Introduction
The availability of information is vital in today’s data-driven environment. For many uses, such as competitive analysis, market research, and basic data collection for analysis, efficiently extracting data from websites is crucial. Tradition-based manual data collection methods can be time-consuming and unproductive. However, online scraping provides an automated method for rapidly and effectively gathering data from websites. This article will introduce you to Selenium, the most potent and adaptable web scraping technology in the market.

Table of Contents
What is Web Scraping?
Web scraping involves the automated extraction of data from websites. It encompasses fetching the web page, parsing its contents, and extracting the desired information. This process could range from simple tasks like extracting product prices from an e-commerce site to more complex operations like scraping dynamic content from web applications.
Traditionally, web scraping was performed using libraries like BeautifulSoup in Python, which parse the HTML content of web pages. However, this approach has limitations, especially when dealing with dynamic content loaded via JavaScript. This is where Selenium shines.
Introducing Selenium
Selenium is a powerful automation tool primarily used for testing web applications. However, its capabilities extend beyond testing to include web scraping. Unlike traditional scraping libraries, Selenium interacts with web pages in the same way a user would, enabling it to handle dynamic content effectively.
In the digital landscape, where websites are not just static pages but dynamic platforms, testing and interacting with web applications pose unique challenges. This is where Selenium, an open-source automation testing tool, emerges as a game-changer. Beyond its testing capabilities, this library has become synonymous with web scraping. It has empowered developers and data enthusiasts to extract valuable information from the vast expanse of the internet.
At its core, Selenium is a suite of tools and libraries designed to automate web browsers across different platforms. Initially developed by Jason Huggins in 2004 as an internal tool at ThoughtWorks, Selenium has evolved into a robust ecosystem, offering various functionalities to meet the diverse needs of web developers and testers.
Key Components of Selenium
Selenium comprises several key components, each serving a specific purpose in the web automation process:
- Selenium WebDriver: WebDriver is the cornerstone of Selenium, providing a programming interface to interact with web browsers. It allows users to simulate user interactions such as clicking buttons, entering text, and navigating through web pages programmatically.
- Selenium IDE: IDE, short for Integrated Development Environment, offers a browser extension for Firefox and Chrome that facilitates record-and-playback testing. While primarily used for rapid prototyping and exploratory testing, Selenium IDE serves as an entry point for beginners to acquaint themselves with Selenium’s capabilities.
- Selenium Grid: Selenium Grid enables parallel execution of tests across multiple browsers and platforms, making it ideal for large-scale test automation projects. By distributing test execution, Selenium Grid significantly reduces the overall test execution time, enhancing efficiency and scalability.
Getting Started with Selenium
Before diving into Selenium, you need to set up your development environment.
Installing Selenium
Selenium is primarily a Python library, so ensure you have Python installed on your system. You can install Selenium using pip, Python’s package manager, by running the following command in your terminal:
pip install seleniumAdditionally, you’ll need to install a WebDriver for the browser you intend to automate. WebDriver acts as a bridge between your Selenium scripts and the web browser. You can download WebDriver executables for popular browsers like Chrome, Firefox, and Edge from their respective websites or package managers.
Setting Up Your First Selenium Project
With Selenium installed, you’re ready to create your first project. Open your preferred code editor and create a new Python script (e.g., my_first_selenium_script.py). In this script, you’ll write the code to automate browser interactions.
Writing Your First Selenium Script
Let’s start with a simple Selenium script to open a web page in a browser. Below is an example script using Python:
from selenium import webdriver# Initialize the WebDriver (replace 'path_to_driver' with the path to your WebDriver executable)
driver = webdriver.Chrome('path_to_driver')# Open a web page
driver.get('https://www.example.com')# Close the browser window
driver.quit()Locating Elements with Selenium
Selenium offers two primary methods for locating elements:
- find_element: Finds the first element matching the specified criteria.
- find_elements: Finds all elements matching the specified criteria, returning a list.
These methods are essential for navigating through a web page and extracting desired information efficiently.
Attributes Available for Locating Elements
Selenium’s By class provides various attributes for locating elements on a page. These attributes include ID, Name, XPath, Link Text, Partial Link Text, Tag Name, Class Name, and CSS Selector.
Each attribute serves a specific purpose and can be utilized based on the unique characteristics of the elements being targeted.
