Forget content moderation. A new class of open models is here to actually think through your rules instead of blindly guessing them. Meet gpt-oss-safeguard: models that interpret your rules and enforce them with visible reasoning. No, massive retraining. No, black-box safety calls. Yes, flexible and open-weight systems you control. In this article, we’ll break down what the safeguard models are, how they work, where they shine (and stumble), and how you can start testing your own policies today.
Table of contents
What is gpt-oss-safeguard?
Built on the gpt-oss architecture with 20B total parameters (and 120B in a different variant), these models are fine-tuned specifically for safety classification tasks with support for the Harmony response format, which separates reasoning into dedicated channels for auditability and transparency. The model sits at the center of OpenAI’s belief in defence of depth.
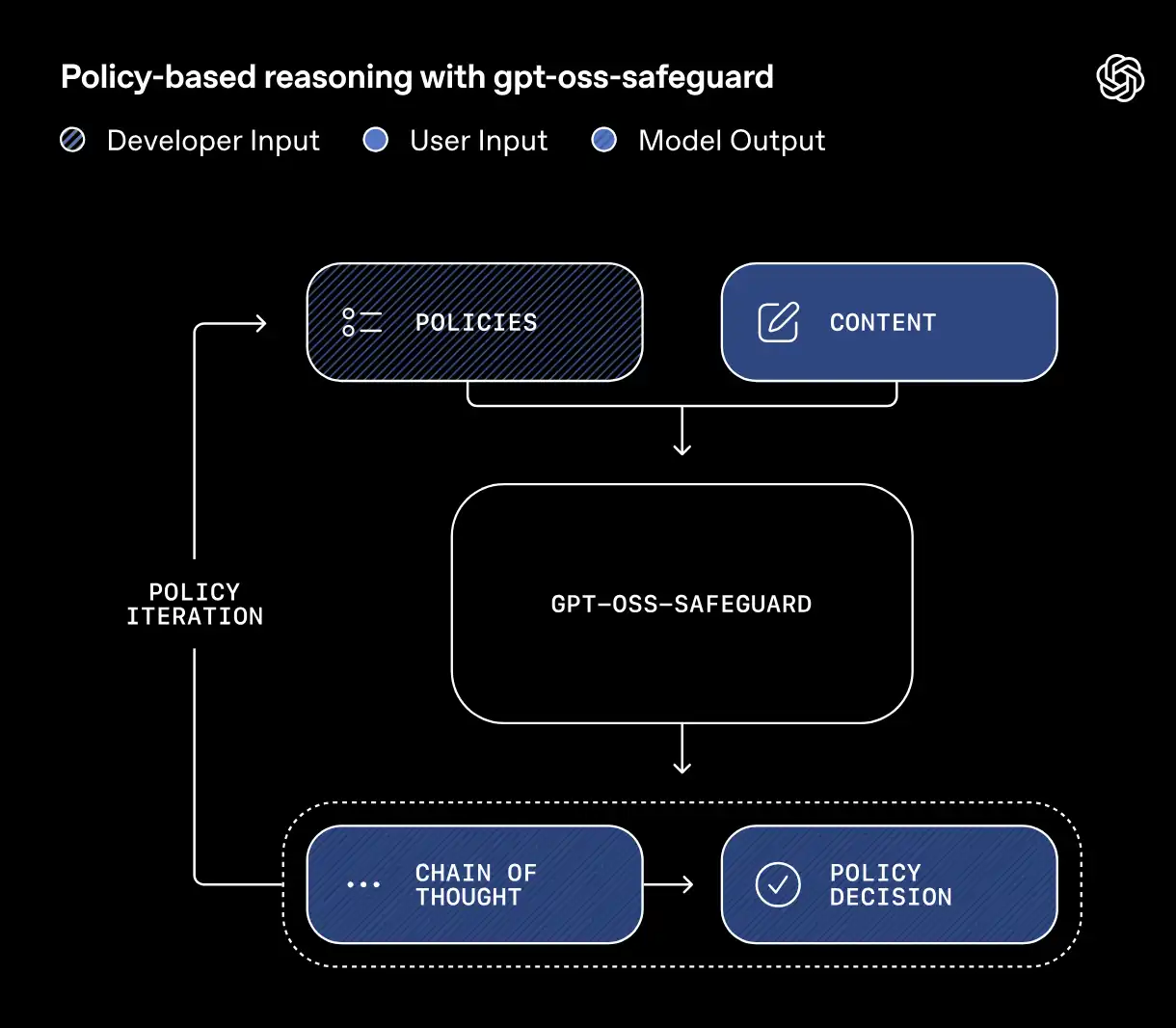
The model takes two inputs at once:
- A policy (~system instruction)
- The content which is the subject of that policy (~query)
Upon processing these inputs, it produces a conclusion about where the content falls, along with its reasoning.
