Large Language Models (LLMs) are the heart of Agentic systems and RAG systems. And building with LLMs is exciting until the scale makes them expensive. There is always a tradeoff for cost vs quality, but in this article we will explore the 10 best ways according to me that can slash costs for the LLM usage while focusing on maintaining the quality of the system. Also note I’ll be using OpenAI API for the inference but the techniques could be applied to other model providers as well. So without any further ado let’s understand the cost equation and see ways of LLM cost optimization.
Table of contents
- Prerequisite: Understanding the Cost Equation
- Route Requests to the Right Model
- Use Models according to the task
- Using Prompt Caching
- Use the Batch API for Tasks that can wait
- Trim the Outputs with max_tokens and Stops parameters
- Make Use of RAG
- Always Manage the Conversation History
- Upgrade to Efficient Model Modes
- Enforce Structured Outputs (JSON)
- Cache Queries
- Conclusion
- Frequently Asked Questions
Prerequisite: Understanding the Cost Equation
Before we start, it’s better we get better versed with about costs, tokens and context window:
- Tokens: These are the small units of the text. For all practical purposes you can assume 1,000 tokens is roughly 750 words.
- Prompt Tokens: These are the input tokens that we send to the model. They are generally cheaper.
- Completion Tokens: These are the tokens generated by the model. They are often 3-4 times more expensive than input tokens.
- Context Window: This is like a short-term memory (It can include the old Inputs + Outputs). If you exceed this limit, the model leaves out the earlier parts of the conversation. If you send 10 previous messages in the context window, then those count as Input Tokens for the current request and will add to the costs.
- Total Cost: (Input Tokens x Per Input Token Cost) + (Output Tokens x Per Output Token Cost)
Note: For OpenAI you can use the billing dashboard to track costs: https://platform.openai.com/settings/organization/billing/overview
To learn how to get the OpenAI API read this article.
1. Route Requests to the Right Model
Not every task requires the best, state-of-the-art model, you can experiment with a cheaper model or try using a few-shot prompting with a cheaper model to replicate a bigger model.
Configure the API key
from google.colab import userdata
import os
os.environ['OPENAI_API_KEY']=userdata.get('OPENAI_API_KEY') Define the functions
from openai import OpenAI
client = OpenAI()
SYSTEM_PROMPT = "You are a concise, helpful assistant. You answer in 25-30 words"
def generate_examples(questions, n=3):
examples = []
for q in questions[:n]:
response = client.chat.completions.create(
model="gpt-5.1",
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": q}]
)
examples.append({"q": q, "a": response.choices[0].message.content})
return examplesThis function uses the larger GPT-5.1 and answers the question in 25-30 words.
# Example usage
questions = [
"What is overfitting?",
"What is a confusion matrix?",
"What is gradient descent?"
]
few_shot = generate_examples(questions, n=3)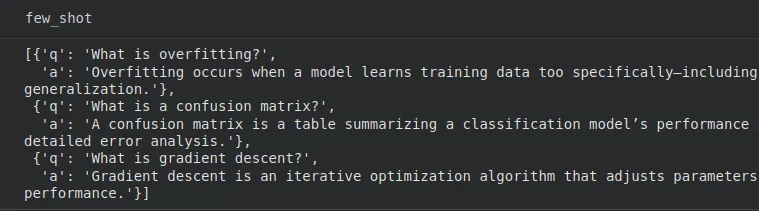
Great, we got our question-answer pairs.
def build_prompt(examples, question):
prompt = ""
for ex in examples:
prompt += f"Q: {ex['q']}\nA: {ex['a']}\n\n"
return prompt + f"Q: {question}\nA:"
def ask_small_model(examples, question):
prompt = build_prompt(examples, question)
response = client.chat.completions.create(
model="gpt-5-nano",
messages=[{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt}]
)
return response.choices[0].message.contentHere, we have a function that uses smaller ‘gpt-5-nano’ and another function that makes the prompt using the question-answer pairs for the model.
answer = ask_small_model(few_shot, "Explain regularization in ML.")
print(answer)Let’s pass a question to the model.
Output:
Regularization adds a penalty to the loss for model complexity to reduce overfitting. Common forms include L1 (lasso) promoting sparsity and L2 (ridge) shrinking weights; elastic net blends.
Great! We have used a much cheaper model (gpt-5-nano) to get our output, but surely we can’t use the cheaper model for every task.
2. Use Models according to the task
The idea here is to use a smaller model for routine tasks, and using the larger models only for complex reasoning. So how do we do this? Here we will define a classifier that returns “simple” or “complex” and route the queries accordingly. This is help us save costs on routine costs.
Example:
from openai import OpenAI
client = OpenAI()
def get_complexity(question):
prompt = f"Rate the complexity of the question from 1 to 10 for an LLM to answer. Provide only the number.\nQuestion: {question}"
res = client.chat.completions.create(
model="gpt-5.1",
messages=[{"role": "user", "content": prompt}],
)
return int(res.choices[0].message.content.strip())
print(get_complexity("Explain convolutional neural networks"))Output:
4
So our classifier says the complexity is 4, don’t worry about the extra LLM call as this is generating only a single number. This complexity number can be used to route the tasks, like: complexity < 7 then route to a smaller model, else a larger model.
