What is process mining?
The term process mining is a methodology used to discover, monitor, and improve processes that already exist within a business by relying on data. The goal of using process mining is to explore where existing business processes are inefficient and address those critical areas. Unfortunately for many businesses, this consideration is usually given a low priority.
Process mining provides a solution that’s elegant in its implementation. Anyone who wants to explore process flows or oversee complex business processes would appreciate the improvements that process mining provides. The techniques are improved by aggregating data and taking feedback into account. The result is a more efficient process that’s building on its past successes. Further Process mining provides visualizations and other output that give a full picture of any bottlenecks, inefficiencies, or gaps the organization’s processes have and sheds light on where to improve.
Why is Process improvement important?
There have been different process improvement approaches for a long time. Since then, businesses have been looking for ways to increase their quality and reduce their costs. Compared to the past, process improvement is more important today due to the following reasons:
- Today’s customers have higher expectations of the quality
- Higher competition in the market
- Unpredictable economic environment
Application areas of Process Mining
Process Mining can be applied in different sectors, mentioned few application areas where process mining is implemented
– > Manufacturing
-> Services
-> Health Care
-> Audit & Banking
-> Telecommunications
->Consumer Goods
->Educational/Research etc.
Process mining consists of two important aspects.
1) Event
2) Log
An event refers to a case or, an activity and Logs are additional information about events.
Process Mining capabilities
Process Mining mainly consists of
- Process Discovery
- Conformance
- Enhancement
Process Discovery:
Process Discovery identifies the business processes, maps and analyzes an organization’s existing business processes, uncovers the process steps that they are not aware of, and realizes process deviations. A discovery technique takes an event log and produces a process model without using any prior information.
Process Discovery follows below steps
-
It identifies as-is processes
-
It identifies process deviations
Conformance:
Conformance checking is a technique to compare a process model with an event log of the same process. The goal is to check if the event log conforms to the model and vice versa.
Conformance follows below steps
-
Analyzes the share(data) of non-conformant cases
-
Identifies the root causes
Enhancement:
The idea is to extend or improve an existing process model using information about the actual process recorded in the event log. This process has the capability aims at changing or extending the existing model.
Enhancement follows below steps
-
Identifying process bottlenecks
-
Suggestions for improvement
PM4py
PM4Py is a python library that supports process mining algorithms in python. It is completely open-source and intended to be used in industrial projects.
The following command is for the installation of the Library.
!pip install pm4py
Loading the data
Now let’s load data in CSV format, But the recommended data format for event logs is XES(EXtensible Event Stream)
process_csv = pd.read_csv("E:\Process_Mining\sepsis_df.csv", encoding='cp1252')
Display the data
process_csv.head()
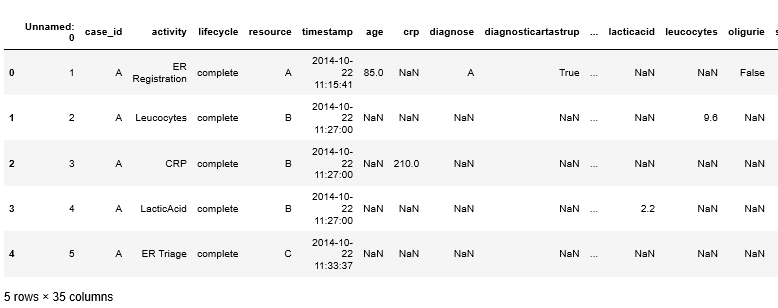
Source: Image made by Author
To carry out process discovery, the dataset must contain the are case ID, the description of an activity, and timestamp.
The case ID is a unique identifier referring to a single instance.
The activity describes an action that has been performed.
The timestamp describes the specific time the activity has been performed and determining the order of events.
Regarding current data the features are
- Case ID : “case_id”
- Activity : “Concept: name”
- Time Stamp: “timestamp”
Before developing a process model, we need to convert features, below is the code:
parameters = {constants.PARAMETER_CONSTANT_CASEID_KEY:CASEID_GLUE , constants.PARAMETER_CONSTANT_ACTIVITY_KEY:ACTIVITY_KEY }
Now we need to convert the CSV file to Event Log format below code is to convert :
event_log = log_converter.apply(process_csv, parameters=parameters)
print(event_log)

Source: Image made by Author
Process Discovery
Process discovery automatically creates a business process representation after collecting and analyzing the data available in systems. The process model is generated using different events/activities.
