I’ve been closely following how quickly the world of LLMs is evolving, and one area that really excites me is the rise of sophisticated Policy Optimization Techniques. What stood out to me recently is DeepSeek-R1, which leverages GRPO to deliver remarkable performance in reinforcement learning. It feels like a glimpse into the future: as AI systems become more capable and complex, the methods we use to optimize them can’t remain static. Traditional approaches are already starting to hit their limits. Newer techniques like GRPO show us how we might unlock the next level of capability and alignment in AI.
Table of contents
What is GRPO?
Group Relative Policy Optimization (GRPO) is a new approach to policy optimization for large language models. Unlike traditional methods that optimize policies in isolation, GRPO allows policies to optimize relative to groups of similar contexts or cases.

GRPO addresses a key challenge in Reinforcement Learning (RL), balancing exploration and exploitation while staying stable against the variability of training examples. It does this by:
- Grouping examples where context and rewarded behavior are similar
- Optimizing policies relative to group performance rather than only metric performance
- Maintaining consistency within contexts while allowing specialized adaptation
- Reducing variance in policy updates through group normalization
This enables more context-aware learning for policies in Large Language Models (LLMs), which must handle a wide range of behaviors across diverse contexts.
[43] # Simplified GRPO Implementation Concept
class GRPO:
def init (self, model, group size=8, relative threshold=0.1):
self.model = model
self.group size = group size
self.relative threshold = relative threshold
self.experience buffer = []
def group_experiences(self, experiences) :
“""Group experiences by contextual similarity""*
groups = []
for exp in experiences:
# Compute embedding for context similarity
context_embedding = self.model encode (exp. context)
# Find or create appropriate group
assigned = False
for group in groups:
if self.compute similarity (context embedding, group.centroid) > 0.
group .add(exp)
assigned = True
break
if not assigned:
groups .append ( ExperienceGroup( texp]))
return groups
def compute relative advantage(self, group):
"""Compute advantages relative to group performance"""
group baseline = np.mean([exp.reward for exp in group.experiences])
relative advantages = []
for exp in group.experiences:
relative adv = exp.reward - group baseline
relative advantages .append(relative adv)
return relative_advantagesWhy is GRPO Important?
GRPO is especially relevant in today’s AI landscape. As LLMs grow in scale and complexity, traditional policy optimization methods face limitations across three major challenges that GRPO aims to address:
- Sample Efficiency Crisis: Traditional methods often require very large datasets to converge reliably. GRPO’s group-based approach improves efficiency by pooling observations within batches, identifying relative patterns across similar contexts, and enabling models to learn effectively with fewer examples.
- Catastrophic Forgetting: Standard Reinforcement Learning (RL) methods struggle to retain proven behaviors when introduced to new contexts. GRPO’s relative optimization enforces group-based consistency, allowing models to adapt while maintaining performance across broader categories.
- Reward Sparsity: Many real-world applications involve delayed or sparse rewards, making absolute performance difficult to measure. GRPO helps models interpolate relative group performance, enabling learning even when rewards are infrequent.
Given the scale at which LLMs now operate; spanning creative writing, reasoning, mathematics, and even emotional intelligence; the ability to remain consistent and reliable across diverse contexts makes GRPO a critical advancement.

From PPO to GRPO: The Advancement of Policy Optimization
Policy Optimization Techniques have naturally progressed over time, and understanding this progression makes it clear why GRPO has emerged as a necessary solution for modern LLMs.
- PPO: When PPO was introduced, it reshaped how the community thought about efficient RL with its clipped objective function, which helped prevent overly large, destructive updates. While effective, PPO treats all training examples equally, ignoring similarities that could represent meaningful contextual groupings.
# Traditional PPO Loss Function
def ppo_loss(old_probs, new_probs, advantages, clip_ratio=0.2):
ratio = new_probs / old_probs
clipped_ratio = torch.clamp(ratio, 1 - clip_ratio, 1 + clip_ratio)
loss = -torch.min(ratio * advantages, clipped_ratio * advantages)
return loss.mean()- GRPO: GRPO builds on PPO by addressing this limitation. Instead of assuming all experiences are proportionate, it optimizes groups of similar examples together. This group-relative approach makes training more context-aware and improves policy performance.
