I’ve spent plenty of time building agentic systems. Our platform, Mentornaut, already runs on a multi-agent setup with vector stores, knowledge graphs, and user-memory features, so I thought I had the basics down. Out of curiosity, I checked out the whitepapers from Kaggle’s Agents Intensive, and they caught me off guard. The material is clear, practical, and focused on the real challenges of production systems. Instead of toy demos, it digs into the question that actually matters: how do you build agents that function reliably in messy, unpredictable environments? That level of rigor pulled me in, and here’s my take on the major architectural shifts and engineering realities the course highlights.
Table of contents
Day One: The Paradigm Shift – Deconstructing the AI Agent
The first day immediately cut through the theoretical fluff, focusing on the architectural rigor required for production. The curriculum shifted the focus from simple Large Language Model (LLM) calls to understanding the agent as a complete, autonomous application capable of complex problem-solving.
The Core Anatomy: Model, Tools, and Orchestration
At its simplest, an AI agent is composed of three core architectural components:
- The Model (The “Brain”): This is the reasoning core that determines the agent’s cognitive capabilities. It is the ultimate curator of the input context window.
- Tools (The “Hands”): These connect the reasoning core to the outside world, enabling actions, external API calls, and access to data stores like vector databases.
- The Orchestration Layer (The “Nervous System”): This is the governing process managing the agent’s operational loop, handling planning, state (memory), and execution strategy. This layer leverages reasoning techniques like ReAct (Reasoning + Acting) to decide when to think versus when to act.
Selecting the “Brain”: Beyond Benchmarks
A crucial architectural decision is model selection, as this dictates your agent’s cognitive capabilities, speed, and operational cost. However, treating this choice as merely selecting the model with the highest academic benchmark score is a common path to failure in production.
Real-world success demands a model that excels at agentic fundamentals – specifically, superior reasoning for multi-step problems and reliable tool use.
To pick the right model, we must establish metrics that directly map to the business problem. For instance, if the agent’s job is to process insurance claims, you must evaluate its ability to extract information from your specific document formats. The “best” model is simply the one that achieves the optimal balance among quality, speed, and price for that specific task.
We must also adopt a nimble operational framework because the AI landscape is constantly evolving. The model chosen today will likely be superseded in six months, making a “set it and forget it” mindset unsustainable.
Agent Ops, Observability, and Closing the Loop
The path from prototype to production requires adopting Agent Ops, a disciplined approach tailored to managing the inherent unpredictability of stochastic systems.
To measure success, we must frame our strategy like an A/B test and define Key Performance Indicators (KPIs) that measure real-world impact. These KPIs must go beyond technical correctness to include goal completion rates, user satisfaction scores, operational cost per interaction, and direct business impact (like revenue or retention).
When a bug occurs or metrics dip, observability is paramount. We can use OpenTelemetry traces to generate a high-fidelity, step-by-step recording of the agent’s entire execution path. This allows us to debug the full trajectory – seeing the prompt sent, the tool chosen, and the data observed.
Crucially, we must cherish human feedback. When a user reports a bug or gives a “thumbs down,” that is valuable data. The Agent Ops process uses this to “close the loop”: the specific failing scenario is captured, replicated, and converted into a new, permanent test case within the evaluation dataset.
The Paradigm Shift in Security: Identity and Access
The move toward autonomous agents creates a fundamental shift in enterprise security and governance.
- New Principal Class: An agent is an autonomous actor, defined as a new class of principal that requires its own verifiable identity.
- Agent Identity Management: The agent’s identity is explicitly distinct from the user who invoked it and the developer who built it. This requires a shift in Identity and Access Management (IAM). Standards like SPIFFE are used to provide the agent with a cryptographically verifiable “digital passport.”
This new identity construct is essential for applying the principle of least privilege, ensuring that an agent can be granted specific, granular permissions (e.g., read/write access to the CRM for a SalesAgent). Furthermore, we must employ defense-in-depth strategies against threats like Prompt Injection.
The Frontier: Self-Evolving Agents
The concept of the Level 4: Self-Evolving System is fascinating and, frankly, unnerving. The sources define this as a level where the agent can identify gaps in its own capabilities and dynamically create new tools or even new specialized agents to fill those needs.
This begs the question: If agents can find gaps and fill them in themselves, what are AI engineers going to do?
