A few days ago, a group of researchers at Google dropped a PDF that didn’t just change AI: it wiped billions of dollars off the stock market.
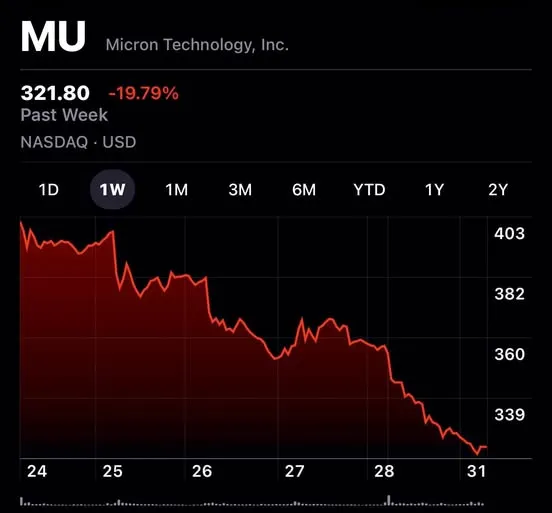
If you looked at the charts for Micron (MU) or Western Digital last week, you saw a sea of Red. Why? Because a new technology called TurboQuant just proved that we might not need nearly as much hardware to run giant AI models as we thought.
But don’t worry about the complex math. Here is the simple breakdown of Google’s latest key-value cache optimization technique TurboQuant.
Table of contents
We introduce a set of advanced theoretically grounded quantization algorithms that enable massive compression for large language models and vector search engines. – Google’s Official Release Note
The Memory Constraint
Think of an AI model like a massive library. Usually, every “book” (data point) is written in high-definition, 4K detail. This takes up a massive amount of shelf space (what techies call VRAM or memory).
The more AI “talks” to you, the more shelf space it needs to remember what happened ten minutes ago. This is why AI hardware is so expensive. Companies like Micron make a fortune because AI models are effectively “storage hogs.”
The Language of AI: Vectors
To understand why this books is so heavy, you have to look at the “ink” used in these books. AI doesn’t see words or images: it sees Vectors.
A vector is essentially a set of coordinates, a string of precise numbers like 0.872632, that tells the AI exactly where a piece of information sits on a massive, multi-dimensional map.
- Simple vectors might describe a single point on a graph.
- High-dimensional vectors capture complex meanings, like the specific “vibe” of a sentence or the features of a human face.
High-dimensional vectors are highly effective, but they demand significant memory, creating bottlenecks in the key-value cache. In transformer models, the KV cache stores past tokens’ key and value vectors so the model doesn’t recompute attention from scratch every time.
The Solution: Vector Quantization
To fight the memory bloat, engineers use a move called Vector Quantization. If the coordinates are too long, we simply “shave” the ends off to save space.
Imagine you have a list of n-dimensional vectors:
- 0.872632982
- 0.192934356
- 0.445821930
That’s a lot of data to store. To save space, we “quantize” them by shaving off the ends:
- 0.872632982 → 0.87
- 0.192934356 → 0.19
- 0.445821930 → 0.44
* The rounding demonstrated is scaler rounding. In practice, vectors are grouped and mapped to a smaller set of representative values, not just individually rounded.
This is reducing coefficient precision or shaving. This can be carried out using methods such as rounding-to-n digits, adaptive thresholding, calibrated predictions thresholding, Least Significant Bit (LSB).
This optimization step has two advantages:
- Enhanced Vector Search: It powers large AI by enabling high-speed similarity lookups, making search engines and retrieval systems significantly faster.
- Unclogged KV Cache Bottlenecks: By reducing the size of key-value pairs, it lowers memory costs and accelerates similarity searches within the cache, which is vital for scaling model performance.
When Vector Quantization Fails?
This process has a hidden cost: full-precision quantization constants (a scale and a zero point) must be stored for every block. This storage is essential so the AI can later “unshave” or de-quantize the data. This adds 1 or 2 extra bits per number, which can eat up to 50% of your intended savings. Because every block needs its own scale and offset, you’re not just storing data but also storing the instructions for decoding it.
The solution reduces memory at the cost of accuracy. TurboQuant changes that tradeoff.
TurboQuant: Compression without Caveats
Google’s TurboQuant is a compression method that achieves a high reduction in model size with low accuracy loss by fundamentally changing how the AI perceives the vector space. Instead of just shaving off numbers and hoping for the best, it uses a two-stage mathematical pipeline to make any data fit a high-efficiency grid perfectly.
Stage 1: The Random Rotation (PolarQuant)
Standard quantization fails because real-world data is messy and unpredictable. To stay accurate, you’re forced to store “scale” and “zero point” instructions for every block of data.
