Guardrails are the building blocks of LLM applications, helping turn experimental LLM apps into reliable, enterprise-grade solutions. How? While LLM-powered AI applications may look effortless in Proof of Concept (POC), scaling them reliably is a hard task. While LLMs excel at open-ended reasoning, they struggle with control and consistency when adapted for specific, mission-critical use cases.
This leads to common production issues, inconsistent behavior, hallucinations, and unpredictable outputs, all of which impact user trust, compliance, and business risk. Since LLMs are inherently probabilistic and sensitive to changes in prompts, data, and context, traditional software engineering alone doesn’t cut it.
That’s why strong guardrails, purpose-built frameworks, and continuous monitoring are crucial to make LLM systems dependable at scale. Here, we explore just how crucial guardrails are for LLM
Table of contents
- What are Guardrails?
- How are Guardrails Implemented?
- What are the types of Guardrails?
- Risks with LLMs
- How do we handle Hallucinations?
- How to make sure our chatbot stays on topic?
- Hands On – Guardrail for Topic Classification
- How to avoid PII (Personal Identifiable Information) leakage
- Hands On – Guardrails for PII filtering
- Preventing Competitor Mentions
- Additional things to explore
- Conclusion
What are Guardrails?
Guardrails in LLM are basically the rules, filters, and checks that keep an AI model’s behavior safe, ethical, and consistent when it’s generating responses.
Think of them as a safety layer wrapped around the model, validating what goes in (inputs) and what comes out (outputs) so the system stays reliable, secure, and aligned with the intended purpose.
How are Guardrails Implemented?
There are several approaches to implementing guardrails in an LLM.
| Approach | Techniques / Use Cases |
|---|---|
| Rules or Heuristic Systems |
|
| Small Finetuned ML Models |
|
| Secondary LLM Call |
|
What are the types of Guardrails?
There are broadly two types of guardrails, input guardrails and output guardrails.
Input guardrails act as the first line of defense for any LLM. They check and validate everything before it reaches the model, things like filtering out sensitive information, blocking malicious or off-topic queries, and ensuring the input stays within the app’s purpose.
Output guardrails, on the other hand, kick in after the model generates a response. They make sure the output is safe, relevant, and aligned with business or compliance rules, catching issues like hallucinations, policy violations, or unwanted mentions before the response reaches the user.
Together, these two layers keep LLM systems consistent, secure, and trustworthy in production.
Risks with LLMs
In this article, we’ll look at four key problems most LLM applications face:
- Model limitations: Can the model actually handle the question? Does it hallucinate or go off track?
Note: Hallucination is a relative term. Generally, it refers to AI outputs that appear authentic but are factually incorrect. In our case, we define hallucination as any response that isn’t grounded in or derived from our intended data or context. - Unintended use: Users can easily break instructions or push the system beyond its purpose. For example, a learning chatbot can be misused for unrelated conversations if not properly restricted.
- Information leakage: Sensitive data (PII – Personal identifiable information) like names or phone numbers must stay within the organization. We need filters to prevent such details from being sent to third-party LLM providers.
- Reputational risk: A chatbot mentioning competitors or violating company policies can harm the brand. Guardrails should be in place to prevent that, and reinforced if they fail.
How do we handle Hallucinations?
In our case, any response that isn’t grounded in our own knowledge base is considered a hallucination. We want the LLM to generate answers strictly based on our internal data, not guess or fill in gaps. In short, hallucination = lack of groundedness.
Natural Language Inference (NLI)
NLI helps us check how faithful the model’s response is to the actual context. It works with two components — Premise and Hypothesis. The premise is what we know to be true (the retrieved chunks from our vector DB), and the hypothesis is the model’s response.
Natural Language Inference then evaluates how well the hypothesis aligns with the premise, basically checking if the LLM’s answer stays grounded in the data it was supposed to rely on.
Hands-on creating Guardrail using NLI
You can check out the entire code from – https://github.com/Badribn0612/Guardrails/blob/main/Lesson_5.ipynb
We will be using guardrails-ai to create guardrail. Checkout https://www.guardrailsai.com/docs/getting_started/quickstart
https://www.guardrailsai.com/docs/getting_started/guardrails_server
To set up the environment.
