Z.ai is out with its next-generation flagship AI model and has named it GLM-5.1. With its combination of extensive model size, operational efficiency, and superior reasoning functions, the model represents a major step forward in large language models. The system improves upon previous GLM models by introducing an advanced Mixture-of-Experts framework, which enables it to perform intricate multi-step operations faster, with more precise results.
GLM-5.1 is also powerful because of its support for the development of agent-based systems that require advanced reasoning capabilities. The model even presents new features that enhance both coding capabilities and long-context understanding. All of this influences actual AI applications and developers’ working processes.
This leaves no room for doubt that the launch of the GLM-5.1 is an important update. Here, we focus on just that, and learn all about the new GLM-5.1 and its capabilities.
Table of contents
GLM-5.1 Model Architecture Components
GLM-5.1 builds on modern LLM design principles by combining efficiency, scalability, and long-context handling into a unified architecture. It helps in maintaining operational efficiency through its ability to handle up to 100 billion parameters. This enables practical performance in day-to-day operations.
The system uses a hybrid attention mechanism together with an optimized decoding pipeline. This enables it to perform effectively in tasks that require handling lengthy documents, reasoning, and code generation.
Here are all the components that make up its architecture:
- Mixture-of-Experts (MoE): The MoE model has 744 billion parameters, which it divides between 256 experts. The system implements top-8-routing, which permits eight experts to work on each token, plus one expert that operates across all tokens. The system requires approximately 40 billion parameters for each token.
- Attention: The system uses two types of attention methods. These include Multi-head Latent Attention and DeepSeek Sparse Attention. The system can handle up to 200000 tokens, as its maximum capacity reaches 202752 tokens. The KV-cache system uses compressed data, which operates at LoRA rank 512 and head dimension 64 to enhance system performance.
- Structure: The system contains 78 layers, which operate at a hidden size of 6144. The first three layers follow a standard dense structure, while the following layers implement sparse MoE blocks.
- Speculative Decoding (MTP): The decoding process becomes faster through Speculative Decoding because it uses a multi-token prediction head, which enables simultaneous prediction of multiple tokens.
GLM-5.1 achieves its large scale and extended contextual understanding through these features, which need less processing power than a complete dense system.
How to Access GLM-5.1
Developers can use GLM-5.1 in multiple ways. The complete model weights are available as open-source software under the MIT license. The following list contains some of the available options:
- Hugging Face (MIT license): Weights available for download. The system needs enterprise GPU hardware as its minimum requirement.
- Z.ai API / Coding Plans: The service provides direct API access at a cost of approximately $1.00 per million tokens and $3.20 per million tokens. The system works with the current Claude and OpenAI system toolchains.
- Third-Party Platforms: The system functions with inference engines, which include OpenRouter and SGLang that support preset GLM-5.1 models.
- Local Deployment: Users with adequate hardware resources can implement GLM-5.1 locally through vLLM or SGLang tools when they possess multiple B200 GPUs or equivalent hardware.
GLM-5.1 provides open weights and commercial API access, which makes it available to both enterprise businesses and individuals. Particularly for this blog, we will use the Hugging Face token to access this model.
GLM-5.1 Benchmarks
Here are the various scores that GLM-5.1 has obtained across benchmarks.
