This article was published as a part of the Data Science Blogathon.
Background
This Blog is about how I solved a real-life problem. Which mutual fund to invest in given your expected return?
The proposed solution should be able to rank mutual funds balancing both returns and risk and should provide top N mutual funds for the given expected return. Luckily for me, I took a vacation for one week and utilized the time to build this solution. from scratch which includes data extraction from API to mutual fund recommendation.
I have extracted data of 33,143 funds. The dataset has more than 24 Million rows and the total size of the dataset is more than 3GB.
Let us first define the problem.
Problem:
The problem is from a plethora of Mutual Funds available in the Market, identify top N funds tailored made to my risk appetite.
| Type of Investor | Return | Risk | |||
| Conservative | Low | Low | |||
| Moderate | Medium / High | Medium / Low | |||
| Aggressive | High | Any |
For these shortlisted funds, I will do further research using financial websites and segregate my fund allocation into various buckets like large-cap, mid-cap, small-cap, etc… for diversification.
Data Extraction:
How do I shortlist promising funds from more than 30,000 funds available? I would at-least require NAV data for all Funds for the last 5 years for ranking purposes. It is impossible to collect data from financial websites as data is not in downloadable format. I searched the internet if anyone has uploaded data. I could not find any. At last, I stumbled across an API to extract the data https://www.mfapi.in/.
I decided to extract data using API. I wrote a python script to download data of more than 30,000 funds from the year 2008.
For each Fund in Mutual_Fund_List:
1. Extract Daywise Fund NAV as a JSON file
2. Append Content of JSON File to a List
3. Convert List to Dataframe
4. Write Dataframe to disk as .csv file
I have named this file as” Indian_Mutual_Funds_NAV_History.csv”
This file has 24 million rows with details of 33,143 funds.
Data Preprocessing
Following Steps are required in data pre-processing:
- Convert Date column in string format to date format
- Consider only Active Funds with a vintage of at least one year.
- Compute Percentage Returns for each Fund with Period =1
- Write the processed file as “MF_Analysis_Pct_Change.txt”
We would implement these pre-processing steps in Python as below.
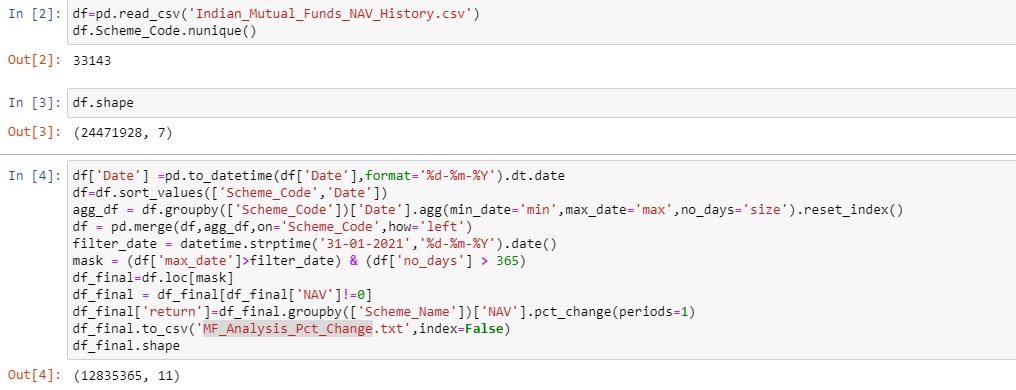
After applying pre-processing we have 8501 active funds.
Returns are computed as (Current Date NAV – Previous Date NAV) / Previous NAV.
I will illustrate with an example for the date 2006-04-04.
Current Date NAV as on 2006-04-04: 116.98
Previous Date NAV (2006-04-03): 116.61
Hence return is (116.98-116.61)/116.61 = 0.00317.
We will convert this into a percentage by multiplying by 100 subsequently.
Mutual Fund Ranking / Recommendation
Let us read the file “MF_Analysis_Pct_Change.txt” created in the previous section. We would also convert the returns into percentages by multiplying by 100.
Let us visualize returns for a sample fund.