We will be using a finetuned model – GuardrailsAI/finetuned_nli_provenance – https://huggingface.co/GuardrailsAI/finetuned_nli_provenance
Below is the code which will be used as our Guardrail – in guardrail-ai, they call it a validator.
@register_validator(name="hallucination_detector", data_type="string")
class HallucinationValidation(Validator):
def __init__(
self,
embedding_model: Optional[str] = None,
entailment_model: Optional[str] = None,
sources: Optional[List[str]] = None,
**kwargs
):
if embedding_model is None:
embedding_model = 'all-MiniLM-L6-v2'
self.embedding_model = SentenceTransformer(embedding_model)
self.sources = sources
if entailment_model is None:
entailment_model = 'GuardrailsAI/finetuned_nli_provenance'
self.nli_pipeline = pipeline("text-classification", model=entailment_model)
super().__init__(**kwargs)
def validate(
self, value: str, metadata: Optional[Dict[str, str]] = None
) -> ValidationResult:
# Split the text into sentences
sentences = self.split_sentences(value)
# Find the relevant sources for each sentence
relevant_sources = self.find_relevant_sources(sentences, self.sources)
entailed_sentences = []
hallucinated_sentences = []
for sentence in sentences:
# Check if the sentence is entailed by the sources
is_entailed = self.check_entailment(sentence, relevant_sources)
if not is_entailed:
hallucinated_sentences.append(sentence)
else:
entailed_sentences.append(sentence)
if len(hallucinated_sentences) > 0:
return FailResult(
error_message=f"The following sentences are hallucinated: {hallucinated_sentences}",
)
return PassResult()
def split_sentences(self, text: str) -> List[str]:
if nltk is None:
raise ImportError(
"This validator requires the `nltk` package. "
"Install it with `pip install nltk`, and try again."
)
return nltk.sent_tokenize(text)
def find_relevant_sources(self, sentences: str, sources: List[str]) -> List[str]:
source_embeds = self.embedding_model.encode(sources)
sentence_embeds = self.embedding_model.encode(sentences)
relevant_sources = []
for sentence_idx in range(len(sentences)):
# Find the cosine similarity between the sentence and the sources
sentence_embed = sentence_embeds[sentence_idx, :].reshape(1, -1)
cos_similarities = np.sum(np.multiply(source_embeds, sentence_embed), axis=1)
# Find the top 5 sources that are most relevant to the sentence that have a cosine similarity greater than 0.8
top_sources = np.argsort(cos_similarities)[::-1][:5]
top_sources = [i for i in top_sources if cos_similarities[i] > 0.8]
# Return the sources that are most relevant to the sentence
relevant_sources.extend([sources[i] for i in top_sources])
return relevant_sources
def check_entailment(self, sentence: str, sources: List[str]) -> bool:
for source in sources:
output = self.nli_pipeline({'text': source, 'text_pair': sentence})
if output['label'] == 'entailment':
return True
return FalseInside the class, we initialize two key models:
- An embedding model (all-MiniLM-L6-v2) to measure similarity between the LLM’s response and the source documents.
- An entailment model (GuardrailsAI/finetuned_nli_provenance) that performs Natural Language Inference (NLI) to check if the response is actually supported by the retrieved content.
Validation flow
- Split the output:
The LLM response (value) is split into sentences. - Find relevant sources:
For each sentence, we find the most similar chunks from our provided sources (like docs or vector DB results) using embeddings and cosine similarity. - Check entailment:
For each sentence, we run NLI — checking if the sentence is “entailed” (supported) by the relevant sources. - Classify results:
If a sentence is supported → it’s entailed.
If not → it’s flagged as hallucinated.
If any hallucinated sentences are found, the validator fails and returns the list of problematic lines. Otherwise, it passes successfully.
