
The idea:

So, what was the idea? Manish said “We blog awesome articles on analytics and have some of the best experts in our team. Why don’t we create a case study based on the data we have with us?” By the time we walked back to our hack room (i.e. our office), a new idea was already taking shape:
We had more than 17,000 data points and profiles of people in India (including their salaries), whom we have interacted with in last one year. How about using this information to find insights in data science industry?
After a few minutes of huddle / brainstorming at the ‘Gyaan-board’ (the white board), we finalized the idea:
With the data we already have, we will build a web application which could predict the salary of an analytics professional based on a few inputs he / she provides.
Available Data

Our query into the database showed us that there were 17,413 data points with more than 30 variables in total. This data was related to various professionals related to Data science / Big Data / Machine Learning, Business intelligence and other domains.
A closer look into these variables showed us that only about half of the variables were good enough for modelling perspective. This is because we removed all the sensitive data like contact details, Date of birth and variables where more than 30% of information was missing.
The available variables could be classified in following classes:
- Demographics including current city of residence
- Education related – Graduation, post graduation
- Current skill sets – Tools and techniques a person knows
There were some additional variables, we could pull from more sources like the interaction these people had on Analytics Vidhya, their level of involvement in learning based on interactions with us, GitHub profile details, Linkedin profile details. We agreed to use these variables for a later build. For now, we were looking at implementing something quick and see, if our audience loves it.
For those of you, who are thinking that the data was clean and structured, let me warn you! The dataset had a lot of challenges. Here are a few of them, just to provide an overview.
Data Challenges & Solution
- College Category (Tier1 / Other): One of the hypothesis we had was that tier1 college graduates would get better compensation compared to others. We actually thought this would be a very significant variable in the model. However, to accept or to reject this hypothesis, we had to categorise colleges in the buckets – tier1 / others. However, dealing with college names wasn’t easy. To take an example, IIT Bombay was written in following forms: IIT Mumbai, IIT Bombay, Indian institute of Technology Mumbai, IIT (Mumbai), IIT(Bombay), IIT Powai and many other ways. We had to reduce these variations into the right combination taking into account special characters, variations of names and huge number of values.
- Skill (Big Data / Machine Learning / Predictive Modeller / BI ): Skill field was also like a free text. It was actually like a tag cloud stored together. Again, each resume had its own set of collections of skills like machine learning, neural networks, PCA, regression, Qlikview, Tableau, Excel, R, Python, Consultant, Data Analytics, Time Series, CHAID, Factor Analysis, Consulting, Growth strategy and many others. We wanted to map each data point to one and only one type of skill profile. We solved this by using a variety of methods on text mining reading word density, frequency and finally clustering them. We ended up with 7 different type of profiles in our model.
- Treating Missing values and Outliers ( Experience / Salary): Work experience and Salary had missing and outlier values. For example, they salary of a person with 2 – 5 years of experience varied from 0 (probably unemployed / bootstrapping a startup) to 50 Lakhs per annum (damn lucky guy!). We treated the missing values using mean imputation methods (similar case) and it worked well for us. We have also treated outlier values separatly.
Insights
After doing all the data exploration or munging, we used regression tree as a modeling technique. We could have looked at other techniques as well, but regression trees are easy to implement (more on this later) and we could implement them in our wordpress setup without a lot of modifications (Tip: Keep implementation of a project in mind from start). Here are a few insights which came out of the analysis:
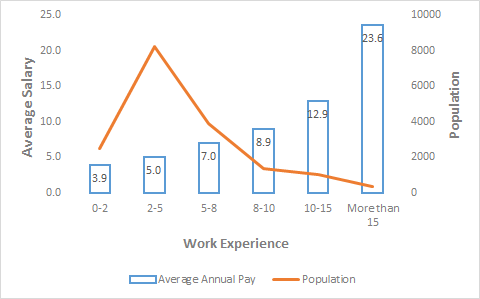
Experience:
As expected, higher experience has higher compensation. But, if you look at the distribution mix of work experience, it also shows the average vintage of this domain is near about ~5 years.
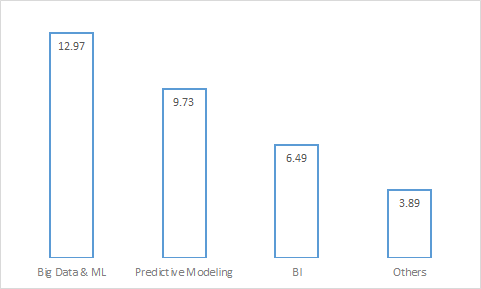
Skills:
Below visualization clearly shows that as you upgrade your skills, better compensation is waiting for you so it’s time to upgrade your skills. You can follow learning path of Python, R, SAS and Qlikview here.
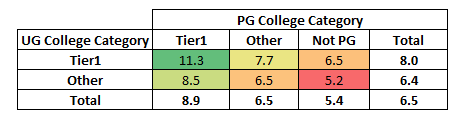
College Type:
Have you graduated from Tier1 colleges? Here is some good news for you. The heat map below shows the willingness of analytics companies to pay premium for talent from Tier 1 institutes.
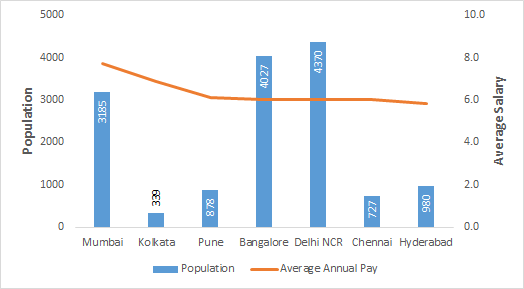
Location:
Mumbai and Kolkata have slightly better compensation compared to other top 5 cities. But, if look at the distribution, it clearly shows the penetration of industries is more in Mumbai, Delhi NCR and Bangalore.
For the die-hard statisticians, some of the graphs above warrant confidence intervals along with these disclaimers. These plots were created to understand the trends rather than reaching conclusions. Also, the sample size was large, so the intervals would be small compared to the variation we are seeing here.
Once we had the decision tree ready, we quickly validated it on a smaller dataset. We found the model to provide right classification in 70% of the cases – not bad given the amount of dirty cuts, we had made in last 1.5 days.
The hustle up to Saturday!
This was Thursday afternoon! We had a basic model ready, we did some tweaks to the model in next half a day, but it was a good draft. We decided that we would make this test live on Saturday morning because a lot of job search happens over the weekend. This meant we had less than 1.5 days for all other preparations. Over the next 36 hours, we did the following:
- Finalized the creatives for landing page, social media campaign and the results
- Created a social media marketing plan
- Made the required additions to our blogging platform
- Implemented the decision tree and tested all the possible cases before go live
Go live and after-effects
Thankfully, we pulled it all together over a few Pizzas and burgers. Our interns extended help for model implementation and to finish all the required testing. The test went live on Saturday morning and reached out to more than 15,000 people over the weekend – not a bad reach for a 3 day hack! We spent most of the Saturday cleaning up the corners we had cut during the process and celebrated the achievement over a movie and dinner in the evening.
This is the fastest turn-around I have done on a predictive model – this is what we love about the start-up life. Here is what our Facebook walls looked like over the weekend:
While Sahil and Manish were unwinding, Sunil & I were conducting a Hackathon – action never stops!
End Notes and Disclosures:
We loved the experience of creating something like Analytics Professional Salary test from scratch in a period of 3 days. It wasn’t easy – there were times, when we thought we are pushing too much, but then we did!
Is the app perfect? The answer is no. Here are some disclosures. I think there are still areas of improvement. I have a hypothesis that the test is under-predicting because the salary data is coming from people who were searching for jobs and low salary could be one of the reasons for the lookout. But even with its limitations, I think we have created a unique, one of its kind app here. I would love to hear your thoughts on what you think about the app and what additional features would you want it to have. Looking forward to it.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Kunal Jain is the Founder and CEO of Analytics Vidhya, one of the world's leading communities of Al professionals. With over 17 years of experience in the field, Kunal has been instrumental in shaping the global Al landscape. His expertise spans diverse markets, from developed economies like the UK to emerging ones like India, where he has successfully led and delivered complex data-driven solutions. As a recognized thought leader, Kunal has empowered countless individuals to realize their Al ambitions through his visionary approach to Al education and community building. Before founding Analytics Vidhya, Kunal earned both his undergraduate and postgraduate degrees from IIT Bombay and held key roles at Capital One and Aviva Life Insurance across multiple geographies. His passion lies at the intersection of analytics, Al, and fostering a thriving community of data science professionals.