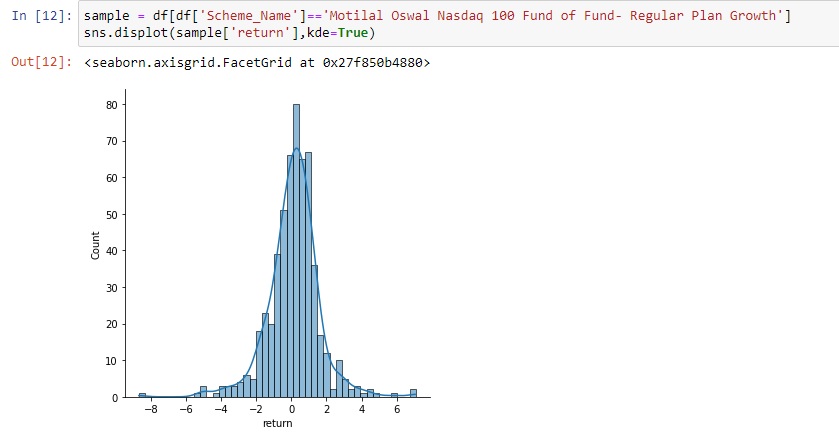
Returns are close to Normal Distribution but we would not assume this for our calculations.
Let us know compute mean, median, standard deviation, min, and max for each fund.
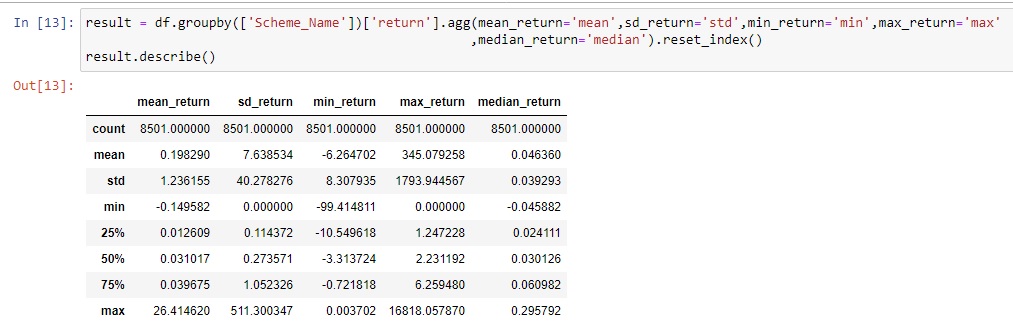
The mean of mean returns is 0.198%. Wow, Nice!. Wait. Look closely at 25%, 50%, 75%, and a max of mean returns. 50% of mean returns is 0.031017 but max is at 26.414620%. There are some outliers. While shortlisting funds we need to ensure that means returns are approximately equal to median returns to ensure that we do not have significant outliers. We need to consider that there are chances of data anomalies also. To be safe, it is best to consider this condition.
Let us now rank mutual funds with the available data i.e. mean returns, median returns, the standard deviation of returns, min and max returns. We need a methodology to compare mutual funds and rank them.
I came up with an approach using Z-SCORE. Z-SCORE can be computed as:
z = (data point – mean) / standard deviation.
A ranking methodology using Z Score considers both the return component (mean returns) and risk component (Standard Deviation).
Conservative Investor (Low-Risk Investor)
Let us assume our target return is 0.01% per day. What could our top N ideal funds? We solve this using Z Score.
Recall, our Z Score formula above:
z = (data point – mean) / standard deviation.
Datapoint: our expected target return which is 0.01%
Mean: Mean returns for the fund
Standard Deviation: Standard Deviation for the Fund
Let us plug our data into the formula and get the top 5 funds:
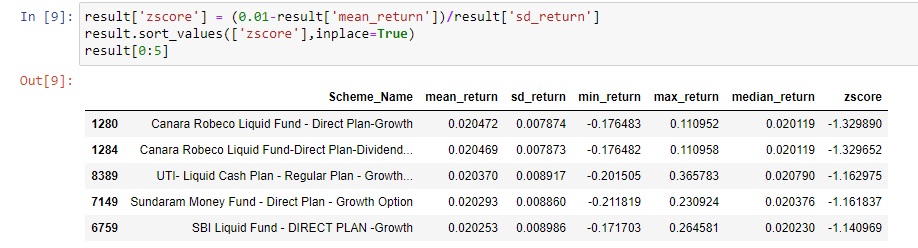
As above, Z-Score for the top fund is -1.329890. This signifies how good or big the distance between the return of the fund when compared to expected returns. A negative Z Score in this case signifies that the return of the fund is above the expected return. Sorting by Z Value and taking the top 5 Z Score in ascending order gives us the top 5 funds with the greatest return considering the risk component of the fund. One more factor to consider is that the mean return of the fund should be comparable to the median return of the Fund. Both Median and Mean of the Fund should be greater than the expected return. We would see why this is important subsequently.