# GRPO Enhanced Loss Function
def grpo_loss(groups, clip_ratio=0.2, group_weight=0.3):
total_loss = 0
for group in groups:
# Compute group-relative advantages
group_advantages = compute relative advantage(group)
# Traditional PPO loss within group
ppo_group_loss = ppo_loss(
group.old_probs,
group.new_probs,
group_advantages,
clip_ratio
)
# Group consistency term
consistency loss = compute group consistency(group)
# Combined loss
group_loss = ppo_group_loss + group_weight * consistency loss
total_loss += group_loss
return total_loss / len(groups)This shift from PPO to GRPO is not just a technical tweak but an evolution; from treating all experiences uniformly to adopting a more structured, context-sensitive approach.

Workflow of GRPO: A Deep Dive
Group Relative Policy Optimization (GRPO) is a coordinated workflow where multiple components interact to achieve more than any single Reinforcement Learning (RL) method can deliver alone. Before exploring the phases and limitations of the GRPO workflow, it’s useful to understand the core processes it employs; this helps explain how models like DeepSeek-R1 achieve their unique CSER capabilities.
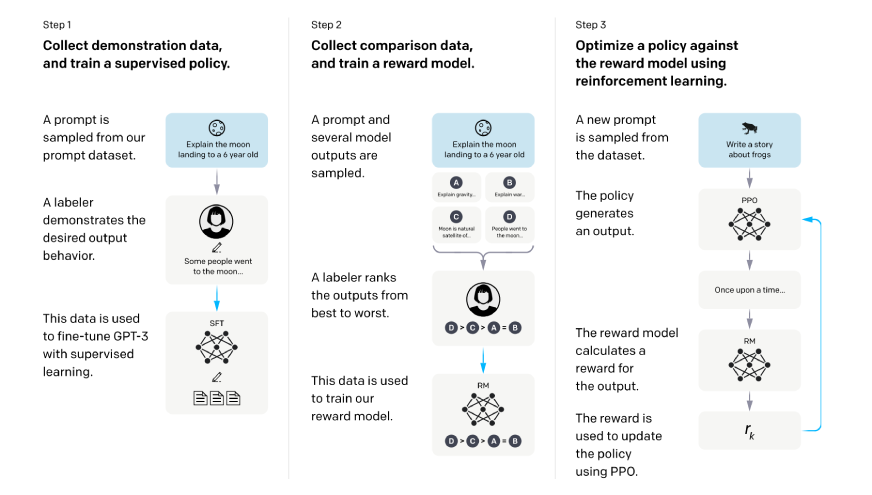
Phase 1: Experience Collection and Preprocessing
The GRPO workflow begins with a collection of experiences (interaction data) of how the LLMs interacted. Here, and more importantly than our prior, GRPO collects experiences of the LLMs in a way that is sensitive not only to the input-output pairs, but also considering contextual metadata that specifies the context with which the agents will decide their grouping actions.
Phase 2: Dynamic Grouping
This is the step that separates GRPO from the past efforts (in RL) as the system digests the experiences collected during the first phase, employs even more sophisticated embedding as understanding embeddings to discover natural grouping of similar experiences. The grouping algorithm contains relative attributes of the following;
- Semantic similarity of the input contexts
- Distribution of the rewards
- Complexity of tasks
- Temporal proximity of the experiences
Phase 3: Relative Advantages Calculation
For every grouping, GRPO calculates the advantages relative to the performance baseline of the group and not to a baseline of the entire population. With this basic potential artifact of conscious grouping, we can still execute to some extent our abilities to moderate conceptions of nuance in what will constitute good performance in various contexts.
Phase 4: Group-Aware Policy Updates
The last phase involves policy update using the calculated relative advantages while maintaining relevant uniformity within groups and across groups to ensure that performance improvements in one group do not lead to performance degradation in others.