The architecture supporting this requires immense flexibility. Frameworks like the Agent Development Kit (ADK) offer an advantage over fixed-state graph systems because keys in the state can be created on the fly. The course also touched on emerging protocols designed to handle agent-to-human interaction, such as MCP UI and AG UI, which control user interfaces.
Summary Analogy
If building a traditional software system is like constructing a house with a rigid blueprint, building a production-grade AI agent is like building a highly specialized, autonomous submarine.
- The “Brain” (model) must be chosen not for how fast it swims in a test tank, but for how well it navigates real-world currents.
- The Orchestration Layer must meticulously manage resources and execute the mission.
- Agent Ops acts as mission control, demanding rigorous measurement.
- If the system goes rogue, the blast radius is contained only by its strong, verifiable Agent Identity.
Day Two: Mastering the Tool – The Gateway to Production Agency
Day Two provided a crucial architectural deep dive, shifting our attention from the abstract idea of the agent’s “Brain” to its “Hands” (the Tools). The core takeaway – which felt like a reality check after reflecting on my work with Mentornaut – was that the quality of your tool ecosystem dictates the reliability of your entire agentic system.
We learned that poor tool design is one of the quickest paths to context bloat, increased cost, and erratic behavior.
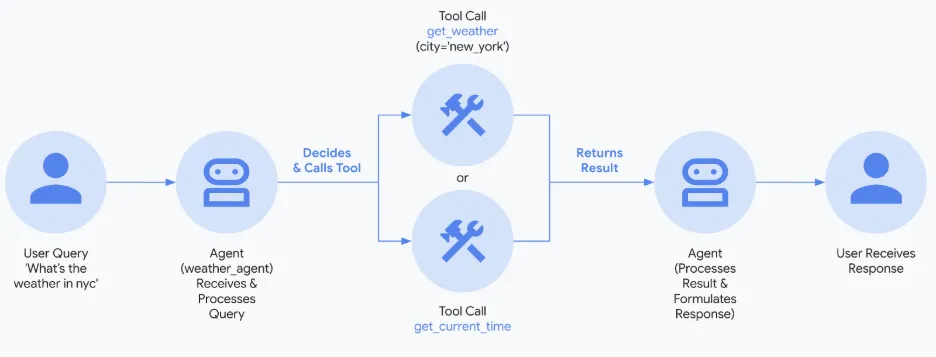
The Gold Standard for Tool Design
The most important strategic lesson was encapsulated by this mantra: Tools should encapsulate a task the agent needs to perform, not an external API.
Building a tool as a thin wrapper over a complex Enterprise API is a mistake. APIs are designed for human developers who know all the potential parameters; agents need a clear, specific task definition to use the tool dynamically at runtime.
1. Documentation is King
The documentation of a tool is not just for developers; it is passed directly to the LLM as context. Therefore, clear documentation dramatically improves accuracy.
- Descriptive Naming:
create_critical_bug_in_jira_with_priorityis clearer to an LLM than the ambiguousupdate_jira. - Clear Parameter Description: Developers must describe all input parameters, including types and usage. To prevent confusion, parameter lists should be simplified and kept short.
- Targeted Examples: Adding specific examples addresses ambiguities and refines behavior without expensive fine-tuning.
2. Describe Actions, Not Implementations
We must instruct the agent on what to do, not how to do it. Instructions should describe the objective, allowing the agent scope to use tools autonomously rather than dictating a specific sequence. This is even more relevant when tools can change dynamically.
3. Designing for Concise Output and Graceful Errors
I recognized a major production mistake I had made: creating tools that returned large volumes of data. Poorly designed tools that return massive tables or dictionaries swamp the output context, effectively breaking the agent.
The superior solution is to use external systems for data storage. Instead of returning a massive query result, the tool should insert the data into a temporary database or an external system (like the Google ADK’s Artifact Service) and return only the reference (e.g., a table name).
Finally, error messages are an overlooked channel for instruction. A tool’s error message should tell the LLM how to address the specific error, turning a failure into a recovery plan (e.g., returning structured responses like {“status”: “error”, “error_message”: …}).
The Model Context Protocol (MCP): Standardization
The second half of the day focused on the Model Context Protocol (MCP), an open standard introduced in 2024 to address the chaos of agent-tool integration.