In short, this validator acts as a truth filter. It ensures the LLM’s response is grounded in the actual source data and doesn’t make things up.
guard = Guard().use(
HallucinationValidation(
embedding_model='all-MiniLM-L6-v2',
entailment_model='GuardrailsAI/finetuned_nli_provenance',
sources=['The sun rises in the east and sets in the west.', 'The sun is hot.'],
on_fail=OnFailAction.EXCEPTION
)
)Now we create a guard, this is like a wrapper around the validators(guardrails), which will execute multiple validators in parallel if they exist.
guard.validate(
'The sun rises in the east.',
)
print("Input Sentence: 'The sun rises in the east.'")
print("Validation passed successfully!\n\n")
We can see that the hypothesis is valid, based on the retrieved premise. You can play with the threshold to find the right point for validation. Below is an example where the validation fails.
try:
guard.validate(
'The sun is a star.',
)
except Exception as e:
print("Input Sentence: 'The sun is a star.'")
print("Validation failed!")
print("Error Message: ", e)
The reason why this failed is not because the sentence is incorrect but the sentence is not from our sources.
How to make sure our chatbot stays on topic?
We want our chatbot to stick to its purpose, not drift into random conversations. For example, a recruiting chatbot should only talk about hiring, applications, or job-related queries. An educational chatbot should focus on helping users learn, not chat about movies or play trivia.
The idea is simple: keep the chatbot aligned with its core intent. If it’s built for data science learning, it shouldn’t suddenly start discussing Game of Thrones.
To do this, we can add domain guardrails that filter inputs and outputs based on the topic. Input guardrails catch off-topic queries before they reach the model, and output guardrails make sure the model’s responses stay relevant and focused.
This helps maintain consistency, prevents misuse, and keeps the user experience aligned with what the chatbot is actually meant to do.
Hands On – Guardrail for Topic Classification
You can check out the entire implementation here: https://github.com/Badribn0612/Guardrails/blob/main/Lesson_6.ipynb
So, in order to filter incoming queries to the agent or chatbot, we will be using a topic classifier. Here, Guardrails AI is using a zero-shot classification model, Facebook/bart-large-mnli, and prompts it with the topics that you want your LLMs to stay within.
Check out the Hugging Face page for the same – https://huggingface.co/facebook/bart-large-mnli
Below is a sample code to impose this guardrail.
from transformers import pipeline
CLASSIFIER = pipeline(
"zero-shot-classification",
model='facebook/bart-large-mnli',
hypothesis_template="This sentence above contains discussions of the folllowing topics: {}.",
multi_label=True,
)
CLASSIFIER(
"Chick-Fil-A is closed on Sundays.",
["food", "business", "politics"]
)While this approach can be useful for general domain restrictions, it will be difficult to use zeroshot classification for niche topics, so in those cases we would have to use an LLM to classify the topics, one down of this approach is that LLM based guardrails are prone to Prompt Injection, hence using a simple classifier for prompt injection and LLM based guardrails for topic classification in parallel would be the best way to do it.
class Topics(BaseModel):
detected_topics: list[str]
t = time.time()
for i in range(10):
completion = unguarded_client.beta.chat.completions.parse(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "Given the sentence below, generate which set of topics out of ['food', 'business', 'politics'] is present in the sentence."},
{"role": "user", "content": "Chick-Fil-A is closed on Sundays."},
],
response_format=Topics,
)
topics_detected = ', '.join(completion.choices[0].message.parsed.detected_topics)
print(f'Iteration {i}, Topics detected: {topics_detected}')
print(f'\nTotal time: {time.time() - t}')Above is the implementation of LLM LLM-based topic classifier. This is how we can make our AI systems stay within the topics. Now let’s jump into the next use case.
How to avoid PII (Personal Identifiable Information) leakage
So, what is PII? Personal Identifiable Information includes identifiers and data as mentioned below.
| Data Type | Examples |
|---|---|
| Direct Identifiers |
|
| Indirect Identifiers |
|
| Sensitive Data |
|
LLM Data Privacy Risks:
- Third-party processing exposure
- Potential data retention by providers
- Risk of training data contamination
- Limited control over data handling
When building LLM-powered apps, one of the biggest risks is accidentally exposing user data like names, emails, or financial info. To prevent that, we need to have PII filtering at two key stages:
- Before sending data to the LLM provider: Any sensitive or personal information in the user query should be masked or removed before it’s passed to the model. This ensures we’re not leaking private data to third-party APIs.