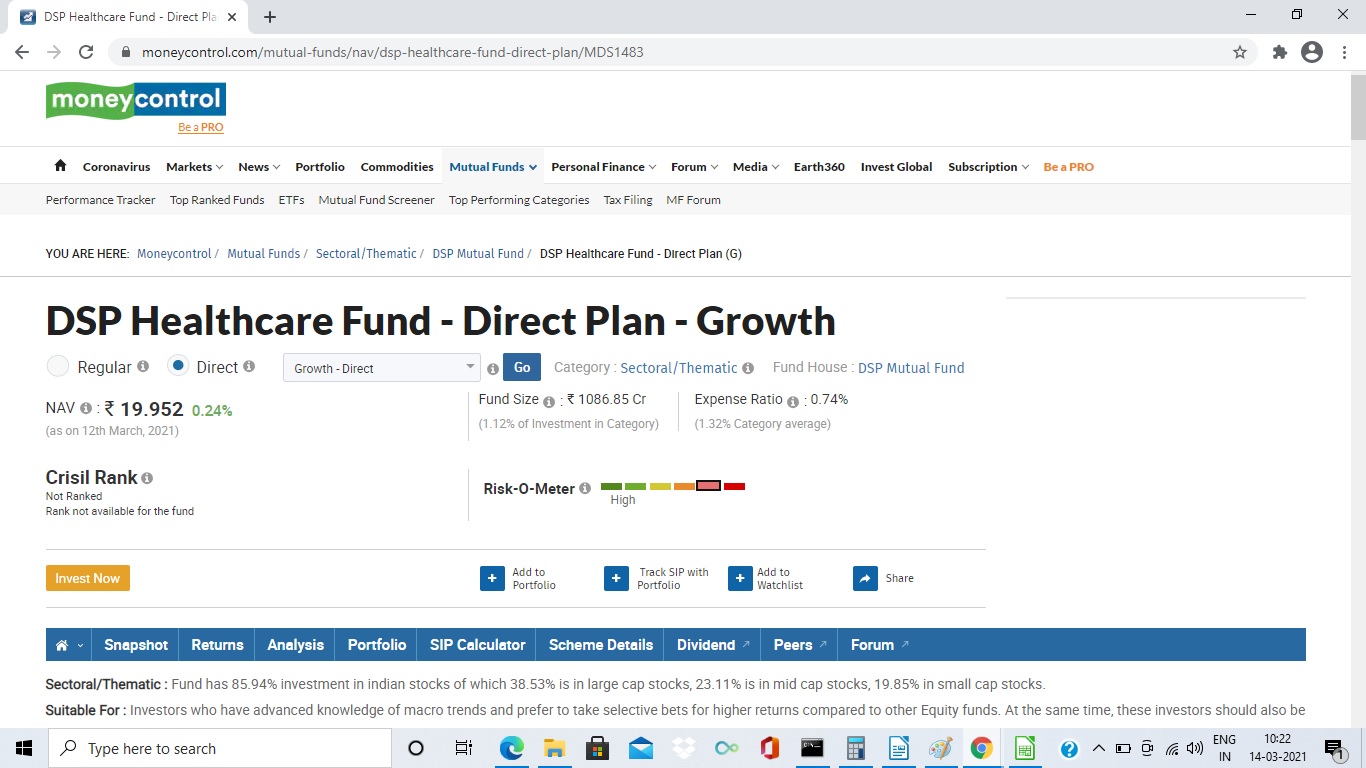
Let us now compare our findings with external websites. One of the popular websites is www.moneycontrol.com. Please find attached a screenshot of the top recommendation.
