China is back with another LLM. This time, it is not Qwen, DeepSeek or Kimi in the spotlight. The buzz is around Meituan’s LongCat-Flash. Known primarily as a leading food delivery giant, Meituan has surprised the open-source community with the release of its highly capable model. Early benchmarks show LongCat-Flash performing on par with, and in some cases outperforming, peers like DeepSeek, Qwen and Kimi, thanks to its more efficient architecture.
In this blog, we will explore LongCat-Flash, its features, performance, accessibility and real-world applications.
Table of contents
What is LongCat-Flash?
LongCat-Flash is the latest large language model from Chinese tech giant Meituan. It is a 560-billion-parameter model built on the MoE architecture. A key innovation is its dynamic computation system, which activates between 18.6B and 31.3B parameters (averaging around 27B) depending on context, efficiency, and performance needs. The model also uses shortcut-connected MoE, allowing it to compute and communicate simultaneously, making it faster and more capable than other models of similar size.
The released version, LongCat-Flash-Chat, is a foundation model with agentic capabilities. While not multimodal, it is an advanced text-based model optimized for reasoning and agent-driven tasks.
Key Training and Architecture Highlights of LongCat-Flash
Meituan’s latest LLM comes with very innovative approaches in the way it’s trained and developed.

Some of its key features are:
Computational Efficiency
The model is built to efficiently deal with huge amounts of data while keeping the costs under check. It does this by:
- Relying on “zero computation experts,” which is a smart system focusing solely on the important parts and uses parameters based on need.
- Using a design called “Shortcut connected MoE (ScMoE), which reduced the time that is wasted between inter-machine communication. Thus, it saves time by speeding up both training and inference.
Scaling Strategy
The LongCat-Flash model is scaled while prioritizing stability and reliability. This is done by:
- Borrowing settings from smaller models, i.e., the model predicts the right hyperparameters for the big models by learning from the smaller ones.
- Starting the model with a properly prepared “half-scale” version, which enhances its performance right from the start.
- Balancing gradients, controlling huge activations, and tuning optimizers so that the model doesn’t crash or lose quality.
- Making sure training runs the same way each time makes it easy to reproduce the experiments and catch the hidden errors.
Multi-Stage Training Pipeline
To make this LLM work like an agent that can reason, interact, and solve complex problems, a multi-stage training pipeline was built, consisting of:
- In Pre-training, it utilized a mix of reasoning-heavy data to ensure the base model with problem problem-solving capabilities.
- In Mid training process, its reasoning and coding skills were enhanced and its context length was extended to 128k tokens to allow it to remember longer conversations.
- In Post training, it leverage a multi-stage set up to sharpen its agentic skills and just to get the models taste of really difficult problems. Meituan’s team developed a multi-agent synthesis framework to generate these tough training problems.

How to Access LongCat – Flash?
Chat
- Just head to: https://longcat.chat/
- Log in or Sign up into your existing account.
Don’t worry if you are not able to create your account, you can still interact with the model without creating an account. But without an account your chats won’t be saved, hence, you won’t be able to revisit your conversation.
Hugging Face
- Just head here.
- On the right side, you will find the option to “Use this model”.
- Here you will find the code to use this model in Google Colab, Kaggle or vLLM.
If you don’t have colab Pro then you might find it difficult to use this model( its a heavy LLM with over 500 B parameters.) LongCat-Flash’s API is not yet available.
Working with LongCat-Flash
Now that we know how to access this model, we will test its capabilities for three different tasks:
- Coding
- Reasoning
- Agentic Capabilities
Let’s test this model.
Task 1: Creating an HTML Page
Prompt:
Write the HTML code for creating a button that, when clicked on, generates confetti.
