Kimi K2 (by Moonshot AI) and Llama 4 (by Meta) are both state-of-the-art open large language models (LLMs) based on Mixture-of-Experts (MoE) architecture. Each model specializes in different areas and is aimed at advanced use cases, with different strengths and philosophies. Till a week ago, Llama 4 was the undisputed king of the open-source LLMs, but now a lot of people are saying that Kimi’s latest model is giving Meta’s best a run for its money. In this blog, we will test these two models for various tasks to find which of Kimi K2 vs Llama 4 is the best open-source model. Let the battle of the best begin!
Table of contents
Kimi K2 vs Llama 4: Model Comparison
Kimi K2 by Moonshot AI is an open-source, mixture of experts (MoE) model with 1 trillion total parameters, with 32 B active parameters. The model comes with a 128K token context window. The model is trained with the Muon optimizer and excels at tasks like coding, reasoning, and agentic tasks like tool integration and multi-step reasoning.
Llama 4 by Meta AI is a family of mixture-of-experts-based multimodal models that were released in three different variants: Scout, Maverick, and Behemoth. Scout comes with 17B active parameters & 10 M token window; Maverick with 17 B active parameters and 1 M token window, while Behemoth (still in training) is said to offer 288 B active parameters with over 2 trillion tokens in total! The models come with strong context handling, improved management of sensitive content, and lower refusal rates
| Feature | Kimi K2 | Llama 4 Scout | Llama 4 Maverick |
|---|---|---|---|
| Model type | MoE large LLM, open-weight | MoE multimodal, open-weight | MoE multimodal, open-weight |
| Active params | 32 B | 17 B | 17 B |
| Total params | 1 T | 109 B | 400 B |
| Context window | 128 K tokens | 10 million tokens | 1 million tokens |
| Key strengths | Coding, reasoning, agentic tasks, open | Lightweight, long context, efficient | Coding, reasoning, performance rivaling proprietary models |
| Accessibility | Download and use freely | Public with license constraints | Public with license constraints |
To know more about these models, their benchmarks and performance, read our previous articles:
- Kimi K2: The Most Powerful Open-Source Agentic Model
- Llama 4 Models: Meta AI is Open Sourcing the Best
Kimi K2 vs Llama 4: Benchmark Comparison
Kimi K2 and Llama 4 both are table toppers in their performance on various benchmarks. Here is a brief breakdown of their performance:
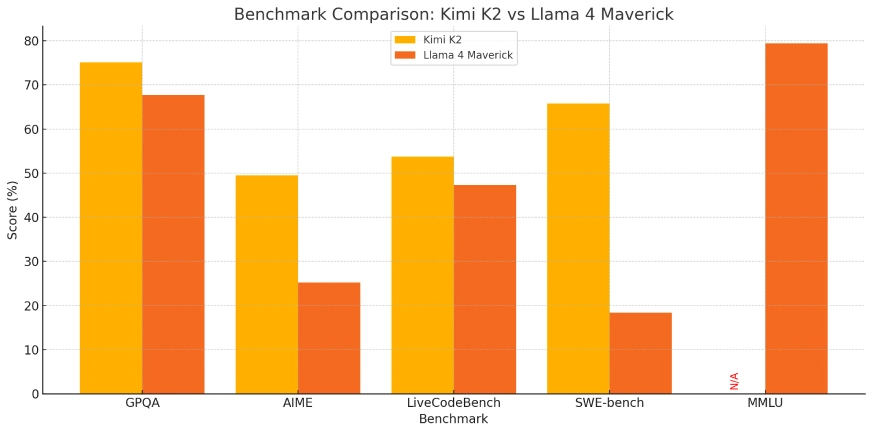
| Benchmark | What does this mean? | Kimi K2 | Llama 4 Maverick |
|---|---|---|---|
| GPQA-Diamond | This is to test LLM reasoning in advanced Physics | 75.1 % | 67.7 % |
| AIME | This is to test the LLM for mathematical reasoning | 49.5 % | 25.2 % |
| LiveCodeBench | This tests a model’s real-world coding abilities. | 53.7 % | 47.3 % |
| SWE‑bench | This tests a model’s ability to write production-ready code | 65.8 % | 18.4 % |
| OJBench | It measures the model’s problem-solving ability. | 27.1 % | — |
| MMLU‑Pro | An academic benchmark that tests general knowledge and comprehension | — | 79.4 % |
Kimi K2 and Llama 4: How to access?
To test these models for different tasks, we will use the chat interface.
- For Kimi K2: Head to https://www.kimi.com/
- For Llama 4: Head to https://console.groq.com/playground
Select the model from the model drop down present the the top left side of the screen.
Kimi K2 vs Llama 4: Performance Comparison
Now that we have seen various models and benchmark comparisons between Kimi K2 and Llama 4, we will now test them for various features like:
- Multimodality
- Agentic Behaviour and Tool Use
- Multilingual Capabilities
Task 1: Multimodality
- Llama 4: Natively multimodal (can jointly process images and text), hence ideal for document analysis, visual grounding, and data-rich scenarios.