Coding
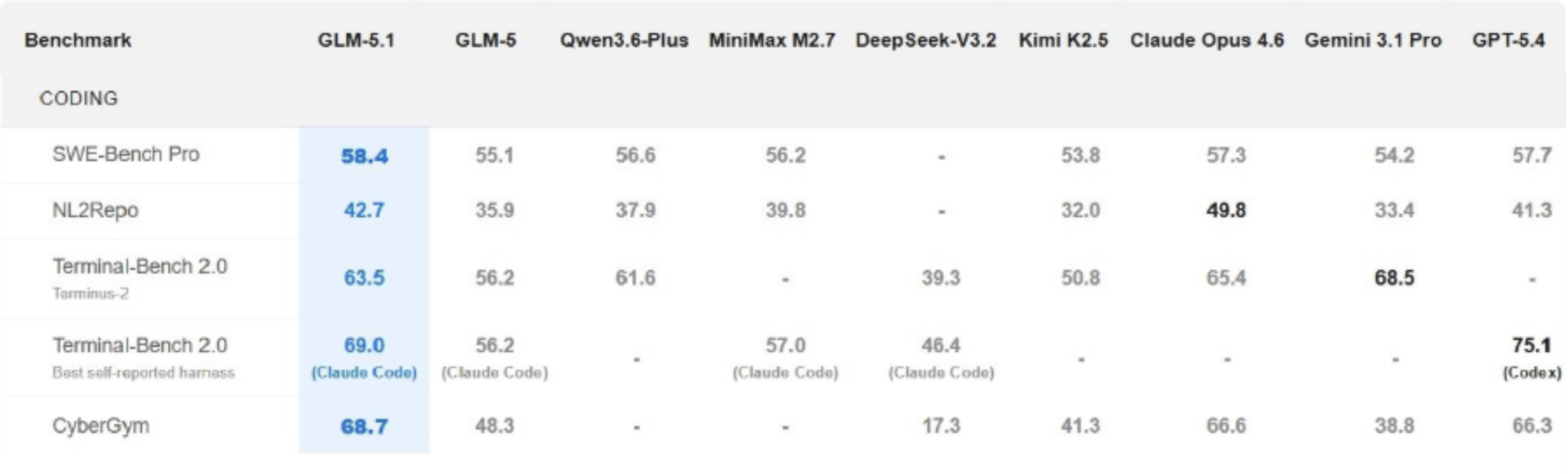
GLM-5.1 shows exceptional ability to complete programming assignments. Its coding performance achieved a score of 58.4 on SWE-Bench Pro, surpassing both GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). GLM-5.1 reached a score above 55 across three coding tests, including SWE-Bench Pro, Terminal-Bench 2.0, and CyberGym, to secure the third position worldwide behind GPT-5.4 (58.0) and Claude 4.6 (57.5) overall. The system outperforms GLM-5 by a significant margin, which shows its better performance in coding tasks with scores of 68.7 compared to 48.3. The new system allows GLM-5.1 to produce intricate code with greater accuracy than before.
Agentic
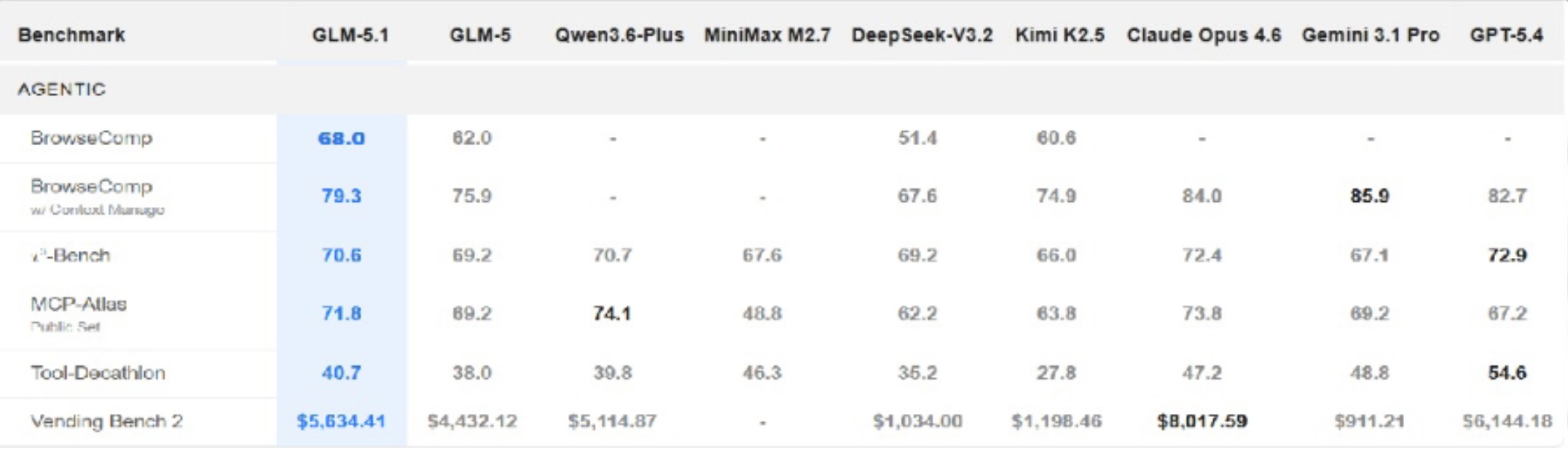
The GLM-5.1 supports agentic workflows, which include multiple steps that require both planning and code execution and tool utilization. This system displays significant progress during prolonged operational periods. Through its operation on the VectorDBBench optimization task, GLM-5.1 executed 655 iterations, which included more than 6000 tool functions to discover several algorithmic enhancements. Also maintains its development track after reaching 1000 tool usage, which proves its ability to keep improving through sustained optimization.
