Off late, I’ve been wondering if I really need paid subscriptions to ChatGPT or Claude anymore. China has been rolling out one impressive LLM after another, and the latest, GLM 4.6, is being hailed as one of the best yet. This model rivals Claude 4.5 Sonnet in coding and matches GPT-5 and Gemini 2.5 Pro in text generation and reasoning. And here’s the kicker: while the big tech players charge anywhere between $10 to $30 per month for similar features, GLM 4.6 gives you access to all of it for free. In this post, we’ll explore GLM 4.6, how to access it, its features, performance benchmarks, and a hands-on test on real-world tasks.
Let’s get started with GLM 4.6!
Table of contents
What is GLM 4.6?
Developed by the Chinese company Zhipu AI, GLM 4.6 is the latest large language model and an upgrade over its predecessor, GLM 4.5. It is a text generation model that works solely with text as both input and output. The model includes improved coding, reasoning, and agentic capabilities, allowing it to proactively choose the right tool for a given task from the set of tools available.
Key Features of GLM 4.6
- Enhanced Context Window: GLM 4.6 boasts a context window of 200K tokens, which is significantly larger than GLM 4.5’s 128K window.
- Better Reasoning and Agentic Capabilities: The model demonstrates improved reasoning and agentic performance. It integrates smoothly with agent frameworks and delivers more consistent, reliable outputs.
- Better Coding: GLM 4.6 performs exceptionally well on coding benchmarks and integrates effectively with tools like Claude Code, Cline, and Kilo Code.
The best part?
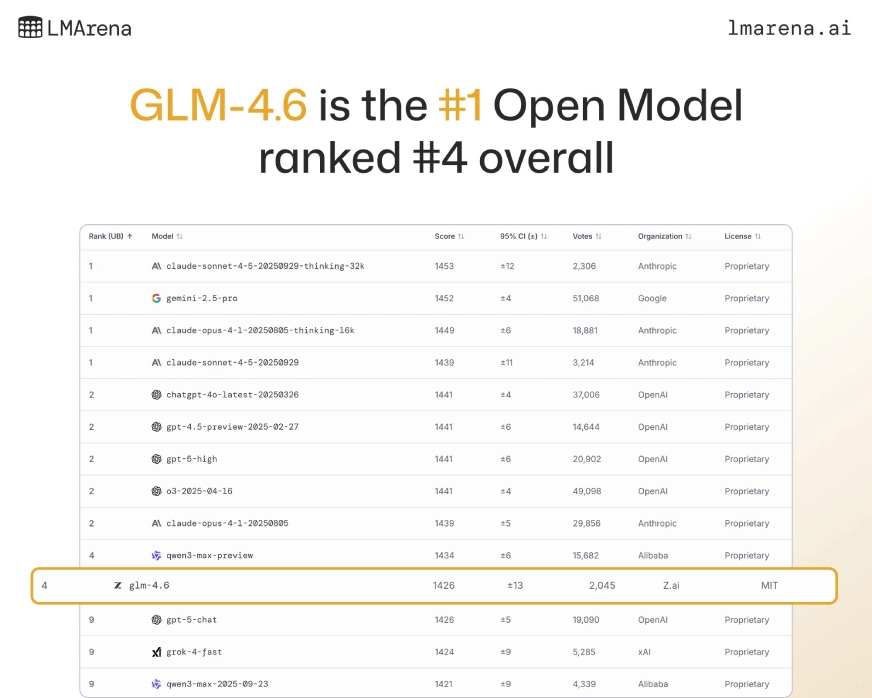
The GLM 4.6 model weights are publicly available on Hugging Face under the MIT license, making it an open-access model. In fact, it currently ranks #1 among open models and #4 overall on the LMArena leaderboard.
Is GLM 4.6 Free or Paid?
The model can be accessed freely through its chat platform. Here the chatbot assists you with all possible tasks be it involving text generation, coding, editing. But the API it incurs some cost which depends on the usage and the cost for input and output tokens. Finally, GLM-4.6 comes in a Coding Plan where it costs around $3/month for its light version to $15/month for the pro version.
How to Access GLM-4.6?
Anyone can access this model using its chat interface or API.
To access it using Chat interface:
- Head to this link.
- Login or Sign up to create your account.
- From the dropdown present at the top, in the middle of the screen, select the model GLM-4.6
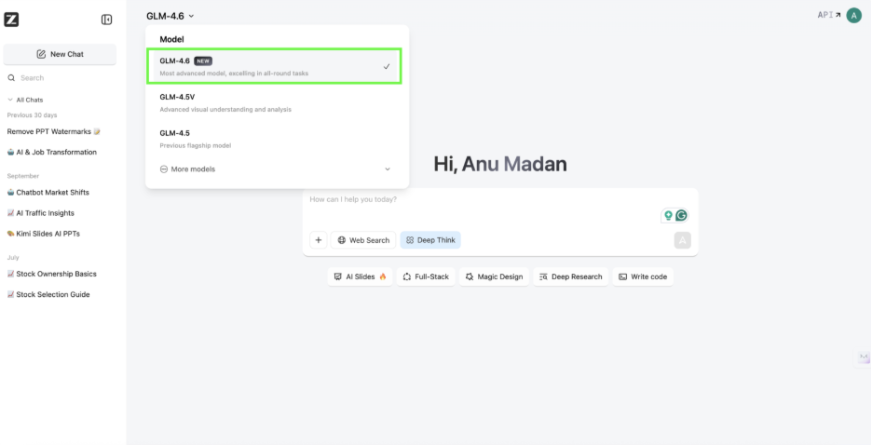
- Add the prompt in the chatbox in the middle of the screen.
