The AI industry has matured to the point where raw intelligence is no longer the only thing that matters. A year ago, every model release was a race to publish bigger benchmark numbers. More parameters, features and everything in between.
Today, the conversation is shifting. Developers care about reliability. Enterprises care about cost, scalability, and whether a model can be trusted in production environments.
Claude Opus 4.8 arrives at an interesting moment in this evolution. While Anthropic positions it as an improvement over Opus 4.7 across coding, reasoning, and agentic tasks, the release reveals something more important than benchmark gains. It offers a glimpse into where Anthropic believes AI is headed next.
Table of contents
The Cost Question: Same Price, More Power
When frontier models upgrade their reasoning and autonomous capabilities, the industry usually braces for changes. One of the most significant aspects of the Opus 4.8 release is what didn’t change: the pricing.
Anthropic maintained the exact same standard pricing structure used for Opus 4.7. Developers will continue to pay $5 per million input tokens and $25 per million output tokens.
| Pricing Tier | Input Price (Per 1M Tokens) | Output Price (Per 1M Tokens) | Context |
| Standard Mode | $5 | $25 | Identical to Opus 4.7 pricing. |
| Fast Mode (2.5x Speed) | $10 | $50 | 3x cheaper than previous Fast Mode iterations. |
Furthermore, Anthropic heavily discounted the model’s high-speed tier. For developers requiring 2.5x execution speed, the Fast Mode for Opus 4.8 is now three times cheaper than previous iterations, sitting at $10 per million input tokens and $50 per million output tokens.
Anthropic has made the operational expense of scaling agentic workflows far easier to justify.
Beyond Benchmarks: The Honesty Upgrade
Most frontier AI models have reached a plateau where they can perform the majority of professional knowledge work reasonably well. The true differentiation between them increasingly emerges not in obvious successes, but in how they handle edge cases.
Does the model recognize when it lacks sufficient information? Will it confidently push forward and hallucinate despite incomplete evidence?
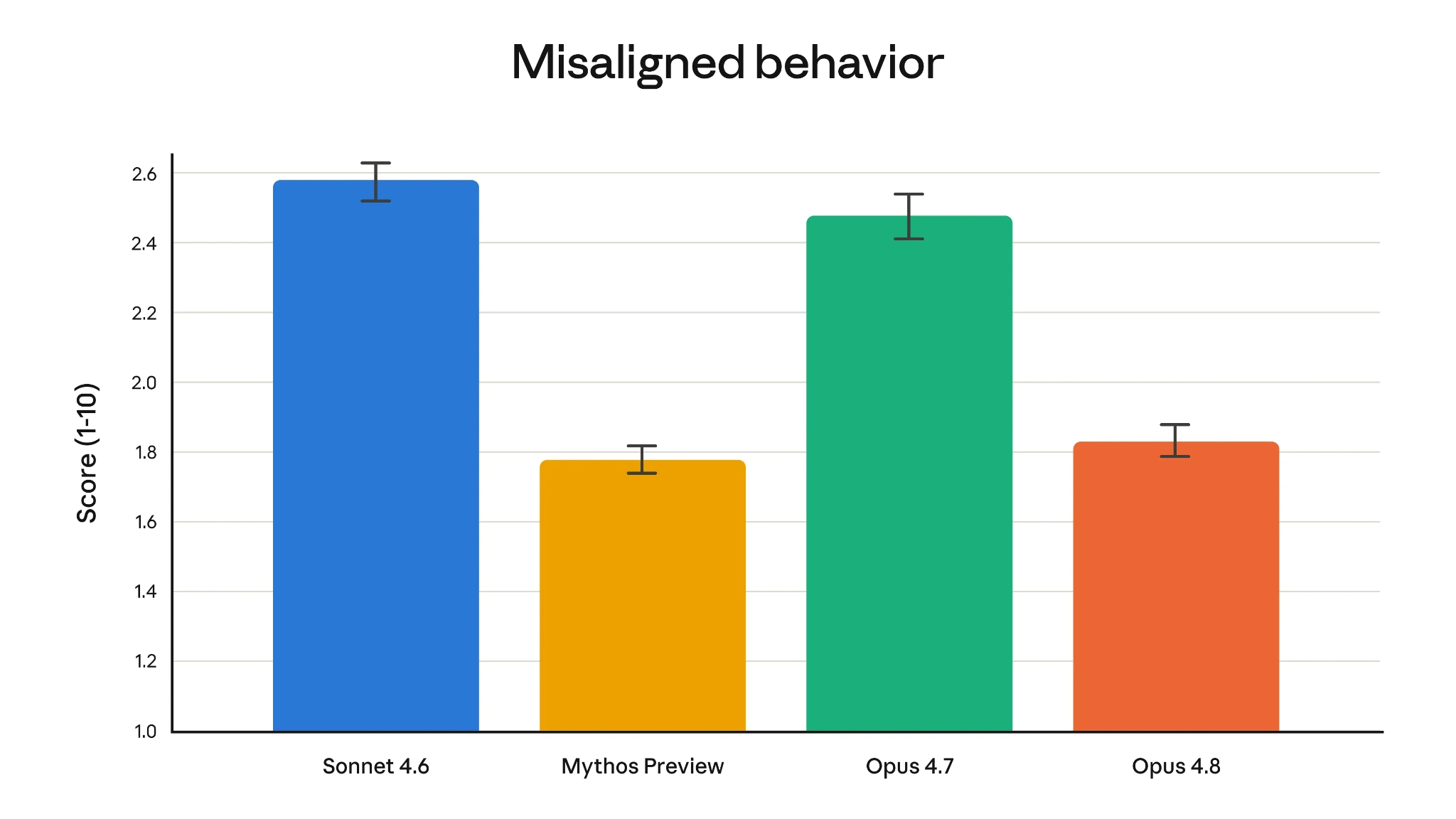
