AI development is accelerating fast. Advances in hardware, software optimization, and better datasets now allow training runs that once took weeks to finish in hours. A recent update from AI researcher Andrej Karpathy shows this shift clearly: the Nanochat open-source project can now train a GPT-2 model on a single node with 8× NVIDIA H100 GPUs in about two hours, down from three just a month ago.
Even more striking, AI agents made 110 code changes in 12 hours, improving validation loss without slowing training. In this article, we look at how self-optimizing AI systems could reshape the way AI research and model training are done.

Table of contents
What is Nanochat?
Andrej Karpathy developed Nanochat to provide a basic complete language model training system which serves as an end-to-end solution. The project aims to show how developers can build a complete ChatGPT-style system by using a small and understandable codebase as their foundation. Nanochat provides two main benefits through its design because it eliminates the need for multiple complex dependencies while maintaining complete system transparency.
The framework includes the entire lifecycle of training and deploying a language model:
- Tokenizer training
- Base model pretraining
- Mid-training with conversational datasets
- Supervised fine-tuning
- Reinforcement learning optimization
- Inference and chat interface
With its total code length of 8000 lines, the entire pipeline results in one of the easiest open-source LLM training systems to access which exists today.
How the AutoResearch System Works?
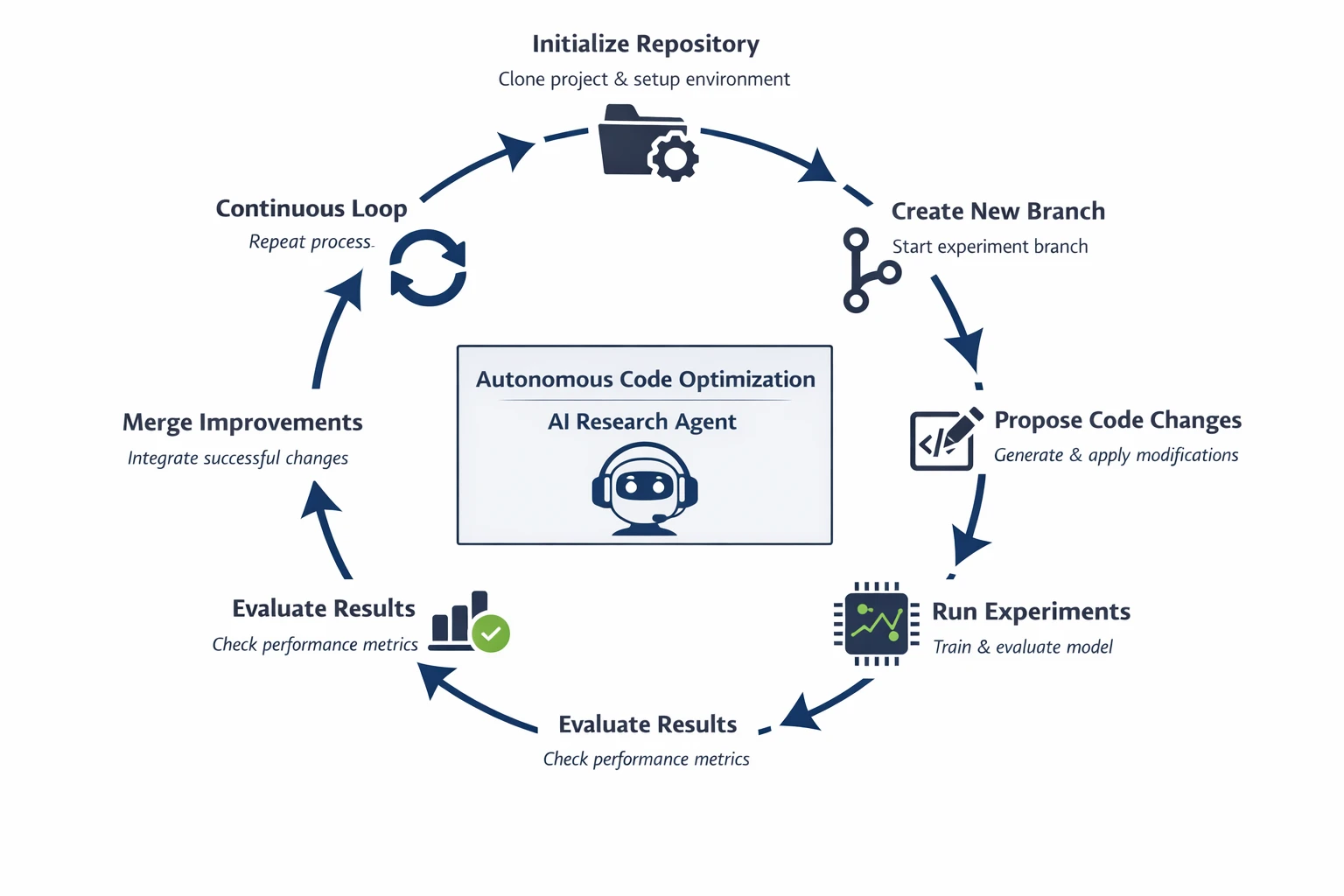
The AutoResearch framework establishes a research loop which allows AI agents to develop the codebase through their ongoing testing and verification process. The system functions as an automatic research engineer who conducts experiments to study its performance.