To access GLM-4.6 using API:
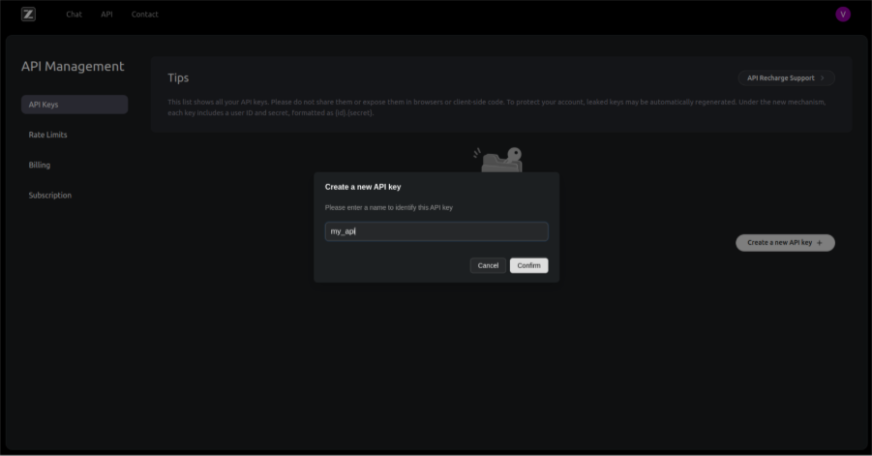
- Visit this website and click on ‘API keys’
- If you don’t have a pervious account then create a new account or signup with Google
- Now click on ‘Create new API key’ and give a name to your API and click on ‘confirm’
Real World Tasks with GLM-4.6
In this section, we will put this latest LLM to test on three main tasks around:
- Coding
- Reasoning
- Agentic Capabilities
Let’s start with the first one!
Coding
Prompt: “Create a stock market analysis app, that suggests people how to diversify their investment based on their future goals”
Output:
Review:
I got a stellar output from this LLM. I selected the “Full Stack” tool after writing my prompt to make sure the model understood it needed to build a prototype for my idea. The request was to create a market analysis app that could help users figure out how much to invest and how to align their investments with future goals.
The generated webpage included several tabs: Dashboard, Investment Goals, Portfolio Analysis, and AI Recommendations. Each tab served a clear purpose, helping users plan, track, and optimize their investments based on their goals. I found the entire interface user-friendly and interactive, especially the sections on Investment Goals and AI Recommendations, which provided actionable insights and a smooth experience.
Reasoning
Prompt: “Analyze the image and describe what’s happening. Follow the arrows to trace the trajectory of closed- vs. open-source models on the scale shown. Interpret what this means, explore its implications, and provide a focused deep-dive into the future of open-source models. Support your conclusions with simple, clear charts or visuals to make insights easy to understand.”
Output:
Review:
The model first gave the response in Chinese, so I asked it to provide it in English. It correctly read the image, identifying where each LLM stood and where the arrows pointed. But its reasoning was not accurate. The model’s interpretation was far from what the image implied.
The image showed that the gap between open-source and closed-source models is decreasing, but the model said the divide is increasing. It also created a mind map for the future of open-source models, which looked good, but the content was mostly incorrect.
Agentic Capabilities
Prompt: “I want the complete list of tariffs imposed by Trump on different countries, the change in tax rates before and after tariffs and the possible impact on both the economies of that country and USA after the imposition of those tariffs. Create a visualization of the overall tariffs imposed by trump on various countries and the graph of the economic impact.”
Output:
Review:
At first glance, the output looks detailed and complete. It seems to cover everything you asked for. But as always, it’s important to read it carefully before relying on it. The model begins well, explaining the impact of the Trump tariffs, but the problems appear in the details. The tariff rates it listed were only updated until April 9, and even after several tries, the model failed to include the latest data. This shows a clear limitation in its agentic capabilities.
Performance and Benchmarks
GLM 4.6 performs strongly across key benchmarks for reasoning, coding, and agentic tasks, showing noticeable gains over GLM 4.5 and competing models:

- AIME 25: Highest overall score, leading in reasoning with tools.
- GPQA & LiveCodeBench v6: Strong performance in problem-solving and coding accuracy.
- BrowseComp: Significant improvement in browsing and comprehension tasks.
- SWE-bench Verified: Competitive results, close to Claude models.
- HLE & Terminal-Bench: Moderate scores with room for improvement.
- τ²-Bench: Slightly behind Claude Sonnet but still solid.
Also Read: 14 Popular LLM Benchmarks to Know in 2025
Is GLM-4.6 better than GPT-5 or Gemini 2.5 Pro or Claude Sonnet 4.5?
So far for me, I think the answer to this question is NO. The model comes with a huge context window, but its reasoning and agentic capabilities do not stand a chance against the top models by OpenAI or Google. The model is fast but somehow hallucinates in the way it retrieves and processes information. On the coding front, it shows significant improvement from the last model and with its integrations on top coding tools like Claude Code – this model is set to be a companion for coders at a cheaper price tag.
Other major releases:
- DeepSeek-V3.2-Exp: 50% Cheaper, 3x Faster, Maximum Value
- Qwen3-Omni Review: Multimodal Powerhouse or Overhyped Promise?
- Kimi OK Computer: A Hands-On Guide to the Free AI Agent
Conclusion
GLM 4.6 isn’t a model you’d use for everyday tasks. Even though it’s free, its responses are less reliable than those from other models. LLMs have improved rapidly over the past few months, and many open models now show impressive sophistication. In comparison, GLM 4.6 still falls short of that standard. However, it has received positive feedback for its coding performance. We can expect its outputs to improve in the coming days.
Give it a try and let me know if you agree with my review.
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.






