With models like Gemini 3 Pro, ChatGPT 5.1 and SAM3 coming to the fray, Anthropic has been relatively quiet in terms of its releases. But this is to end now. Claude is here to announce itself with its latest offering Claude Opus 4.5 which is contesting for the spot of the best AI coding model. In this article, we’ll examine its coding prowess, real-world performance, and how to access it.
Table of contents
What is Claude Opus 4.5?
Claude Opus 4.5 is the most intelligent model that Claude 4.5 model family has to offer, combining maximum capability with practical performance. Ideal for complex specialized tasks, professional software engineering, and advanced agents. Opus had always been the magnum opus of the family, but due to its exorbitant pricing, never had a renown. But Claude Opus 4.5 features a more accessible price point than previous Opus models.
Key Features
Here are the key features of Claude Opus 4.5:
- State-of-the-art real-world coding: Opus 4.5 handles messy engineering problems without needing step-by-step coaching. It works through ambiguity, reasons about tradeoffs, and fixes issues earlier models simply couldn’t.
- Efficient code generation: The model writes clean, reliable code while using fewer tokens than previous iterations. You get tighter implementations with less overhead, which matters a lot when you’re shipping or iterating quickly.
- Multilingual proficiency: Whether you’re jumping between Python, Java, C++, or less common languages, Opus 4.5 stays consistent. It shows strong results across nearly every major language benchmark, which makes it a dependable choice for polyglot teams.
- Advanced planning and refactoring: Here’s where it separates itself from most models. Opus can outline multi-repo refactors, explain why a change is needed, and then follow through on the plan.
- Agentic workflow orchestration: The model is built for multi-step, multi-agent work. One agent can debug while another updates documentation, and Opus keeps everything coherent.
- Strong general intelligence: Although it’s framed as a coding model, Opus 4.5 shows clear lifts in reasoning, long-context accuracy, math, and visual understanding.
How to Access Claude Opus 4.5?
If you want to try Opus 4.5 yourself, there are several paths depending on your setup:
- Claude apps: Use it directly in the browser or desktop app using the Claude Apps interface. This requires the paid subscription for the tool.
2. Claude API for developers: Call the model Claude Opus 4.5 through the Anthropic API: Claude API Docs
3. Claude Code: Access Opus 4.5 for coding agents inside the desktop app: Claude Code
The best way to access Claude Opus 4.5 would be via. Windsurf, where the model is available for the credit requirement of Sonnet models. It is 10x cheaper than the token cost of Opus 4.1, which is a big plus.
Claude Opus 4.5 Pricing
To access Claude Opus 4.5 from the web interface, you need to have the Pro subscription which costs $20. If you are going to access it via API, then the token pricing for Opus 4.5 is:
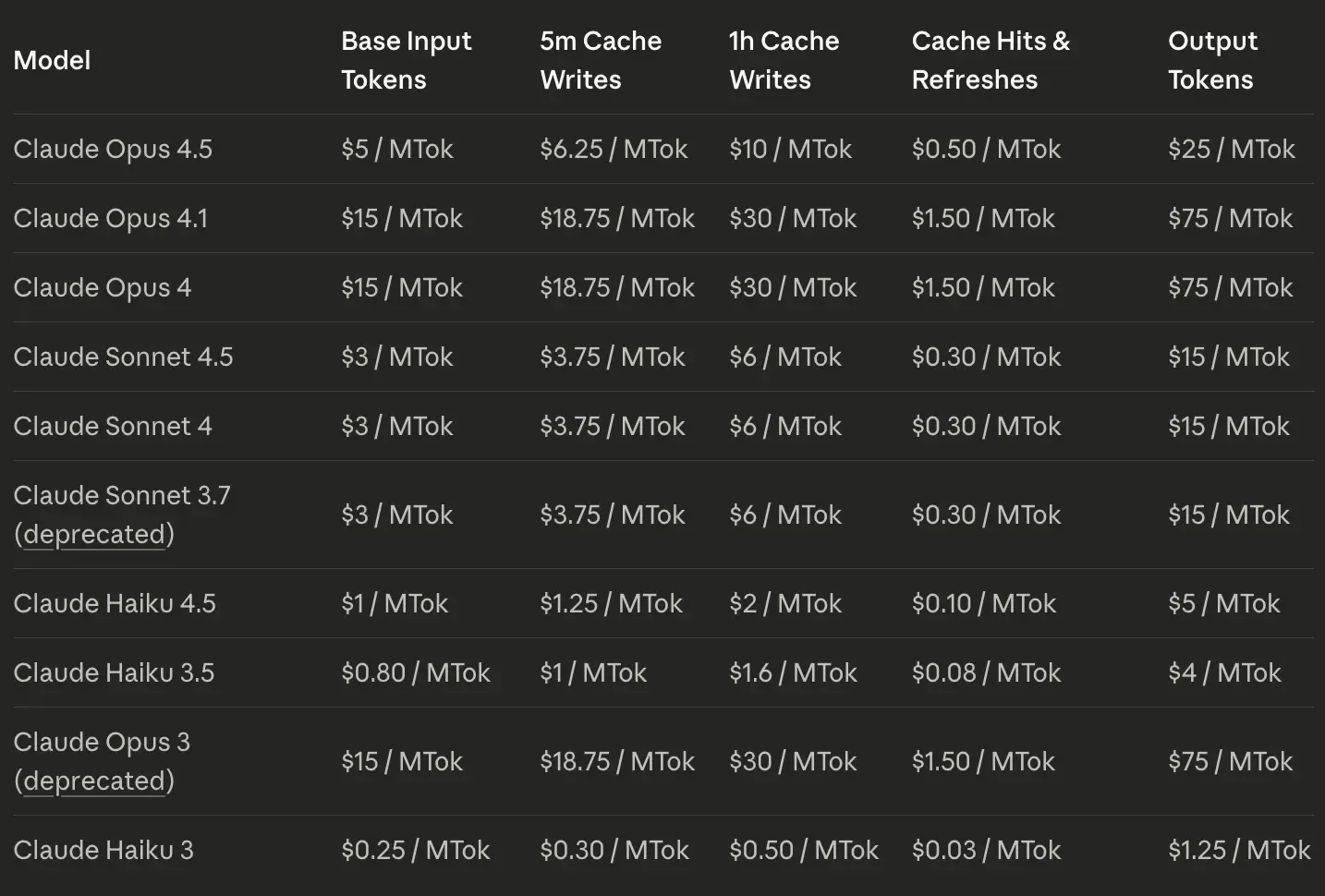
Claude Opus 4.5 is clearly cheaper, than any previous iteration of Anthropic’s Opus family. But there is a huge caveat that we’ll encounter soon: Limits!
