-
Coming from a Programming Background? Here’s your Quick Fire Python Guide to Basics!
Do you already know C++, JavaScript, R, or any other programming language? Then learn the basics of Python coding in under 15 minutes
Sebastian 30 Oct, 2024
-
Discrete Probability Distributions
Discrete probability distributions describe the probability of occurrence of each value of a discrete random variable in a situation.
Priyanka 08 Nov, 2024
-
Correlation Analysis Using R
Correlation is a statistical measure that defines the relationship between two variables. Learn about correlation analysis using R.
vipin.shrivastava 27 Jan, 2021
-
Here’s What You Need to Know to Become a Data Scientist!
Being a data scientist has become prestigious in 2021. Learn how to become a data scientist in 2021 and begin your journey.
Ram Dewani 25 Jan, 2021
-
5 Highly Recommended Skills / Tools to learn in 2021 for being a Data Analyst
In this article, we are going to see the top 5 data analyst skills that will help you become a data analyst in 2021 and progress seamlessly
Palak 25 Jan, 2021
-
Kaggle Grandmaster Series – Exclusive Interview with 2x Kaggle Grandmaster Marios Michailidis
Analytics Vidhya 25 Jan, 2021
-
An Introduction to Hypothesis Testing
Hypothesis testing is one of the most useful concepts of Statistical Inference. This article is an introduction to hypothesis testing
Nivedita 07 May, 2024
-
Elbow Method for Optimal Cluster Number in K-Means
Elbow method helps you understand how your data is organized using visual analysis and gives insight into choosing the optimal value of k.
Basil Saji 04 Apr, 2025
-
KNN Classifier in Python: Implementation, Features, and Applications
This article concerns one of the supervised ML classification algorithms- KNN (K Nearest Neighbor) algorithm in Python for beginners
Basil Saji 15 Oct, 2024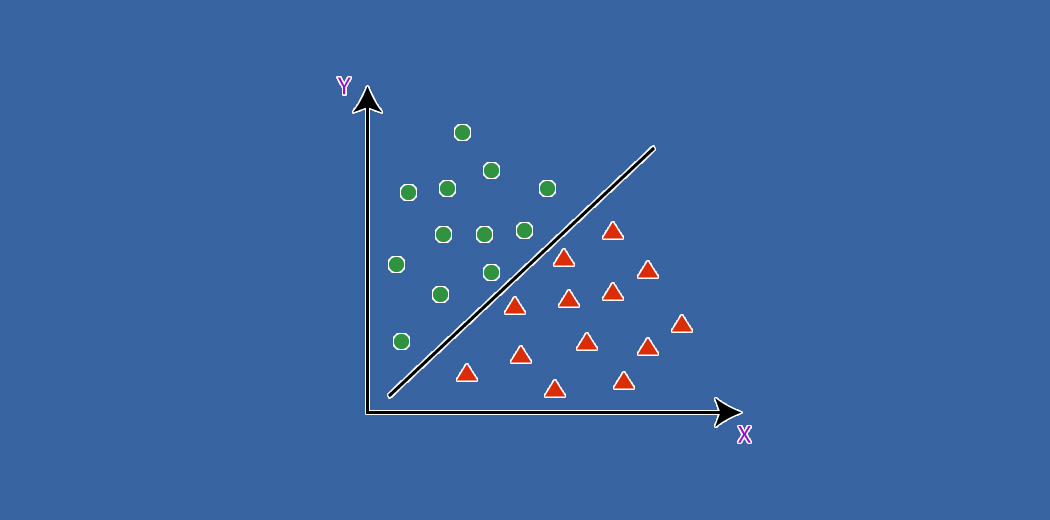
-
Kaggle Grandmaster Series – Exclusive Interview with Kaggle Competitions Grandmaster Peiyuan Liao (Rank 28!)
in this edition of Kaggle Grandmaster Series, We are joined by one of the youngest kaggle competitions Grandmasters, Peiyuan Liao
Analytics Vidhya 19 Jan, 2021