- Before showing the response to the user: Even the model’s output can sometimes echo or regenerate sensitive information. We need a post-processing layer to scan and filter such data before displaying it back to the user.
By combining input and output filtering, we make sure user data stays protected within our system, keeping privacy, compliance, and trust intact.
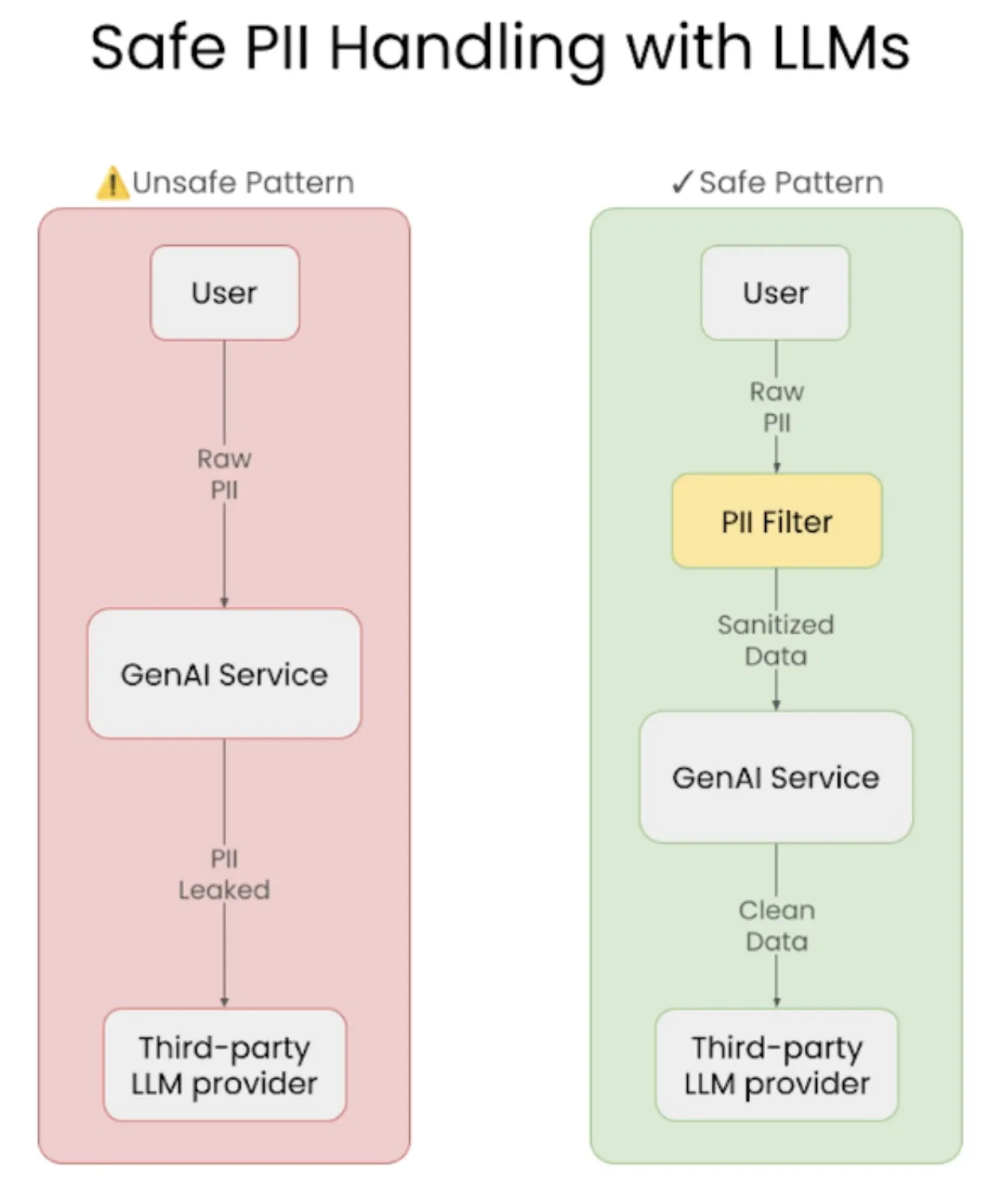
We’ll be using Presidio Analyzer, an open-source project from Microsoft, to detect and handle PII data.