Locating Elements by Specific Attributes
Let’s explore some common strategies for locating elements using specific attributes:
- ID: Ideal for locating elements with a unique identifier.
- Name: Useful when elements are identified by their name attribute.
- XPath: A powerful language for locating nodes in an XML document, XPath is versatile and can target elements based on various criteria.
- Link Text and Partial Link Text: Effective for locating hyperlinks based on their visible text.
- Tag Name: Useful for targeting elements based on their HTML tag.
- Class Name: Locates elements based on their class attribute.
- CSS Selector: Employs CSS selector syntax to locate elements, offering flexibility and precision.
Basic Scraping with Selenium
Let’s consider a simple example of scraping the titles of articles from a news website.
# Open the webpage
driver.get("https://example.com/news")
# Find all article titles
titles = driver.find_elements_by_xpath("//h2[@class='article-title']")
# Extract and print the titles
for title in titles:
print(title.text)In this example, we first navigate to the desired webpage using driver.get(). Then, we use find_elements_by_xpath() to locate all HTML elements containing article titles. Finally, we extract the text of each title using the .text attribute.
Handling Dynamic Content
One of the key advantages of Selenium is its ability to handle websites with dynamic content. This includes content loaded via JavaScript or content that appears only after user interactions (e.g., clicking a button).
# Click on a button to load more content
load_more_button = driver.find_element_by_xpath("//button[@id='load-more']")
load_more_button.click()
# Wait for the new content to load
driver.implicitly_wait(10) # Wait for 10 seconds for the content to load
# Scraping the newly loaded content
new_titles = driver.find_elements_by_xpath("//h2[@class='article-title']")
for title in new_titles:
print(title.text)Here, we simulate clicking a “Load More” button using click(). We then wait for the new content to load using implicitly_wait(), ensuring that the scraper waits for a specified amount of time before proceeding.
Example: Scraping Wikipedia
In this example, I’ll demonstrate how to scrape information related to “Data Science” from Wikipedia using Selenium, a powerful tool for web scraping and automation. We’ll walk through the process of navigating to the Wikipedia page, locating specific elements such as paragraphs and hyperlinks, and extracting relevant content. You can scrape some other websites after reading this article by applying different techniques.
Before scraping, let’s begin by inspecting the webpage. Right-click on the paragraph you wish to scrape, and a context menu will appear.
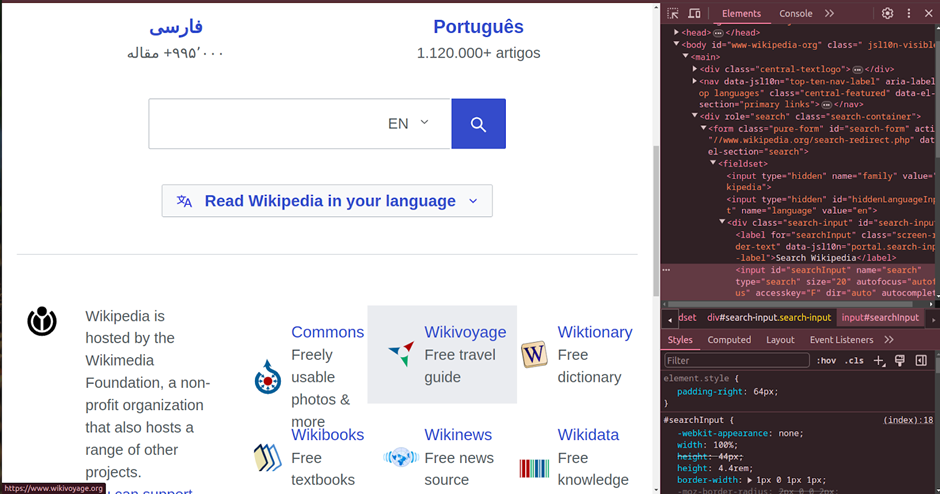
Click right again on the context menu to find the Copy options. Then select ‘Copy full XPath’, ‘Copy XPath’, or any other available options to access the HTML document. This is how we will be using XPATH.
Step 1: Import the Necessary Libraries
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import ByStep 2: Initialize the WebDriver for Chrome
Now, let’s initialize the WebDriver for Chrome with custom options and service configuration.