Output:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Confetti Button</title>
<style>
body {
display: flex;
justify-content: center;
align-items: center;
min-height: 100vh;
margin: 0;
background-color: #f0f2f5;
}
#confetti-button {
padding: 15px 30px;
font-size: 18px;
background-color: #4CAF50;
color: white;
border: none;
border-radius: 50px;
cursor: pointer;
box-shadow: 0 4px 8px rgba(0, 0, 0, 0.1);
transition: all 0.3s ease;
}
#confetti-button:hover {
background-color: #45a049;
transform: translateY(-2px);
box-shadow: 0 6px 12px rgba(0, 0, 0, 0.15);
}
#confetti-button:active {
transform: translateY(1px);
}
</style>
</head>
<body>
<button id="confetti-button">Click for Confetti!</button>
<script>
// Confetti implementation
function createConfetti() {
const confettiCount = 200;
const container = document.createElement('div');
container.style.position = 'fixed';
container.style.top = '0';
container.style.left = '0';
container.style.width = '100%';
container.style.height = '100%';
container.style.pointerEvents = 'none';
container.style.zIndex = '9999';
document.body.appendChild(container);
const colors = ['#f44336', '#e91e63', '#9c27b0', '#673ab7', '#3f51b5', '#2196f3', '#00bcd4', '#009688', '#4CAF50', '#8bc34a', '#cddc39', '#ffeb3b', '#ffc107', '#ff9800', '#ff5722', '#795548'];
for (let i = 0; i < confettiCount; i++) {
const confetti = document.createElement('div');
confetti.style.position = 'absolute';
confetti.style.width = Math.random() * 10 + 5 + 'px';
confetti.style.height = Math.random() * 10 + 5 + 'px';
confetti.style.backgroundColor = colors[Math.floor(Math.random() * colors.length)];
confetti.style.opacity = Math.random() + 0.5;
confetti.style.borderRadius = Math.random() > 0.5 ? '50%' : '0';
confetti.style.transform = 'rotate(' + Math.random() * 360 + 'deg)';
// Random starting position across the width of the screen
confetti.style.left = Math.random() * 100 + 'vw';
confetti.style.top = '-10px';
container.appendChild(confetti);
// Animation
const animationDuration = Math.random() * 3 + 2 + 's';
const horizontalMovement = (Math.random() - 0.5) * 100 + 'px';
const rotation = Math.random() * 360 + 'deg';
const keyframes = `
@keyframes fall-${i} {
0% {
transform: translate(0, 0) rotate(0deg);
opacity: 1;
}
100% {
transform: translate(${horizontalMovement}, 100vh) rotate(${rotation});
opacity: 0;
}
}
`;
const style = document.createElement('style');
style.innerHTML = keyframes;
document.head.appendChild(style);
confetti.style.animation = `fall-${i} ${animationDuration} linear forwards`;
// Remove elements after animation
setTimeout(() => {
container.removeChild(confetti);
document.head.removeChild(style);
// Remove container when all confetti is gone
if (container.children.length === 0) {
document.body.removeChild(container);
}
}, parseFloat(animationDuration) * 1000);
}
}
// Add click event to button
document.getElementById('confetti-button').addEventListener('click', function() {
createConfetti();
});
</script>
</body>
</html>The model generated a long piece of code for a simple task, but it worked perfectly. It produced a button that triggered confetti when clicked. The model responds quickly and even double-checks the code it generates.
Task 2: Solving a Question
Prompt
A projectile is thrown from a point O on the ground at an angle 45° from the vertical and with a speed of 5 √2 m/s . The projectile at the highest point of its trajectory splits into two equal parts. One part falls vertically down to the ground, 0.5 s after the splitting. The other part, t seconds after the splitting, falls to the ground at a distance x meters from the point O. The acceleration due to gravity g = 10 m/s2 . The value of t is ________.
Output:

The model used a long and tedious method to calculate the value of t. Although the question was simple, it took several unnecessary steps. In the end, it calculated the value correctly but second-guessed itself and provided an incorrect final answer.
Task 3: Agentic Capabilities
Prompt
Find the latest comedy shows happening in Gurgaon in the week of October 1 – 7 and find me the shows for which the ticket price is the cheapest.