If any PII exists within our vector database, we’ll also need to filter that out before sending the final response to the user, making sure no sensitive information slips through at any stage.
Hands On – Guardrails for PII filtering
Check out the entire implementation here: https://github.com/Badribn0612/Guardrails/blob/main/Lesson_7.ipynb
# Presidio imports
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
presidio_analyzer = AnalyzerEngine()
presidio_anonymizer= AnonymizerEngine()
# First, let's analyze the text
text = "can you tell me what orders i've placed in the last 3 months? my name is Hank Tate and my phone number is 555-123-4567"
analysis = presidio_analyzer.analyze(text, language='en')
print(presidio_anonymizer.anonymize(text=text, analyzer_results=analysis)) 
Implement a function to detect PII
def detect_pii(
text: str
) -> list[str]:
result = presidio_analyzer.analyze(
text,
language='en',
entities=["PERSON", "PHONE_NUMBER"]
)
return [entity.entity_type for entity in result] Create a Guardrail that filters out PII
@register_validator(name="pii_detector", data_type="string")
class PIIDetector(Validator):
def _validate(
self,
value: Any,
metadata: Dict[str, Any] = {}
) -> ValidationResult:
detected_pii = detect_pii(value)
if detected_pii:
return FailResult(
error_message=f"PII detected: {', '.join(detected_pii)}",
metadata={"detected_pii": detected_pii},
)
return PassResult(message="No PII detected") Create a Guard that ensures no PII is leaked
guard = Guard(name='pii_guard').use(
PIIDetector(
on_fail=OnFailAction.EXCEPTION
),
)
try:
guard.validate("can you tell me what orders i've placed in the last 3 months? my name is Hank Tate and my phone number is 555-123-4567")
except Exception as e:
print(e)This is how you can implement PII filtering to not expose confidential data to LLM providers. Now let’s move on to our final use case.
Preventing Competitor Mentions
This is an important guardrail to ensure our system never references competitor names, products, or resources. Even a casual mention can harm the company’s reputation or violate brand guidelines.
By setting up filters or prompt-level restrictions, we can make sure the chatbot stays neutral and focused on our own ecosystem, avoiding any content that could indirectly promote or compare against competitors.
For example, if you’ve built a chatbot for Bain & Company, it shouldn’t be talking about or promoting competitors like EY or PwC. Its responses should strictly reflect Bain’s services, expertise, and brand positioning, not draw comparisons or reference external firms.
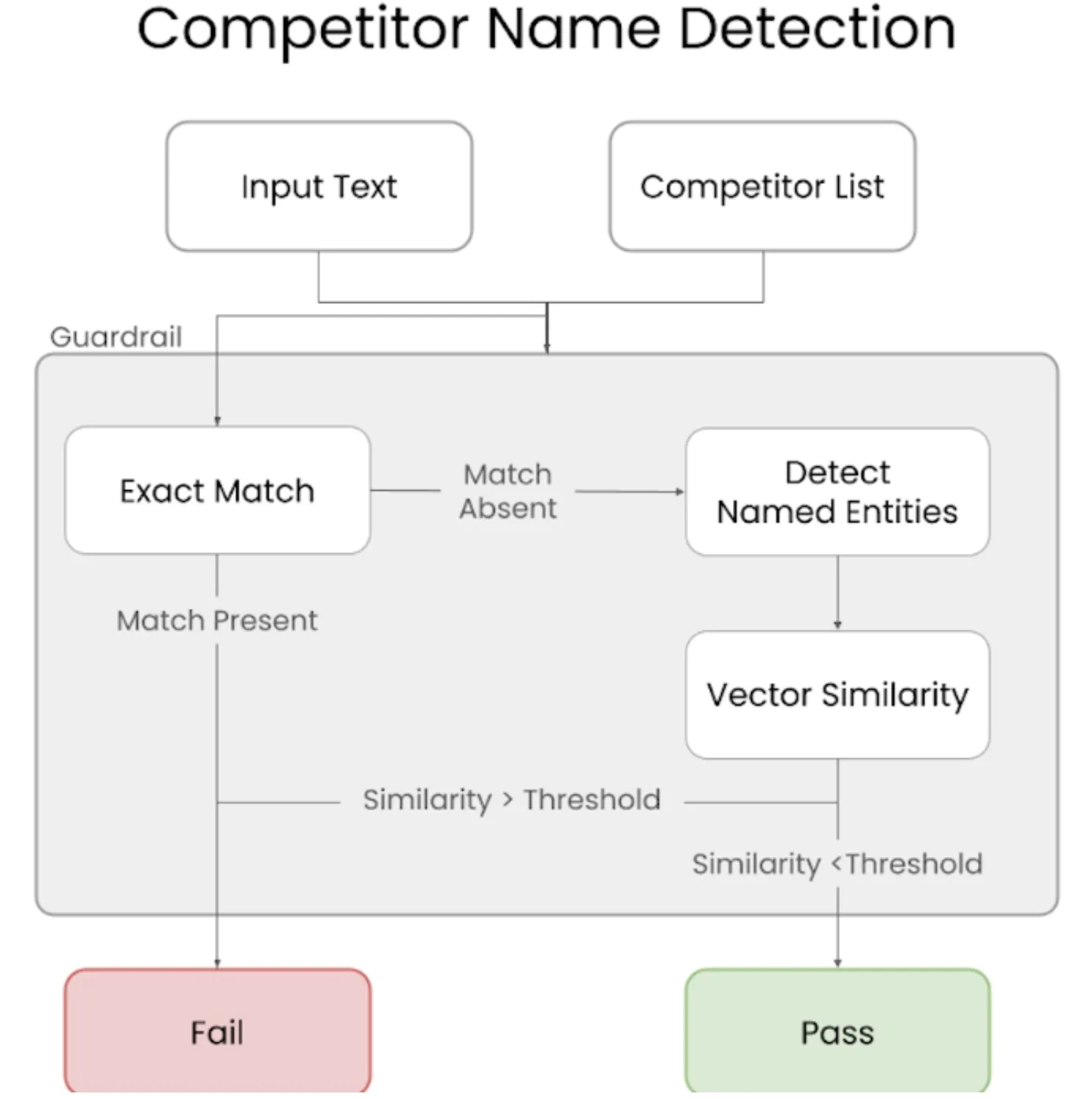
Above is an architecture that you can implement to avoid mentioning competitors.
Hands On – Guardrails for Competitor Name Filtering
Check out the entire implementation here: https://github.com/Badribn0612/Guardrails/blob/main/Lesson_8.ipynb
Competitor Check Validator
You’ll build a validator to check for competitors mentioned in the response from your LLM. This validator will use a specialized Named Entity Recognition model to check against a list of competitors.
from typing import Optional, List