Download the Chrome WebDriver by clicking on this link: https://chromedriver.chromium.org/downloads
Verify the compatibility of your Chrome and WebDriver versions.
For different browsers, you can download the WebDriver from these links:
chrome_options = Options()
chrome_service = Service('/home/jaanvi/calldetailfolder/chromedriver-linux64/chromedriver')
driver=webdriver.Chrome(service=chrome_service, options = chrome_options) Step 3: Begin the Website Scraping Process
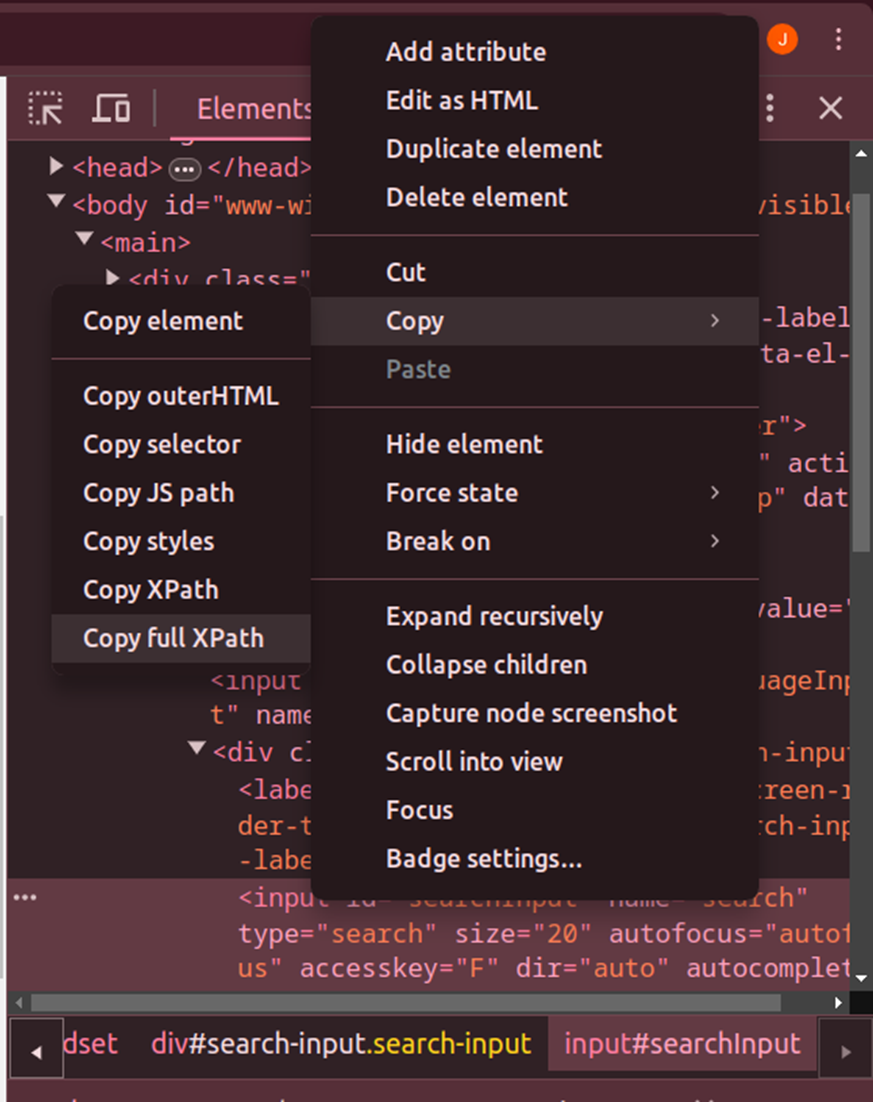
1. Let’s open the Wikipedia website.
driver.get('https://www.wikipedia.org/')2. Now search using the search box . You can get the XPATH by doing right click and click on inspect and copy the Xpath.
Type = driver.find_element(By.XPATH,
"/html/body/main/div[2]/form/fieldset/div/input")
Type.send_keys('Data Science')3. Now let’s click on the search button.