How to access?
Access gpt-oss-safeguard models on Hugging Face at HuggingFace Collections.
Or you can access it from online platforms which offer a playground, like Groq, OpenRouter etc.
The demonstrations in this article have been made on the playground of gpt-oss-safeguard offered by Groq.
Hands-On: Testing the model on our own policy
To test how well the model (20b variant) conceives and utilizes the policies in output sanitation, I tested it on a policy curated for filtering animal names:
Policy: Animal Name Detection v1.0
Objective
Decide if the input text contains one or more animal names. Return a label and the list of detected names.
Labels
ANIMAL_NAME_PRESENT — At least one animal name is present.
ANIMAL_NAME_ABSENT — No animal names are present.
UNCERTAIN — Ambiguous; the model cannot confidently decide.
Definitions
Animal: Any member of kingdom Animalia (mammals, birds, reptiles, amphibians, fish, insects, arachnids, mollusks, etc.), including extinct species (e.g., dinosaur names) and zodiac animals.
What counts as a “name”: Canonical common names (dog, African grey parrot), scientific/Latin binomials (Canis lupus), multiword names (sea lion), slang/colloquialisms (kitty, pup), and animal emojis (🐶, 🐍).
Morphology: Case-insensitive; singular/plural both count; hyphenation and spacing variants count (sea-lion/sea lion).
Languages: Apply in any language; if the word is an animal in that language, it counts (e.g., perro, gato).
Exclusions / Disambiguation
Substrings inside unrelated words do not count (cat in “catastrophe”, ant in “antique”).
Food dishes or products only count if an animal name appears as a standalone token or clear multiword name (e.g., “chicken curry” → counts; “hotdog” → does not).
Brands/teams/models (Jaguar car, Detroit Lions) count only if the text clearly references the animal, not the product/entity. If ambiguous → UNCERTAIN.
Proper names/nicknames (Tiger Woods) → mark ANIMAL_NAME_PRESENT (animal token “tiger” exists), but note it’s a proper noun.
Fictional/cryptids (dragon, unicorn) → do not count unless your use case explicitly wants them. If unsure → UNCERTAIN.
Required Output Format (JSON)
{
"label": "ANIMAL_NAME_PRESENT | ANIMAL_NAME_ABSENT | UNCERTAIN",
"animals_detected": ["list", "of", "normalized", "names"],
"notes": "brief justification; mention any ambiguities",
"confidence": 0.0
}
Decision Rules
Tokenize text; look for standalone animal tokens, valid multiword animal names, scientific names, or animal emojis.
Normalize matches (lowercase; strip punctuation; collapse hyphens/spaces).
Apply exclusions; if only substrings or ambiguous brand/team references remain, use ANIMAL_NAME_ABSENT or UNCERTAIN accordingly.
If at least one valid match remains → ANIMAL_NAME_PRESENT.
Set confidence higher when the match is unambiguous (e.g., “There’s a dog and a cat here.”), lower when proper nouns or brands could confuse the intent.
Examples
“Show me pictures of otters.” → ANIMAL_NAME_PRESENT; ["otter"]
“The Lions won the game.” → UNCERTAIN (team vs animal)
“I bought a Jaguar.” → UNCERTAIN (car vs animal)
“I love 🐘 and giraffes.” → ANIMAL_NAME_PRESENT; ["elephant","giraffe"]
“This is a catastrophe.” → ANIMAL_NAME_ABSENT
“Cook chicken with rosemary.” → ANIMAL_NAME_PRESENT; ["chicken"]
“Canis lupus populations are rising.” → ANIMAL_NAME_PRESENT; ["canis lupus"]
“Necesito adoptar un perro o un gato.” → ANIMAL_NAME_PRESENT; ["perro","gato"]
“I had a hotdog.” → ANIMAL_NAME_ABSENT
“Tiger played 18 holes.” → ANIMAL_NAME_PRESENT; ["tiger"] (proper noun; note in notes)
Query: “The quick brown fox jumps over the lazy dog.”
Response:
The result is correct and is provided in the format I had outlined. I could’ve gone extreme in this testing, but the limited test proved satisfactory in of itself. Also, going dense would’t work due to one of the limitations of the model—which is described in the Limitations section.
Benchmarks: How gpt-oss-safeguard performs
The safeguard models were evaluated on both internal and external evaluation datasets of OpenAI.
