LLMs are no longer restricted to a question-answer format. They now form the basis of intelligent applications that help with real-world problems in real-time. In that context, Kimi K2 comes as a multiple-purpose LLM that is immensely popular among AI users worldwide. While everyone knows of its powerful agentic capabilities, not many are sure how it performs on the API. Here, we test Kimi K2 in a real-world production scenario, through an API-based workflow to evaluate whether Kimi K2 stands up to its promise of a great LLM.
Table of contents
Also read: Want to find the best open-source system? Read our comparison review between Kimi K2 and Llama 4 here.
What is Kimi K2?
Kimi K2 is a state-of-the-art open-source large language model built by Moonshot AI. It employs a Mixture-of-Experts (MoE) architecture and has 1 trillion total parameters (32 billion activated per token). Kimi K2 particularly incorporates forward-thinking use cases for advanced agentic intelligence. It is capable not only of generating and understanding natural language but also of autonomously solving complex problems, utilizing tools, and completing multi-step tasks across a broad range of domains. We covered all about its benchmark, performance, and access points in detail in an earlier article: Kimi K2 the best open-source agentic model.
Model Variants
There are two variants of Kimi K2:
- Kimi-K2-Base: The bare-bones model, a great starting point for researchers and builders who want to have full control over fine-tuning and custom solutions.
- Kimi-K2-Instruct: The post-trained model that is best for a drop-in, general-purpose chat and agentic experience. It is a reflex-grade model with no deep thinking.
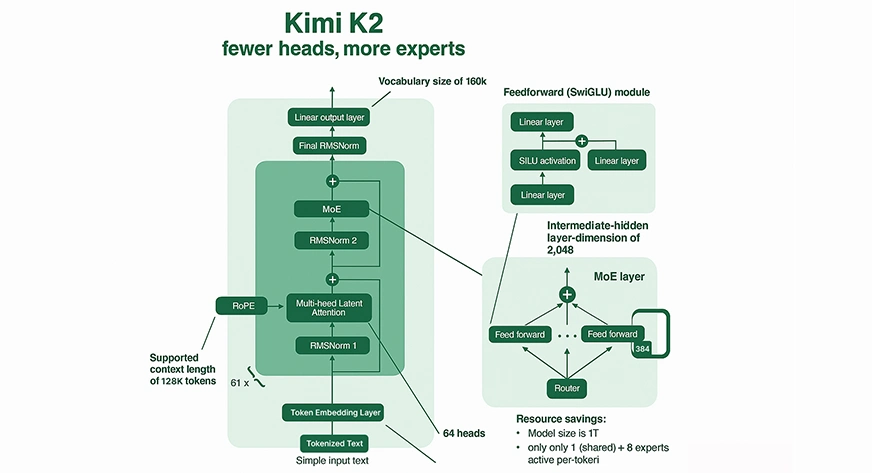
Mixture-of-Experts (MoE) Mechanism
Fractional Computation: Kimi K2 does not activate all parameters for each input. Instead, Kimi K2 routes every token into 8 of its 384 specialized “experts” (plus one shared expert), which offers a significant decrease in compute per inference compared to both the MoE model and dense models of comparable size.
Expert Specialization: Each expert within the MoE specializes in different knowledge domains or reasoning patterns, leading to rich and efficient outputs.
Sparse Routing: Kimi K2 utilizes smart gating to route relevant experts for each token, which supports both huge capacity and computationally feasible inference.
Attention and Context
Massive Context Window: Kimi K2 has a context length of up to 128,000 tokens. It can process extremely long documents or codebases in a single pass, an unprecedented context window, far exceeding most legacy LLMs.
Complex Attention: The model has 64 attention heads per layer, enabling it to track and leverage complicated relationships and dependencies across the sequence of tokens, typically up to 128,000.
Training Innovations
MuonClip Optimizer: To allow for stable training at this unprecedented scale, Moonshot AI developed a new optimizer called MuonClip. It bounds the scale of the attention logits by rescaling the query and key weight matrices at each update to avoid the extreme instability (i.e., exploding values) common in large-scale models.