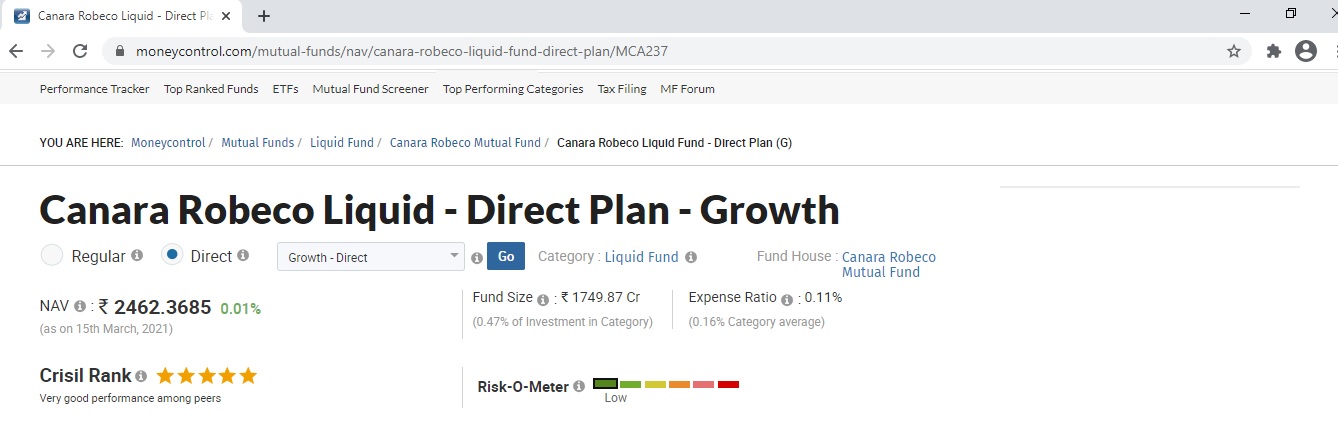
We can see that Crisil’s rank is 5 stars and the risk is low.

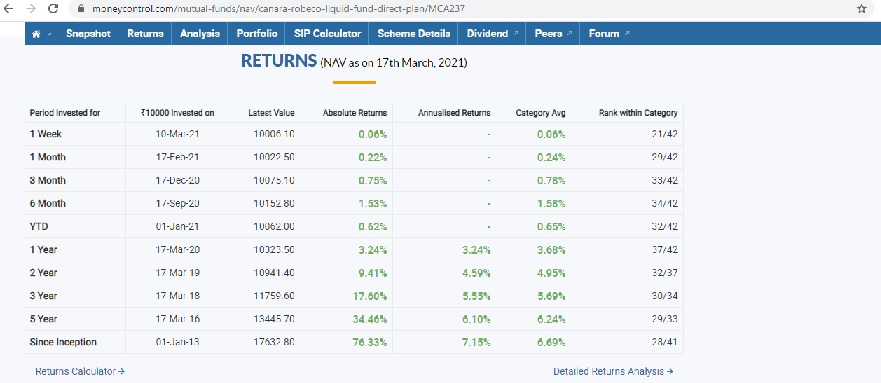
There is no free lunch. If higher returns are needed, we need to take a slightly higher risk.
Moderate Investor
Let us assume our target return is 0.04% per day. What could our top N ideal funds? We solve this using Z Score.
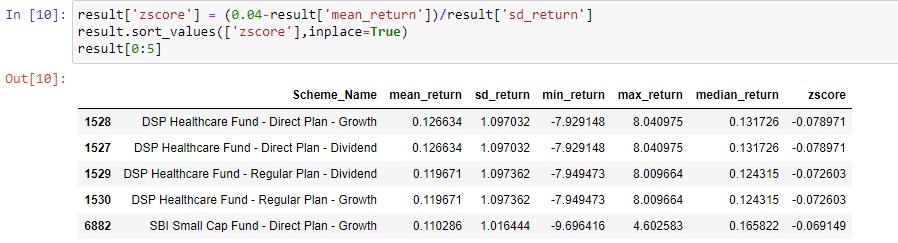
Both Median and Mean returns are more than expected returns.
