Google has recently released their most intelligent model that can create, reason, and understand across multiple modalities. Google Gemini 3 Pro is not just an incremental update, it is in fact a major step forward in AI capability. This model with the cutting-edge reasoning, multimodal understanding, and agentic capabilities is going to be the main factor to change the way developers create intelligent applications. And with the new Gemini 3 Pro API, developers can now create smarter, more dynamic systems than ever before.
If you are making complex AI workflows, working with multimodal data, or developing agentic systems that can manage multi-step tasks on their own, this guide will teach you all about utilizing Gemini 3 Pro via its API.
Table of contents
What Makes Gemini 3 Pro Special?
Let us not get lost in the technical details and first discuss the reasons behind the buzz among the developers about this model. The Google Gemini 3 Pro model that has been in development for a while has now reached the very top of the AI benchmarking list with a fantastic Elo rating of 1501, and it was not merely designed to deliver maximum performance but the whole package was oriented towards a great experience for the developer.
The main features are:
- Advanced reasoning: The model is now capable of solving intricate, multi-step problems with very subtle thinking.
- Massive context window: A massive 1 million token input context allows for the feeding of whole codebases, full-length books or long video content.
- Multimodal mastery: Text, images, video, PDFs and code can all be processed together in a very smooth way.
- Agentic workflows: Run multi-step tasks where the model orchestrates, checks and modifies its action of being a robot.
- Dynamic thinking: Depending on the situation, the model will either go through the problem step by step or just give the answer.
You can learn more about Gemini 3 Pro model and its features in the following article: Gemini 3 Pro
Getting Started: Your First Gemini 3 Pro API Call
Step 1: Get Your API Key
Go to Google AI Studio and log in using your Google account. Now, click the profile icon at the top right corner, and then choose “Get API key” option. If it is your first time, select “Create API key in new project” otherwise import an existing one. Make a copy of the API key right away because you will not be able to see it again.
Step 2: Install the SDK
Choose your preferred language and install the official SDK using following commands:
Python:
pip install google-genaiNode.js/JavaScript:
npm install @google/genaiStep 3: Set Your Environment Variable
Store your API key securely in an environment variable:
export GEMINI_API_KEY="your-api-key-here"Gemini 3 Pro API Pricing
The Gemini 3 Pro API utilizes a pay-as-you-go model, where your costs are primarily calculated based on the number of tokens consumed for both your input (prompts) and the model’s output (responses).
The key determinant for the pricing tier is the context window length of your request. Longer context windows, which allow the model to process more information simultaneously (like large documents or long conversation histories), incur a higher rate.
The following rates apply to the gemini-3-pro-preview model via the Gemini API and are measured per one million tokens (1M).
| Feature | Free Tier | Paid Tier (per 1M tokens in USD) |
|---|---|---|
| Input price | Free (limited daily usage) |
$2.00, prompts ≤ 200k tokens $4.00, prompts > 200k tokens |
| Output price (including thinking tokens) | Free (limited daily usage) |
$12.00, prompts ≤ 200k tokens $18.00, prompts > 200k tokens |
| Context caching price | Not available |
$0.20–$0.40 per 1M tokens (depends on prompt size) $4.50 per 1M tokens per hour (storage price) |
| Grounding with Google Search | Not available |
1,500 RPD (free) Coming soon: $14 per 1,000 search queries |
| Grounding with Google Maps | Not available | Not available |
Understanding Gemini 3 Pro’s New Parameters
The API presents several revolutionary parameters one of which is the thinking level parameter, giving full control over to the requester in a very detailed manner.
The Thinking Level Parameter
This new parameter is very likely the most significant one. You are no longer left to wonder how much the model should “think” but rather it is explicitly controlled by you:
- thinking_level: “low”: For basic tasks such as classification, Q&A, or chatting. There will be very little latency, and the costs will be lower which makes it perfect for high-throughput applications.
- thinking_level: “high” (default): For complex reasoning tasks. The model takes longer but the output will consist of a more carefully reasoned argument. This is the time for problem-solving and analysis.
Tip: Do not use thinking_level in conjunction with the older thinking_budget parameter, as they are not compatible and will result in a 400 error.
Media Resolution Control
While analysing images, PDF documents, or videos, now you can regulate the virtual processor usage when analysing visual input:
- Images:
media_resolution_highfor the best quality (1120 tokens/image). - PDFs:
media_resolution_mediumfor document understanding (560 tokens). - Videos:
media_resolution_lowfor action recognition (70 tokens/frame) andmedia_resolution_highfor conversation-heavy text (280 tokens/frame).
This puts the optimization of quality and token usage in your hands.
Temperature Settings
Here is something that you may find intriguing: you can simply keep the temperature at its defaults of 1.0. Unlike earlier models that would often make productive use of temperature tuning, Gemini 3’s reasoning is optimized around this default setting. Lowering the temperature can cause strange loops or degrade performance on more complex tasks.
Build With Me: Hands-On Examples of Gemini 3 Pro API
Demo 1: Building a Smart Code Analyzer
Let’s build something using a real-world use case. We’ll create a system that first analyses code, identifies discrepancies, and suggests improvements using Gemini 3 Pro’s advanced reasoning feature.