Search=driver.find_element(By.XPATH,
"/html/body/main/div[2]/form/fieldset/button/i")
Search.click()4. Let’s extract the single paragraph.
single_para=driver.find_element(By.XPATH,
"/html/body/div[2]/div/div[3]/main/div[3]/div[3]/div[1]/p[2]")
print(single_para.text)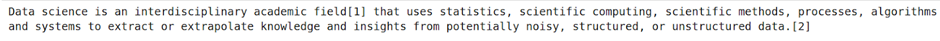
5. Now let’s extract all the paragraphs using the ID.
para=driver.find_element(By.ID,"mw-content-text")
print(para.text)
6. Navigating through the table of contents.
navigating= driver.find_element(By.XPATH,
"/html/body/div[2]/div/div[2]/div[2]/nav/div/div/ul/li[4]/a/div")
navigating.click()7. Accessing the content using the table of contents.
opening_link=driver.find_elements(By.XPATH,
"/html/body/div[2]/div/div[3]/main/div[3]/div[3]/div[1]/p[17]/a[2]")8. Opening a specific link from the table of contents.
opening_link = driver.find_elements(By.XPATH,
"/html/body/div[2]/div/div[3]/main/div[3]/div[3]/div[1]/p[17]/a[2]")
opening_link.click()9. Locating and clicking hyperlinks by text.
continue_link = driver.find_element(By.LINK_TEXT, 'data visualization')
continue_link.click()10. Can also locate using Partial_LINK_TEXT.
continue_link = driver.find_element(By.PARTIAL_LINK_TEXT, 'donut ')
continue_link.click()11. Locating content by CSS Selector and printing its text.
content = driver.find_element(By.CSS_SELECTOR,
'#mw-content-text > div.mw-content-ltr.mw-parser-output > table > tbody')
content.text
In this example, we harnessed Selenium’s capabilities to scrape Wikipedia for Data Science information. Selenium, known primarily for web application testing, proved invaluable in efficiently extracting data from web pages. Through Selenium, we navigated complex web structures, employing methods like XPath, ID, and CSS Selector for element location. This flexibility facilitated dynamic interaction with web elements such as paragraphs and hyperlinks. By extracting targeted content, including paragraphs and hyperlinks, we gathered pertinent Data Science information from Wikipedia. This extracted data can be further analyzed and processed to serve various purposes, showcasing Selenium’s prowess in web scraping endeavors.
Conclusion
Selenium offers a powerful and versatile solution for web scraping, especially when dealing with dynamic content. By mimicking user interactions, it enables the scraping of even the most complex web pages. However, it’s essential to use it responsibly and adhere to website terms of service and legal regulations. With the right approach, it can be a valuable tool for extracting valuable data from the web. Whether you’re a data scientist, a business analyst, or a curious individual, mastering web scraping with Selenium opens up a world of possibilities for accessing and utilizing web data effectively.
Frequently Asked Questions
Q1. What is Selenium, and what is its primary use?
A. Selenium is an open-source automation tool primarily used for testing web applications. Its primary use is to automate web browsers for testing purposes, but it is also widely utilized for web scraping.
Q2. What are the key components of Selenium?
A. Selenium comprises several key components, including WebDriver, Selenium IDE, and Selenium Grid. WebDriver is the cornerstone, providing a programming interface for browser automation. Selenium IDE offers a record-and-playback functionality, while Selenium Grid enables parallel execution of tests across multiple browsers and platforms.
Q3. What programming languages are supported by Selenium?
A. Selenium supports multiple programming languages, including Python, Java, C#, Ruby, and JavaScript. Users can choose their preferred language based on their familiarity and project requirements.
Q4. How do I install Selenium on my system?
A. Selenium can be installed using package managers like pip for Python. Additionally, users need to download and configure WebDriver executables for the browsers they intend to automate.
Q5. What are the common methods for locating elements in Selenium?
A. Selenium provides various methods for locating elements on a web page, including find_element, find_elements, and methods based on attributes like ID, XPath, CSS Selector, etc.
Q6. Is Selenium suitable for large-scale web scraping projects?
A. Yes, Selenium can be used for large-scale web scraping projects, especially when combined with Selenium Grid for parallel execution across multiple browsers and platforms. However, users should be mindful of website terms of service and legal considerations when conducting large-scale scraping.
Hi, I am Janvi, a passionate data science enthusiast currently working at Analytics Vidhya. My journey into the world of data began with a deep curiosity about how we can extract meaningful insights from complex datasets.