The workflow operates through the following steps:
- Repository Initialization
The agent starts with an existing project repository (for example, Nanochat). The system creates an experimental environment which includes the complete codebase through a process of codebase cloning.
- Branch Creation
The agent establishes a new testing branch which allows him to conduct tests on changes without risking any disruption to the primary codebase.
- Code Modification Proposal
The agent analyzes the repository and proposes potential improvements through his analysis work, which includes four main components.
- Training loop optimizations
- Dataset preprocessing improvements
- Hyperparameter adjustments
- Model architecture tweaks
- Automated Experiment Execution
The system performs automatic execution of modified code to support model training and testing activities. It records metrics such as:
- Validation loss
- Training speed
- Resource utilization
- Performance Evaluation
The system conducts a direct comparison between current results and the established baseline performance of the model. The new version demonstrates superior performance over its previous version, which qualifies as a system upgrade.
- Automated Merge
The system performs automatic merging of validated improvements into the main code branch.
- Continuous Research Loop
The agent establishes a perpetual research cycle that enables the development of an automated research system which enhances itself through persistent operation.
The system can produce multiple code enhancements which range from dozens to hundreds through its autonomous operating method that requires no human contact.
Setup and Installation
The framework can be setup to run autonomous research experiments locally.
- Clone the Repository
git clone https://github.com/karpathy/autoresearch.git
cd autoresearch- Setting Up the Environment
python -m venv venv
source venv/bin/activate- Install the dependencies
pip install -r requirements.txt - Configure the API Keys
export OPENAI_API_KEY="your_api_key_here" - Run the Autonomous Agent
python main.py The 2-Hour GPT-2 Training Breakthrough
The Nanochat project achieved its most important recent accomplishment through its achievement of faster GPT-2 model training times. The following information shows the training time and hardware used to complete the task:
- Training time: ~3 hours
- Hardware: 8× NVIDIA H100 GPUs
The training period has decreased to about two hours with the same hardware setup. The improvement appears minor, but machine learning research benefits faster training cycles because it enables researchers to complete experiments at a higher speed.
Researchers can test more ideas, iterate faster, and discover improvements sooner. The following optimizations served as essential components which enabled this achievement:
1. Switching to the NVIDIA ClimbMix Dataset
The most significant performance enhancement resulted from changing the training dataset. Previous research studies analyzed the following datasets:
- FineWeb
- Olmo
- DCLM
The training experiments showed training regressions when these datasets were used.
Nanochat achieved better results when it started using NVIDIA ClimbMix dataset because it needed less tuning work. The study shows a critical lesson about AI development. Data quality can matter as much as model architecture.
The correct dataset selection will lead to major advancements in both training efficiency and model testing results.
2. FP8 Precision Training
The second optimization achievement permitted FP8 precision training execution within the system. FP8 (8-bit floating point) allows GPUs to perform calculations faster while maintaining sufficient accuracy for neural network training.
- The advantages of FP8 training bring the following benefits to users:
- The system performs tensor calculations at higher speeds.
- The system requires less memory bandwidth for its operations.
- The system achieves better output performance from its graphics processing unit.
- The system provides educational institutions with more affordable training expenses.
The most effective method for enhancing performance in extensive AI workloads involves selecting precision levels that provide optimal results.
3. Training Pipeline Optimization
The training pipeline for Nanochat received multiple enhancements beyond the dataset modifications and FP8 optimization. The system received multiple upgrades which included better data loading pipelines and optimized training loops and improved GPU utilization and refined batch scheduling.