3. Using Prompt Caching
If the LLM-system uses bulky system instructions or lots of few-shot examples across many calls, then make sure to place them at the start of your message.
Few important points here:
- Ensure the prefix is exactly identical across requests (including all the characters, whitespace included).
- According to OpenAI the supported models will automatically benefit from Caching but the prompt has to be longer than 1,024 tokens.
- Requests using Prompt Caching have a
cached_tokensvalue as a part of the response.
4. Use the Batch API for Tasks that can wait
Many tasks don’t require immediate responses, this is where we can use the asynchronous Batch endpoint for the inference. By submitting a file of requests and giving OpenAI upto 24 hours time to process them, will reduce 50% costs on token costs compared to the usual OpenAI API calls.
5. Trim the Outputs with max_tokens and Stops parameters
What we’re trying to do here is stop the untrolled token generation, Let’s say you need a 75-word summary or a specific JSON object, don’t let the model keep generating unnecessary text. Instead we can make use of the parameters:
Example:
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{
"role": "system",
"content": "You are a data extractor. Output only raw JSON."
}
],
max_tokens=100,
stop=["\n\n", "}"]
)We have set max_tokens as 100 as it’s roughly 75 words.
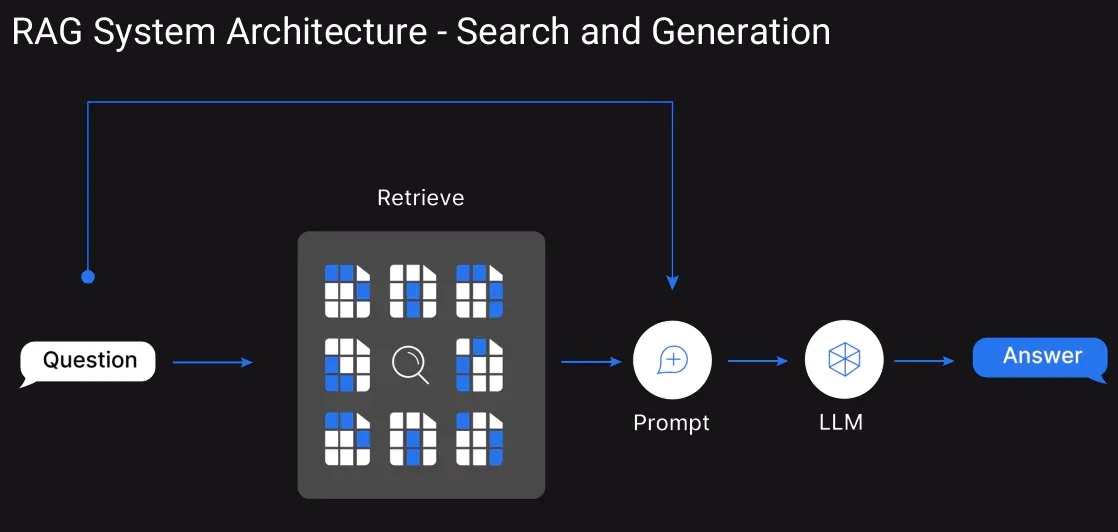
6. Make Use of RAG
Instead of flooding the context window, we can use Retrieval-Augmented Generation. This will help convert the knowledge base into embeddings and store them in a vector database. When a user queries, then all the context won’t be in the context window but the retrieved top few relevant text chunks will be passed for context.
7. Always Manage the Conversation History
Here our focus is on the conversation history where we pass the older inputs and outputs. Instead of iteratively adding the conversations we can implement a “sliding window” approach.
Here we drop the oldest messages once the context gets too long (set a threshold), or summarize previous turns into a single system message before continuing. Ensure that the active context window is not too long as it’s crucial for long-running sessions.
Function for summarization
from openai import OpenAI
client = OpenAI()
SYSTEM_PROMPT = "You are a concise assistant. Summarize the chat history in 30-40 words."
def summarize_chat(history_text):
response = client.chat.completions.create(
model="gpt-5.1",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": history_text}
]
)
return response.choices[0].message.contentInference
chat_history = """
User: Hi, I'm trying to understand how embeddings work.
Assistant: Embeddings turn text into numeric vectors.
User: Can I use them for similarity search?
Assistant: Yes, that’s a common use case.
User: Nice, show me simple code.
Assistant: Sure, here's a short example...
"""
summary = summarize_chat(chat_history)User asked what embeddings are; assistant explained they convert text to numeric vectors. User then asked about using embeddings for similarity search; assistant confirmed and provided a short example code snippet demonstrating basic similarity search.
We now have a summary which can be added to the model’s context window when the input tokens are above a defined threshold.
