AI agents are LLM-powered systems that act autonomously to solve complex tasks. Unlike simple chatbots, agents plan steps, call external tools, and use memory to keep context. For example, an agent can analyse data sources and generate a multi-step plan, whereas a basic LLM app can only answer a single prompt.
Therefore, developers now need to understand not only how agents work but also the layers that make them reliable at scale. Frameworks, runtimes, and harnesses each play a different role, and choosing the wrong one often leads to complexity, inefficiency, or problems later on. In this article, we’ll go through the differences between agent frameworks, agent runtimes, and agent harnesses. And by the end you will learn how they work, when to use each, and how they fit together in a modern agent stack.
Table of contents
- Background: What is an “Agent” in AI Systems
- Agents vs Traditional LLM Apps
- Core Components of an AI Agent
- When to Use an Agent Framework
- What are Agent Runtimes?
- What are Agent Harnesses?
- How These Layers Fit Together: The Tri-Layer Architecture
- The Tri-Layer Architecture
- When to Use What: Decision Matrix
- Real-World Examples & Tools
- Conclusion
- Frequently Asked Questions
Background: What is an “Agent” in AI Systems
An AI agent is an autonomous system that uses an LLM and external tools to perform tasks and autonomously takes actions toward a goal. Modern generative agents use large language models as a “brain” but augment them with extra capabilities. This makes them far more powerful than standalone LLMs. Traditional LLM apps answer prompts directly, but agents iteratively plan, utilize tools, and remember information.
Agents vs Traditional LLM Apps
Conventional LLM applications generate a response in one shot, without long-term context. In contrast, an AI agent can break a complex task into subproblems, call external APIs or databases, and loop until the goal is met.
For example, A normal chatbot might translate text, but an agent could retrieve live data, summarize it, and then generate an action plan.
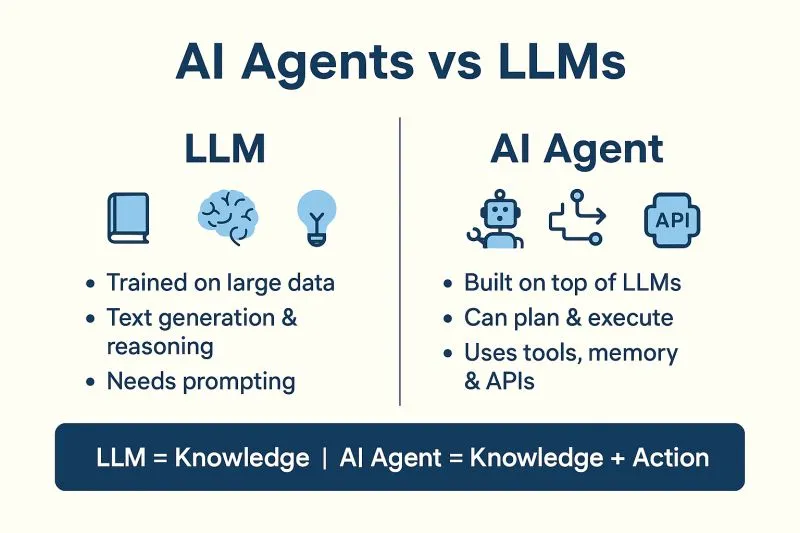
Why tools, memory, and planning matter
Tools allow agents to access real-world data through APIs or code execution. Memory stores context beyond a single conversation. Planning lets agents break large problems into steps. Without these components, an LLM can only produce one-off responses. With them, it operates more like a software worker capable of completing complex tasks.