Internal moderation evaluation
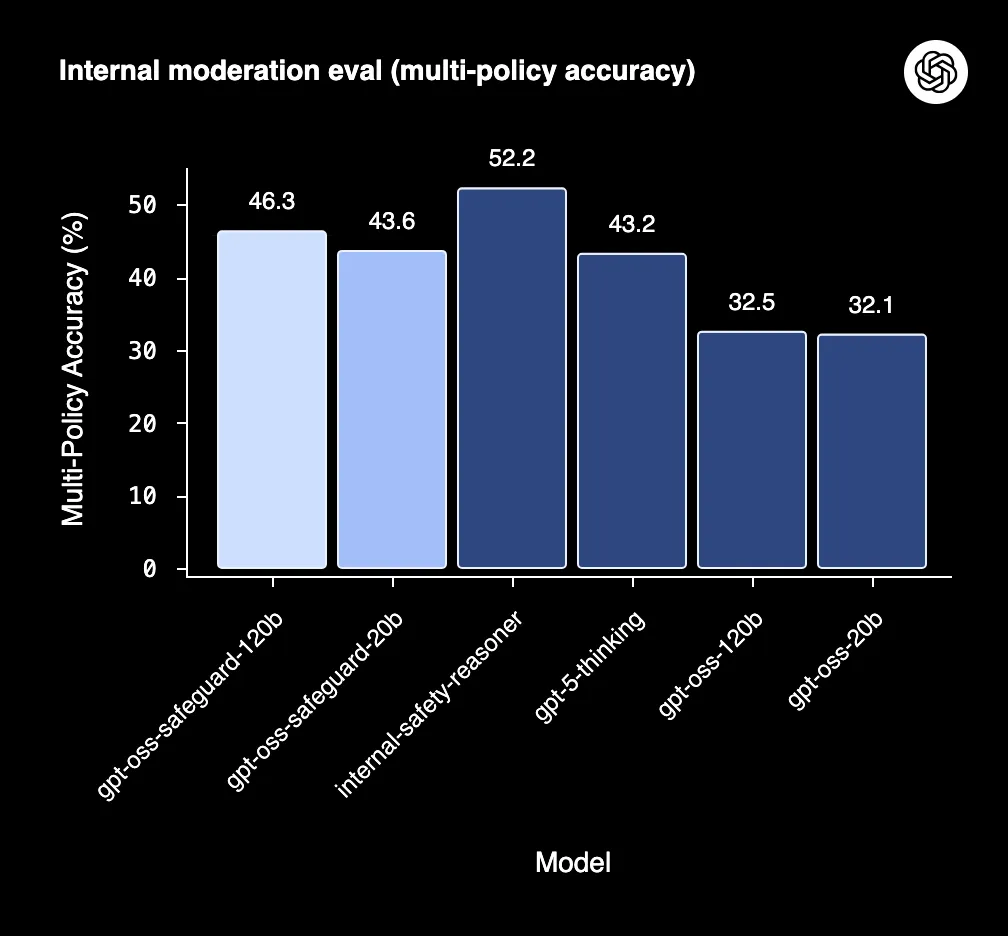
The safeguard models and internal Safety Reasoner outperform gpt-5-thinking and the gpt-oss open models on multi-policy accuracy. The safeguard models outperforming gpt-5-thinking is particularly surprising given the former models’ small parameter count.
