This article was published as a part of the Data Science Blogathon.
Introduction
The share price of HDFC Bank is going up. It’s on an increasing trend. People are selling in higher numbers and making some instant money.
These are sentences we hear about the stock market on a regular basis nowadays. You can replace HDFC with any other stock that thrived during a tumultuous 2020 and the narrative remains pretty similar.
The stock market is an interesting medium to earn and invest money. It is also a lucrative option that increases your greed and leads to drastic decisions. This is majorly due to the volatile nature of the market. It is a gamble that can often lead to a profit or a loss. There is no proper prediction model for stock prices. The price movement is highly influenced by the demand and supply ratio.

In this article, we will try to mitigate that through the use of reinforcement learning. We will go through the reinfrocement learning techniques that have been used for stock market prediction.
Techniques We Can Use for Predicting Stock Prices
As it is a prediction of continuous values, any kind of regression technique can be used:
- Linear regression will help you predict continuous values
- Time series models are models that can be used for time-related data
- ARIMA is one such model that is used for predicting futuristic time-related predictions
- LSTM is also one such technique that has been used for stock price predictions. LSTM refers to Long Short Term Memory and makes use of neural networks for predicting continuous values. LSTMs are very powerful and are known for retaining long term memory
However, there is another technique that can be used for stock price predictions which is reinforcement learning.
.png)
What is Reinforcement Learning?
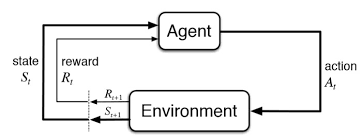
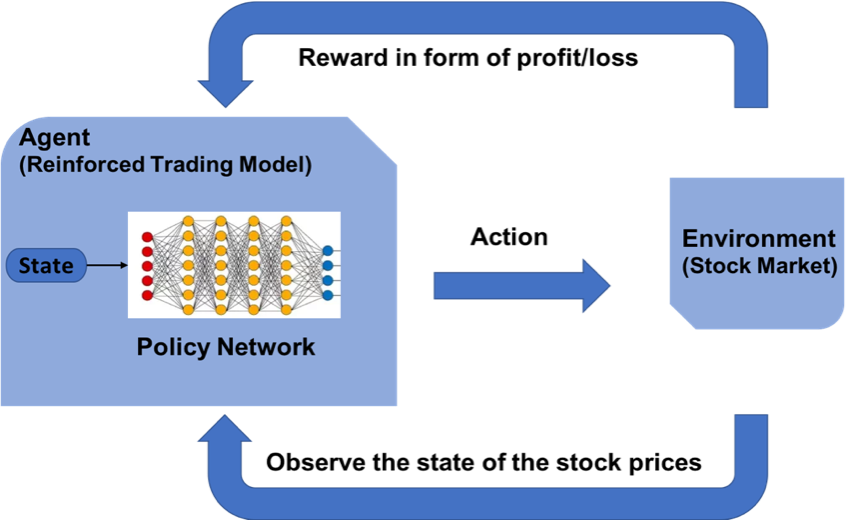
Reinforcement learning is another type of machine learning besides supervised and unsupervised learning. This is an agent-based learning system where the agent takes actions in an environment where the goal is to maximize the record. Reinforcement learning does not require the usage of labeled data like supervised learning.
Reinforcement learning works very well with less historical data. It makes use of the value function and calculates it on the basis of the policy that is decided for that action.
Reinforcement learning is modeled as a Markov Decision Process (MDP):
-
An Environment E and agent states S
-
A set of actions A taken by the agent
-
P(s,s’)=>P(st+1=s’|st=s,at=a) is the transition probability from one state s to s’
-
R(s,s’) – Immediate reward for any action
How can we predict stock market prices using reinforcement learning?
The concept of reinforcement learning can be applied to the stock price prediction for a specific stock as it uses the same fundamentals of requiring lesser historical data, working in an agent-based system to predict higher returns based on the current environment. We will see an example of stock price prediction for a certain stock by following the reinforcement learning model. It makes use of the concept of Q learning explained further.