Claude Opus 4.5 Benchmarks
Claude has been renowned for emphasising on the coding and reasoning prowess of its model, while presenting the benchmarks. But considering the claim of it being the best coding AI, I guess it makes sense in this regard.
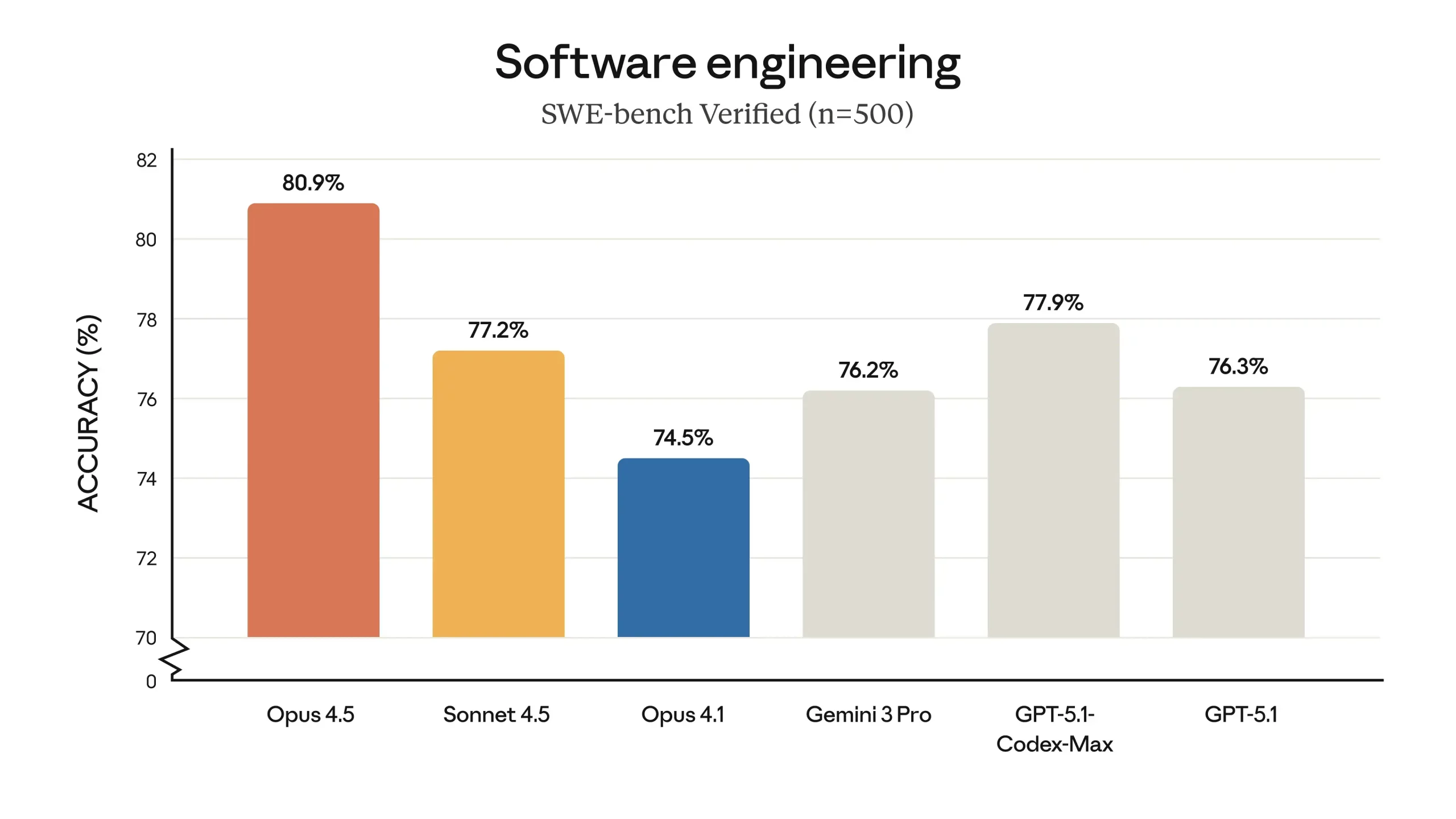
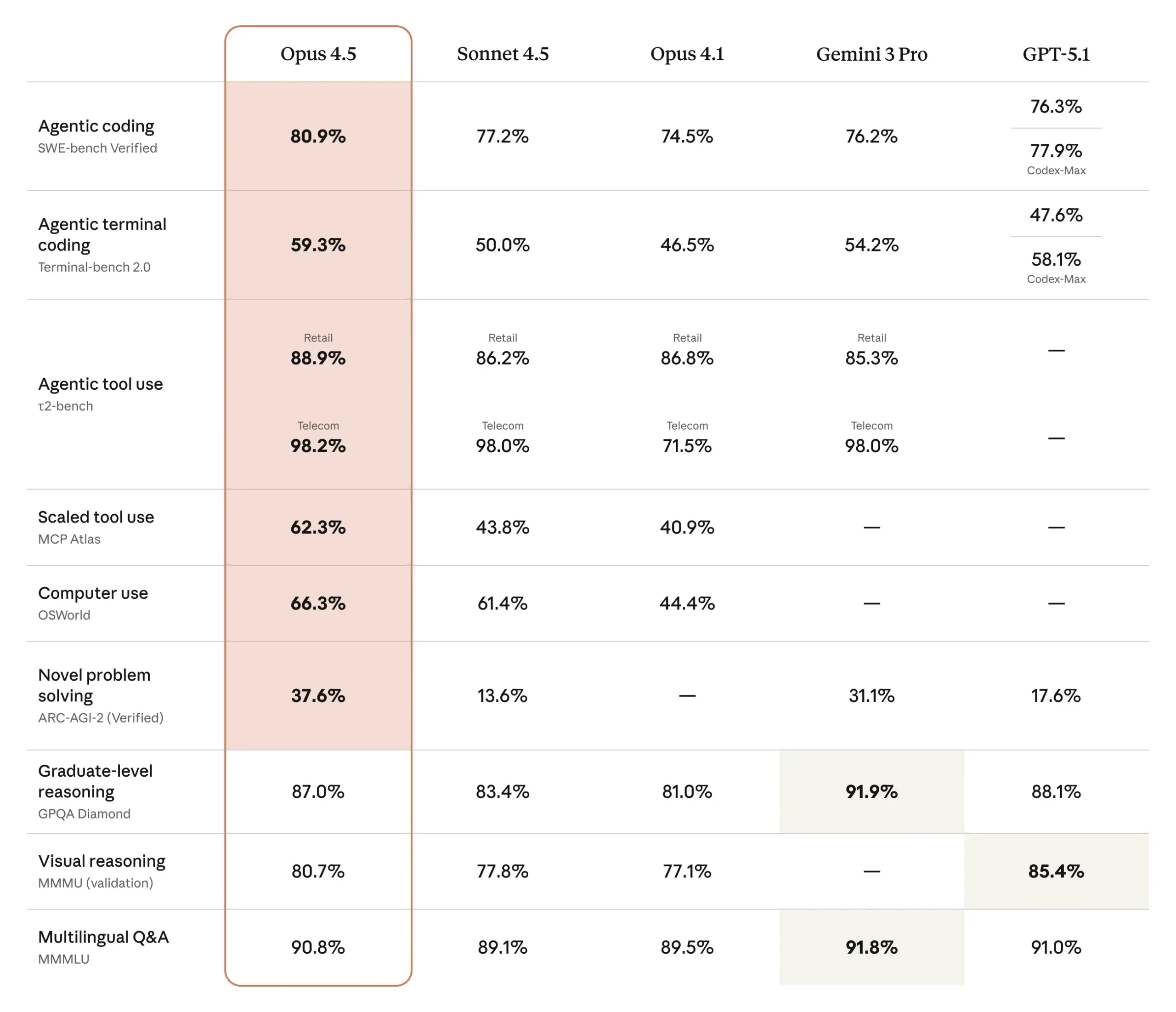