TurboQuant solves this by first applying a random rotation (or random preconditioning) to the input vectors. This rotation forces the data into a predictable, concentrated distribution (specifically Polar coordinates) regardless of what the original data looked like. A random rotation spreads information evenly across dimensions, smoothing out spikes and making the data behave more uniformly.
- The Benefit: Because the distribution is now mathematically “flat” and predictable, the AI can apply optimal rounding to every coordinate without needing to store those extra “scale and zero” constants.
- The Result: You bypass the normalization step entirely, achieving massive memory savings with zero overhead.
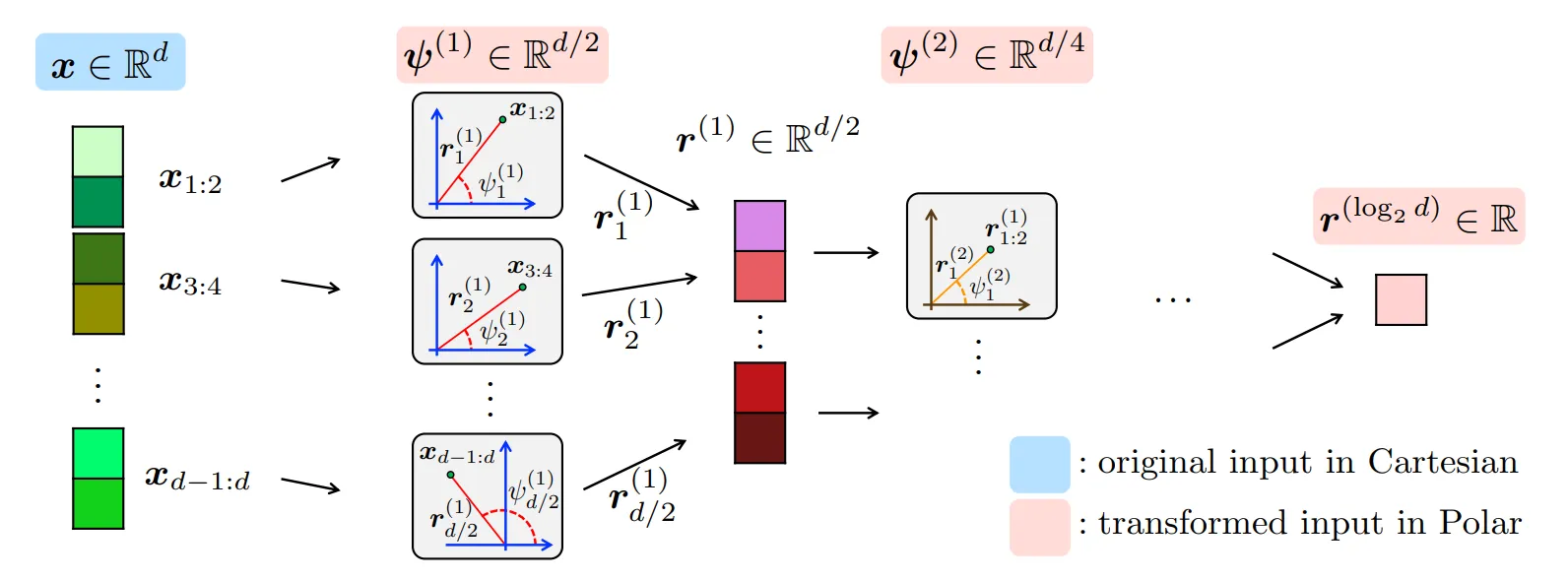
To learn more about the PolarQuant method refer: arXiv
Stage 2: The 1-Bit “Residual” Fix (Quantized JL)
Even with a perfect rotation, simple rounding introduces bias. Tiny mathematical errors that lean in one direction. Over time, these errors accumulate, causing the AI to lose its “train of thought” or hallucinate. TurboQuant fixes this using Quantized Johnson-Lindenstrauss (QJL).
- The Residual: It isolates the “leftover” error (the residual) that was lost during the first stage of rounding.
- The 1-Bit Sign: It quantizes this error to a single bit (the sign bit, either +1 or -1).
- The Math: This 1-bit check serves as an “unbiased estimator,” meaning across many operations, the tiny directional hints (1-Bit Sign) statistically cancel out the bias.