Steps for designing a reinforcement learning model is –
- Importing Libraries
- Create the agent who will make all decisions
- Define basic functions for formatting the values, sigmoid function, reading the data file, etc
- Train the agent
- Evaluate the agent performance
Define the Reinforcement Learning Environment
MDP for Stock Price Prediction:
- Agent – An Agent A that works in Environment E
- Action – Buy/Sell/Hold
- States – Data values
- Rewards – Profit / Loss
The Role of Q – Learning
Q-learning is a model-free reinforcement learning algorithm to learn the quality of actions telling an agent what action to take under what circumstances. Q-learning finds an optimal policy in the sense of maximizing the expected value of the total reward over any successive steps, starting from the current state.
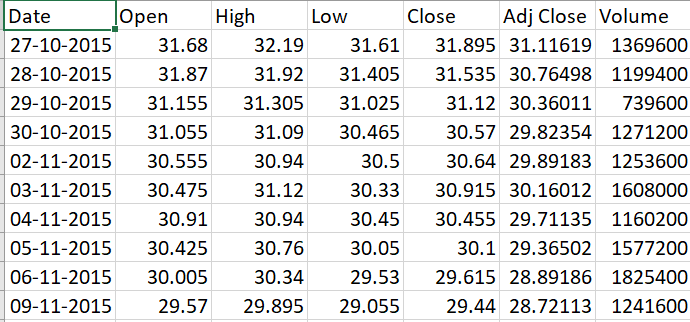
Obtaining Data
-
Go to Yahoo Finance
-
Type in the company’s name for eg. HDFC Bank
-
Select the time period for e.g. 5 years
-
Click on Download to download the CSV file
Let’s Implement Our Model in Python
Importing Libraries
To build the reinforcement learning model, import the required python libraries for modeling the neural network layers and the NumPy library for some basic operations.
import keras from keras.models import Sequential from keras.models import load_model from keras.layers import Dense from keras.optimizers import Adam import math import numpy as np import random from collections import deque
Creating the Agent
The Agent code begins with some basic initializations for the various parameters. Some static variables like gamma, epsilon, epsilon_min, and epsilon_decay are defined. These are threshold constant values that are used to drive the entire buying and selling process for stock and keep the parameters in stride. These min and decay values serve like threshold values in the normal distribution.
The agent designs the layered neural network model to take action of either buy, sell, or hold. This kind of action it takes by looking at its previous prediction and also the current environment state. The act method is used to predict the next action to be taken. If the memory gets full, there is another method called expReplay designed to reset the memory.
Class Agent:
def __init__(self, state_size, is_eval=False, model_name=""):
self.state_size = state_size # normalized previous days
self.action_size = 3 # sit, buy, sell
self.memory = deque(maxlen=1000)
self.inventory = []
self.model_name = model_name
self.is_eval = is_eval
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.model = load_model(model_name) if is_eval else self._model()
def _model(self):
model = Sequential()
model.add(Dense(units=64, input_dim=self.state_size, activation="relu"))
model.add(Dense(units=32, activation="relu"))
model.add(Dense(units=8, activation="relu"))
model.add(Dense(self.action_size, activation="linear"))
model.compile(loss="mse", optimizer=Adam(lr=0.001))
return model
def act(self, state):
if not self.is_eval and random.random()<= self.epsilon:
return random.randrange(self.action_size)
options = self.model.predict(state)
return np.argmax(options[0])
def expReplay(self, batch_size):
mini_batch = []
l = len(self.memory)
for i in range(l - batch_size + 1, l):
mini_batch.append(self.memory[i])
for state, action, reward, next_state, done in mini_batch:
target = reward
if not done:
target = reward + self.gamma * np.amax(self.model.predict(next_state)[0])
target_f = self.model.predict(state)
target_f[0][action] = target
self.model.fit(state, target_f, epochs=1, verbose=0)
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
Define Basic Functions
The formatprice() is written to structure the format of the currency. The getStockDataVec() will bring the stock data into python. Define the sigmoid function as a mathematical calculation. The getState() is coded in such a manner that it gives the current state of the data.
def formatPrice(n):
return("-Rs." if n<0 else "Rs.")+"{0:.2f}".format(abs(n))
def getStockDataVec(key):
vec = []
lines = open(key+".csv","r").read().splitlines()
for line in lines[1:]:
#print(line)
#print(float(line.split(",")[4]))
vec.append(float(line.split(",")[4]))
#print(vec)
return vec
def sigmoid(x):
return 1/(1+math.exp(-x))
def getState(data, t, n):
d = t - n + 1
block = data[d:t + 1] if d >= 0 else -d * [data[0]] + data[0:t + 1] # pad with t0
res = []
for i in range(n - 1):
res.append(sigmoid(block[i + 1] - block[i]))
return np.array([res])
Training the Agent
Depending on the action that is predicted by the model, the buy/sell call adds or subtracts money. It trains via multiple episodes which are the same as epochs in deep learning. The model is then saved subsequently.