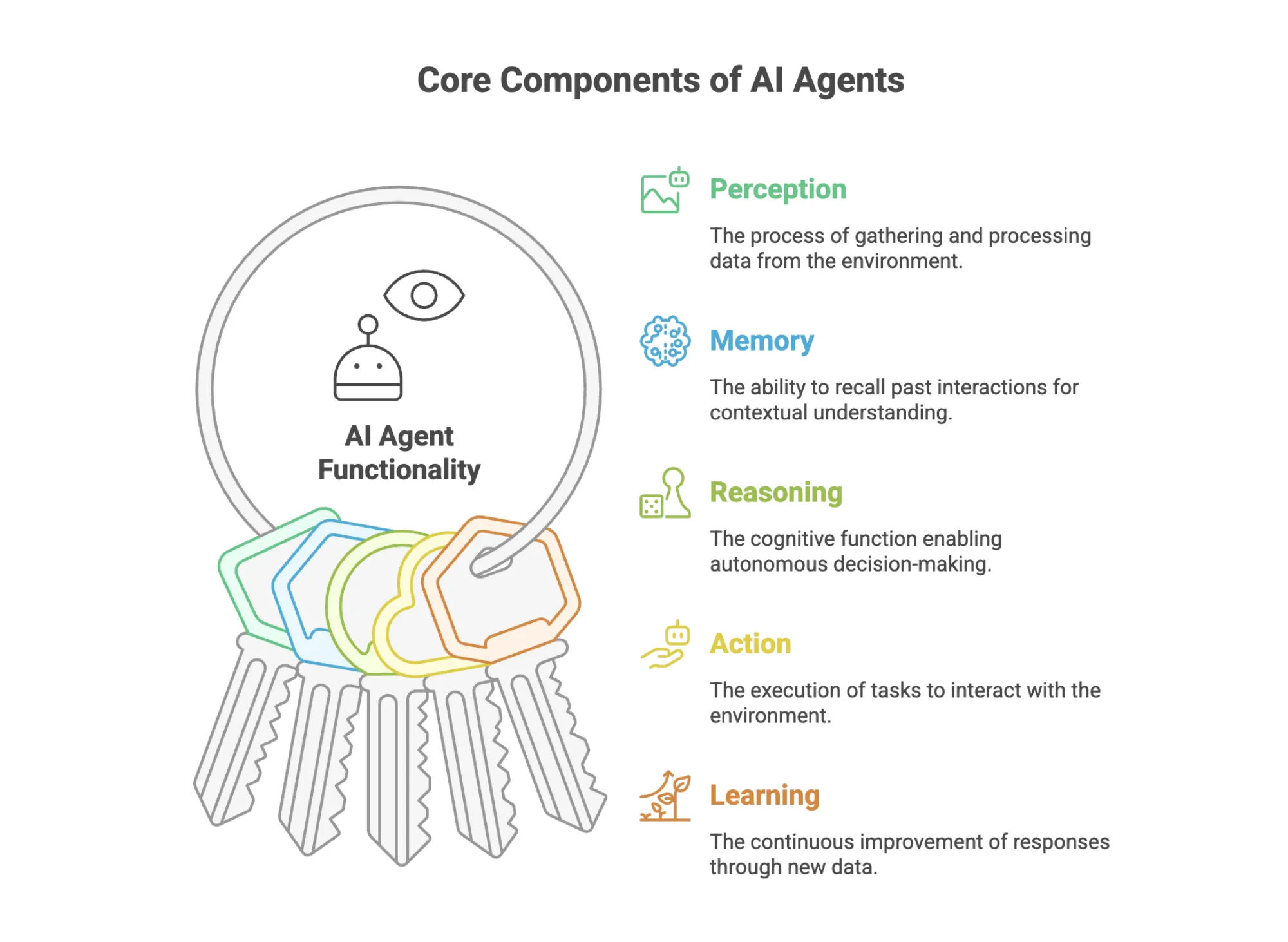
Core Components of an AI Agent
Effective agents are built on three pillars: planning, tool utilization, and memory. Planning is the LLM’s reasoning process. Tool utilization gives the agent hands and senses.
For Example, web search, calculators, or code execution environments. Memory allows the agent to store past interactions to maintain context over a conversation. Together, these components let an agent map a problem to a sequence of actions that achieve the goal. Therefore, every functional agent includes the following:
- Reasoning engine (LLM or multimodal model)
- Tooling system for executing external actions
- Memory management
- Planner for multi-step execution
- Runtime to manage execution, retries, and state
- Interface or harness that wraps the agent for deployment
What are Agent Frameworks?
Agent frameworks are libraries or SDKs that help you build agentic applications. They provide abstractions and standard patterns for composing language models with tools, memory, and control logic. In essence, a framework is your blueprint for the agent: it defines prompts, tool calls, and the overall agent loop in a structured way so you don’t have to code everything from scratch.
Or simply, an agent framework is a set of libraries that helps developers build an agent’s reasoning process, tool definitions, prompts, and memory structures. Frameworks define what an agent is and how it should behave, but they do not guarantee durable execution.
Read more: Top 7 Agent Frameworks to Build AI Agents
Key Capabilities
Agent frameworks usually include modules for orchestration, memory, and tool setups. They offer flexibility for developers who want full control over how agents think and act.
- Tool Orchestration: Frameworks help define tools that an agent can use. They manage how tools are exposed to the model, how parameters are validated, and how responses flow back into the agent’s reasoning loop.
- Memory Integration: Frameworks integrate short-term and long-term memory systems. They provide vector store interfaces, summarizers, and retrieval tools so agents can store and recall information reliably.
When to Use an Agent Framework
Use a framework whenever you’re building or prototyping an LLM agent. Frameworks are ideal for development and early-stage projects where ease-of-use matters. There are some of the advantages of using an Agent framework:
- Highly customizable agent behaviour
- Fine-grained control over memory, tools, or planning
- Rapid prototyping without worrying about long-running execution
- Research and experimentation where flexibility matters
For example, for a data analysis agent that uses a search API and memory, a framework like LangChain lets you assemble these pieces quickly without writing all the boilerplate.