Data Scale: Kimi K2 was pre-trained on 15.5 trillion tokens, which develops the model’s knowledge and ability to generalize.
How to Access Kimi K2?
As mentioned, Kimi K2 can be accessed in two ways:
Web/Application Interface: Kimi can be accessed instantly for use from the official web chat.
API: Kimi K2 can be integrated with your code using either the Together API or Moonshot’s API, supporting agentic workflows and the use of tools.
Steps To Obtain an API Key
For running Kimi K2 through an API, you will need an API key. Here is how to get it:
Moonshot API:
- Sign up or log in to the Moonshot AI Developer Console.
- Go to the “API Keys” section.
- Click “Create API Key,” provide a name and project (or leave as default), then save your key for use.
Together AI API:
- Register or log in at Together AI.
- Locate the “API Keys” area in your dashboard.
- Generate a new key and record it for later use.
Local Installation
Download the weights from Hugging Face or GitHub and run them locally with vLLM, TensorRT-LLM, or SGLang. Simply follow these steps.
Step 1: Create a Python Environment
Using Conda:
conda create -n kimi-k2 python=3.10 -y
conda activate kimi-k2Using venv:
python3 -m venv kimi-k2
source kimi-k2/bin/activateStep 2: Install Required Libraries
For all methods:
pip install torch transformers huggingface_hubvLLM:
pip install vllmTensorRT-LLM:
Follow the official [TensorRT-LLM install documentation] (requires PyTorch >=2.2 and CUDA == 12.x; not pip installable for all systems).
For SGLang:
pip install sglangStep 3: Download Model Weights
From Hugging Face:
With git-lfs:
git lfs install
git clone https://huggingface.co/moonshot-ai/Kimi-K2-InstructOr using huggingface_hub:
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="moonshot-ai/Kimi-K2-Instruct",
local_dir="./Kimi-K2-Instruct",
local_dir_use_symlinks=False,
)Step 4: Verify Your Environment
To ensure CUDA, PyTorch, and dependencies are ready:
import torch
import transformers
print(f"CUDA Available: {torch.cuda.is_available()}")
print(f"CUDA Devices: {torch.cuda.device_count()}")
print(f"CUDA Version: {torch.version.cuda}")
print(f"Transformers Version: {transformers.__version__}")Step 5: Run Kimi K2 With Your Preferred Backend
With vLLM:
python -m vllm.entrypoints.openai.api_server \
--model ./Kimi-K2-Instruct \
--swap-space 512 \
--tensor-parallel-size 2 \
--dtype float16Adjust tensor-parallel-size and dtype based on your hardware. Replace with quantized weights if using INT8 or 4-bit variants.
Hands-on with Kimi K2
In this exercise, we will be taking a look at how large language models like Kimi K2 work in real life with real API calls. The objective is to test its efficacy on the move and see if it provides a strong performance.
Task 1: Creating a 360° Report Generator using LangGraph and Kimi K2:
In this task, we will create a 360-degree report generator using the LangGraph framework and the Kimi K2 LLM. The application is a showcase of how agentic workflows can be choreographed to retrieve, process, and summarize information automatically through the use of API interactions.