SWE-bench Verified: Opus 4.5 scores 80.9% on this real-world code challenge set (n=500), compare to 77.2% for Sonnet 4.5. This is a clear lead over other frontier models (GPT-5.1 Codex-Max was 77.9%).
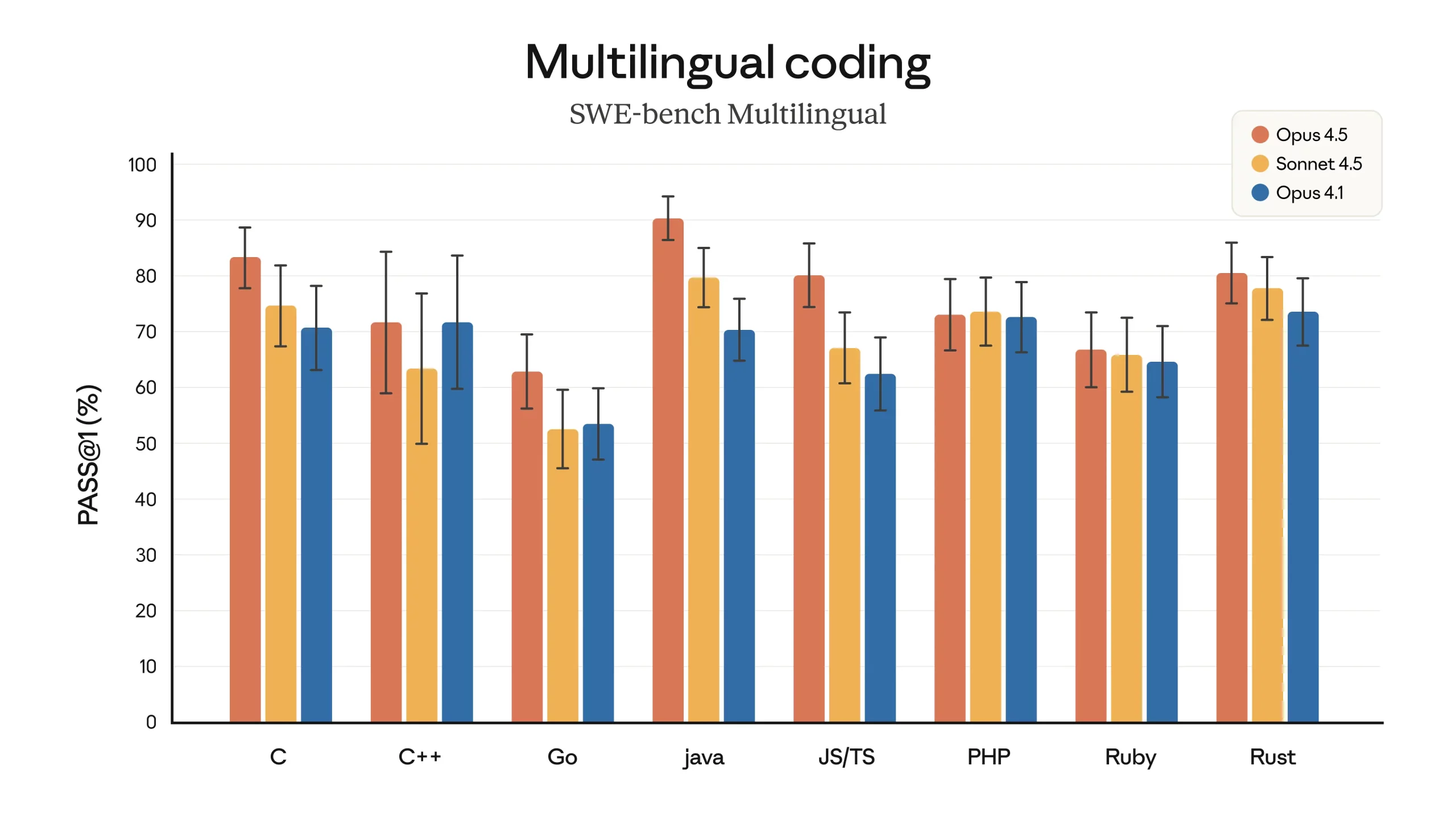
Multilingual Coding: On SWE-bench Multilingual, Opus 4.5 leads in 7 of 8 languages 7, often scoring ~10–15% higher than Sonnet 4.5 in languages like Java and Python.