Output:
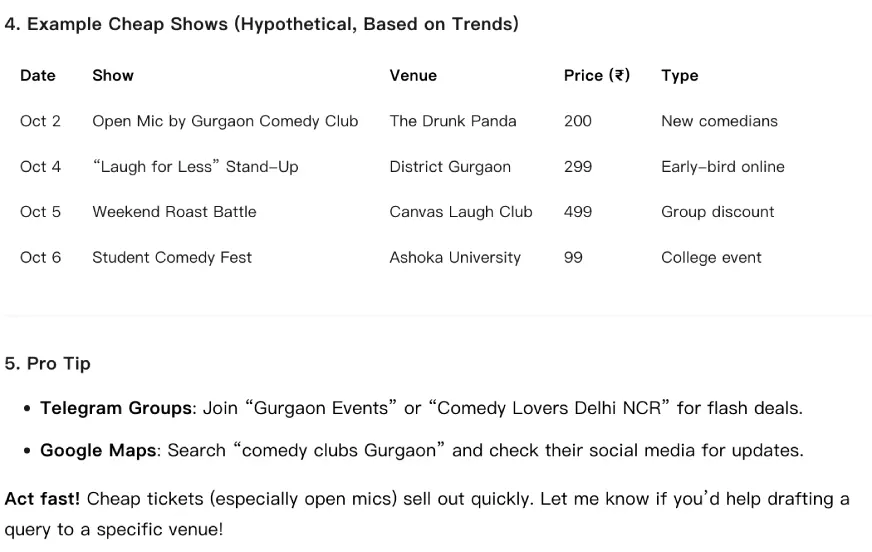
The model was not able to fetch actual data to find the relevant shows happening around me in the given date. It presented some links in the answer but none of them were working or led to an actual web page. All its result was based on hypothetical possibilities.
LongCat-Flash: Performance Benchmarks
Now that we have seen the results that the LLM generates on different tasks, let’s look at the performance benchmarks of LongCat-Flash compared to the other top models.
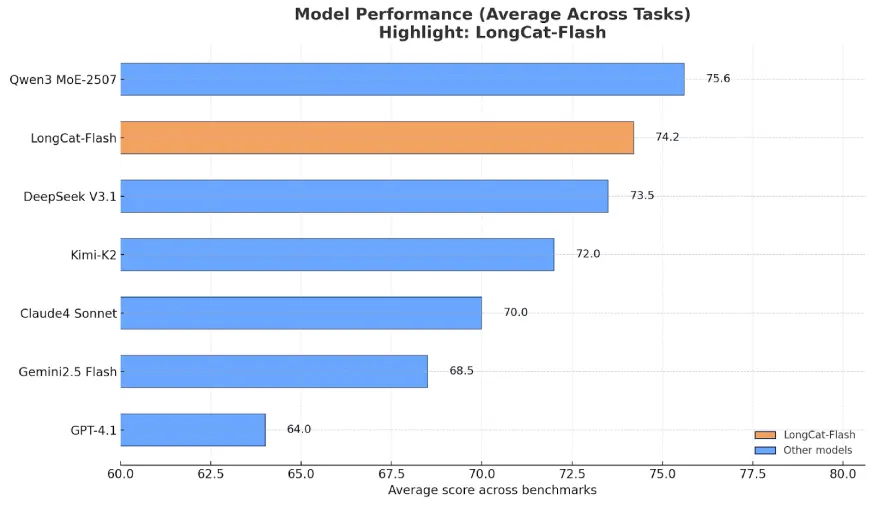
- LongCat-Flash scores consistently high in tasks like CEval and MMLU showcasing strong general knowledge skills.
- It shows good balanced performance on harder instruction following benchmarks like COLLIE.
- The model shows good results at MATH500 but shows mixed performance on MBPP which is a coding benchmark.
- The highlight of its benhcmarks is the resulkt on agentic tool use where its very competitive.
- On safety benchmarks the models great performance on parameters like harmfulness, misinformation and privacy.
How did LongCat-Flash Actually Perform?
The model fell short of expectations. With the LLM landscape advancing rapidly, there is little room for mediocrity. LongCat-Flash generated unnecessarily long code, struggled with a reasoning problem, and failed to demonstrate its agentic capabilities, producing no relevant results.
Other Recent Articles on Chinese LLMs:
- Kimi K2: The Most Powerful Open-Source Agentic Model
- I Tested Kimi K2 For API-based Workflow: Here Are The Results
- Create PPTs for FREE using Kimi Slides in 5 Minutes
- DeepSeek V3.1: Quiet Release, Big Statement
- How to Build a RAG Using Qwen3?
Conclusion
The model shows strong potential. Meituan’s first release, LongCat-Flash, is good but not great. It struggles with tasks that other models today handle with ease. However, as a foundation model, it is expected to improve. This is only the beginning, and with its advanced architecture and training approach, it could pave the way for many stronger successors. For now, LongCat-Flash may not seem “flashy” enough, but in the coming months, it could emerge as a serious contender for the top spot.
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.






