Have you ever wished your AI agent could learn and adapt on the fly, just like you do? Imagine an AI assistant that, after failing a task once, remembers its mistake and never repeats it. An AI that doesn’t just respond to prompts but actively gets smarter with every single interaction.
For years, this has been the holy grail of artificial intelligence, a dream held back by two major roadblocks. We’ve built powerful AI agents, but they either stay stuck in a fixed way of thinking or fail in real-world scenarios that need continuous learning. It’s a classic dilemma: a static genius versus a slow learner with a never-ending appetite for power and data.
But what if there was a third way? A new research paper has come out with a way that allows AI agents to learn continuously from a changing environment without involving the hefty costs of fine-tuning the massive models that power them. Memento is a revolutionary approach that does exactly that. By giving LLM agents an external, human-like memory, Memento offers a scalable, efficient, and incredibly powerful pathway to the next generation of generalist AI. In this blog, we will break down the details of Memento and how it works.
Table of contents
The Problem with Today’s LLM Agents
Large Language Model (LLM) agents are the future. Unlike traditional LLMs that just answer questions, these agents are proactive problem-solvers. They can autonomously perform complex tasks by using external tools and reasoning through problems step-by-step.
However, as powerful as they are, most LLM agents fall into one of two categories, each with a critical flaw:
- The Rigid Agent: This type of agent is built with a fixed, hard-coded workflow. It’s great at its specific job, but it can’t adapt. It won’t incorporate new information on its own or learn from its mistakes in real-time. Think of a highly specialized machine that can only do one task perfectly.
- The Fine-Tuning Agent: This is the more flexible, but incredibly costly, approach. These agents are updated by fine-tuning their core LLM parameters based on new data or reinforcement learning. This allows for more dynamic behavior, but the process is a logistical nightmare. This makes them impractical for continuous, online learning.
Memento was built to solve this central challenge: How do we create an AI that can continuously learn without the constant, expensive, and risky process of fine-tuning?
What is Memento?
Memento is basically a memory-driven framework that allows LLM agents to learn from experience like any human would. They recall, adapt, and reuse past cases without retraining the base large language model they’re built on.
The creators of Memento looked to the most powerful and efficient learning machine we know: the human brain. Humans don’t “fine-tune” their brains every time they learn something new. Instead, we rely on our memory. We store past experiences, learn from our successes and failures, and use these memories to guide our future decisions, known as Case-Based Reasoning (CBR). It’s a psychological principle that suggests we solve new problems by recalling and adapting solutions from similar past situations.
Memento brings this human-like approach to LLM agents. Instead of fine-tuning the LLM’s core model, Memento gives the agent an external episodic memory called a Case Bank. The Case Bank stores past trajectories, including steps taken, outcomes, and whether they ended in success or failure. This allows the agent to “learn on the fly” without a single gradient update to its foundational model.
Memento framework code can be found here: GitHub
What happens in Memento?
The core of this system is a Memory-augmented Markov Decision Process (M-MDP). It’s a way to model the agent’s decision-making process where its memory is a key part of every choice. This is a massive shift from traditional models that rely solely on their internal, fixed knowledge.
