Introduction
Data mining, a crucial aspect of the data science realm, involves uncovering hidden insights and patterns within datasets to extract valuable information. This article serves as a comprehensive guide to understanding the fundamental concepts, tasks, applications, and tools associated with data mining. From basic data mining tasks like classification and prediction to exploring advanced algorithms and real-life applications, this overview aims to provide insights into the diverse facets of data mining.
This article was published as a part of the Data Science Blogathon.
Table of contents
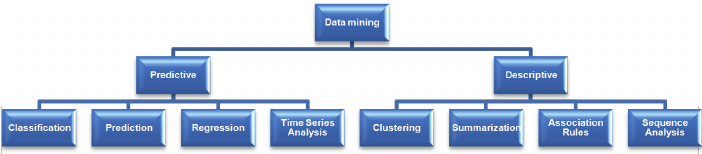
What is Data Mining
“Data Mining”, that mines the data. In simple words, it is defined as finding hidden insights(information) from the database, extract patterns from the data.
There are different algorithms for different tasks. The function of these algorithms is to fit the model. These algorithms identify the characteristics of data. There are 2 types of models.
Predictive model
A predictive model is a statistical or machine learning model that is designed to predict future outcomes or behaviors based on historical data. These models analyze patterns and relationships within the data to make predictions about unseen or future instances. Predictive models are commonly used in various fields such as finance, marketing, healthcare, and weather forecasting. They aim to forecast trends, identify potential risks, or make informed decisions based on the insights gained from the data.
Descriptive model
A descriptive model is used to summarize and describe the characteristics of a dataset. Unlike predictive models, descriptive models focus on understanding and explaining the existing data rather than making predictions about future outcomes. These models aim to uncover patterns, relationships, and insights within the data to gain a better understanding of the underlying structure or behavior. Descriptive models are often used for exploratory data analysis, reporting, and visualization purposes to communicate insights to stakeholders effectively.
Benefits of Data Mining
Key benefits of data mining:
- Improved Decision Making: Data mining helps businesses make informed decisions by providing valuable insights and predictions. For example, a retail store can use data mining to understand which products are often bought together and use this information to optimize product placement.
- Enhanced Customer Engagement: By understanding customer behavior and preferences, businesses can tailor their services to meet customer needs, leading to improved customer satisfaction and loyalty.
- Efficient Operations: Data mining can help identify inefficiencies in a business process. For instance, a manufacturing company can use data mining to detect bottlenecks in their production process and take corrective action.
- Risk Management: Data mining can help businesses identify potential risks and take preventive measures. For example, banks can use data mining to predict the likelihood of a customer defaulting on a loan.
- New Opportunities: Data mining can uncover hidden patterns and trends that can lead to new business opportunities. For instance, a streaming service can use data mining to identify popular genres and invest in creating content in those genres.
Data Mining Tools
Data miners need tools to extract, transform, and analyze data. Here are some popular data mining tools:
- RapidMiner: Think of RapidMiner as a Swiss Army knife for data mining. It’s a versatile tool that can handle data preprocessing, machine learning, and predictive modeling. It’s user-friendly with a drag-and-drop interface, making it a great choice for beginners.
- Weka: Weka is like the old reliable friend in the world of data mining. It’s been around for a while and has a comprehensive collection of data preprocessing and modeling techniques. It’s open-source and easy to use, making it popular in academia and industry alike.
- Orange: Orange is a bit like a box of Lego blocks – it allows you to visually build data workflows. It’s great for exploratory data analysis and has a range of machine learning algorithms. Plus, it’s open-source!
- KNIME: KNIME is like a high-tech conveyor belt for your data. It allows you to visually design data workflows and has a vast array of features for data blending, machine learning, and reporting.
- Python and R: Python and R are like the superheroes of data mining. They are programming languages that have powerful libraries (like pandas, scikit-learn, ggplot) for data mining tasks. They are highly flexible and powerful, but require programming knowledge.
Basic Data Mining Tasks
Under this section, we are going to see some of the mining functions/tasks.
Classification
This term comes under supervised learning. Classification algorithms require that the classes should be defined based on variables. Characteristics of data define which class belongs to. Pattern recognition is one of the types of classification problems in which input(pattern) is classified into different classes based on its similarity of defined classes.
Prediction
In real life, we often see predicting future things/values/or else based on past data and present data. Prediction is also a type of classification task. According to the type of application, for example, predicting flood where dependant variables are the water level of the river, its humidity, raining scale, and so on are the attributes.