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
import reSet up the NER model in Hugging Face to use in the validator:
# Initialize NER pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
NER = pipeline("ner", model=model, tokenizer=tokenizer)
Setting up the validator (Guardrail)
@register_validator(name="check_competitor_mentions", data_type="string")
class CheckCompetitorMentions(Validator):
def __init__(
self,
competitors: List[str],
**kwargs
):
self.competitors = competitors
self.competitors_lower = [comp.lower() for comp in competitors]
self.ner = NER
# Initialize sentence transformer for vector embeddings
self.sentence_model = SentenceTransformer('all-MiniLM-L6-v2')
# Pre-compute competitor embeddings
self.competitor_embeddings = self.sentence_model.encode(self.competitors)
# Set the similarity threshold
self.similarity_threshold = 0.6
super().__init__(**kwargs)
def exact_match(self, text: str) -> List[str]:
text_lower = text.lower()
matches = []
for comp, comp_lower in zip(self.competitors, self.competitors_lower):
if comp_lower in text_lower:
# Use regex to find whole word matches
if re.search(r'\b' + re.escape(comp_lower) + r'\b', text_lower):
matches.append(comp)
return matches
def extract_entities(self, text: str) -> List[str]:
ner_results = self.ner(text)
entities = []
current_entity = ""
for item in ner_results:
if item['entity'].startswith('B-'):
if current_entity:
entities.append(current_entity.strip())
current_entity = item['word']
elif item['entity'].startswith('I-'):
current_entity += " " + item['word']
if current_entity:
entities.append(current_entity.strip())
return entities
def vector_similarity_match(self, entities: List[str]) -> List[str]:
if not entities:
return []
entity_embeddings = self.sentence_model.encode(entities)
similarities = cosine_similarity(entity_embeddings, self.competitor_embeddings)
matches = []
for i, entity in enumerate(entities):
max_similarity = np.max(similarities[i])
if max_similarity >= self.similarity_threshold:
most_similar_competitor = self.competitors[np.argmax(similarities[i])]
matches.append(most_similar_competitor)
return matches
def validate(
self,
value: str,
metadata: Optional[dict[str, str]] = None
):
# Step 1: Perform exact matching on the entire text
exact_matches = self.exact_match(value)
if exact_matches:
return FailResult(
error_message=f"Your response directly mentions competitors: {', '.join(exact_matches)}"
)
# Step 2: Extract named entities
entities = self.extract_entities(value)
# Step 3: Perform vector similarity matching
similarity_matches = self.vector_similarity_match(entities)
# Step 4: Combine matches and check if any were found
all_matches = list(set(exact_matches + similarity_matches))
if all_matches:
return FailResult(
error_message=f"Your response mentions competitors: {', '.join(all_matches)}"
)
return PassResult()This validator basically helps me make sure my chatbot never mentions or promotes competitors, directly or indirectly.
Here’s how it works in simple terms
- I pass in a list of competitor names when initializing the validator. The code then stores those names (in both normal and lowercase) and prepares embeddings for them using a SentenceTransformer model.