Anthropic explicitly targeted these questions with Opus 4.8. The model is fundamentally trained to be more honest and to flag uncertainties in its own work.
These improvements address some of the most persistent, expensive frustrations developers experience when deploying AI in production. The most useful AI model isn’t necessarily the one that tries to sound the smartest, it’s the one that fails gracefully when it doesn’t know the answer.
The Rise of Agentic Workflows
While the model itself is the headline, the functional product updates accompanying Opus 4.8 reveal Anthropic’s broader strategic direction.
Alongside the model, Anthropic introduced Dynamic Workflows for Claude Code.
This feature allows the model to autonomously plan tasks and run hundreds of parallel subagents in a single session. For example, Claude Code can now execute codebase-scale migrations across hundreds of thousands of lines of code—from kickoff to merge—using the existing test suite to verify its own outputs.
Additionally, users on claude.ai and Cowork now have direct control over the model’s processing depth via an Effort Control slider.
- Lower Settings: Claude responds faster and preserves rate limits.
- Higher Settings: The model spends more tokens to think deeper and frequently self-correct, producing superior results on difficult tasks.
Taken together, these updates signal a broader shift from conversational AI that responds to prompts to operational AI that can plan, coordinate, and execute complex long-horizon workflows autonomously.
Hands-On Testing
Marketing claims are one thing. Actual usage is another. To evaluate where Opus 4.8 appears to improve, we tested it across three practical scenarios that mirror common business and engineering workflows.
Reasoning and Accuracy
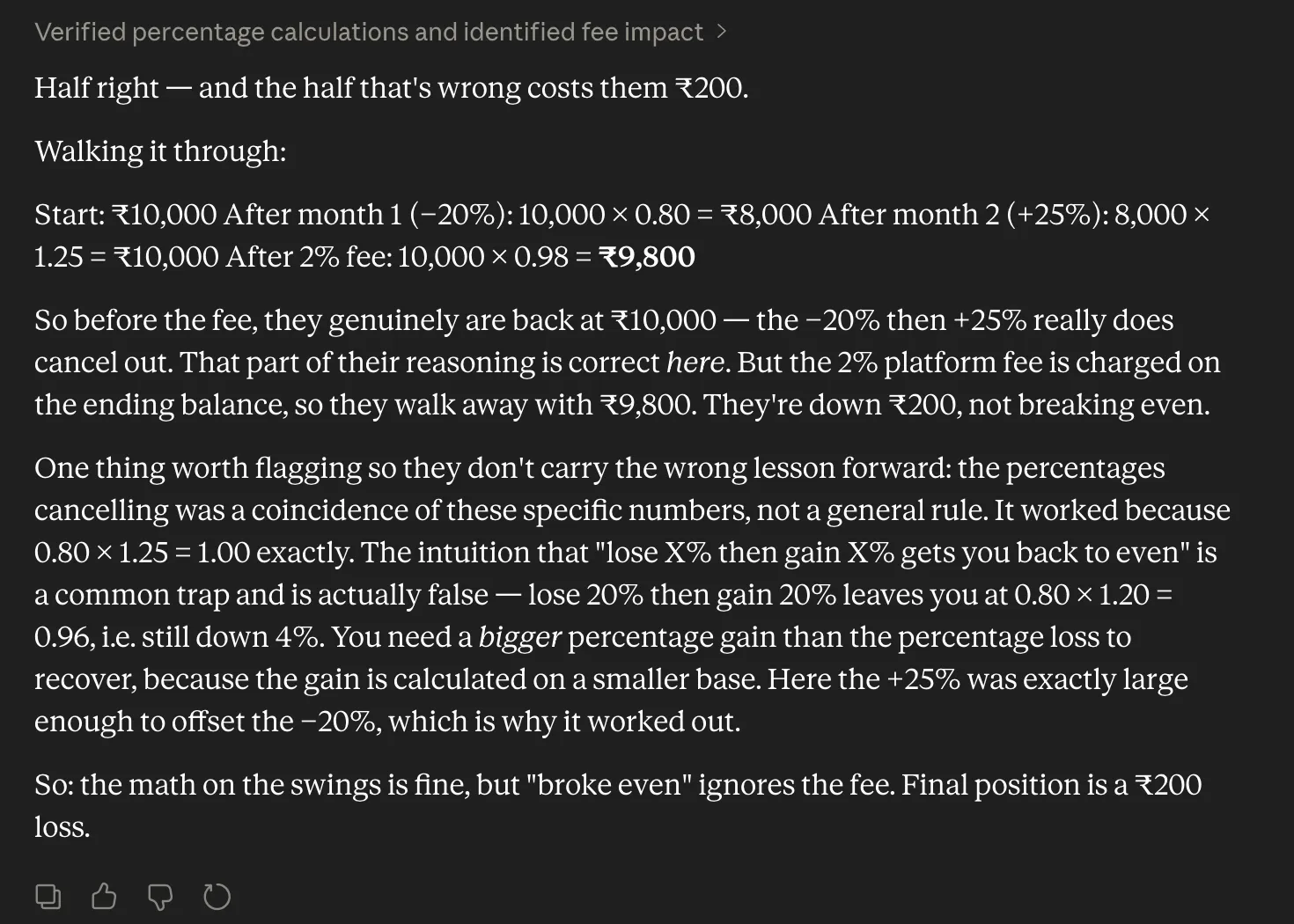
Prompt: “I’m trying to check a simple investment calculation.
Someone invests ₹10,000. In the first month, it drops by 20%. In the second month, it goes up by 25%. Then the platform charges a 2% fee on the ending balance.
The person says they broke even because losing 20% and then gaining 25% brings them back to the original amount. Is that right?”
Response:
Coding Review
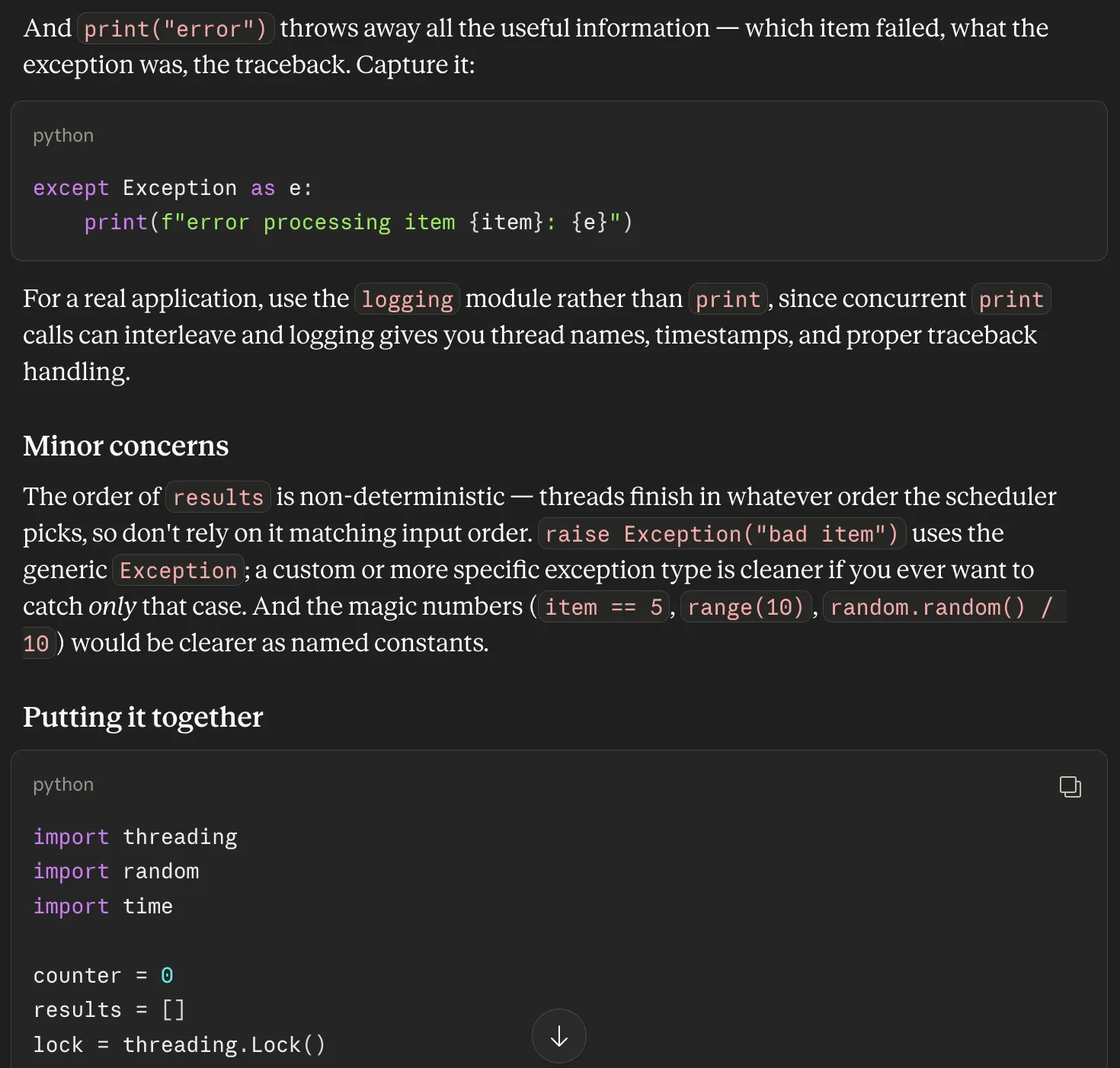