Hi Kunal, Within a span of time you guys have developed a very good application of "Analytics Professional Salary Test" . Hats-off to you and your team for the handwork. It is very good to know where we are standing in the Market and what is the Market Value for the professional like us. I wish to good luck to your team and expecting more articles to publish. Everyday I thoroughly enjoying this blog! I just loved it !!! Thanks, Vinayak
Very nicely done. I liked the approach taken to get something meaningful in 3 days. ( Important tip as well : Keeping implementation of a project in mind from start )
Thanks Sanjay
Great work! Enjoyed reading your efforts to create something that you're passionate about. Keep rocking. My suggestion for app is : 1) It would be more engaging if any summary statistics or buckets of salary ranges sorted by cities along with the participant report is included in the final result page of app. He/she can compare quickly with others in his/her city. 2) Suggesting the participant to improve in certain areas like getting a PG degree or earning a skill will get him/her more salary in their city. For example: Congratulations! With skills SAS & R You are earning 4-6 lakhs in Hyderabad. To earn 8 lakhs per anum upgrade your skill set with Python & Qlikview. Ofcourse, No guarantee! It is just a suggestion ;) Or Hey! You are earning 8-10 Lakhs with just a graduation degree from tier 1 college. Great! To earn 15+ we recommend you to earn a PG degree from IBS, Hyd(1 year programme). Would like to hear from you if my suggestions felt stupid :D Regards Aditya