# Complete GRPO Workflow Implementation
class GRPOTrainer:
def init__(self, model, config)
self.model = model
self.config = config
self.group_encoder = ContextualGroupEncoder()
self.advantage_computer = RelativeAdvantageComputer ()
def train_step(self, batch):
# Phase 1: Preprocess experiences
experiences = self.preprocess_batch(batch)
# Phase 2: Form groups dynamically
groups = self.group_encoder.form_groups (experiences)
# Phase 3: Compute relative advantages
for group in groups
group.advantages = self.advantage_computer.compute(group)
# Phase 4: Update policy with group awareness
loss = self.compute_grpo_loss(groups)
# Backpropagation and optimization
self .optimizer.zero_grad()
loss. backward()
self.optimizer.step()
return {
"loss': loss.item(),
‘num_groups': len(groups),
‘avg_group_size': np.mean([len(g) for g in groups])Also Read: A Guide to Reinforcement Fine-tuning
How DeepSeek-R1 Used GRPO?
DeepSeek-R1’s Group Relative Policy Optimization (GRPO) is considered one of the most advanced applications of this technique in Large Language Models (LLMs). Beyond implementation, new architectural features allow GRPO to integrate seamlessly within the model. DeepSeek-R1 was developed in response to the limitations of traditional policy optimization, aiming to handle complex reasoning tasks without sacrificing agility or consistency across diverse environments.

Multi-Scale Group Formation DeepSeek-R1 would componentize the hierarchy of groupings or nesting, meaning they operate at multiple scales at once. Micro scale for example – would mean combining individual reasoning steps together within the intertices of complex problems. Macro scale examples on the other hand, mean combining entire categories of problems together. With multi-scale GRPO, DeepSeek-R1 is capable of maintaining large-scale consistency across applications while simultaneously optimizing sub-components.
In addition to being able to make a reasoning-aware confidence computation, DeepSeek-R1 also uses reasoning-aware metrics for calculating its advantage metric. Not only does the system reward a correct answer response during evaluation of the reasoning process, it also rewards the reasoning steps taken along the path to a final answer, giving the system an opportunity to develop a reward signal that not only values the final answer, but also indicates the system to encourage better cognitive processes along the way.
# DeepSeek-R1 Reasoning-Aware GRPO
class DeepSeekGRPO:
def init__(self, reasoning model, verifier_model):
self.reasoning model = reasoning model
self.verifier_model = verifier_model
self.reasoning groups = {}
def compute_reasoning aware_advantage(self, reasoning trace) :
“""Compute advantages considering reasoning quality"""
steps = reasoning trace.decompose_steps()
step_scores = []
for step in steps:
# Score individual reasoning step
step_score = self.verifier_model.score_step(step)
step_scores.append(step_score)
# Find similar reasoning patterns in group
group_id = self.find_reasoning_group(reasoning trace)
group = self. reasoning groups[group_id]
# Compute relative advantage within reasoning group
group_baseline = np.mean([trace.final_score for trace in group])
relative advantage = reasoning trace. final_score - group_baseline
# Weight by reasoning quality
reasoning quality = np.mean(step_scores)
weighted advantage = relative advantage * reasoning quality
return weighted advantageDeepSeek-R1 Training Pipeline
The DeepSeek-R1 training pipeline integrates Group Relative Policy Optimization (GRPO) within a high-performing Large Language Model (LLM) framework, showing how advances in Reinforcement Learning (RL) can be applied in a scalable, practical system.
- Pre-training Foundation: The pipeline begins with pre-training on a curated dataset spanning multiple domains. Unlike conventional methods, this stage prepares the model for GRPO by including reasoning traces and annotations of intermediate steps.
- GRPO Integration Layer: At its core, an integration layer combines the pre-trained model with GRPO optimization, ensuring coherence while enabling group-specific adaptations.
- Multi-Objective Optimization: DeepSeek-R1 is trained with a framework balancing five goals:
- Accuracy: Deliver correct answers.
- Reasoning quality: Provide clear, logical rationales.
- Processing efficiency: Minimize computational overhead.
- Consistency: Maintain reliability across domains.
- Safety: Prevent biased or harmful outputs.