Regression
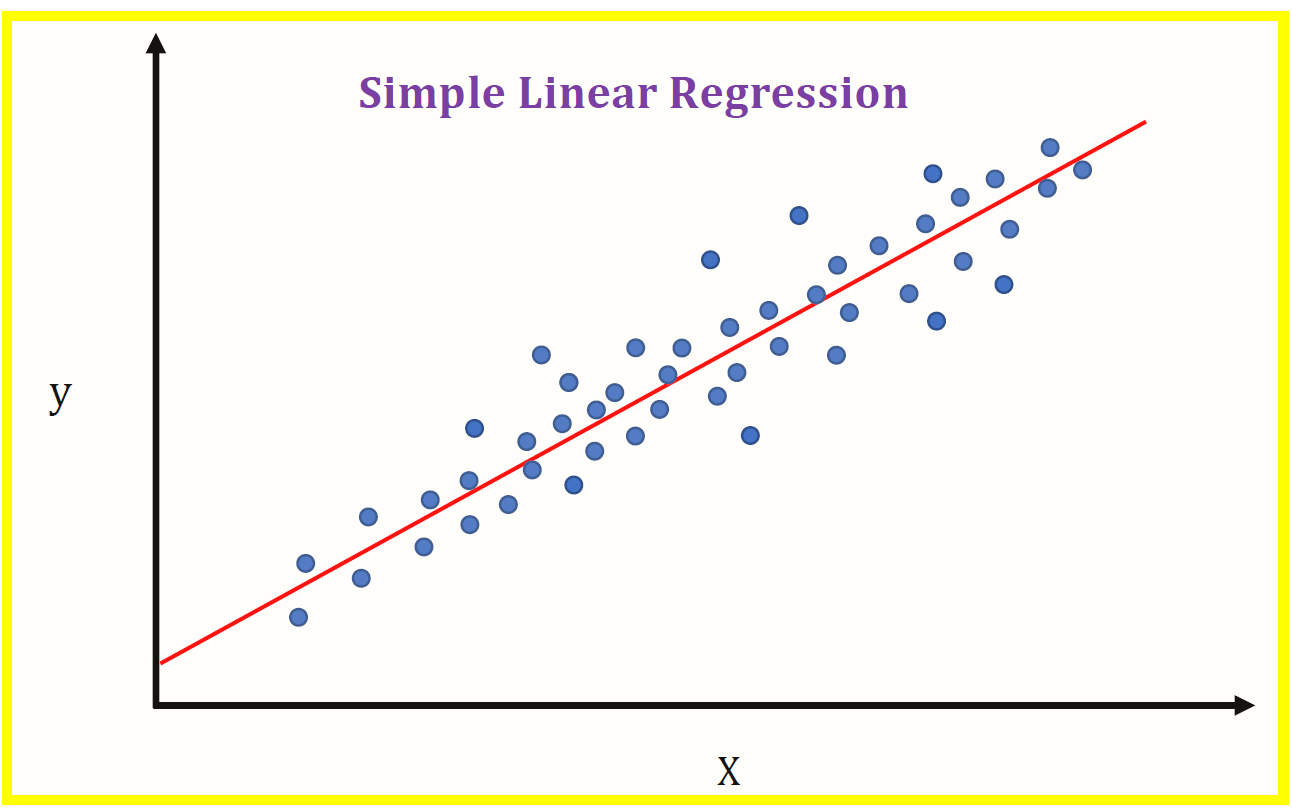
Regression is a statistical technique that is used to determine the relationship between variables(x) and dependant variables(y). There are few types of regression as Linear, Logistic, etc. Linear Regression is used in continuous values(0,1,1.5,….so on) and Logistic Regression is used where there is the possibility of only two events such as pass/fail, true/false, yes/no, etc.
Time Series Analysis
In time series analysis, a variable changes its value according to time. It means analysis goes under the identifying patterns of data over a period of time. It can be seasonal variation, irregular variation, secular trend, and cyclical fluctuation. For example, annual rainfall, stock market price, etc.
Clustering
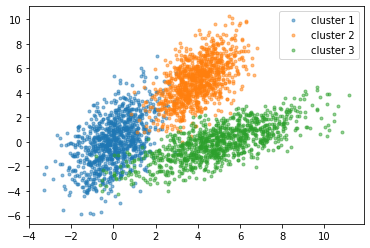
Clustering is the same as classification i.e it groups the data. Clustering comes under unsupervised machine learning. It is a process of partitioning the data into groups based on similar kinds of data.
Summarization
Summarization is nothing but characterization or generalization. It retrieves meaningful information from data. It also gives a summary of numeric variables such as mean, mode, median, etc.
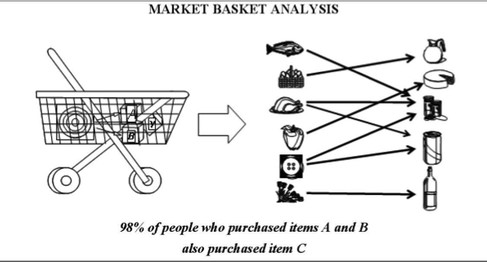
Association Rules
It’s the main task of Mining. It helps in finding appropriate patterns and meaningful insights from the database. Association Rule is a model which extracts types of data associations. For example, Market Basket Analysis where association rules are applied to the database to know that which items are purchased together by the customer.