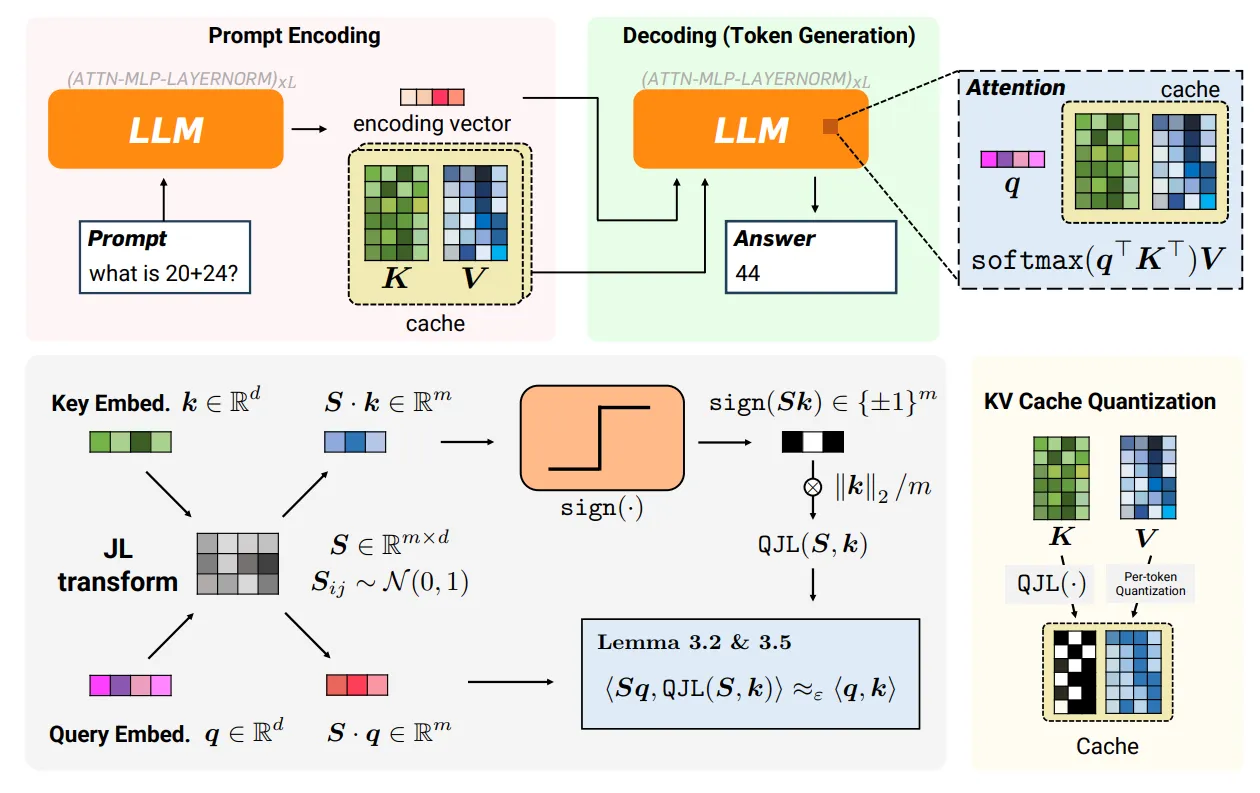
To learn more about the QJL method refer: arXiv
PolarQuant and QJL are used in TurboQuant for reducing key-value bottlenecks without sacrificing AI model performance.
| Method | Memory | Accuracy | Overhead |
| Standard KV cache | High | Perfect | None |
| Quantization | Lower | Slight loss | High (metadata) |
| TurboQuant | Much lower | Near-perfect | Minimal |
The Performance Reality
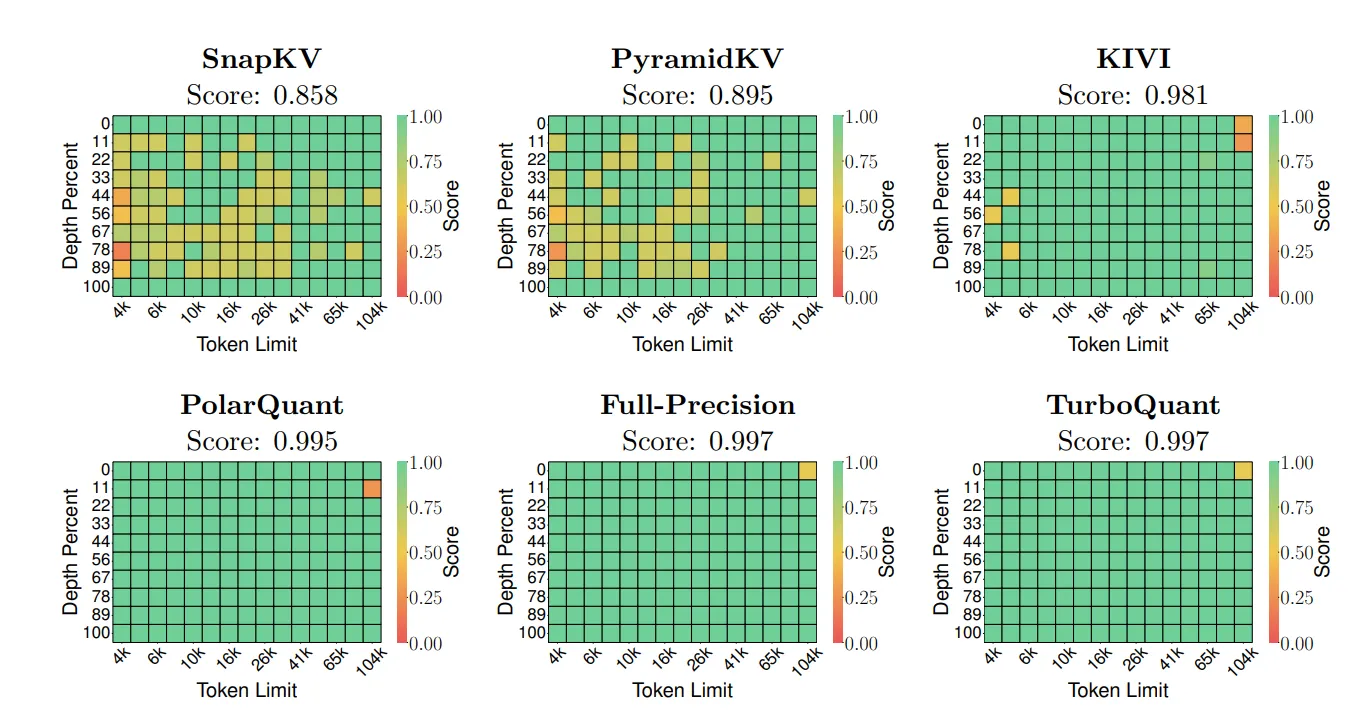
By removing the metadata tax and fixing the rounding bias, TurboQuant delivers a “best of both worlds” result for high-speed AI systems:
- Quality Neutrality: In testing with models like Llama-3.1, TurboQuant achieved the same exact performance as the full-precision model while compressing the memory by a factor of 4x to 5x.
- Instant Search: In nearest-neighbor search tasks, it outperforms existing techniques while reducing “indexing time” (the time needed to prepare the data) to virtually zero.
- Hardware Friendly: The entire algorithm is designed for vectorization, meaning it can run in parallel on modern GPUs with a lightweight footprint.
The Reality: Beyond the Research Paper
The true impact of TurboQuant isn’t just measured in citations, but in how it reshapes the global economy and the physical hardware in our pockets.
1. Breaking the “Memory Wall”
For years, the “Memory Wall” was the single greatest threat to AI progress. As models grew, they required an huge amount of RAM and storage, making AI hardware prohibitively expensive and keeping powerful models locked in the cloud.
When TurboQuant was unveiled, it fundamentally changed that math:
- The Semiconductor Shift: The announcement of TurboQuant optimization sent shockwaves through the storage industry. AI can suddenly become 6x more memory-efficient, the frantic demand for physical RAM will cool down.
- From Cloud to Consumer: By shrinking the “digital cheat sheet” of AI (the KV cache) down to just 3 bits per value, TurboQuant effectively “unclogged” the hardware bottleneck. This moved sophisticated AI from massive server farms to 16GB consumer devices like the Mac Mini, enabling high-performance LLMs to run locally and privately.