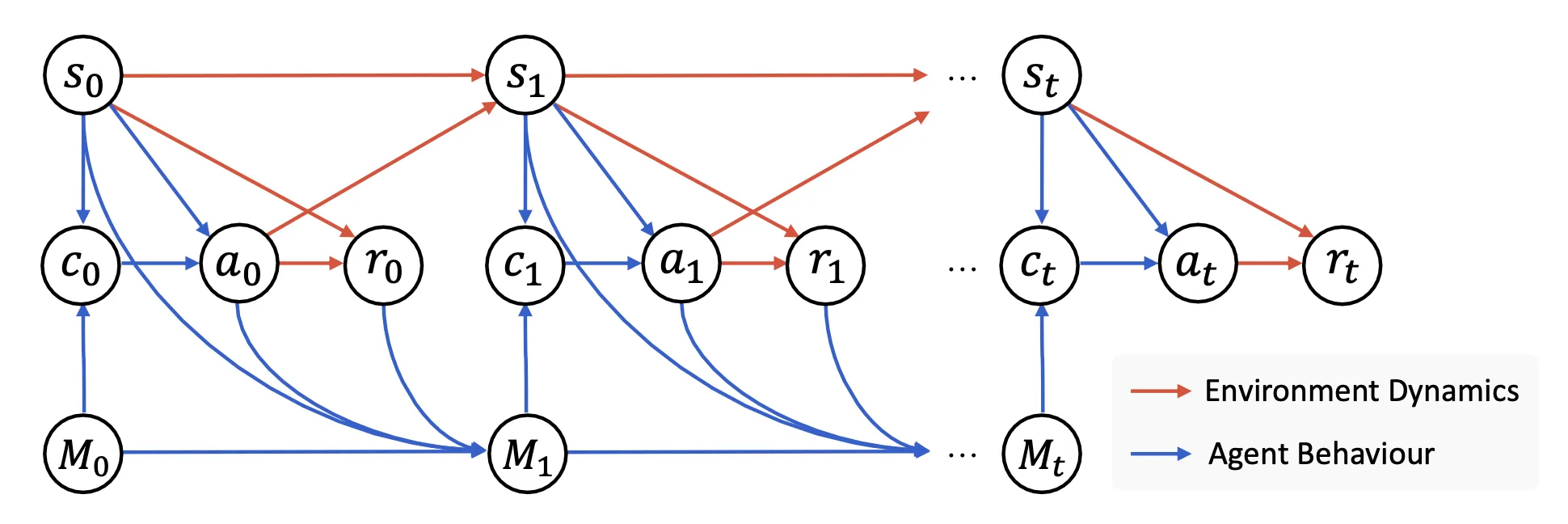
Now that we know what Memento is, let’s dive into its architecture.
How Memento’s Architecture Works?
Memento operates on a simple, yet powerful, two-stage framework:
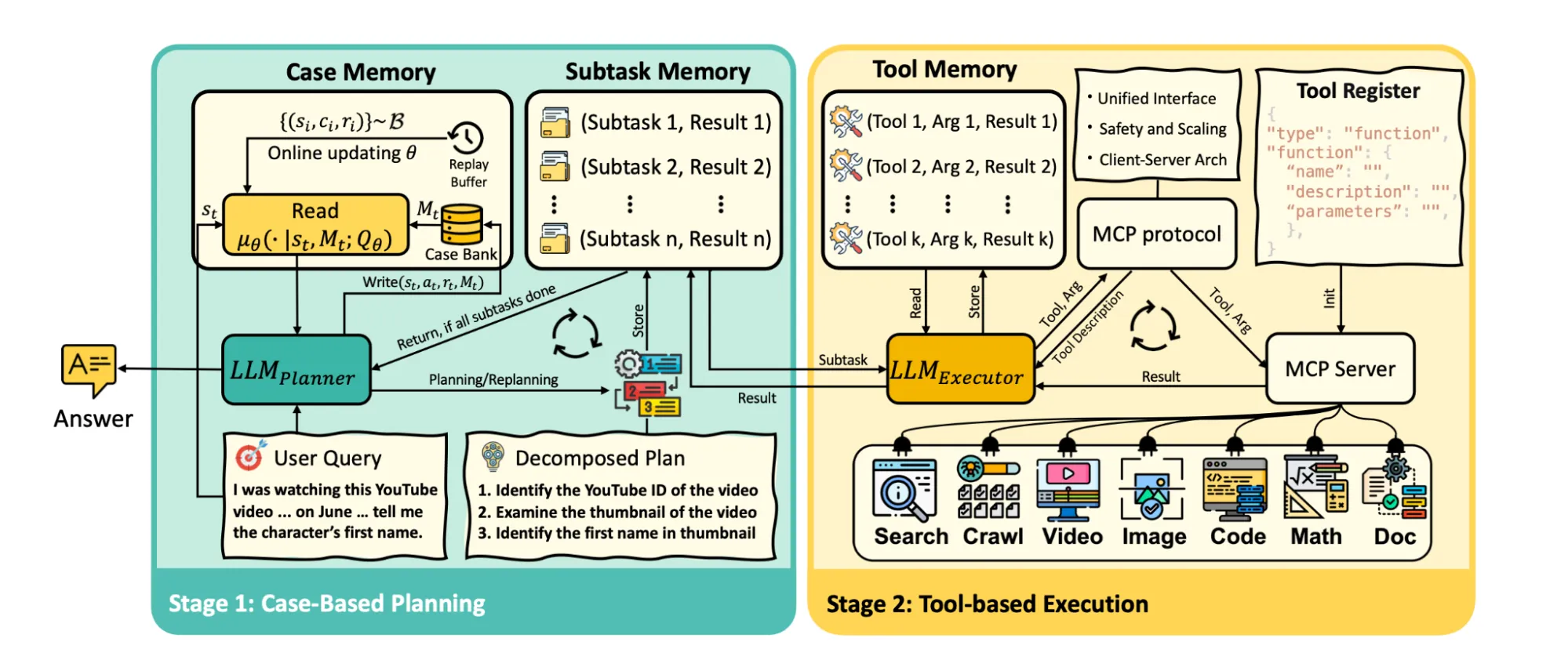
Stage 1: Case-Based Planning
This is where the agent thinks. An LLM acts as the Planner, taking in a user query and, just like a human, breaking it down into a list of sub-tasks. The secret sauce here is the Case Memory.