- It uses two checks — one for exact mentions and another for semantic similarity, so even if the model tries to rephrase a competitor’s name slightly, we can still catch it.
What actually happens
- Exact match: It first looks through the chatbot’s response to see if any competitor names are directly mentioned.
- Entity extraction: Then it runs NER to find any organization names in the response — this helps detect brand mentions even if the chatbot doesn’t use the exact name.
- Vector similarity check: For each extracted entity, it checks how semantically close it is to any competitor using embeddings. If the similarity is above the set threshold (0.6), that entity is flagged as a competitor.
- Final check: If any competitor names show up (either exactly or semantically), the validation fails with an error message listing them. Otherwise, it passes.
So, in short, this validator is my way of ensuring that the chatbot stays completely aligned with our brand voice and doesn’t slip up by mentioning or promoting competitors like EY or PwC in a Bain chatbot scenario.
Additional things to explore
You can also check out the Guardrails Hub – it’s a great place to explore open-source and community-built guardrails, and even create your own: https://hub.guardrailsai.com/
Most guardrails are designed for specific use cases, but when it comes to more complex scenarios, we often need to use LLMs as guardrails themselves. While this approach can introduce prompt injection risks, we can mitigate that by adding an ML classifier layer on top for extra safety.
You can also explore NVIDIA NeMo Guardrails, another powerful framework for building safe and controlled AI apps:
Conclusion
Building production-ready LLM applications needs more than just flashy demos; it needs strong, systematic safeguards. Guardrails play a key role in tackling four major challenges faced by any LLM: detecting hallucinations with NLI validation, keeping conversations on-topic through classifiers, protecting PII using tools like Presidio Analyzer, and ensuring brand safety with NER and semantic checks.
The best systems combine multiple layers, simple rule-based filters, small ML models, and LLM-based validators to build reliable defenses. But this goes beyond just one app. Unchecked AI content adds to the growing “AI slop” online, where hallucinated data feeds back into future models.
Organizations should treat validation pipelines not only as a compliance need but as a responsibility to maintain content quality and trust. Use frameworks like Guardrails AI and NVIDIA NeMo Guardrails, test continuously, and remember, guardrails aren’t limits. They’re what turn LLM experiments into stable, enterprise-grade systems that deliver real value safely.
Data science Trainee at Analytics Vidhya, specializing in ML, DL and Gen AI. Dedicated to sharing insights through articles on these subjects. Eager to learn and contribute to the field's advancements. Passionate about leveraging data to solve complex problems and drive innovation.