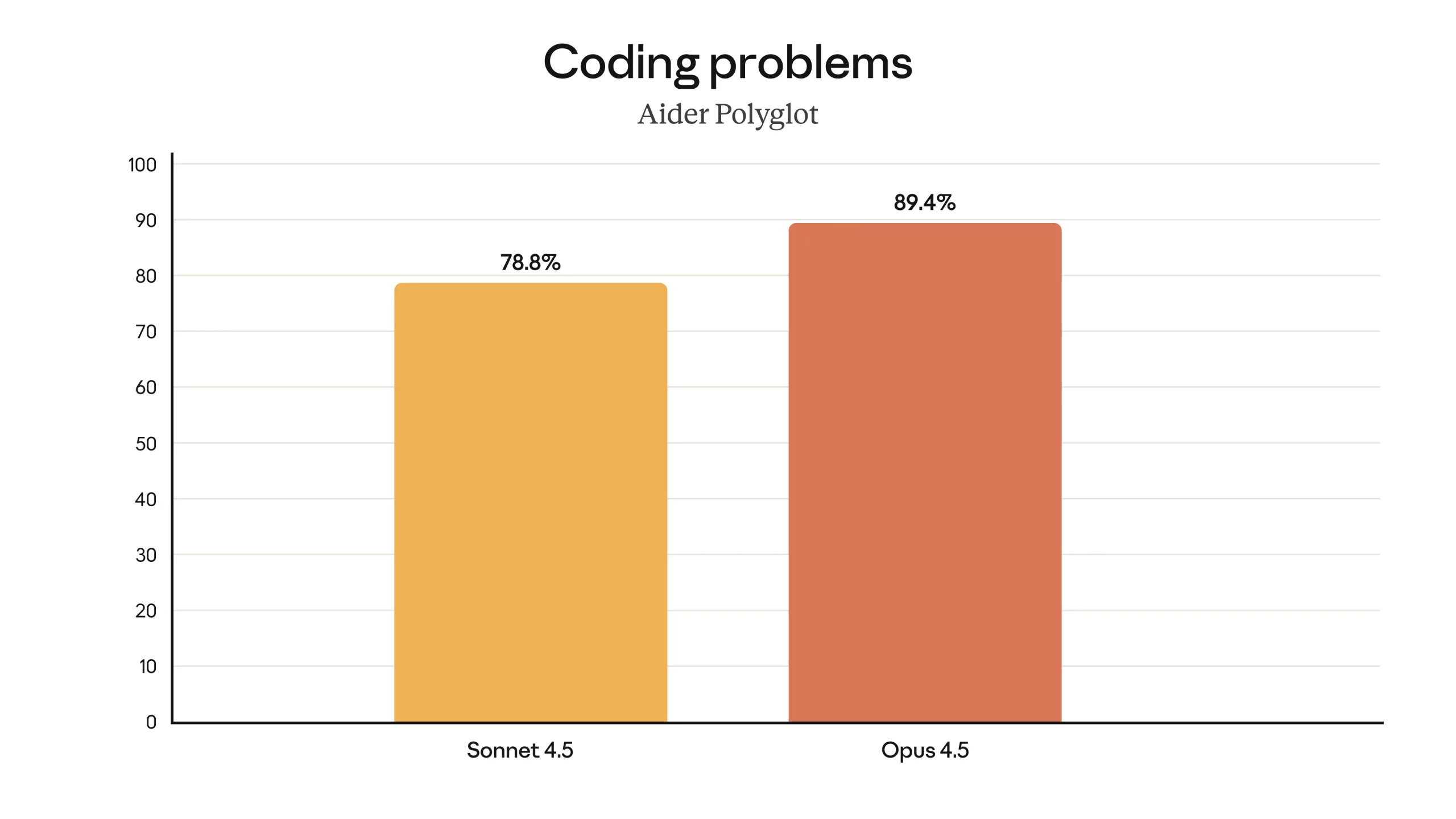
Aider Polyglot: Opus 4.5 is 10.6% better than Sonnet 4.5 at solving tough coding problems in multiple languages.