- VectorDBBench: Achieved 21,500 QPS over 655 iterations (6× gain) on an index optimization task.
- KernelBench: 3.6× ML performance gain on GPU kernels vs 2.6× for GLM-5, continuing past 1000 turns.
- Self-debugging: Built a complete Linux desktop stack from scratch within 8 hours (planning, testing, error-correction) as claimed by Z.ai.
Reasoning
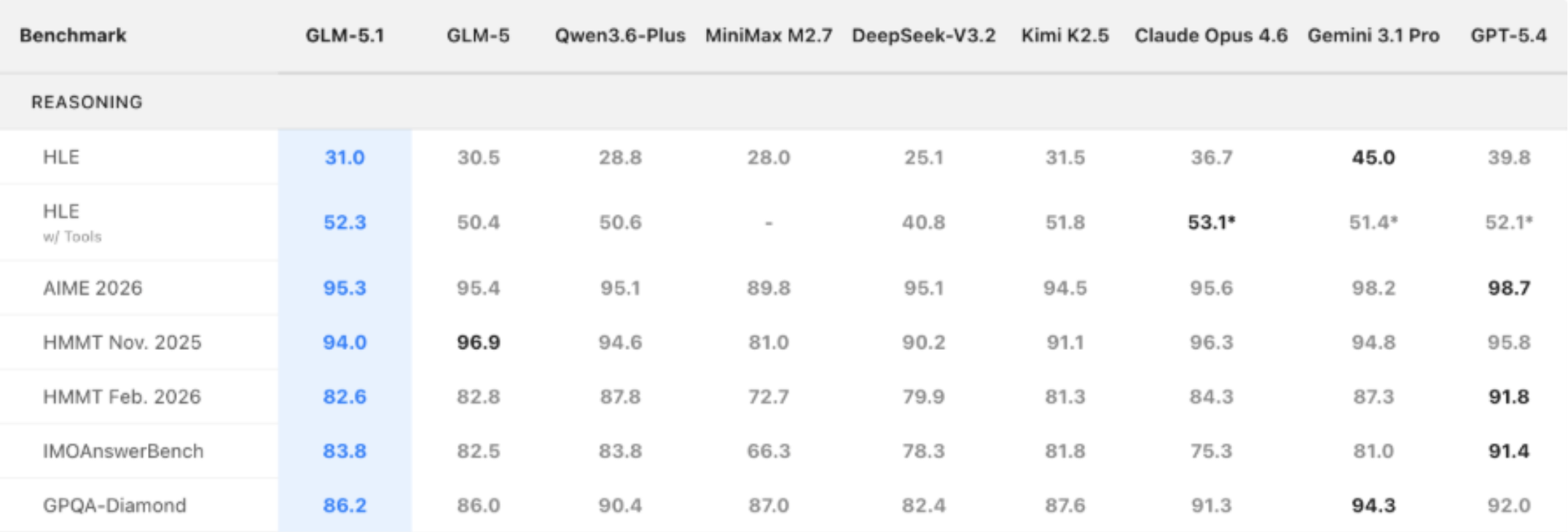
GLM-5.1 provides excellent results across standard reasoning tests and QA evaluation tests. The system demonstrates performance results that match leading systems used for general intelligence assessment.