2. A New Standard for Global Scale
TurboQuant proved that the future of AI isn’t just about building bigger libraries, but about inventing a more efficient “ink.”
- The “Invisible” Infrastructure: Unlike previous research that required complex retraining, TurboQuant was designed to be data-oblivious. It could be dropped into any existing transformer model (like Google Gemini) to immediately slash costs and energy consumption.
- Democratizing Intelligence: This efficiency provided the bridge for AI to scale to the new users. In mobile-first markets, it turned the dream of a fully capable, on-device AI assistant into a battery-friendly reality. Your next phone might run GPT-level AI locally!
Ultimately, TurboQuant marks the moment when AI efficiency became as critical as raw compute power. It is no longer just a “scoring sheet” achievement. It is the invisible scaffolding that allows the next generation of semantic search and autonomous agents to function at a global, human scale.
TurboQuant: Future Outlook
For years, scaling AI meant throwing more hardware at the problem: more GPUs, more memory, more cost. TurboQuant challenges that belief.
Instead of expanding outward, it focuses on using what we already have more intelligently. By reducing the memory burden without heavily compromising performance, it changes how we think about building and running large models.
Frequently Asked Questions
Q1. What is TurboQuant in AI?
A. TurboQuant is an AI memory optimization technique that reduces RAM usage by compressing KV cache data with minimal impact on performance.
Q2. How does TurboQuant reduce RAM usage?
A. It uses random rotation and efficient quantization to compress vectors, eliminating extra metadata and reducing memory required for AI models.
Q3. Does TurboQuant replace the need for high storage in AI?
A. Not entirely, but it significantly lowers storage requirements, making large models more efficient and easier to run on smaller hardware.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