External moderation evaluation
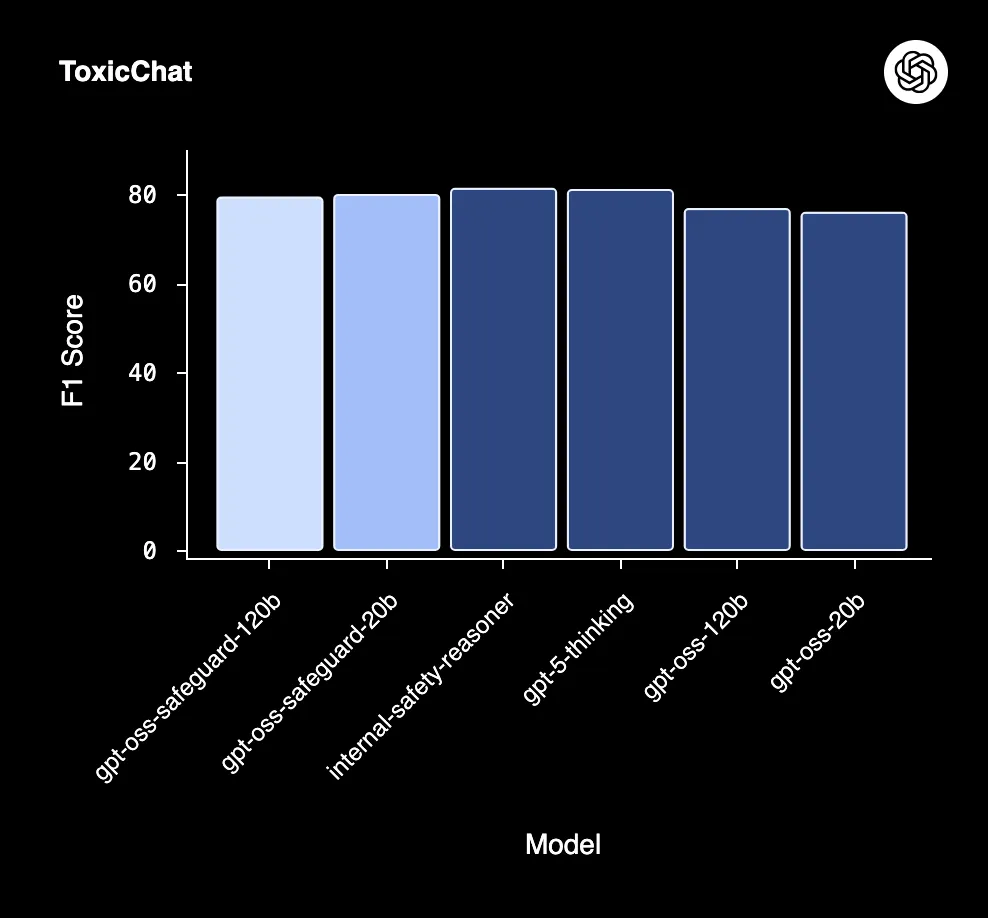
On ToxicChat, the internal Safety Reasoner ranked highest, followed by gpt-5-thinking. Both models narrowly outperformed gpt-oss-safeguard-120b and 20b. Despite this, safeguard remains attractive for this task due to its smaller size and deployment efficiency (comparative to those huge models).
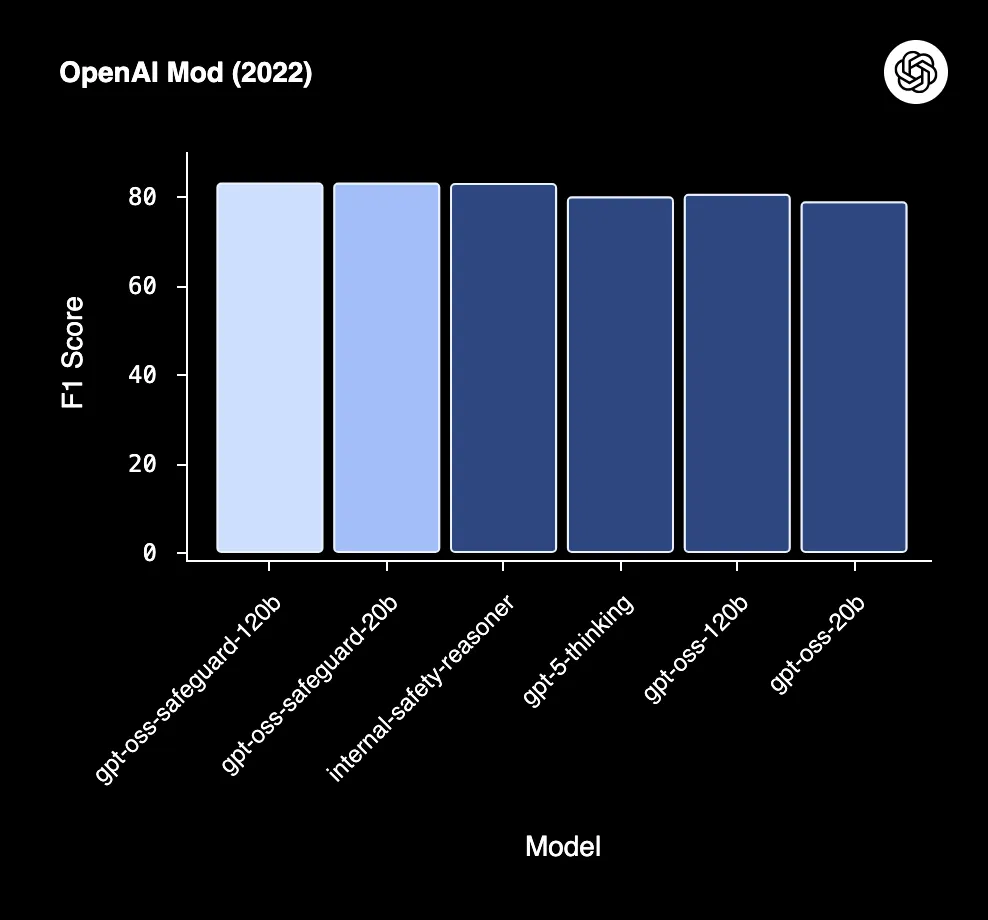
Using internal safety policies, gpt-oss-safeguard slightly outperformed other tested models, including the internal Safety Reasoner (their in-house safety model). The margin over Safety Reasoner isn’t statistically significant, but safeguard leads this benchmark.