Let us compare our findings with www.moneycontrol.com
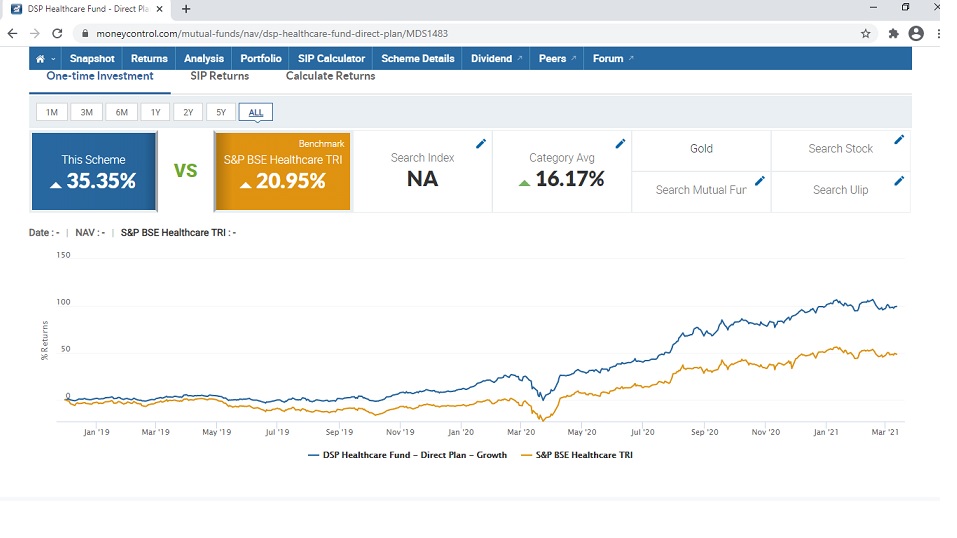
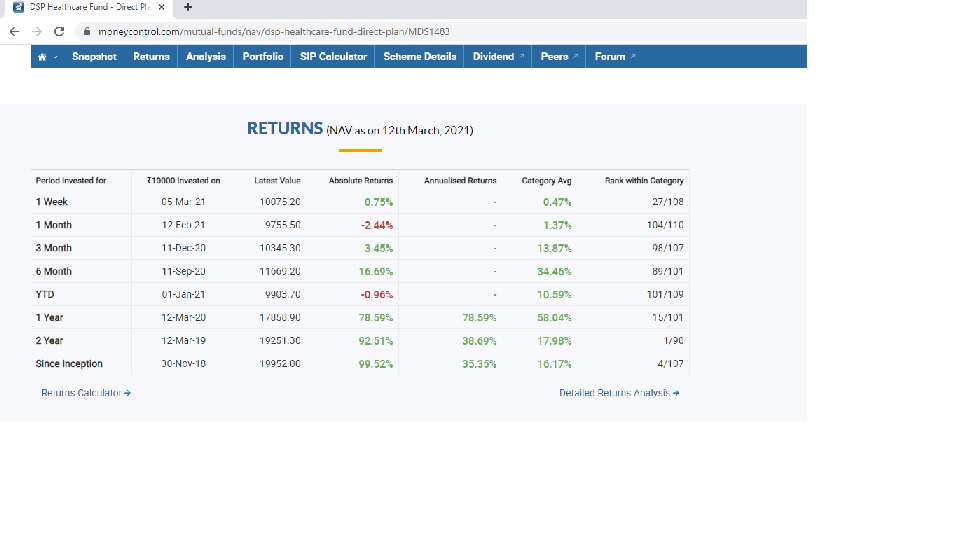
My methodology of ranking seems to correlate pretty well for medium returns also.
Aggressive Investor
Let us assume our target return is 0.08% per day. What could our top N ideal funds? We solve this using Z Score.
Let us view the top 5 funds.
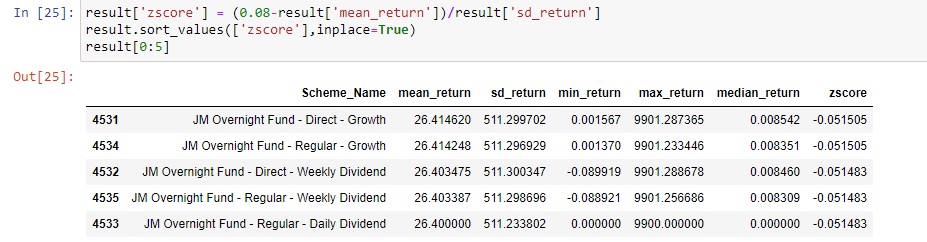
Houston, we have a problem here. Can you spot it?