- Ongoing Assessment and Adjustment: The pipeline includes monitoring tools that track performance across diverse reasoning tasks. These insights allow continuous tuning of GRPO parameters and grouping strategies, ensuring the model maintains optimal performance as it evolves.
# DeepSeek-R1 Multi-Objective Training Pipeline
class DeepSeekRIPipeline:
def init__(self, base model, config):
self.base model = base model
self.grpo_optimizer = GRPOOp: er(config.grpo)
self.multi_obj_balancer = Multi0bjectiveBalancer (config. objectives)
self.safety checker = SafetyVerifier()
def training epoch(self, dataset)
metrics = {
taccuracy': (1,
‘reasoning quality’: [1,
‘efficiency’: [],
‘consistency’: [1,
"safety": []
}
for batch in dataset:
# Generate reasoning traces
traces = self.generate_reasoning_ traces (batch)
# Form groups using GRPO
groups = self.grpo optimizer. form groups(traces)
# Multi-objective evaluation
for group in groups:
group metrics = self.evaluate_group(group)
# Balance objectives
balanced loss = self.multi_obj_balancer.compute_loss(
group_metrics
)
# Safety filtering
safe_traces = self.safety checker. filter(group.traces)
# Update model
self.update model (safe traces, balanced_loss)
# Track metrics
for key, value in group metrics. items():
metrics [key] .append (value)
return {k: np.mean(v) for k, v in metrics.items()}What is Advanced GRPO?
As Group Relative Policy Optimization (GRPO) evolves, researchers will expand Policy Optimization Techniques to new levels of sophistication. Advanced GRPO implementations will be especially relevant for next-generation Large Language Models (LLMs) and complex Reinforcement Learning (RL) tasks.
- Hierarchical Grouping Structure: Future GRPO systems will implement hierarchical groupings across multiple abstraction levels. This will allow models to optimize accuracy within small, focused in-context interactions while ensuring consistency across broader, related groups.
- Adaptive Group Boundaries: Instead of fixed grouping, advanced GRPO will define boundaries dynamically, using performance metrics and data patterns to adapt group structures in real time.
- Cross-Group Knowledge Sharing: Knowledge transfer between related groups will become integral, enabling models to leverage learnings from one context to optimize others. This cross-pollination will significantly improve efficiency.
- Meta-Learning Linking: The most advanced GRPO systems will integrate meta-learning, creating optimization processes that evolve over time. Such systems won’t just improve task performance—they’ll also improve their ability to learn how to learn.
# Advanced GRPO with Hierarchical Structure
class AdvancedGRPO:
def init (self, model, hierarchy depth=:
self.model = model
self.hierarchy depth = hierarchy depth
self.group hierarchy = self. initialize hierarchy()
self.transfer_networks = self.create transfer_networks()
def hierarchical _grouping(self, experiences
“""Create hierarchical group structure""
hierarchy = {}
for level in range(self.hierarchy depth) :
if level == 0:
# Finest granularity
groups = self.cluster_by similarity(experiences, threshold=0.9)
else:
# Coarser granularity
parent_groups = hierarchy[level-1]
groups = self.merge_similar_groups(parent_groups,
threshold=0.7*level)
hierarchy[level] = groups
return hierarchy
def cross group transfer(self, source group, target_groups):
“Transfer knowledge between related groups*"
source patterns = self.extract_patterns (source group)
transfer weights = {}
for target in target_groups:
similarity = self.compute group similarity(source group, target)
if similarity > 0.6:
transfer weight = similarity * 0.3 # Controlled transfer
transfer _weights[target.id] = transfer weight
return transfer_weightsAdvantages of GRPO
GRPO offers several advantages beyond performance gains compared to standard Policy Optimization Techniques. It represents a broader shift away from the pitfalls of traditional RL in Large Language Models (LLMs) and provides remedies to fundamental challenges.
- Advanced Sample Efficiency: GRPO significantly improves sample efficiency by leveraging similarities across experiences. This allows models to learn from related contexts while ignoring minor perturbations—critical given the cost and scale of LLM training.