Code Link: https://github.com/sjsoumil/Tutorials/blob/main/kimi_k2_hands_on.py
Code Output:
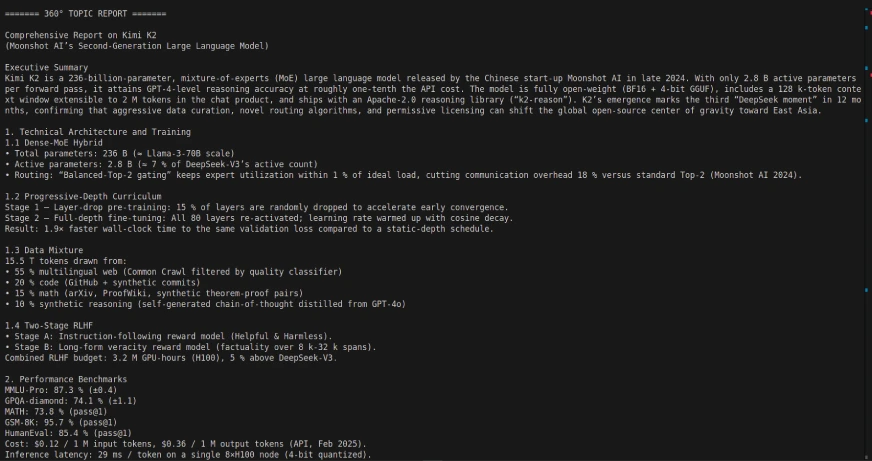
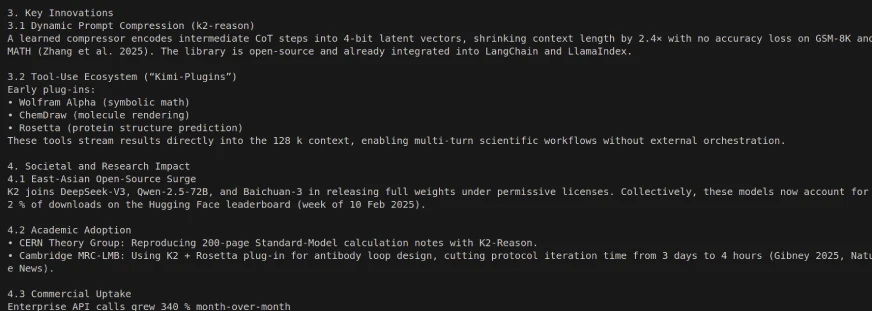
Employing Kimi K2 with LangGraph can allow for some powerful, autonomous multi-step, agentic workflow, as Kimi K2 is designed to autonomously decompose multi-step tasks, such as database querying, reporting, and document processing, using tool/api integrations. Just temper your expectations for some of the response times.
Task 2: Creating a simple chatbot using Kimi K2
Code:
from dotenv import load_dotenv
import os
from openai import OpenAI
load_dotenv()
OPENROUTER_API_KEY = os.getenv("OPENROUTER_API_KEY")
if not OPENROUTER_API_KEY:
raise EnvironmentError("Please set your OPENROUTER_API_KEY in your .env file.")
client = OpenAI(
api_key=OPENROUTER_API_KEY,
base_url="https://openrouter.ai/api/v1"
)
def kimi_k2_chat(messages, model="moonshotai/kimi-k2:free", temperature=0.3, max_tokens=1000):
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=temperature,
max_tokens=max_tokens,
)
return response.choices[0].message.content
# Conversation loop
if __name__ == "__main__":
history = []
print("Welcome to the Kimi K2 Chatbot (type 'exit' to quit)")
while True:
user_input = input("You: ")
if user_input.lower() == "exit":
break
history.append({"role": "user", "content": user_input})
reply = kimi_k2_chat(history)
print("Kimi:", reply)
history.append({"role": "assistant", "content": reply})Output:
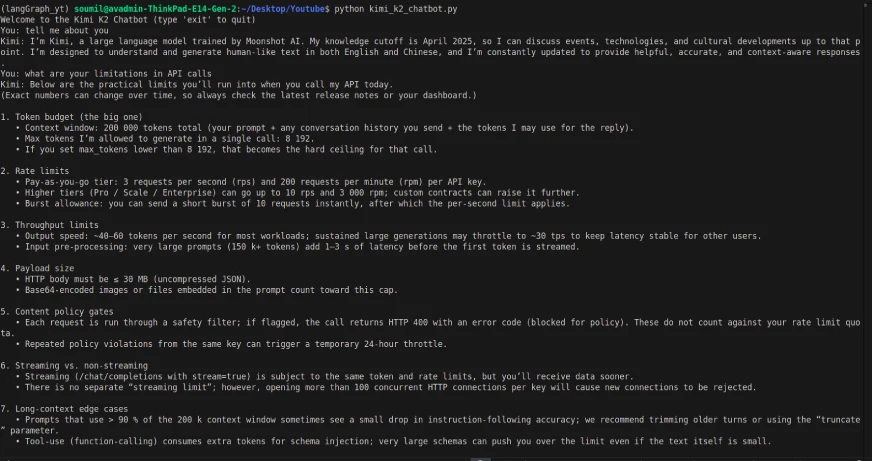
Despite the model being multimodal, the API calls only had the ability to provide text-based input/output (and text input had a delay). So, the interface and the API call act a little bit differently.