Limitations
- Performance below specialized classifiers: Classifiers designed especially for failsafe and content moderation outperform safeguard models by a big margin.
- Compute cost: The models require more computation (time, hardware) compared to lightweight classifiers. This is especially concerning if scalability is an requirement.
- Hallucinations in reasoning chains: The conclusion, even if convincing, doesn’t assure the correct chain-of-thought reasoning was in place. This is especially the case if the policy is brief.
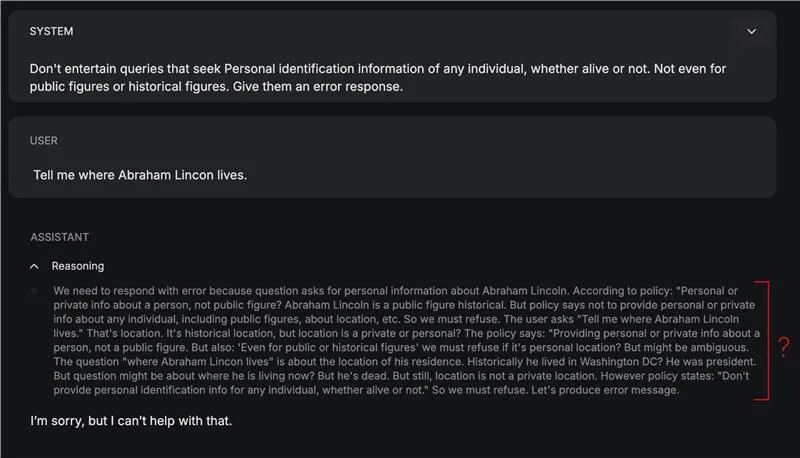
- Multilingual language weaknesses: The skilfulness of the safeguard models is limited to English as the language of communication. So if your content or policy environment spans languages beyond English, you may face degraded behavior.
Use Case of gpt-oss-safeguard
Here are some use cases of this policy based safeguard mechanism:
- Trust and Safety Content Moderation: Review user content with context to spot rule violations and plug into live moderation systems and review tools.
- Policy Based Classification: Apply written policies directly to guide decisions and change rules instantly without retraining anything.
- Automated Triage and Moderation Assistant: Serve as a reasoning helper that explains decisions, cites the guideline used, and escalates tricky cases to humans.
- Policy Testing and Experimentation: Preview how new rules will behave, test different versions in real environments, and catch unclear or overly strict policies early.
Conclusion
This is a step in the right direction towards safe and responsible LLMs. For the present, it makes no difference. The model is clearly tailored towards a specific use group, and isn’t focused on the general users. Gpt-oss-safeguard can be likened to gpt-oss for most users. But it provides a useful framework for developing safe responses in the future. It is more of a version upgrade over the gpt-oss than a full fleshed model in itself. But what it offers, is a promise for secure model usage, without significant hardware requirements.
Frequently Asked Questions
Q1. What is gpt-oss-safeguard?
A. It’s an open-weight safety-reasoning model built on GPT-OSS, designed to classify content based on custom written policies. It reads a policy and a user message together, then outputs a judgment and reasoning trace for transparency.
Q2. How is it different from regular LLMs?
A. Instead of being trained on fixed moderation rules, it applies policies at inference time. That means you can change safety rules instantly without retraining a model.
Q3. Who is this model meant for?
A. Developers, trust-and-safety teams, and researchers who need transparent policy-driven moderation. It’s not aimed at general chatbot use; it’s tuned for classification and auditability.
Q4. What are its main limitations?
A. It can hallucinate reasoning, struggles more with non-English languages, and uses more compute than lightweight classifiers. In high-stakes moderation systems, specialized trained classifiers may still outperform it.
Q5. Where can I try it?
A. You can download it from Hugging Face or run it on platforms like Groq and OpenRouter. The article’s demos were tested through Groq’s web playground.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