Sequence Discovery
It is also called sequential analysis. It is used to discover or find the sequential pattern in data.
Sequential Pattern means the pattern which is purely based on a sequence of time. These patterns are similar to found association rules in database or events are related but its relationship is based only on “Time”.
Up to this point, we have seen all the basic functions or tasks of Mining. Let’s go-ahead to know more about Data Mining…
Data Mining VS KDD(Knowledge Discovery in Database)
Data Mining: Process of use of algorithms to extract meaningful information and patterns derived from the KDD process. It is a step involved in KDD.
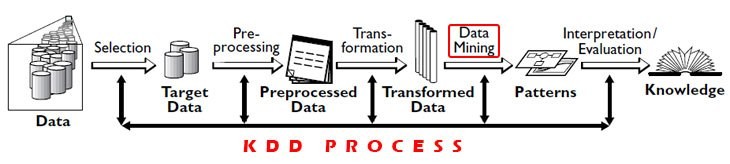
KDD: It is a significant process of identifying meaningful information and patterns in Data. The input is given to this process is data and output gives useful information from data.
KDD process consists 5 steps:
1)Selection: Need to obtain data from various data sources, databases.
2)Preprocessing: This process of cleaning data in terms of any incorrect data, missing values, erroneous data.
3)Transformation: Data from various sources must be converted, encoded into some format for preprocessing.
4)Data Mining: In this process, algorithms are applied to transformed data to achieve desired output/results.
5)Interpretation/evaluation: Has to perform some visualizations to present data mining results which are very important.
Data Mining Applications
E-Commerce
E-commerce is one of the real-life applications of it. E-commerce companies are like Amazon, Flipkart, Myntra, etc. They use mining techniques to see the functionality of every product in such a way that “which product is viewed most by the customer also what they also liked other”.
Retailing
It is another application from the retail market. Retailers find the pattern of “Freshness, Frequency, Monetary(In terms of Currency)”. Retailers keep the track of sales of products, transactions.
Education
Education is an emerging, trending field nowadays. It concerns knowledge discovery from educational data. The main goal of this application is to study or identify the student’s behavior pattern in terms of future learning, effects of study, advanced knowledge of learning, etc. These data mining techniques are used by institutions to take accurate decisions and also predict appropriate results.
Data Mining Algorithms
- K-means clustering
- Support vector machines
- Apriori
- KNN
- Naive Bayes
- CART and many more…
These are few algorithms.
Now I am going to give you information about the required libraries below.
Apriori:
from apyori import aprioriK-means clustering:
from kneed import KneeLocator
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScalerSupport Vector Machines:
from sklearn import svmNaive Bayes:
from sklearn.naive_bayes import GaussianNBCART:
from sklearn.tree import DecisionTreeRegressorKNN:
from
sklearn.neighbors
import
KNeighborsClassifierSo here are few libraries that to be installed while performing the algorithm.
Conclusion
Data mining plays a pivotal role in modern data-driven decision-making processes across various industries. By leveraging predictive and descriptive models, enables organizations to derive actionable insights from vast amounts of data, driving strategic decision-making and enhancing operational efficiency. With a basic understanding of Python and database concepts, individuals can explore the vast landscape of data mining, employing algorithms and tools to extract valuable knowledge from datasets. As data continues to proliferate, remains a vital tool for unlocking the hidden potential within data, empowering organizations to gain a competitive edge in today’s data-driven world.
Frequently Asked Questions
Q1. What is the difference between data mining and machine learning?
A. Data mining primarily focuses on extracting patterns and insights from existing datasets, often using statistical techniques and algorithms. Machine learning, on the other hand, involves the development of algorithms that enable computers to learn from data and make predictions or decisions without being explicitly programmed.
Q2. What are some popular tools used for data mining?
A. Some popular tools for data mining include KNIME, WEKA, and ORANGE. These tools provide a user-friendly interface and a wide range of functionalities for tasks such as data preprocessing, modeling, and visualization, making them valuable assets for data analysts and scientists.
Q3. How can data mining be applied in real-world scenarios?
A.Finds applications in various domains such as e-commerce, retailing, healthcare, and education. For example, e-commerce companies utilize data mining techniques to analyze customer behavior, recommend products, and optimize marketing strategies. In healthcare, data mining helps identify patterns in patient data for disease diagnosis and treatment planning. These real-world applications highlight the versatility and importance of data mining in today’s data-driven society.
Amruta Kadlaskar
01 Mar, 2024
I am data science enthusiastic, tech savvy and traveller.