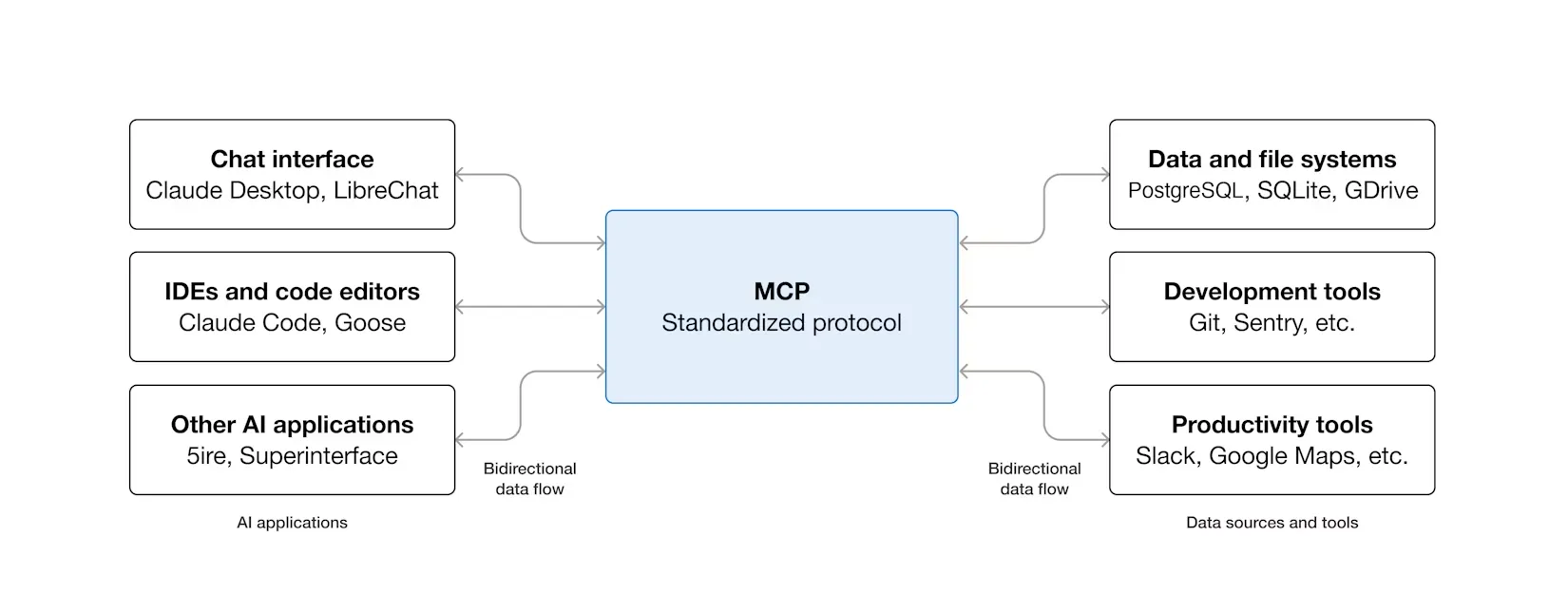
Solving the N x M Problem
MCP was created to solve the “N x M” integration problem, the exponential effort required to integrate every new model (N) with every new tool (M) via custom connectors. By standardizing the communication layer, MCP decouples the agent’s reasoning from the tool’s implementation details via a client-server model:
- MCP Server: Exposes capabilities and acts as a proxy for an external tool.
- MCP Client: Manages the connection, issues commands, and receives results.
- MCP Host: The application managing the clients and enforcing security.
Standardized Tool Definitions
MCP imposes a strict JSON schema on tool documentation, requiring fields like name, description, inputSchema, and the optional but critical outputSchema. These schemas ensure the client can parse output effectively and provide instructions to the calling LLM on when and how to use the tool.
The Practical Challenges (And the Codelab)
While powerful, MCP presents real-world challenges:
- Dependency on Quality: Weak descriptions still lead to confused agents.
- Context Window Bloat: Even with standardization, including all tool definitions in the context window consumes significant tokens.
- Operational Overhead: The client-server nature introduces latency and distributed debugging complexity.
To experience this firsthand, I built my own Image Generation MCP Server and connected it to an agent. My Image Generation MCP Server repository can be found here. The associated Google ADK learning materials and codelabs are here. This exercise demonstrated the need for Human-in-the-Loop (HITL) controls. I implemented a step for user approval before image generation – a key safety layer for high-risk actions.