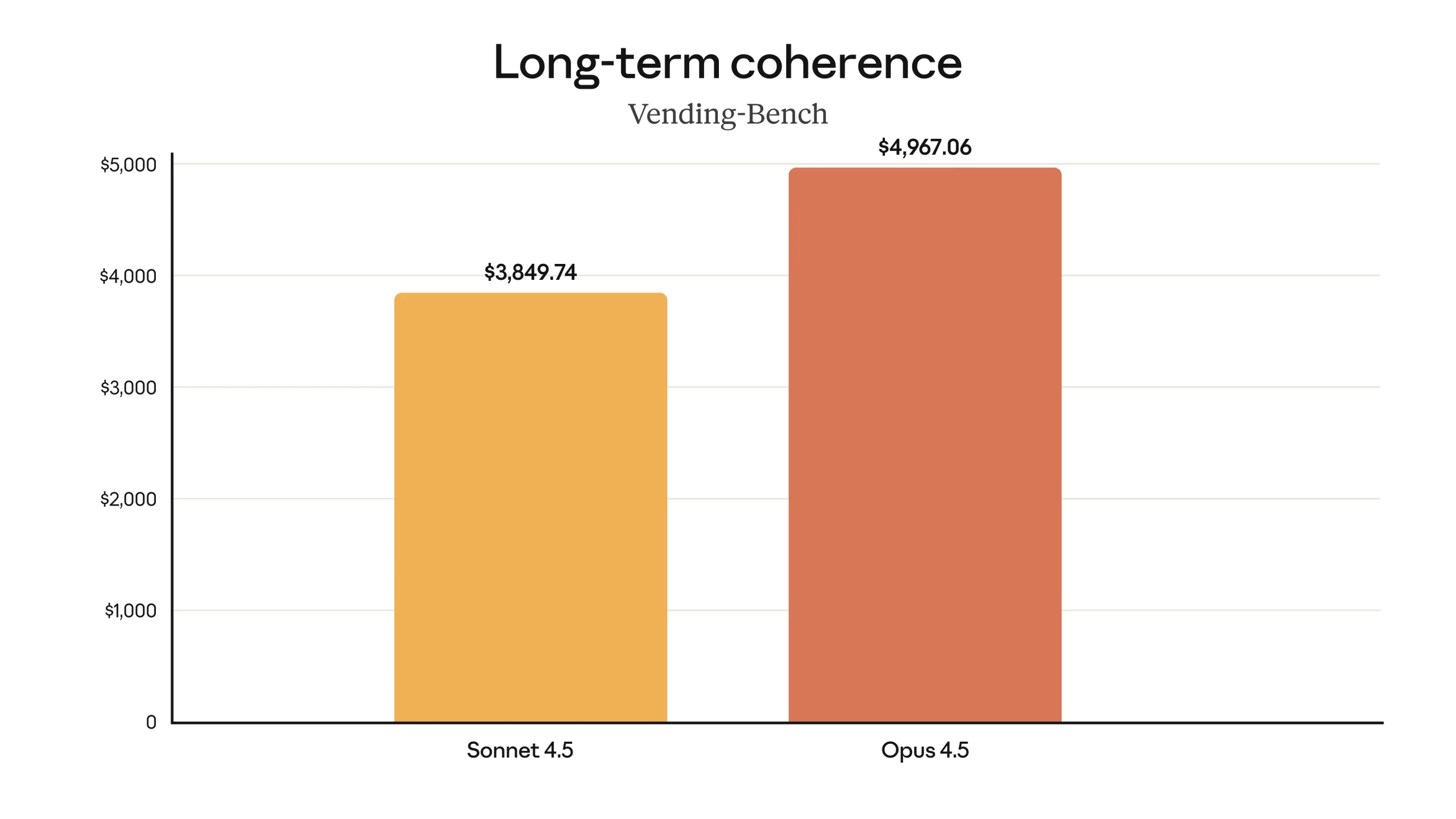
Vending-Bench (Long-term Planning): Opus 4.5 earns 29% more reward than Sonnet 4.5 in a long-
horizon planning task, showing much better goal-directed behavior.
Opus 4.5 has a clear lead in software engineering tasks for its competitors, and even other Anthropic models. To see how well it stacks against its contemporaries on a variety of benchmarks the following visual would assist:
The heavy reliance of Anthropic on software engineering and agent tasks might not be welcomed under most contexts. But what it offers AI coding is hard to look past.
Safety Features
One thing that sets Claude Opus 4.5 apart isn’t just how well it codes, but how reliably it behaves when the stakes rise. Anthropic’s internal evaluations point to Opus 4.5 as their most robustly aligned model so far, and likely the best-aligned frontier model available today.
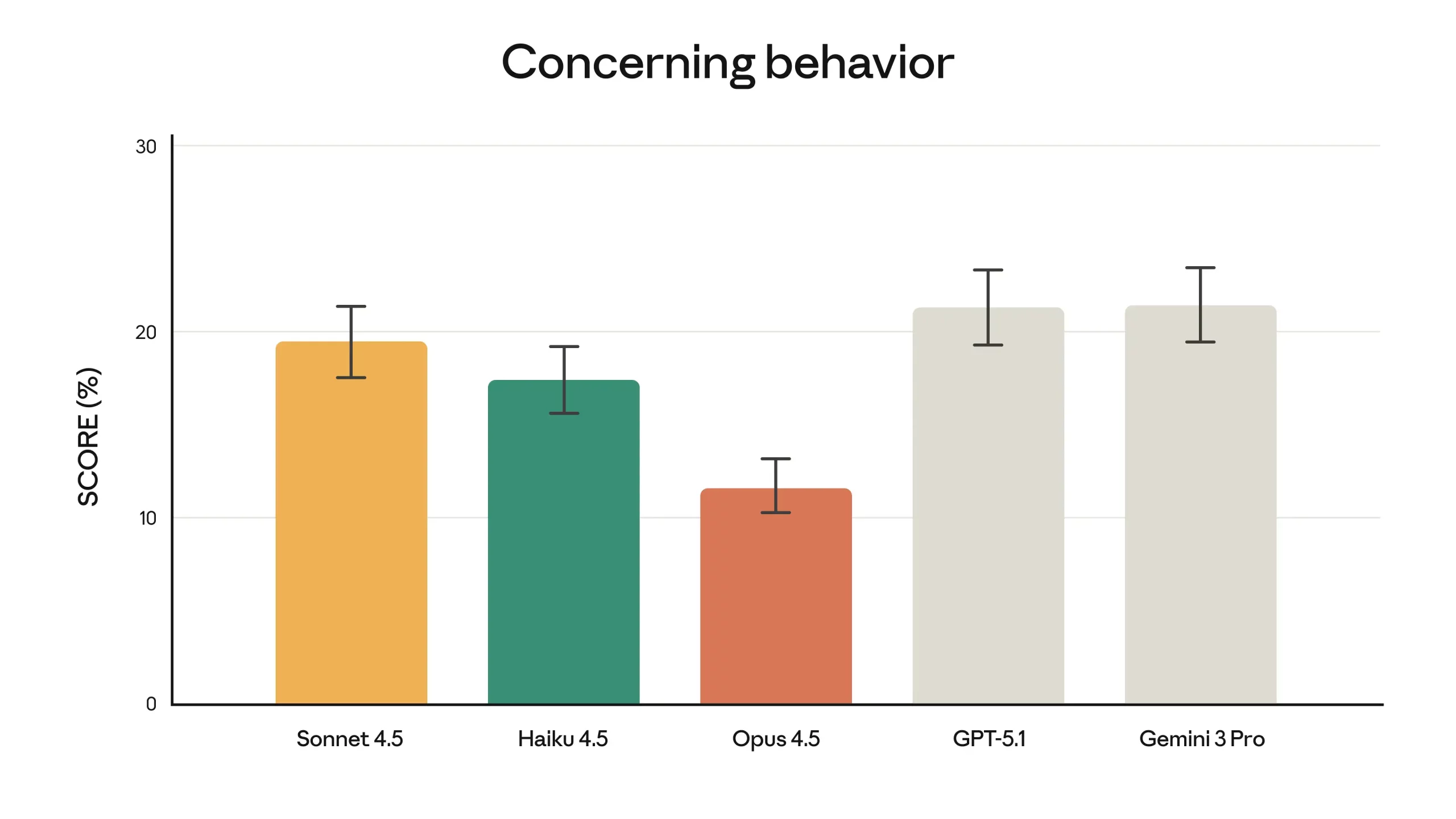
It shows a sharp drop in “concerning behavior,” the kind that includes cooperating with risky user intent or drifting into actions no one asked for. And when it comes to prompt injection, the kind of deceptive attacks that try to hijack a model with hidden instructions, Opus 4.5 stands out even more.