import sys
stock_name = input("Enter stock_name, window_size, Episode_count")
window_size = input()
episode_count = input()
stock_name = str(stock_name)
window_size = int(window_size)
episode_count = int(episode_count)
agent = Agent(window_size)
data = getStockDataVec(stock_name)
l = len(data) - 1
batch_size = 32
for e in range(episode_count + 1):
print("Episode " + str(e) + "/" + str(episode_count))
state = getState(data, 0, window_size + 1)
total_profit = 0
agent.inventory = []
for t in range(l):
action = agent.act(state)
# sit
next_state = getState(data, t + 1, window_size + 1)
reward = 0
if action == 1: # buy
agent.inventory.append(data[t])
print("Buy: " + formatPrice(data[t]))
elif action == 2 and len(agent.inventory) > 0: # sell
bought_price = window_size_price = agent.inventory.pop(0)
reward = max(data[t] - bought_price, 0)
total_profit += data[t] - bought_price
print("Sell: " + formatPrice(data[t]) + " | Profit: " + formatPrice(data[t] - bought_price))
done = True if t == l - 1 else False
agent.memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print("--------------------------------")
print("Total Profit: " + formatPrice(total_profit))
print("--------------------------------")
if len(agent.memory) > batch_size:
agent.expReplay(batch_size)
if e % 10 == 0:
agent.model.save(str(e))
Training Output at the end of the first episode:
Total Profit: Rs.340.03
Evaluation of the model
Once the model has been trained depending on new data, you will be able to test the model for the profit/loss that the model is giving. You can accordingly evaluate the credibility of the model.
stock_name = input("Enter Stock_name, Model_name")
model_name = input()
model = load_model(model_name)
window_size = model.layers[0].input.shape.as_list()[1]
agent = Agent(window_size, True, model_name)
data = getStockDataVec(stock_name)
print(data)
l = len(data) - 1
batch_size = 32
state = getState(data, 0, window_size + 1)
print(state)
total_profit = 0
agent.inventory = []
print(l)
for t in range(l):
action = agent.act(state)
print(action)
# sit
next_state = getState(data, t + 1, window_size + 1)
reward = 0
if action == 1: # buy
agent.inventory.append(data[t])
print("Buy: " + formatPrice(data[t]))
elif action == 2 and len(agent.inventory) > 0: # sell
bought_price = agent.inventory.pop(0)
reward = max(data[t] - bought_price, 0)
total_profit += data[t] - bought_price
print("Sell: " + formatPrice(data[t]) + " | Profit: " + formatPrice(data[t] - bought_price))
done = True if t == l - 1 else False
agent.memory.append((state, action, reward, next_state, done))
state = next_state
if done:
print("--------------------------------")
print(stock_name + " Total Profit: " + formatPrice(total_profit))
print("--------------------------------")
print ("Total profit is:",formatPrice(total_profit))
End Notes
Reinforcement learning gives positive results for stock predictions. By using Q learning, different experiments can be performed. More research in reinforcement learning will enable the application of reinforcement learning at a more confident stage.
You can reach out to







Hi there, very interested to know more, I am having troubles with the execution of the above code, do u have a more direct alternative to explain your code structure to deliver the outcome, I am trying to understand how the code structure works as I have an error about the name agent "is not defined" how can I get around that which is towards the end of your code for execution
Hi Claudio, You would not have run the Agent piece of code, hence you are facing this error. Ekta
I solved this by changing any instance of "agent" in the code to the name of my class model. You can see just above the first box of code the model is defined as "class Agent". This is then referred to in the training code; agent = Agent(window_size, True, model_name) To fix this I changed "agent" to whatever I named my class model agent = MyModel(window_size, True, Model_name)
Hi, this is a very good introductory post. But can I ask for any related academic papers or blogs where details are disclosed? I want to know details since I am not very familiar with deep RL Many thanks.
Hi, You can refer to the following link - https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=reinforcement+learning+stock+prediction&btnG= This link has all the papers for RL. Thanks, Ekta
Very good model, can you tell me what parameters you used during training for the window_size and Episode_count?