Below are the different process discovery Algorithms
1) Alpha Miner
2) Inductive Miner
3) Heuristic Miner
4) Directly-Follows Graph
Alpha Miner:
Alpha Miner is the first algorithm that bridges the gap between event logs or observed data and the discovery of a process model. Alpha Miner can build process models in the form of Petri Net without using additional knowledge.
Running Alpha Miner results in the following:
- A Petri net model in which all the transitions are visible, unique, and correspond to the classified events.
- The initial marking — Describes the status of the Petri net model when the execution starts.
- The final marking — Describes the status of the Petri net model when the execution ends.
The execution of the process starts from the events included in the initial marking and finishes at the events included in the final marking.
Some of the characteristics of the algorithm:
- It cannot handle loops of length one or two.
- Invisible and duplicated tasks cannot be discovered.
- It does not handle noise well.
Inductive Miner:
Inductive miner models usually make extensive use of hidden transitions, especially for skipping/looping on a portion of the model. The fundamental idea of the algorithm is to find a prominent split in the event log (there are different types of splits: sequential, parallel, concurrent, and loop). After finding the split, the algorithm recurs on the sub-logs (found by applying the split) until a base case is identified.
The Inductive Miner does not work on Petri nets but on process trees (we can convert them to Petri nets)
Heuristics Miner:
Heuristics Miner is an algorithm that acts on the Directly-Follows Graph, providing a way to handle noise and find common constructs. The output of the Heuristics Miner is a Heuristics Net, so an object that contains the activities and the relationships between them. The Heuristics Net can convert into a Petri net.
To apply Heuristics Miner to discover a Heuristics Net, it is necessary to import a log. Then a Heuristic Net can be found.
Some of the characteristics of the algorithm:
- Takes frequency into account
- Detects short loops and skipping events
- Does not guarantee that the discovered model will be sound
Directly-Follows graphs:
Directly-Follows graphs are graphs where the nodes represent the events in the log and directed edges are present between nodes if there is at least a trace in the log where the source event is followed by the target event.
These directed edges work nicely together with some additional metrics, such as:
- Frequency — The number of times the source event is followed by the target event.
- Performance — some kind of aggregation, for example, the average time elapsed between the two events.
Here we will confine ourselves to Alpha Miner Model
Import the Library
from pm4py.algo.discovery.alpha import factory as alpha_miner net, im, fm = alpha_miner.apply(event_log)
Now it’s time to see the process model in graphical representation.
from pm4py.visualization.petri_net import visualizer as pn_visualizer gviz = pn_visualizer.apply(net, im, fm) pn_visualizer.view(gviz)
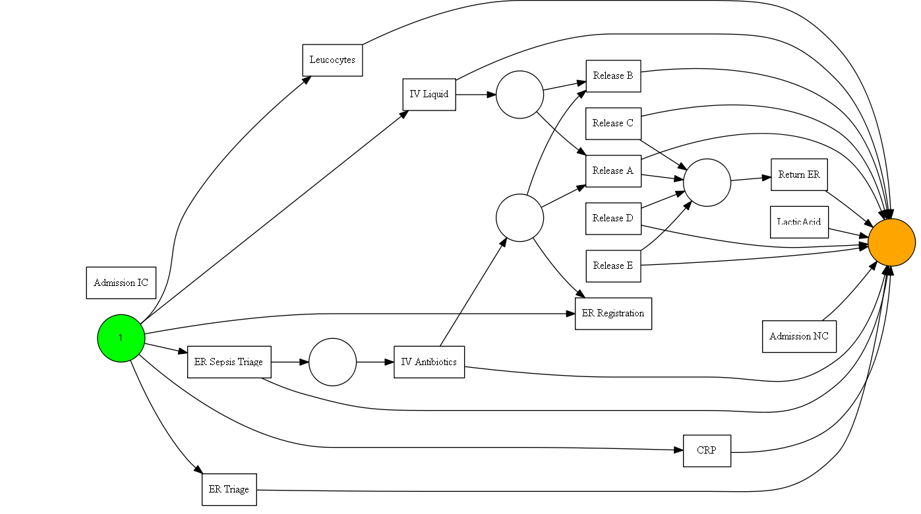
Source: Image made by Author
Conclusion :
In this article, I explained briefly about process mining and different algorithms in process mining for various businesses. In this article, I gave details only about the Alpha Miner algorithm. I recommend visiting https://pm4py.fit.fraunhofer.de/documentation#discovery to know about other algorithms.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