- Enhanced Stability and Robustness: Standard Policy Optimization often struggles with instability in high-dimensional action spaces. GRPO’s group-relative approach introduces natural regularization, preventing extreme updates and keeping training stable.
- Contextual Adaptability: GRPO enables models to adapt to specific, context-dependent tasks while maintaining overall consistency. This is essential for LLMs, which must handle everything from creative writing to technical analysis across diverse domains.
Limitations of GRPO
Although GRPO has clear benefits, it also comes with limitations that are important to consider when implementing it in LLMs or other RL systems.
- Computational Overhead: Group mechanics demand higher compute and memory. The system must evaluate similarity, maintain groups, and calculate relative advantages, adding processing load.
- Group Formation Sensitivity: Performance depends heavily on grouping methods. Poor grouping can lead to suboptimal or worse results than standard approaches, requiring robust algorithms and experimentation.
- Hyperparameter Complexity: GRPO adds parameters for thresholds, group size, and relative advantages. Tuning them is time-consuming and often requires expert knowledge.
- Domain Transfer Challenges: While effective in one domain, group structures may not transfer well to very different domains; a key challenge for LLMs operating across diverse tasks.
# GRPO Limitation Analysis
class GRPOLimitationanalyzer:
def _ init__(self):
self.compute_profiler
self.group_quality assessor = G
self.hyperparameter_sensitivity =
HyperparameterSensitivityAnalyzer()
def analyze limitations(self, grpo_system, baseline system)
“analyze GRPO limitations compared to baseline"
# Computational Overhead Analysis
overhead_analysis = self.compute_profiler.compare_overhead(
grpo_system, baseline system
)
# Group Formation Quality
group_quality = self.group_quality assessor.evaluate(
grpo_system. groups
)
# Hyperparameter Sensitivity
sensitivity analysis = self.hyperparameter_sensitivity.analyze(
grpo_system. config
)
return {
‘computational_overhead': overhead_analysis,
"group formation quality’: group_quality,
‘hyperparameter_ sensitivity’: sensitivity analysis,
‘recommendations’: self.generate_mitigation_strategies()
}
def generate mitigation_strategies(self)
"""Generate strategies to mitigate GRPO limitations"""
return [
"Implement efficient grouping algorithms with O(log n) complexity",
"use adaptive group size limits based on available resources",
"Employ automated hyperparameter optimization techniques",
“Implement group quality monitoring with fallback mechanisms"
]Use Cases
GRPO is inherently adaptable for many Reinforcement Learning (RL) use cases, envisioning RL’s use cases will showcase GRPO as an exceptional Policy Optimization Technique. Following are some examples:
- Conversational AI Systems: GRPO is strong for training conversational AIs, which need to respond contextually and must avoid differences between conversation types, and respond consistently with itself. Grouping allows a conversational AI to specialize for multiple conversation contexts (i.e., technical support, creative writing, education) while not allowing for negative transfer between domains.
- Code Generation and Programming Assistant: Large Language Models (LLM) for code generation have much to gain from GRPO, enabling the LLM to group similar programming contexts to optimize their training process. The model can specialize for programming languages, coding patterns, and complexity while enforcing standards across whole groups.
- Educational Content Generation: Anytime education is involved, GRPO can develop an individualized learning experience for each student. By creating groups based upon learning style, subject matter, and skill level, GRPO can focus its attention on optimizing the content generation to be highest quality for that group of students, while still adhering to the educational standards as a whole.
- Research and Scientific Support: Research based LLM’s use GRPO to optimally balance with respect to factual accuracy, creativity, and either general or discipline-specific knowledge. From its grouping capacities LLM’s are able to gain specialization in rich knowledge domains, while retaining expert performance quality in all phases.
Conclusion
GRPO is more than another optimization step; it marks a shift toward context-aware RL, enabling practical advances for LLMs. DeepSeek-R1 showed how GRPO delivers stable, secure, real-world performance, moving AI from simple pattern matching to reasoning systems. By optimizing across contextually similar groups, GRPO addresses core LLM challenges of sample efficiency, stability, and relative performance. Its potential is vast, offering a path to balance specialization with consistency as AI workflows evolve.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]