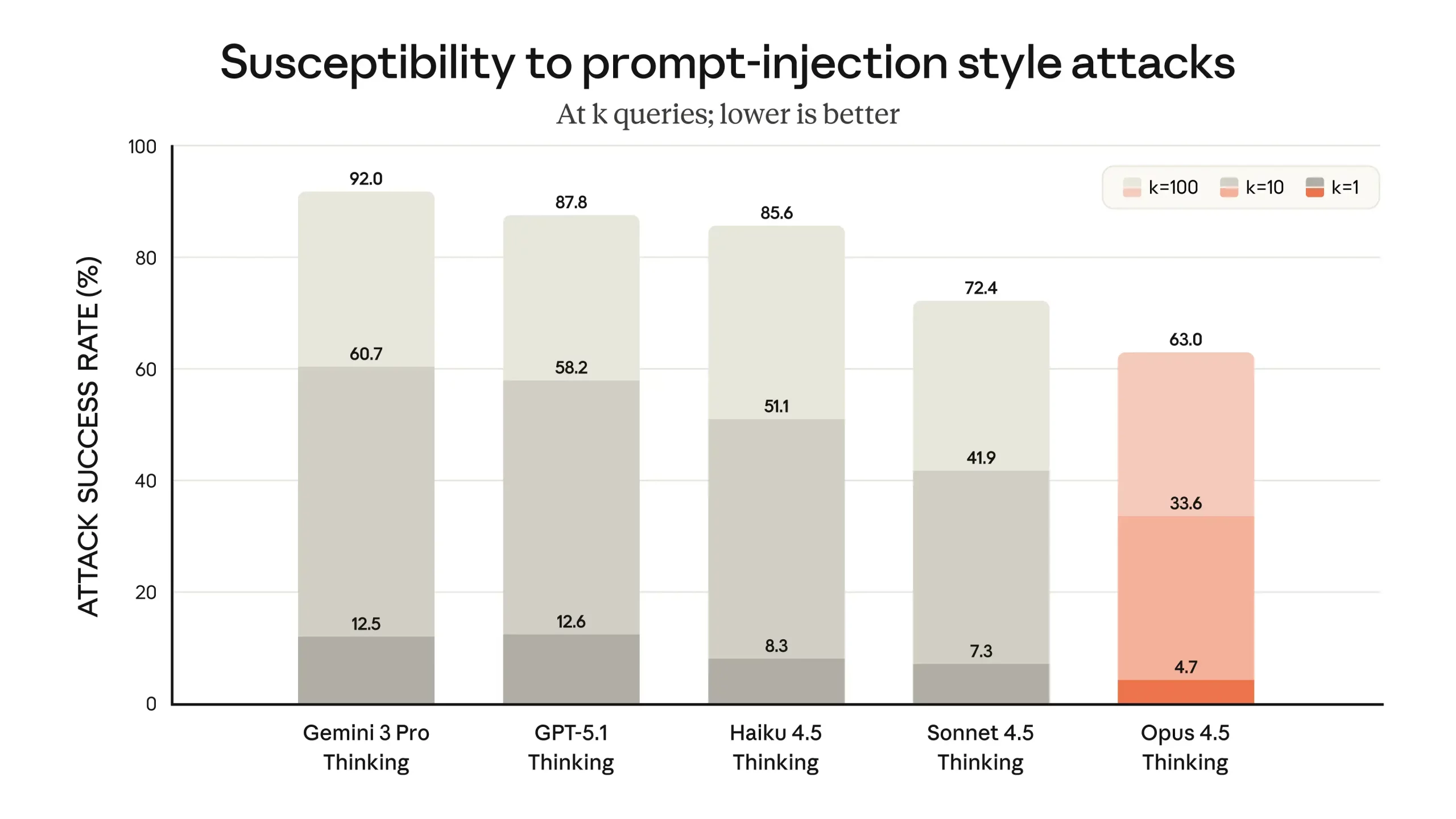
Safety isn’t an afterthought here. It’s a defining advantage and a standout feature that is gonna pave the way for more features to follow.