Mean returns are more than expected returns but the median return is poor.
Let us view Fund History from www.moneycontrol.com
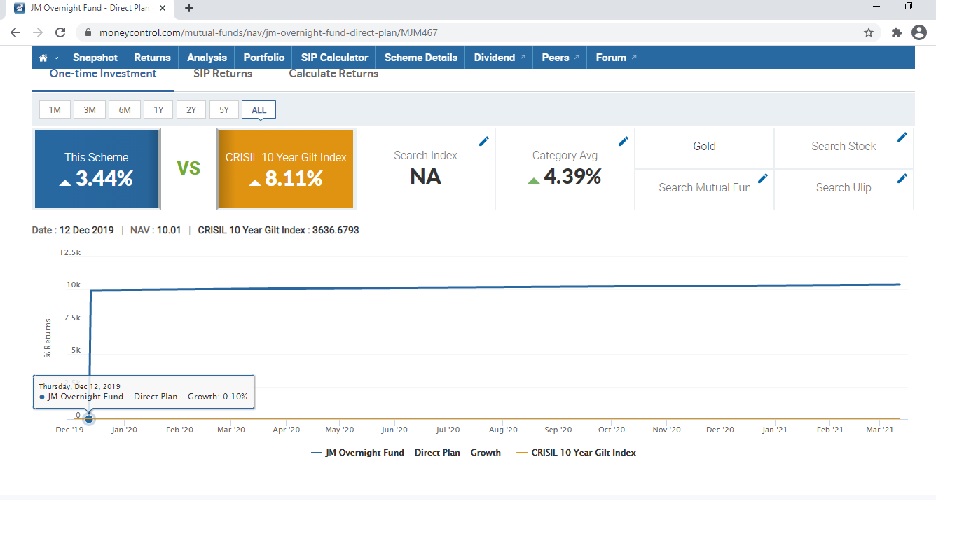
We can infer that it is a data problem and not a data extraction problem.
Let us view the next 5 top funds
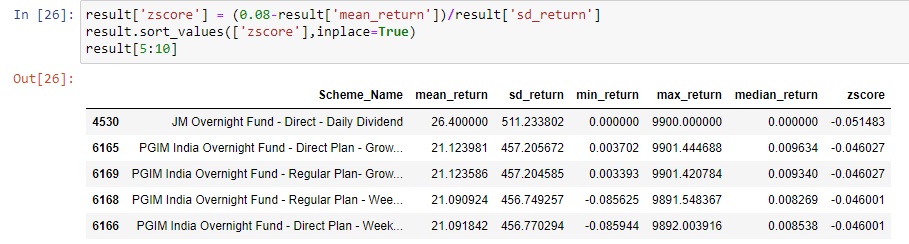
Things become trickier here. Again, mean returns and median returns are not comparable and median returns are less than expected return. Let us try the next 6 funds.
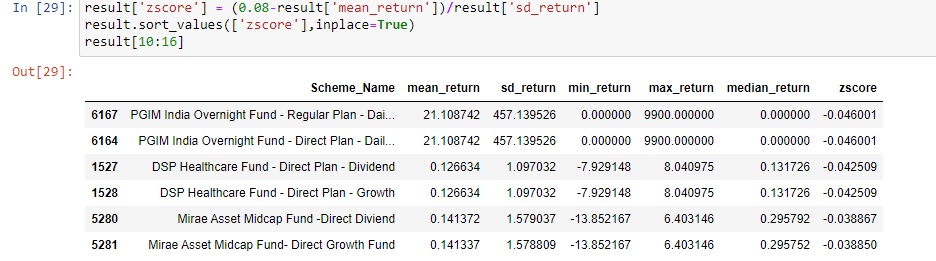
Now again, we get DSP Health Care Fund which is already recommended in medium returns. Let us check the next two funds. Mirae Asset Midcap Fund – Direct Dividend and Mirae Asset Midcap Fund – Direct-Growth Fund. The mean and median returns of this fund look fine and are more than the expected return. Let us compare the returns with www.moneycontrol.com.