GLM-5.1 achieved 95.3% on AIME, which is an advanced math competition, and 86.2% on GPQA, which tests advanced question-answering abilities. The scores approach the highest performance of top systems, which include GPT-5.4 that achieved 98.7% and 94.3% in two separate assessments. GLM-5.1 demonstrates extensive academic capabilities, which result in high achievement across multiple disciplines and Olympiad competitions.
GLM-5.1 Capabilities
GLM-5.1 performs exceptionally well in three specific tasks – long-term planning, code generation, and multi-turn logical reasoning. The software can produce and debug computer code, while it can solve difficult inquiries and execute complex tasks with excellent results. The system enables developers to construct “agents” that use its function calling and structured output capabilities to interact with various tools. The two tasks shown here demonstrate the system’s programming capabilities. The system allows users to solve problems through prompts, leading to accurate solutions that frequently include code.
Task 1: Finding the Factorial of a Large Number
Prompt:
“Hi, you are an excellent code instructor, so help me with this question.
Q. Write Python code for finding the Factorial of a Large Number.”
Response by GLM-5.1:
def factorial_large(n: int) -> str:
if n < 0: return ""
if n == 0: return "1"
# Array to store individual digits (stored in reverse order for easier carry handling)
res = [1]
for x in range(2, n + 1):
carry = 0
# Multiply x with every digit in the current result
for i in range(len(res)):
product = res[i] * x + carry
res[i] = product % 10
carry = product // 10
# Append the remaining carry to the result array
while carry:
res.append(carry % 10)
carry //= 10
# The digits are stored in reverse order, so reverse and join them
return "".join(map(str, res[::-1]))Output:

Verdict: The system shows efficient functioning because it follows a two-pointer technique, providing the best performance results. The solution uses minimum overhead resources while implementing effective helper functions. The implementation exists in a short format, lacking complete documentation and commentary. This makes it more suitable for solving problems rapidly instead of using it in production environments, which need readable and maintainable code.
Task 2: Checking if a String is a Palindrome
Prompt:
“Hi, you are an excellent code instructor, so help me with this question.
Q. Given a string s, return true if s can be a palindrome after deleting at most one character from it.”
Response by GLM-5.1:
def validPalindrome(s: str) -> bool:
def is_palindrome(l: int, r: int) -> bool:
while l < r:
if s[l] != s[r]:
return False
l += 1
r -= 1
return True
left, right = 0, len(s) - 1
while left < right:
if s[left] != s[right]:
return is_palindrome(left + 1, right) or is_palindrome(left, right - 1)
left += 1
right -= 1
return TrueOutput:

Verdict: The response from GLM-5.1 shows efficient performance combined with technical validity. It shows competence in executing extensive numerical operations through manual digit processing. The system achieves its design goals through its iterative method, which combines performance with correct output. The implementation exists in a short format and provides limited documentation through basic error handling. This makes the code appropriate for algorithm development but unsuitable for production usage because that environment requires clear, extendable, and strong performance.
Overall Review of GLM-5.1 Capabilities
GLM-5.1 provides multiple applications through its open-source infrastructure and its sophisticated system design. This enables developers to create deep reasoning capabilities, code generation functions, and tool utilization systems. The system maintains all existing GLM family strengths through sparse MoE and long context capabilities. It also introduces new functions that allow for adaptive thinking and debugging loop execution. Through its open weights and low-cost API options, the system offers access to research while supporting practical applications in software engineering and other fields.
Conclusion
The GLM-5.1 is a live example of how current AI systems develop their efficiency and scalability, while also improving their reasoning capabilities. It guarantees a high performance with its Mixture-of-Experts architecture, while maintaining a reasonable operational cost. Overall, this system enables the handling of actual AI applications that require extensive operations.
As AI heads towards agent-based systems and extended contextual understanding, GLM-5.1 establishes a base for future development. Its routing system and attention mechanism, together with its multi-token prediction system, create new possibilities for upcoming large language models.