Hands-On Example of Claude Opus 4.5
All that talk would amount to nothing if it doesn’t show up when it matters. I’d be testing the models across the following tasks to see how well it performs:
- Visual Reasoning in Claude Chat UI
- Contained Balls and Video Game Clone
1. Visual Reasoning in Claude Chat UI
In this task, we’ll explore how well Claude Opus 4.5 can reason about images using its chat interface. We’d be providing the following image as input:
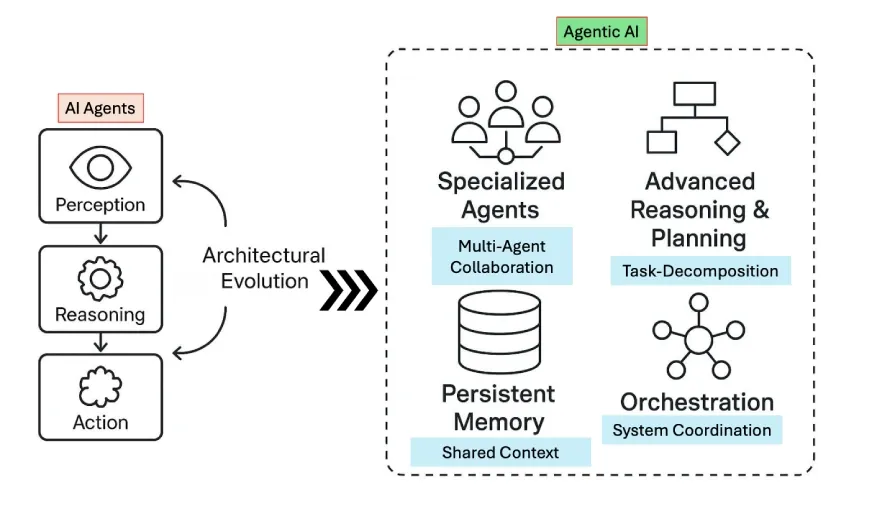
What’s happening in this image?
Response:
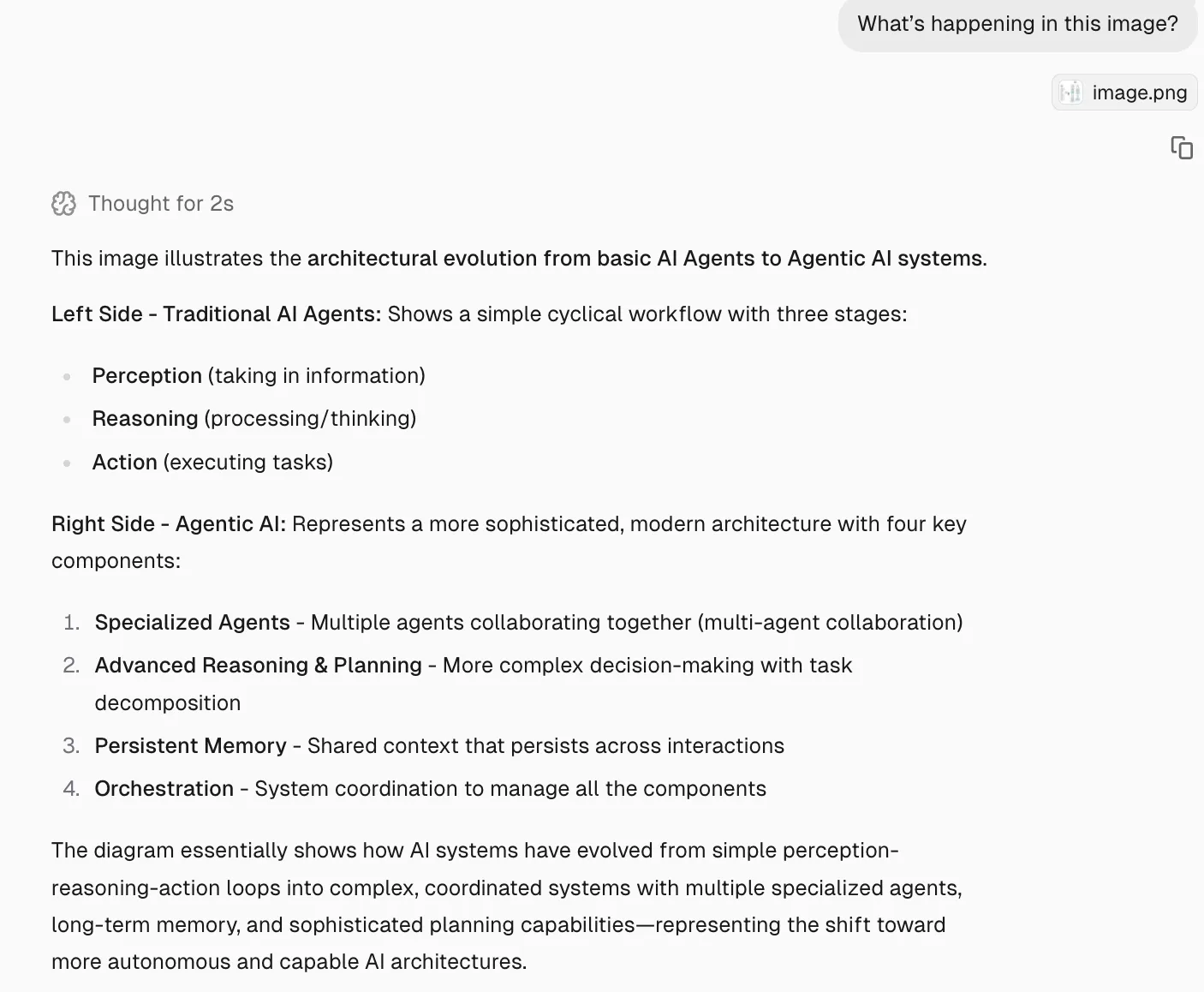
Then I asked the following question to elaborate on its previous response:
What kind of interpretations you can made through the diagram?”