Before it acts, the Planner “reads” from its Case Bank, retrieving past experiences that are most similar to the current task. The agent then uses these past cases, including both successful and failed attempts, to inform its current plan, helping it to avoid previous mistakes and apply proven strategies.
Stage 2: Tool-Based Execution
Once the Planner has its strategy, it hands off the sub-tasks to the Executor. This is another LLM that is enhanced with a comprehensive set of external tools, such as web search, code interpreters, and file processors. The Executor carries out the plan, one sub-task at a time, using the right tools to get the job done. The agent is even equipped with powerful search and crawling tools to fetch and analyze information from the web in real-time.
Every action the agent takes and the reward it receives (success or failure) is recorded and “written” back into the Case Bank. This creates a continuous feedback loop where the agent’s memory is constantly growing and getting smarter with every new interaction. This process is formalized through soft Q-learning, a method that allows the agent to learn the value of different cases (experiences) over time. It’s a sophisticated way of ensuring the agent learns which past experiences are most valuable to retrieve.
Memento: Real World Performance
The Memento framework is not just a theoretical concept; it has delivered truly remarkable results. The paper details extensive evaluations across multiple benchmarks, and the numbers are compelling:
- Top-1 on GAIA: Memento achieved the #1 spot on the GAIA leaderboard, a benchmark designed to test an agent’s ability to perform complex, long-horizon tasks requiring tool use and autonomous planning. The results were particularly strong on the test set, where it scored 79.40%, a new benchmark for open-source agent frameworks.
- Outperforming the Competition: On the DeepResearcher dataset, which tests real-time web research, Memento reached an impressive 66.6% F1 score and 80.4% PM. It outperformed state-of-the-art training-based systems, proving that a memory-based approach can be more effective than brute-force fine-tuning.
- The Power of Memory: Ablation studies in the paper confirmed the critical role of the Case Bank. The addition of case-based memory alone boosted accuracy on out-of-distribution tasks by as much as 9.6%, showcasing the power of learning from past experiences.
The Memento framework, powered by a combination of models like GPT-4.1 and o4-mini, showcases that it’s not about using the biggest model, but about using the right framework to leverage that model’s capabilities.
Conclusion
The Memento framework represents a profound shift in how we think about and build AI agents. It proves that we can create highly capable, continuously learning systems without the crippling costs and technical complexities of model fine-tuning.
This approach offers a powerful, scalable, and efficient pathway toward building truly generalist LLM agents, the kind of AI that can tackle a wide range of tasks and get better with every single interaction. By embracing a human-like memory and learning paradigm, Memento is not just a better way to build AI; it’s a more intuitive one. It’s a step toward AGI that doesn’t just act intelligently but learns and adapts in a way that feels a lot more… human.
Ready to see how a memory-based approach could change the way you build AI? Check out the code and see Memento in action for yourself. The future of AI is here, and it’s built on a foundation of memory, not just raw power.
Frequently Asked Questions
Q1. What is Memento in LLM agents?
A. Memento is a memory-driven framework that lets LLM agents learn continuously using an external Case Bank, avoiding costly fine-tuning while improving adaptability.
Q2. How does Memento help agents improve performance?
A. It stores past successes and failures, retrieves similar cases for new tasks, and adapts strategies—allowing agents to avoid mistakes and act smarter.
Q3. How effective is Memento compared to fine-tuning?
A. Memento outperformed training-heavy systems, topping the GAIA benchmark with 79.4% and boosting out-of-distribution accuracy by 9.6%—all without retraining the base model.
Anu Madan is an expert in instructional design, content writing, and B2B marketing, with a talent for transforming complex ideas into impactful narratives. With her focus on Generative AI, she crafts insightful, innovative content that educates, inspires, and drives meaningful engagement.