What are Agent Runtimes?
Agent runtime is execution engines designed for running agents in production. They handle how the agent runs over time, focusing on reliability and state management.
In other words, a runtime is like the backend service that powers the agent once it’s deployed. It makes sure the agent’s workflow can pause, resume, and recover from failures, and often provides additional features like streaming and human-in-the-loop support.
For example, LangChain’s LangGraph is a runtime that saves each step’s state to a database, so the agent can resume exactly where it left off even after a crash.
Key Features
- Durable Execution: Durable execution ensures that if an agent crashes mid-task, the runtime restores the last known state and resumes the workflow. This prevents loss of progress during multi-step operations.
- Error Handling & Retries: Runtimes implement structured failure handling. They retry failed steps, repair broken states, and prevent runaway loops. Good runtimes reduce human intervention by handling predictable failures automatically.
When to Choose a Runtime
Choose a dedicated runtime when you move into production or need robust execution. If your agent needs to run across hours or days, handle many parallel sessions, or survive infrastructure hiccups, a runtime is necessary:
- You deploy agents to production
- Tasks require long-running execution
- You need state recovery after failures
- You run multi-step workflows that must remain stable
- You want predictable error boundaries
What are Agent Harnesses?
Agent harnesses are higher-level systems that wrap agent frameworks and provide opinionated defaults or testing suites. Think of a harness as a “model wrapper” that comes with batteries included. Harnesses set up built-in tools, prompts, and workflows so you can spin up an agent quickly. They also often double as evaluation frameworks, allowing you to test the agent’s behaviour under controlled scenarios.
Key Capabilities
The major key capability of harness includes:
- Prebuilt tools and workflows: Harnesses come with ready-to-use utilities and patterns. For example, DeepAgents provides file operations such as ls, read_file, and write_file, along with automatic subagent creation. This makes it easy to break a large task into smaller parts without extra coding.
- Opinionated defaults: Harnesses choose sensible defaults so workflows run immediately with little configuration. For example, a harness may preselect a model, set a default system prompt, and decide which tools should be used first. Another example is a harness that automatically prioritizes search before code execution to ensure reliable results.
When to Use a Harness
Use a harness when you want a quick, ready-made agent that works with minimal setup. It is ideal when you are prototyping or need an end-to-end solution that already follows best practices. In these situations, a harness saves significant time and effort. You should choose a harness when:
- You want to launch an agent quickly
- The use case fits a common or standard pattern
- You do not need custom planning or tool orchestration
- You prefer managed defaults instead of manual configuration
How These Layers Fit Together: The Tri-Layer Architecture
Conceptually, you can think of it as Framework → Runtime → Harness. First, you use a framework to configure the agent. Finally, a harness wraps around the process for evaluation: it might automatically run test scenarios or supply higher-level services. Each layer builds on the one before, and together they cover the full lifecycle of an agentic system.
The Tri-Layer Architecture
Framework → Runtime → Harness
For example: you might write a LangChain agent (framework) to define a customer support workflow. Then you deploy it with LangGraph (runtime) so it can handle real user sessions and interruptions.
Finally, you use DeepAgents or a test harness to run that agent against thousands of sample queries to catch hallucinations or bugs. In practice, the runtime and harness are powering or testing what you designed with the framework. The runtime “operationalizes” the framework’s logic, and the harness “validates” it, reinforcing a feedback loop for improvement.

How They Interoperate
An agent created in a framework can run inside any compatible runtime. A harness wraps both and adds workflows, guardrails, and deployment integrations. This stack mirrors traditional software architecture but optimizes for LLM-driven autonomy.
For Example: A workflow defined in one framework could run on LangGraph or another scheduler without changes. Similarly, harnesses rely on the definitions from the framework and the traces from the runtime. Logs, metrics, and state snapshots from the runtime feed into the harness (for scoring or monitoring), and results from the harness can lead you to tweak the framework’s design.
When to Use What: Decision Matrix
Which layer you prioritize depends on your stage and needs:
Framework vs Runtime vs Harness: Quick Comparison
- Framework: Defines the agent logic. It’s a static blueprint specifying which LLM, prompts, and tools to use. Use it when you’re building or customizing an agent.
- Runtime: Manages the execution. It runs the agent loop with persistence, concurrency, and fault tolerance. Use it when you need stateful, production-grade performance.
- Harness: Provides testing and defaults. It executes the agent under controlled conditions or with opinionated settings. Use it when you want to validate behaviour or jump-start with ready-made workflows.