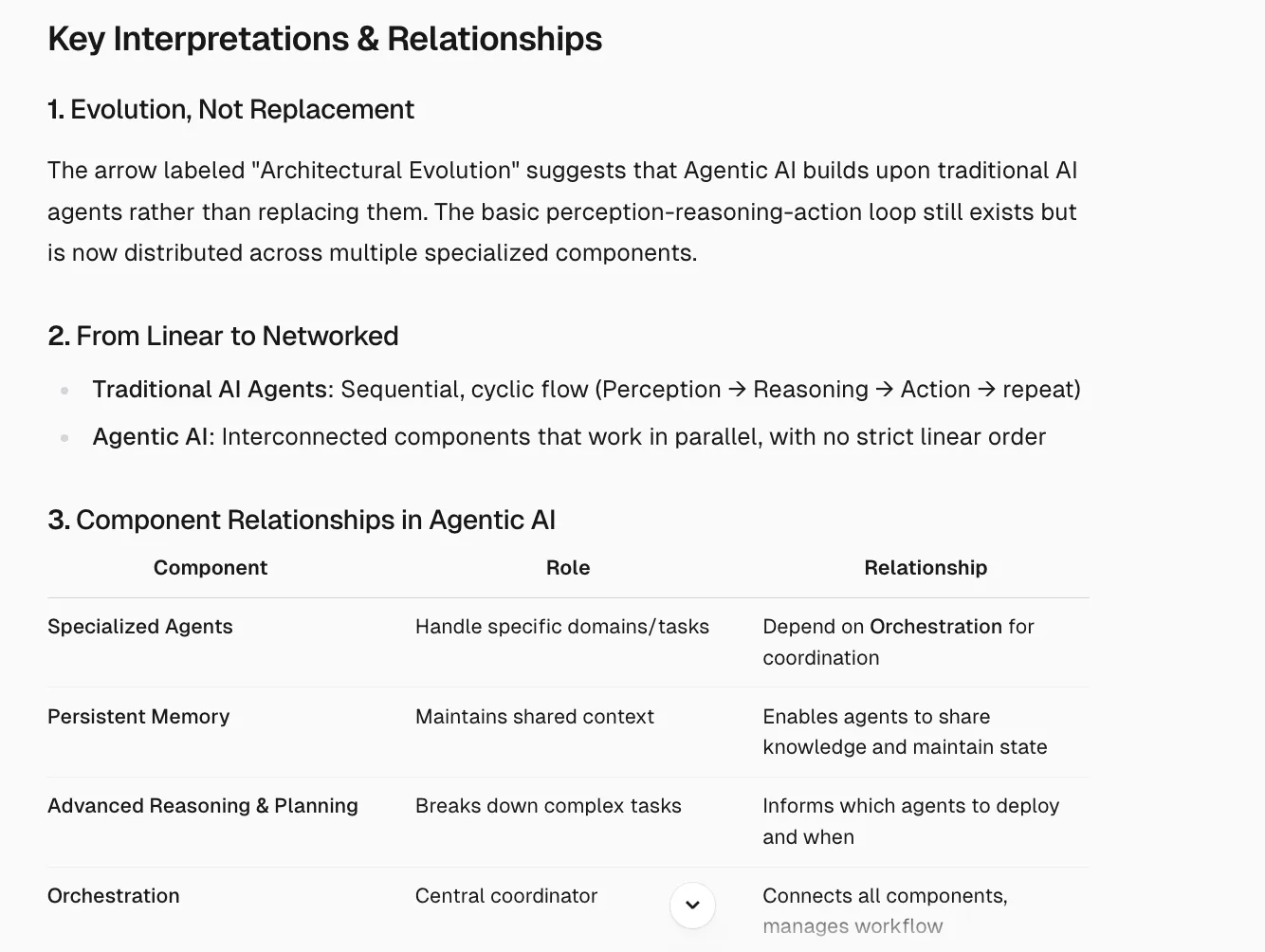

I wasn’t satisfied yet. To further test the model’s understanding of the problem I asked the following followup question:
If this arrow was reversed, how would the meaning change?
Response:


The model was able to perform very well on counter-factual task. Most models would fail to visualise/understand the difference in the context just by a change in the direction of the arrow. The model was not only able to realise this, but was able to infer from this change. The normal interpretations can be improved upon.
2. Contained Balls and Video Game Clone
This is where I ran into a problem: Limits! Even after having the paid subscription of Claude, I was unable to get it to create responses that required continuing chats over 3 times. Therefore, complex codes that are volumous, would be hard to processing using the web interface.
So, I started looking online for others who were able to run the model for large usage minutes. I came across the following clip from X:
The Super Mario one is even more impressive. Creating such a linear app clone in a moment deserves a lot of praise. As someone who has followed LLMs for some time, I have realised how hard it is for models to do such a task. I tried doing ta similar task with Gemini 3 pro and ChatGPT 5.1, and the results weren’t even comparable to this.
Both the responses are just as impressive. Anyone who had tried creating the ball containing simulation in the past knows, how hard it is for models to do such a simple task. Claude Opus 4.5 was able to do it masterfully, so that none of the balls went out of bounds.
Conclusion
Claude Opus 4.5 is just as the company had advertised: The best coding model. It sets a new benchmark for AI coding, by handling everything from planning to clean implementation while staying consistent across longer tasks. Where other models lose coherence or introduce bugs when pushed, Opus 4.5 keeps producing code that feels practical and developer minded.
It is not perfect. It sometimes invents solutions instead of flagging missing tools and it is softer as an editor than what its competitors offer. Still, the gains in software development are clear. Among a wave of recent model launches, it stands out due to its coding prowess. If building real products with AI matters to you, Opus 4.5 is the strongest option available right now. This could be the go-to choice for programmers going forward.
Frequently Asked Questions
Q1. What makes Claude Opus 4.5 different from previous Opus models?
A. It’s smarter at real engineering tasks, far cheaper in token cost, and easier to access across apps, API, and cloud platforms.
Q2. Do I need a paid plan to use Opus 4.5?
A. Yes for the main Claude app, but you can also access it through platforms like AWS Bedrock or Windsurf depending on your setup.
Q3. Is Claude Opus 4.5 actually better at coding than GPT-5.1 and Gemini 3 Pro?
A. Early results say yes on complex debugging and full-stack tasks, but the article’s hands-on testing will make the real call.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