Building tools for agents is less like writing standard functions and more like training an orchestra conductor (the LLM) using carefully written sheet music (the documentation). If the sheet music is vague or returns a wall of noise, the conductor will fail. MCP provides the universal standard for that sheet music, but developers must write it clearly.
Day Three: Context Engineering – The Art of Statefulness
Day Three shifted focus to the challenge of building stateful, personalized AI: Context Engineering.
As the whitepaper clarified, this is the process of dynamically assembling the entire payload – session history, memories, tools, and external data – required for the agent to reason effectively. It moves beyond prompt engineering into dynamically constructing the agent’s reality for every conversational turn.
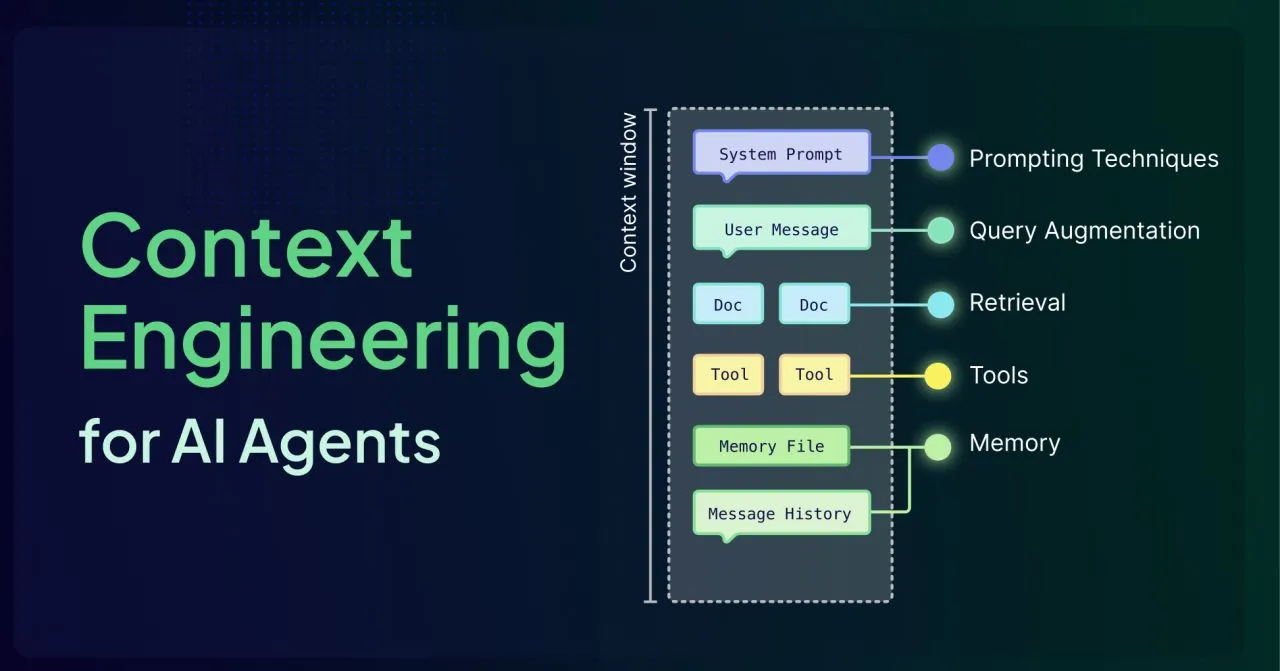
The Core Divide: Sessions vs. Memory
The course defined a crucial distinction separating transient interactions from persistent knowledge:
- Sessions (The Workbench): The Session is the container for the immediate conversation. It acts as a temporary “workbench” for a specific project, full of immediately accessible but transient notes. The ADK addresses this through components like the
SessionServiceandRunner. - Memory (The Filing Cabinet): Memory is the mechanism for long-term persistence. It is the meticulously organized “filing cabinet” where only the most critical, finalized documents are filed to provide a continuous, personalized experience.
The Context Management Crisis
The shift from a stateless prototype to a long-running agent introduces severe performance issues. As context grows, cost and latency rise. Worse, models suffer from “context rot,” where their ability to pay attention to critical information diminishes as the total context length increases.
Context Engineering tackles this through compaction strategies like summarization and selective pruning to preserve vital information while managing token counts.