My review after the hands-on
The Kimi K2 is an open-source and large language model, which means it’s free, and this is a big plus for developers and researchers. For this exercise, I accessed Kimi K2 with an OpenRouter API key. While I previously accessed the model through the easy-to-use web interface, I preferred to use the API for more flexibility and to build a custom agentic workflow in LangGraph.
During testing the chatbot, the response times I experienced with the API calls were noticeably delayed, and the model cannot, yet, support multi-modal capabilities (e.g., image or file processing) through the API like it can in the interface. Regardless, the model worked well with LangGraph, which allowed me to design a complete pipeline for generating dynamic 360° reports.
While it was not earth-shattering, it illustrates how open-source models are rapidly catching up to the proprietary leaders, such as OpenAI and Gemini, and they are going to continue to close the gaps with models like Kimi K2. It is an impressive performance and flexibility for a free model, and it shows that the bar is getting higher on multimodal capabilities with LLMs that are open-source.
Conclusion
Kimi K2 is a great option in the open-source LLM landscape, especially for agentic workflows and ease of integration. While we ran into a few limitations, such as slower response times via API and a lack of multimodality support, it provides a great place to start developing intelligent applications in the real world. Plus, not having to pay for these capabilities is one huge perk that helps developers, researchers, and start-ups. As the ecosystem evolves and matures, we will see models like Kimi K2 gain advanced capabilities rapidly as they quickly close the gap with proprietary companies. Overall, if you are considering open-source LLMs for production use, Kimi K2 is a possible option well worth your time and experimentation.
Frequently asked questions
Q1. What is Kimi K2?
A. Kimi K2 is Moonshot AI’s next-generation Mixture-of-Experts (MoE) large language model with 1 trillion total parameters (32 billion activated parameters per interaction). It is designed for agentic tasks, advanced reasoning, code generation, and tool use.
Q2. What are the main use cases for Kimi K2?
– Advanced code generation and debugging
– Automated agentic task execution
– Reasoning and solving complex, multi-step problems
– Data analysis and visualization
– Planning, research assistance, and content creation
Q3. What are the key features and specifications of Kimi K2?
– Architecture: Mixture-of-Experts Transformer
– Total Parameters: 1T (trillion)
– Activated Parameters: 32B (billion) for each query
– Context Length: Up to 128,000 tokens
– Specialization: Tool use, agentic workflows, coding, long sequence processing
Q4. How is Kimi K2 accessed and what are its deployment options?
– API Access: Available from Moonshot AI’s API console (and also supported from Together AI and OpenRouter)
– Local Deployment: Possible locally; requires powerful local hardware typically (for effective use requires multiple high-end GPUs)
– Model Variants: Released as “Kimi-K2-Base” (for customization/fine-tuning) and “Kimi-K2-Instruct” (for general-purpose chat, agentic interactions).
Q5. In what ways does Kimi K2’s performance compare against other language models?
A. Kimi K2 typically equals or exceeds, leading open-source models (for example, DeepSeek V3, Qwen 2.5). It is competitive with proprietary models on benchmarks for coding, reasoning, and agentic tasks. It is also remarkably efficient and low-cost as compared to other models of similar or smaller scale!
I am a Data Science Trainee at Analytics Vidhya, passionately working on the development of advanced AI solutions such as Generative AI applications, Large Language Models, and cutting-edge AI tools that push the boundaries of technology. My role also involves creating engaging educational content for Analytics Vidhya’s YouTube channels, developing comprehensive courses that cover the full spectrum of machine learning to generative AI, and authoring technical blogs that connect foundational concepts with the latest innovations in AI. Through this, I aim to contribute to building intelligent systems and share knowledge that inspires and empowers the AI community.