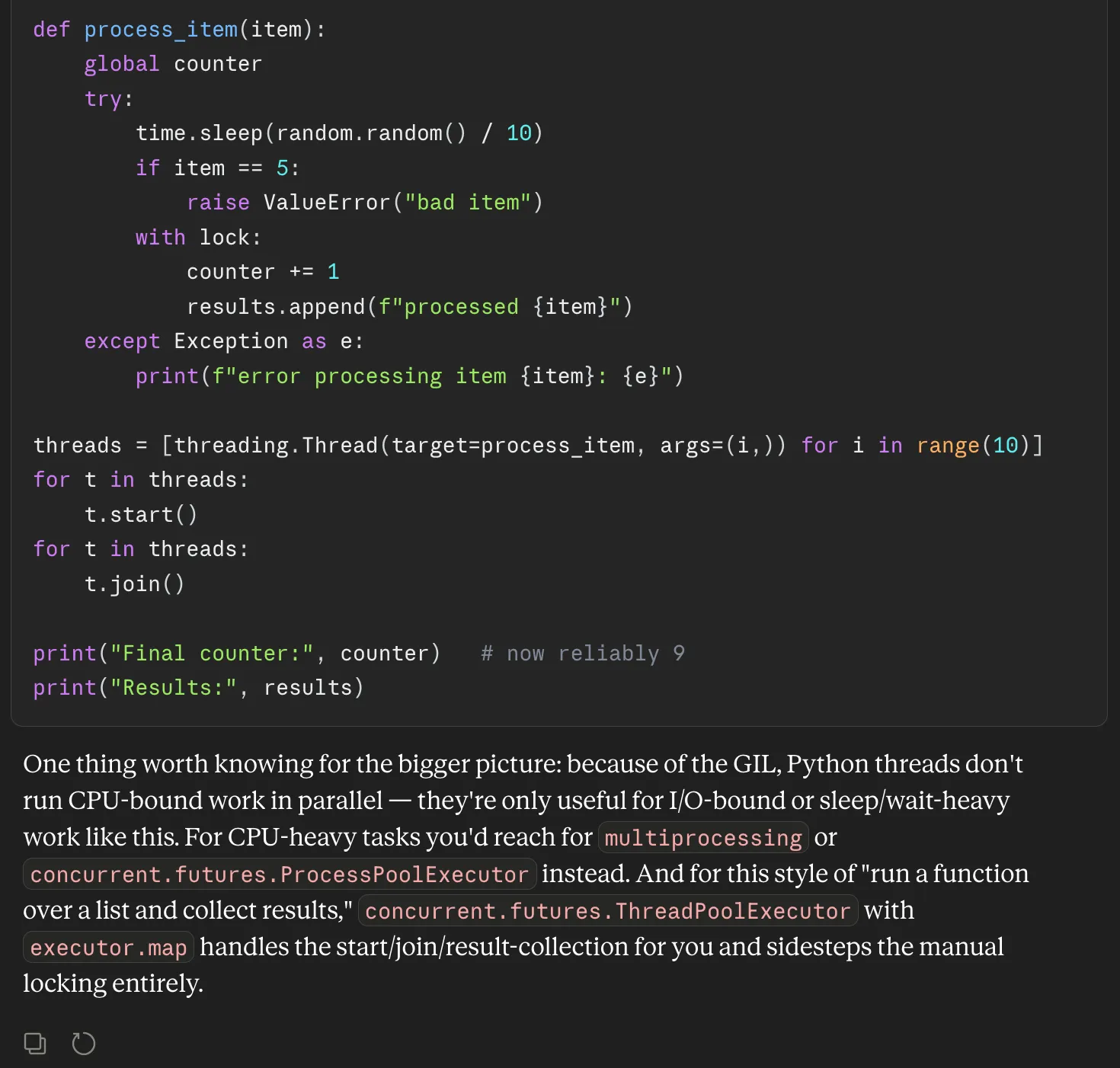
Prompt: “I have this Python script that processes a list of items using threads. It usually works, but sometimes the final count looks off, and errors are hard to debug. Can you review it and suggest what might be wrong?”
Code:
import threading
import time
import random
counter = 0
results = []
def process_item(item):
global counter
try:
time.sleep(random.random() / 10)
if item == 5:
raise Exception("bad item")
counter += 1
results.append(f"processed {item}")
except:
print("error")
threads = []
for i in range(10):
t = threading.Thread(target=process_item, args=(i,))
threads.append(t)
t.start()
print("Final counter:", counter)
print("Results:", results)Response:
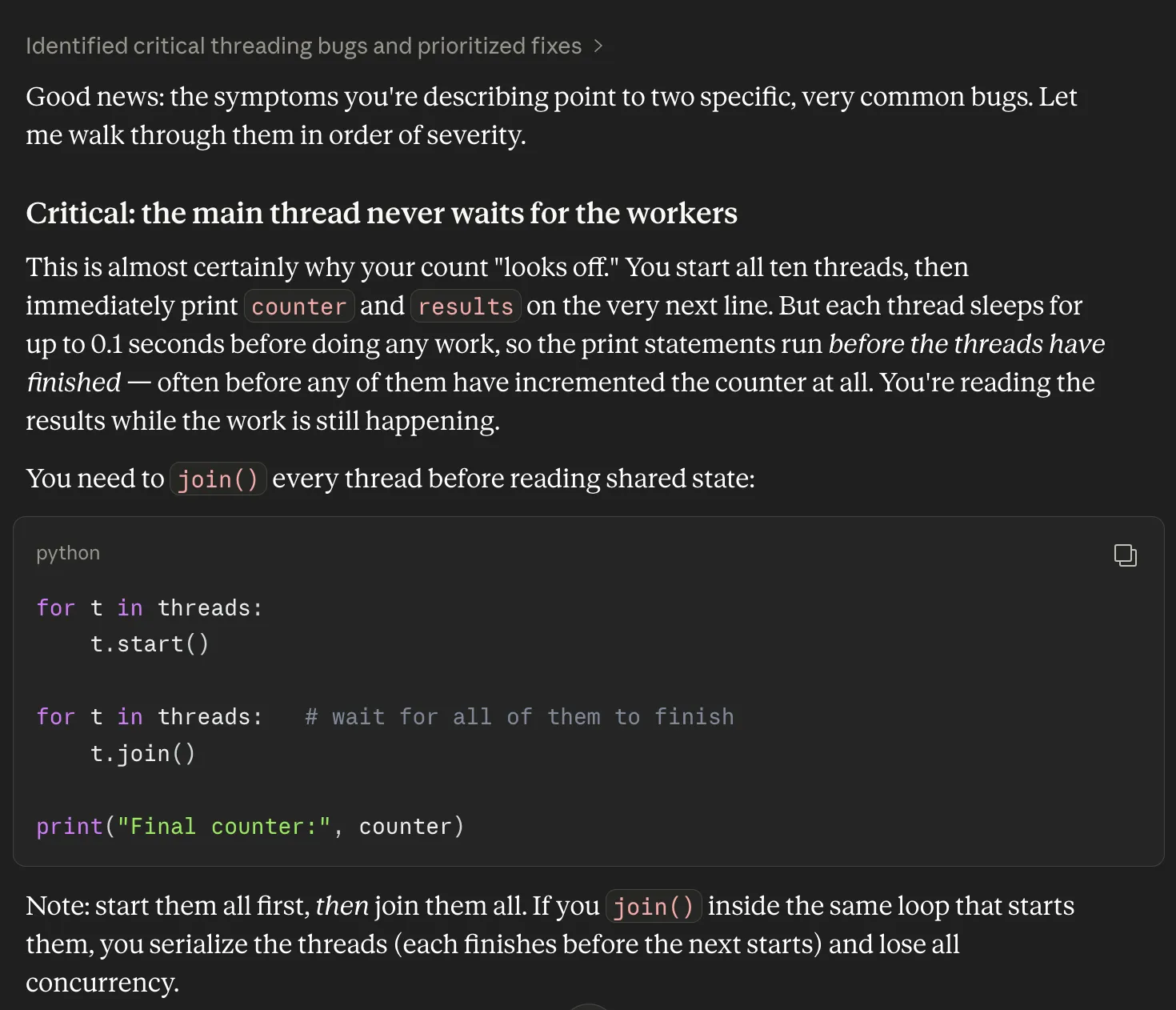
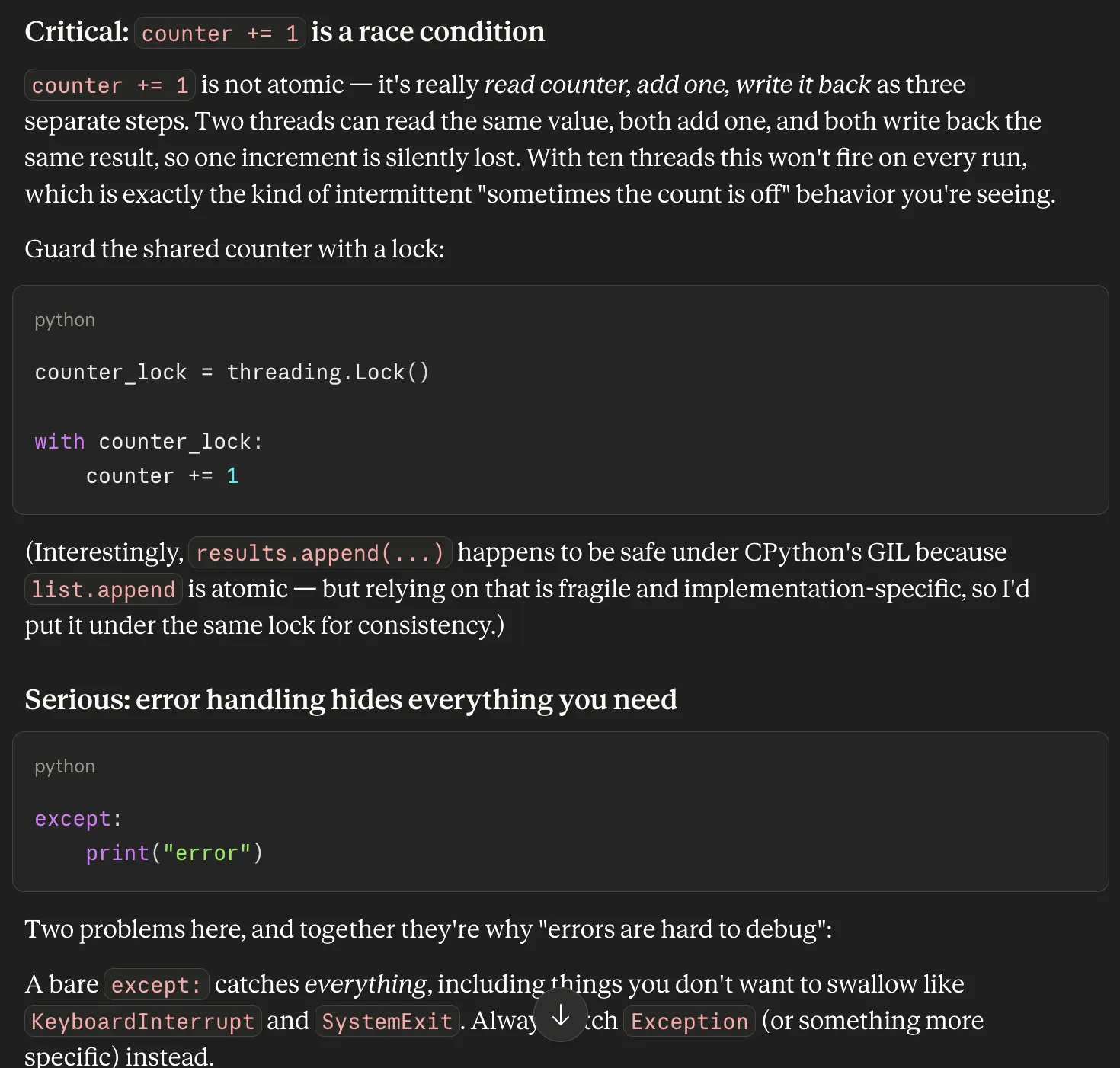
Strategic Planning
Prompt: “Our company has automation all over the place. Finance has some scripts, HR uses a few workflow tools, customer support has bots, and operations has its own RPA setup. Leadership now wants to move toward a centralized multi-agent AI platform over the next year.