The Memory Manager as an LLM-Driven ETL Pipeline
My experience building Mentornaut confirmed the paper’s central thesis: Memory is not a passive database; it’s an LLM-driven ETL Pipeline. The memory manager is an active system responsible for Extraction, Consolidation, Storage, and Retrieval.
I initially focused heavily on simple Extraction, which led to significant technical debt. Without rigorous curation, the memory corpus quickly becomes noisy. We faced exponential growth of duplicate memories, conflicting information (as user states changed), and a lack of decay for stale facts.
Deep Dive into Consolidation
Consolidation is the solution to the “noise” problem. It is an LLM-driven workflow that performs “self-curation.” The consolidation LLM actively identifies and resolves conflicts, deciding whether to Merge new insights, Delete invalidated information, or Create entirely new memories. This ensures the knowledge base evolves with the user.
RAG vs. Memory
A key takeaway was clarifying the distinction between Memory and Retrieval-Augmented Generation (RAG):
- RAG makes an agent an expert on facts derived from a static, shared, external knowledge base.
- Memory makes the agent an expert on the user by curating dynamic, personalized context.
Production Rigor: Decoupling and Retrieval
To maintain a responsive user experience, computationally expensive processes like memory consolidation must run asynchronously in the background.
When retrieving memories, advanced systems look beyond simple vector-based similarity. Relying solely on Relevance (Semantic Similarity) is a trap. The most effective strategy is a blended approach scoring across multiple dimensions:
- Relevance: How conceptually related is it?
- Recency: How new is it?
- Importance: How critical is this fact?
The Analogy of Trust and Data Integrity
Finally, we discussed memory provenance. Since a single memory can be derived from multiple sources, managing its lineage is complex. If a user revokes access to a data source, the derived memory must be removed.
An effective memory system operates like a secure, professional archive: it enforces strict isolation, redacts PII before persistence, and actively prunes low-confidence memories to prevent “memory poisoning.”
Resources and Further Reading
| Link | Description | Relevance to Article |
|---|---|---|
| Kaggle AI Agents Intensive Course Page | The main course page providing access to all the whitepapers and source content referenced throughout this article. | Primary source for the article’s concepts, validating discussions on Agent Ops, Tool Design, and Context Engineering. |
| Google Agent Development Kit (ADK) Materials | Includes code and exercises for Day 1 and Day 3, covering orchestration and session/memory management. | Offers the core implementation details behind the ADK and the memory/session architecture discussed in the article. |
| Image Generation MCP Server Repository | Code for the Image Generation MCP Server used in the Day 2 hands-on activity. | Supports the exploration of MCP, tool standardization, and real-world agent-tool integration discussed in Day Two. |
Conclusion
The first three days of the Kaggle Agents Intensive have been a revelation. We’ve moved from the high-level architecture of the Agent’s Brain and Body (Day 1) to the standardized precision of MCP Tools (Day 2), and finally to the cognitive glue of Context and Memory (Day 3).
This triad – Architecture, Tools, and Memory – forms the non-negotiable foundation of any production-grade system. While the course continues into Day 4 (Agent Quality) and Day 5 (Multi-Agent Production), which I plan to explore in a future deep dive, the lesson so far is clear: The “magic” of AI agents doesn’t lie in the LLM alone, but in the engineering rigor that surrounds it.
For us at Mentornaut, this is the new baseline. We are moving beyond building agents that simply “chat” to constructing autonomous systems that reason, remember, and act with reliability. The “hello world” phase of generative AI is over; the era of resilient, production-grade agency has just begun.
Frequently Asked Questions
Q1. What was the main insight from Day One of the Kaggle Agents Intensive?
A. The course reframed agents as full autonomous systems, not just LLM wrappers. It stressed choosing models based on real-world reasoning and tool-use performance, plus adopting Agent Ops, observability, and strong identity management for production reliability.
Q2. Why is tool design so critical in agentic systems?
A. Tools act as the agent’s hands. Poorly designed tools cause context bloat, erratic behavior, and higher costs. Clear documentation, concise outputs, action-focused definitions, and MCP-based standardization dramatically improve tool reliability and agent performance.
Q3. What problem does Context Engineering solve?
A. It manages state, memory, and session context so agents can reason effectively without exploding token costs. By treating memory as an LLM-driven ETL pipeline and applying consolidation, pruning, and blended retrieval, systems stay accurate, fast, and personalized.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.