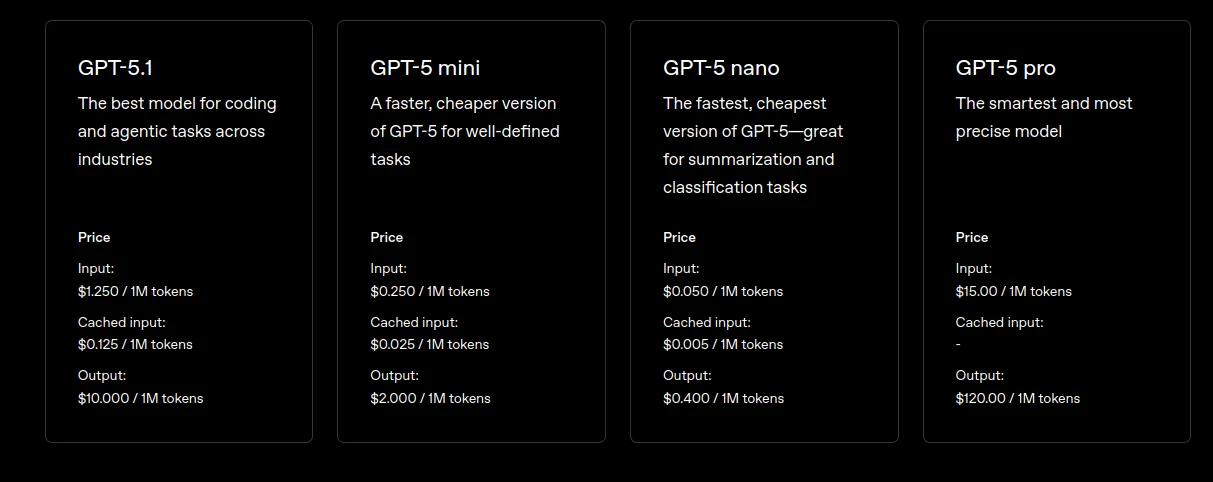
8. Upgrade to Efficient Model Modes
OpenAI frequently releases optimized versions of their models. Always check for newer “Mini,” or “Nano” variants of the latest models. These are specifically made for efficiency, often delivering similar performance for certain tasks at a fraction of the cost.
9. Enforce Structured Outputs (JSON)
When you need data extracted or formatted. Defining a strict schema forces the model to cut the unnecessary tokens and returns only the exact data fields requested. Denser responses mean fewer generated tokens on your bill.
Imports and Structure Definition
from openai import OpenAI
import json
client = OpenAI()
prompt = """
You are an extraction engine. Output ONLY valid JSON.
No explanations. No natural language. No extra keys.
Extract these fields:
- title (string)
- date (string, format: YYYY-MM-DD)
- entities (array of strings)
Text:
"On 2025-12-05, OpenAI introduced Structured Outputs, allowing developers to enforce strict JSON schemas. This improved reliability was welcomed by many engineers."
Return JSON in this exact format:
{
"title": "",
"date": "",
"entities": []
}
"""Inference
response = client.chat.completions.create(
model="gpt-5.1",
messages=[{"role": "user", "content": prompt}]
)
data = response.choices[0].message.content
json_data = json.loads(data)
print(json_data)Output:
{'title': 'OpenAI Introduces Structured Outputs', 'date': '2025-12-05', 'entities': ['OpenAI', 'Structured Outputs', 'JSON', 'developers', 'engineers']}
As we can see only the required dictionary with the required details is returned. Also the output is neatly structured as key-value pairs.
10. Cache Queries
Unlike our earlier idea of caching, this is quite different. If the users frequently ask the exact same questions, cache the LLM’s response in your own database. Check this database before calling the API. This cached response is faster for the user and is practically free. Also if working with LangGraph for Agents then you can explore this for Node-level-caching: Caching in LangGraph
Conclusion
Building with LLMs is powerful but the scale can quickly make them expensive, so understanding the cost equation becomes essential.By applying the right mix of model routing, caching, structured outputs, RAG, and efficient context management, we can significantly slash inference costs. These techniques help maintain the quality of the system while ensuring the overall LLM usage remains practical and cost-effective. Don’t forget to take check the billing dashboard for the costs after implementing each technique.
Frequently Asked Questions
Q1. What is a token in the context of LLMs?
A. A token is a small unit of text, where roughly 1,000 tokens correspond to about 750 words.
Q2. Why are completion tokens more costly than prompt tokens?
A. Because output tokens (from the model) are often several times more expensive per token than input (prompt) tokens.
Q3. What is the “context window” and why does it matter for cost?
A. The context window is the short-term memory (previous inputs and outputs) sent to the model; a longer context increases token usage and thus cost.
Passionate about technology and innovation, a graduate of Vellore Institute of Technology. Currently working as a Data Science Trainee, focusing on Data Science. Deeply interested in Deep Learning and Generative AI, eager to explore cutting-edge techniques to solve complex problems and create impactful solutions.