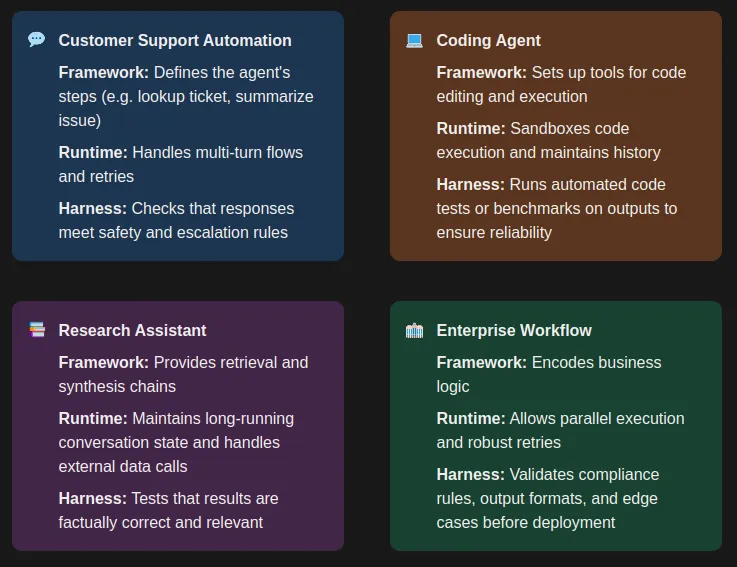
Use-Case Based Recommendations
- Customer Support Automation: A framework defines the agent’s steps (e.g. lookup ticket, summarize issue). A runtime handles multi-turn flows and retries. A harness can then check that responses meet safety and escalation rules.
- Research Assistant: The framework provides retrieval and synthesis chains. The runtime maintains long-running conversation state and handles external data calls. The harness tests that results are factually correct and relevant.
- Coding Agent: The framework sets up tools for code editing and execution. The runtime sandboxes code execution and maintains history. The harness runs automated code tests or benchmarks on outputs to ensure reliability.
- Enterprise Workflow: The framework encodes business logic. The runtime allows parallel execution and robust retries. The harness validates compliance rules, output formats, and edge cases before deployment.
Real-World Examples & Tools
Several tools fall into each category. Knowing the ecosystem helps you select the right stack.
Frameworks
- LangChain: A leading open-source agent framework, offering rich abstractions for LLMs and tools.
- LlamaIndex: Helps build retrieval-augmented agents by managing indexes and data sources.
- Microsoft Semantic Kernel: Provides components (plugins, memory, chains) for building agentic apps.
- OpenAI Agents SDK: An official SDK for building agents with OpenAI models.
- Vercel AI SDK, CrewAI, etc.: Other libraries that abstract common agent patterns
Runtimes
- LangGraph: LangChain’s production-ready runtime for durable agent execution.
- Temporal: A general-purpose workflow engine often used for AI agents, offering strong fault tolerance.
- Inngest: A serverless orchestration platform that can schedule agent tasks.
- Airflow/Argo: DAG schedulers sometimes adapted for AI pipelines.
These runtimes focus on stateful, long-running operations like running distributed agents.
Harnesses
- DeepAgents: LangChain’s opinionated agent harness. It comes with planning tools, filesystem access, and built-in workflows.
- Claude Agent SDK: Anthropic’s toolkit for building agents (inspired by their Claude Code system).
- Amp Code: A specialized harness for coding agents, with built-in defaults tuned for software development.
- Custom Test Harnesses: For example, using OpenAI Evals or custom scripts to benchmark agent outputs. These serve as evaluation harnesses to ensure agent quality.
Conclusion
Agent frameworks, runtimes, and harnesses each serve a unique purpose. Frameworks define how agents behave, runtimes ensure stable execution, and harnesses provide ready-made solutions for rapid deployment. Understanding these layers helps developers choose the right tools, avoid pitfalls, and build reliable AI systems.
Together, they create a modern stack for scalable agent development. So, from this detailed guide our final take is start simple with a harness, move to a framework when customization is required, and use a runtime when reliability becomes essential. This approach ensures your agents stay flexible, stable, and future proof.
Frequently Asked Questions
Q1. What is an AI agent?
A. An AI agent is a system powered by an LLM that autonomously plans, uses tools, and maintains memory to complete complex tasks beyond single-shot responses.
Q2. How are agents different from traditional LLM apps?
A. Traditional LLM apps generate one-off responses. Agents can plan, use APIs or tools, remember context, and iterate until a task is complete.
Q3. What are the core components of an AI agent?
A. Every agent includes a reasoning engine, tools, memory, a planner, a runtime for execution, and an interface or harness for deployment.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.