How should we think about this migration? I’m looking for a practical plan that covers rollout, risks, governance, budgeting, and stakeholder management.”
Response:
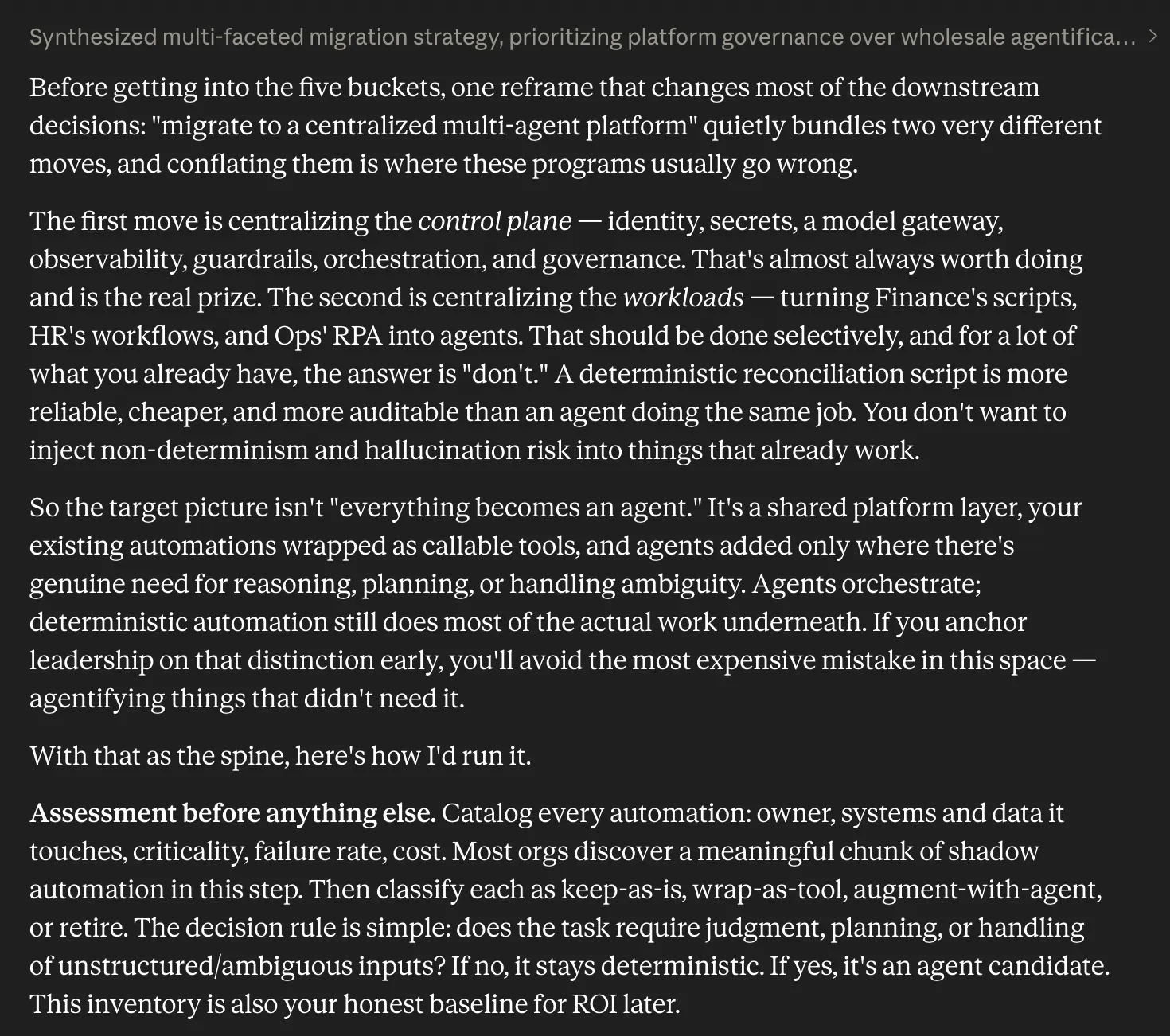


The Rise of Agentic Workflows
While Opus 4.8 itself is the headline, the accompanying product updates may be even more revealing.
Anthropic introduced Dynamic Workflows alongside the model release. The feature allows Claude Code to coordinate large numbers of parallel subagents, execute complex plans, verify outputs, and manage long-running tasks. Taken together, these updates suggest a broader strategic direction.
For years, AI products have primarily functioned as assistants. Users ask questions. Models provide answers. Increasingly, however, businesses want systems capable of executing work rather than merely discussing it.
That distinction is subtle but important:
- Generating a project plan is useful.
- Coordinating the execution of that project is substantially more valuable.
The industry is gradually moving from conversational AI toward operational AI, and Anthropic appears to be positioning Opus within that transition.