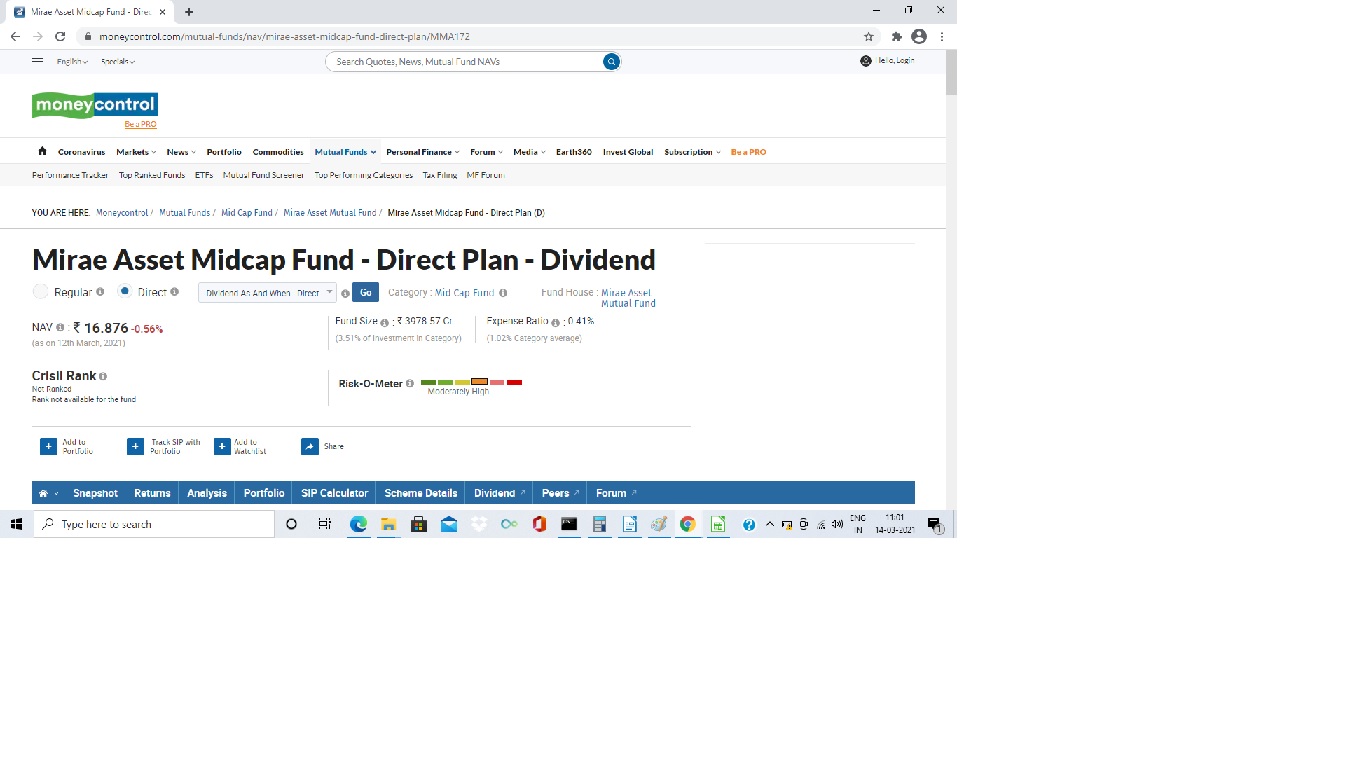
The risk is moderately high. Let us check returns.