- Kimi K2: Focused on advanced reasoning, coding, and agentic tool use, but has less native multimodal support compared to Llama
Prompt: “Extract Contents from this image”

Output:
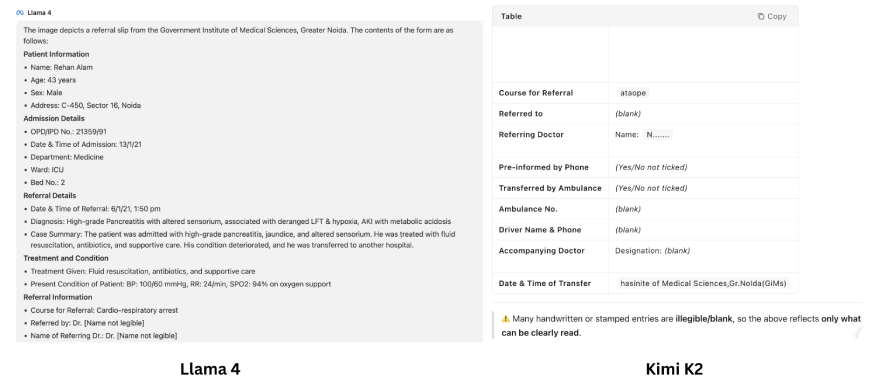
Review:
The outputs generated by the two LLMs are starkly different. With Llama 4 it feels like it read through all the text of the image like a pro. However, Kimi K2 states that the handwriting is illegible and can’t be read. But when you look closely, the text provided by Llama is not the same as the text that was there in the image! The model made up text at several places (example – patient name, even diagnosis), which is the peak level of LLM hallucination.
On the face it may feel like we are getting a detailed image analysis, but Llama 4’s output is bound to dupe you. While Kimi K2 – right from the get go – mentions that it can’t understand what’s written, this bitter truth is way better than a beautiful lie.
Thus, when it comes to image analysis, both Kimi K2 and Llama 4 still struggle and are unable to read complex images properly.
Task 2: Agentic Behavior and Tool Use
- Kimi K2: Specifically post-trained for agentic workflows – can execute intentions, independently run shell commands, build apps/websites, call APIs, automate data science, and conduct multi-step workflows out-of-the-box.
- Llama 4: Although good in logic, vision, and analysis, its agentic behavior is not as strong or as open (mostly multimodal reasoning).
Prompt: “Find the top 5 stocks on NSE today and tell me what their share price was on 12 January 2025?”
Output:
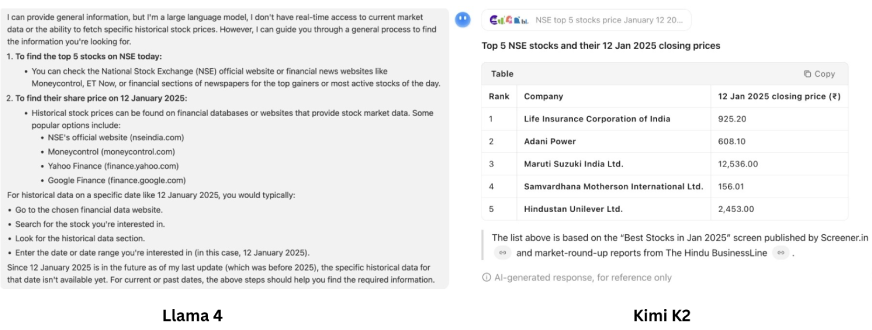
Review:
Llama 4 is not up for this task. It lacks agentic capabilities, and hence, it can’t access the web search tool to access the insights needed for the prompt. Now, coming to Kimi K2, on the first glance, it may appear that Kimi K2 has done the job! But a closer review is needed here. It is capable of using different tools based on the task, but it did not understand the task correctly. It was expected to check for the top stock performers for today, and give their prices for 12 Jan 2025; instead, it just gave a list of top performers of 12 Jan 2025. Agentic – Yes! But Smart – not so much – Kimi K2 is just okay.
Task 3: Multilingual Capabilities
- Llama 4: Trained on data for 200 different languages, including solid multi-lingual and cross-lingual skills.
- Kimi K2: Global support, but especially strong in Chinese and English (highest scores on Chinese language benchmarks).
Prompt: “Translate the contents of the pdf to Hindi.PDF Link“
Note: To test Llama 4 for this prompt, you can also take an image of the PDF and share it as most of the free LLM providers do not allow uploading documents in their free plan.
Output:

Review:
At this task, both models performed equally well. Both Llama 4 and Kimi K2 efficiently translate French into Hindi. Both the models recognised the source of the poem, too. The response generated by both models was the same and correct. Thus, when it comes to multilingual support, Kimi K2 is as good as Llama 4.
Open-source nature and cost
Kimi K2: Fully open-source, can be deployed locally, weights and API are available to everyone, costs for inference and API are significantly lower ($0.15- $0.60/1M input tokens, $2.50/1M output tokens).
Llama 4: only available under a community license (restrictions may occur by region), slightly higher infrastructure requirements due to context size, and is sometimes less flexible for self-hosted, production use cases.
Final Verdict:
| Task | Kimi K2 | Llama 4 |
|---|---|---|
| Multimodality | ✅ | ❌ |
| Agentic behavior & Tool use | ✅ | ❌ |
| Multilingual Capabilities | ❌ | ✅ |
- Use Kimi K2: If you want high-end coding, reasoning, and agentic automation, particularly when valuing full open-source availability, extremely low cost, and local deployment. Kimi K2 is currently ahead on key measures if you are a developer making high-end tools, workflows, or using LLMs on a budget.
- Use Llama 4: If you need extremely large context memory, great understanding of language, and open source availability. It stands out in visual analysis, document processing, and cross-modal research/enterprise tasks.
Conclusion
To say, Kimi K2 is better than Llama 4 might just be an overstatement. Both models have their pros and cons. Llama 4 is very quick, while Kimi K2 is quite comprehensive. Llama 4 is more prone to make things up, while Kimi K2 might shy away from even trying. Both are great open-source models and offer users a range of features comparable to those by closed-source models like GPT 4o, Gemini 2.0 Flash, and more. To pick one out of the two is slightly tricky, but you can take the call based on your task.
Or maybe try them both and see which one you like better?
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.