The combination of small performance improvements from each individual optimization resulted in an observable decrease of training duration.
AI Agents Are Now Improving Nanochat
The Nanochat ecosystem has reached its most exciting point because AI agents work to enhance project development through automatic project upgrades. Karpathy created a testing system which enables AI agents to develop the codebase through automated testing instead of conducting manual tests for improvements.
The workflow operates through these basic steps:
- The agent establishes a new feature branch.
- The agent suggests changes and performance enhancements.
- The system conducts experiments in an automated manner.
- The system merges updates when the modifications lead to better outcomes.
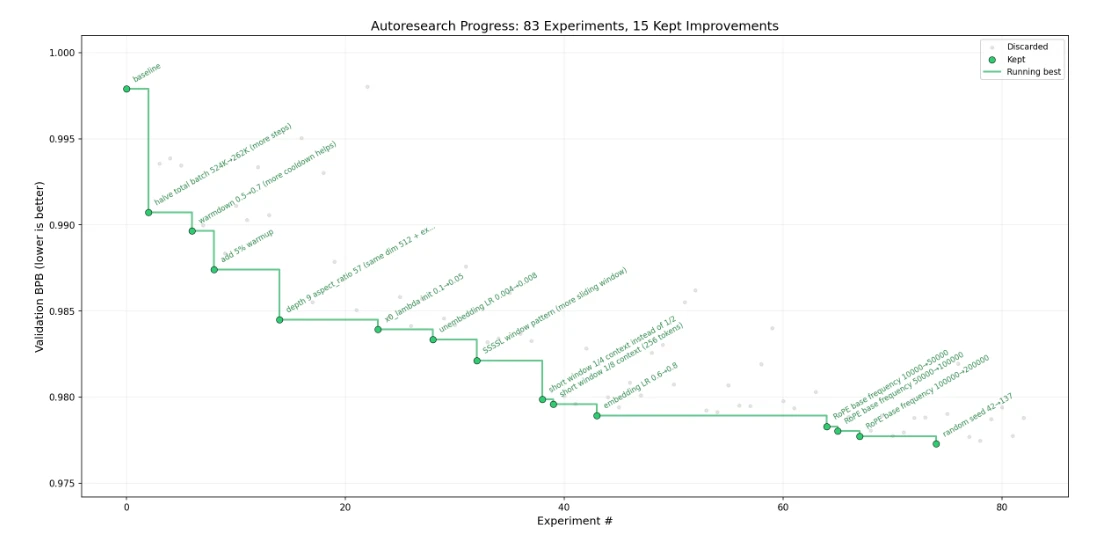
The system generated its output in 12 hours which included:
- 110 code modifications
- The system decreased validation loss from 0.862415 to 0.858039
- The system maintained existing training time
It system establishes an ongoing testing process which allows for fast implementation of testing results that lead to system upgrades. The system functions as a research entity which works on its own development process.
The Future of Open-Source AI
Nanochat is also part of a broader movement toward open-source AI infrastructure. Developers from different countries create and enhance AI systems through their collaborative efforts which do not depend on major corporate laboratories. Open-source LLM projects provide several benefits:
- AI development transparency
- community collaboration enables faster innovation
- new researchers find it easier to enter the field
The upcoming hardware advancements and training pipeline improvements will enable small teams to match the capabilities of major AI laboratories.
The AI ecosystem will experience an explosion of creativity and experimentation because of this development.
Conclusion
The latest achievement of Nanochat proves that AI development has reached an accelerated pace of advancement. The ability to train a GPT-2 capability model within two hours using current computer technology qualifies as an outstanding accomplishment.
The most important advancement in technology stems from the development of AI agents which possess the capability to conduct system improvements without human input. Autonomous research loops which now exist in their current state will enable researchers to develop research programs which will produce significant output.
Frequently Asked Question
Q1. What is Nanochat?
A. Nanochat is an open-source project by Andrej Karpathy that demonstrates a complete end-to-end pipeline for training and deploying a ChatGPT-style language model.
Q2. How fast can Nanochat train a GPT-2 level model?
A. Nanochat can train a GPT-2 level model in about two hours using a single node with 8 NVIDIA H100 GPUs.
Q3. How are AI agents improving Nanochat?
A. Autonomous AI agents test code changes, run experiments, and merge improvements automatically, generating over 100 optimizations while reducing validation loss.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]