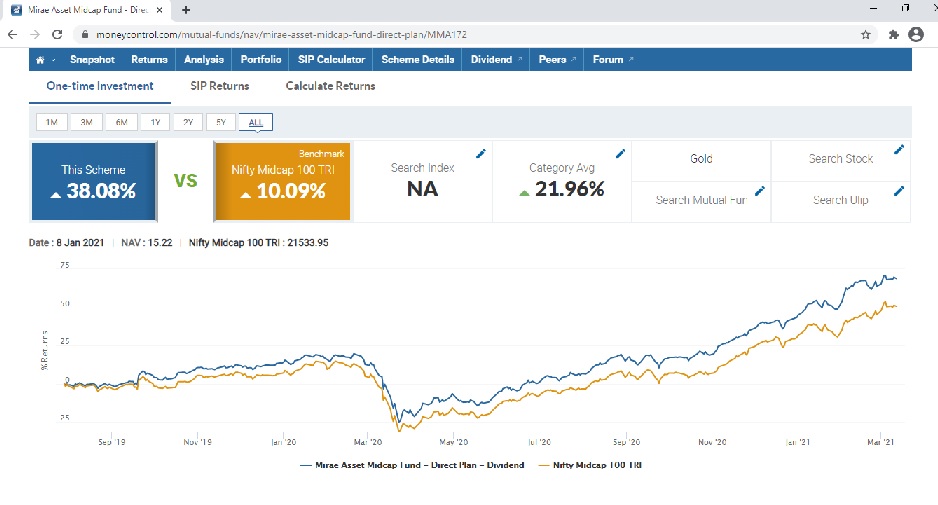
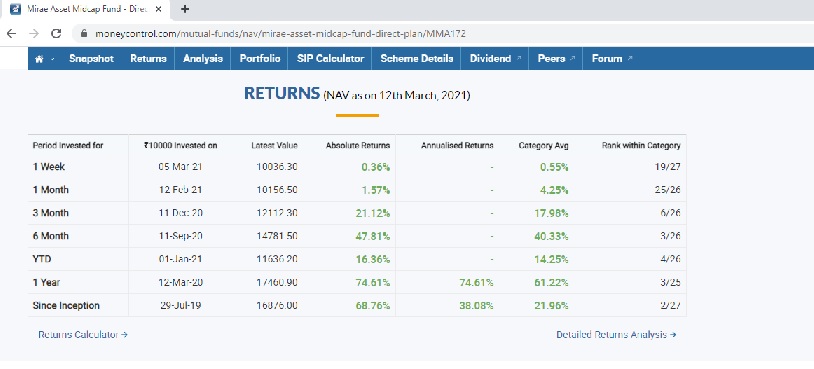
How Do I use this solution?
Now, I have a ranking of each fund. Whenever I come across a recommendation for a Fund, I would look into its ranking and look for similar or better funds and make an informed decision considering returns expected and risk appetite at that moment of time.
Limitations of the Solution:
1. I have used a single variable to solve the problem. Real-world problems are usually addressed by multiple variables.
2. I did not address the ranking of Funds across various types for diversification like Large Cap, Mid Cap, Small Cap, ELSS, Overnight Funds, Liquid Funds, etc.
Machine Learning Model
I did try to develop a Machine Learning Model to predict future NAV but I am not too excited to build a solution with a Single Variable as it will be an academic exercise as it is extremely unlikely to predict returns confidently for at least for next one year using only one variable. I need to collect more data with various dimensions to make any progress on this. There are a lot of intangible factors in predicting stocks or mutual funds accurately. For e.g. Corona Pandemic, who could have predicted this during August 2019?
End Notes
In this blog, how simple application of Data Science can help us in achieving optimal decisions in personal finance. This can be applied across various fields and domains.
Disclaimer:- This is my personal project used to solve a problem which I faced. To arrive at a final decision I may use further techniques to arrive at final funds to be invested. This is just an approach to solve a problem and the above-proposed solution is not an optimal one and can be improved. The above solution is arrived at considering the amount of data I can extract and my personal laptop infrastructure constraints as I did not use a cloud machine for this. Please do further research before actual investment and this blog is sole to be used for learning purposes.
Bio: Balaji is an Experienced Data Scientist, Kaggle Competition Expert, Top 20 AV Competitor Passionate about building solutions using ML.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Seasoned data profession with over 6+ years of experience as Data Scientist and over a decade of experience in Analytics.Kaggle Competition Expert. Passionate in developing data products and solutions.







Balaji, This is a really learning article. I would really like to run this program. Can you please share the datafile "Indian_Mutual_Funds_NAV_History.csv" or the sript to get the data. Thanks. Prasun Neogy Kolkata
Prasun Neogy, Glad you found Blog to be useful. I will try open source the dataset sooner.
Hi Balaji. This looks very interesting and also I liked that yours would be unbiased approach as you are probably getting any commissions for recommendations or rejections. Please share your excel.file and is the query refreshable? I can also.see If someone can collaborate with you to make a well.rounded tool.
Hi, Really great work and very much helpful in learning. Could you please help me too by sharing the "Indian_Mutual_Funds_NAV_History.csv" file. Mail ID: [email protected]