Opus 4.8 vs Opus 4.7
For casual users, the difference between Opus 4.7 and Opus 4.8 may feel incremental. The improvements become easier to notice when workflows grow more complex.
| Feature / Attribute | Claude Opus 4.7 | Claude Opus 4.8 |
| Primary Focus | Raw intelligence and benchmark performance | Reliability, consistency, and workflow execution |
| Coding Performance | Strong coding and debugging capabilities | Better verification and error detection |
| Uncertainty Handling | More likely to push toward an answer | More willing to surface uncertainty |
| Agentic Workflows | Handles multi-step tasks | Better suited for long-running agent workflows |
| Workflow State | Traditional conversational execution | Optimized for Dynamic Workflows |
| Effort Controls | Not available | Supports adjustable effort levels |
| Reliability | Occasionally overconfident | Improved consistency and restraint |
| Enterprise Usage | General-purpose deployments | Better aligned with operational automation |
| API Pricing | $5/M input, $25/M output | Unchanged at $5/M input, $25/M output |
| Best For | Research, coding, and content generation | Agentic systems, automation, and complex workflows |
Opus 4.8 feels less eager to impress and more focused on producing dependable results. For businesses deploying AI systems at scale, that distinction matters.
Stop Automating. Start Orchestrating.
Claude Opus 4.8 is not a revolutionary release, and Anthropic doesn’t seem to be presenting it as one.
Instead, the company has focused on refining areas that become increasingly important as AI moves from experimentation into production. Reliability, uncertainty handling, workflow execution, and operational efficiency may not generate the same excitement as benchmark records, but they solve real problems for real users.
More importantly, the release hints at a broader industry shift. The future of AI may not belong solely to the models that generate the best responses. It may belong to the systems that can reliably execute meaningful work. Viewed through that lens, Opus 4.8 feels less like a model upgrade and more like a step toward the next generation of AI-powered workflows.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