Python Implementation
import os
from google import genai
# Initialize the Gemini API client with your API key
# You can set this directly or via environment variable
api_key = "api-key" # Replace with your actual API key
client = genai.Client(api_key=api_key)
def analyze_code(code_snippet: str) -> str:
"""
Analyzes code for discrepancies and suggests improvements using Gemini 3 Pro.
Args:
code_snippet: The code to analyze
Returns:
Analysis and improvement suggestions from the model
"""
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents=[
{
"text": f"""Analyze this code for issues, inefficiencies, and potential improvements.
Provide:
1. Issues found (bugs, logic errors, security concerns)
2. Performance optimizations
3. Code quality improvements
4. Best practices violations
5. Refactored version with explanations
Code to analyze:
{code_snippet}
Be direct and concise in your analysis."""
}
]
)
return response.text
# Example usage
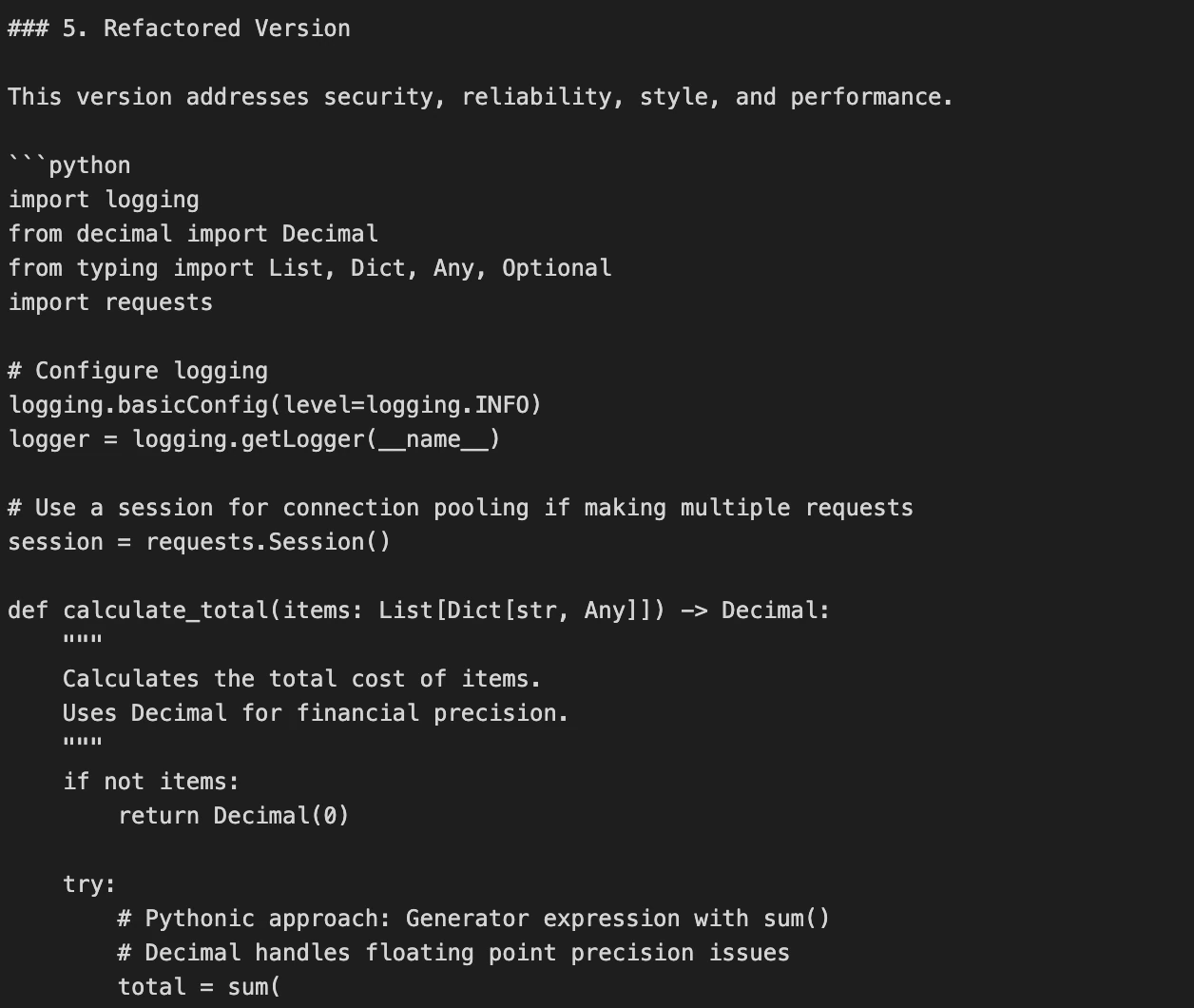
sample_code = """
def calculate_total(items):
total = 0
for i in range(len(items)):
total = total + items[i]['price'] * items[i]['quantity']
return total
def get_user_data(user_id):
import requests
response = requests.get(f"http://api.example.com/user/{user_id}")
data = response.json()
return data
"""
print("=" * 60)
print("GEMINI 3 PRO - SMART CODE ANALYZER")
print("=" * 60)
print("\nAnalyzing code...\n")
# Run the analysis
analysis = analyze_code(sample_code)
print(analysis)
print("\n" + "=" * 60)Output:
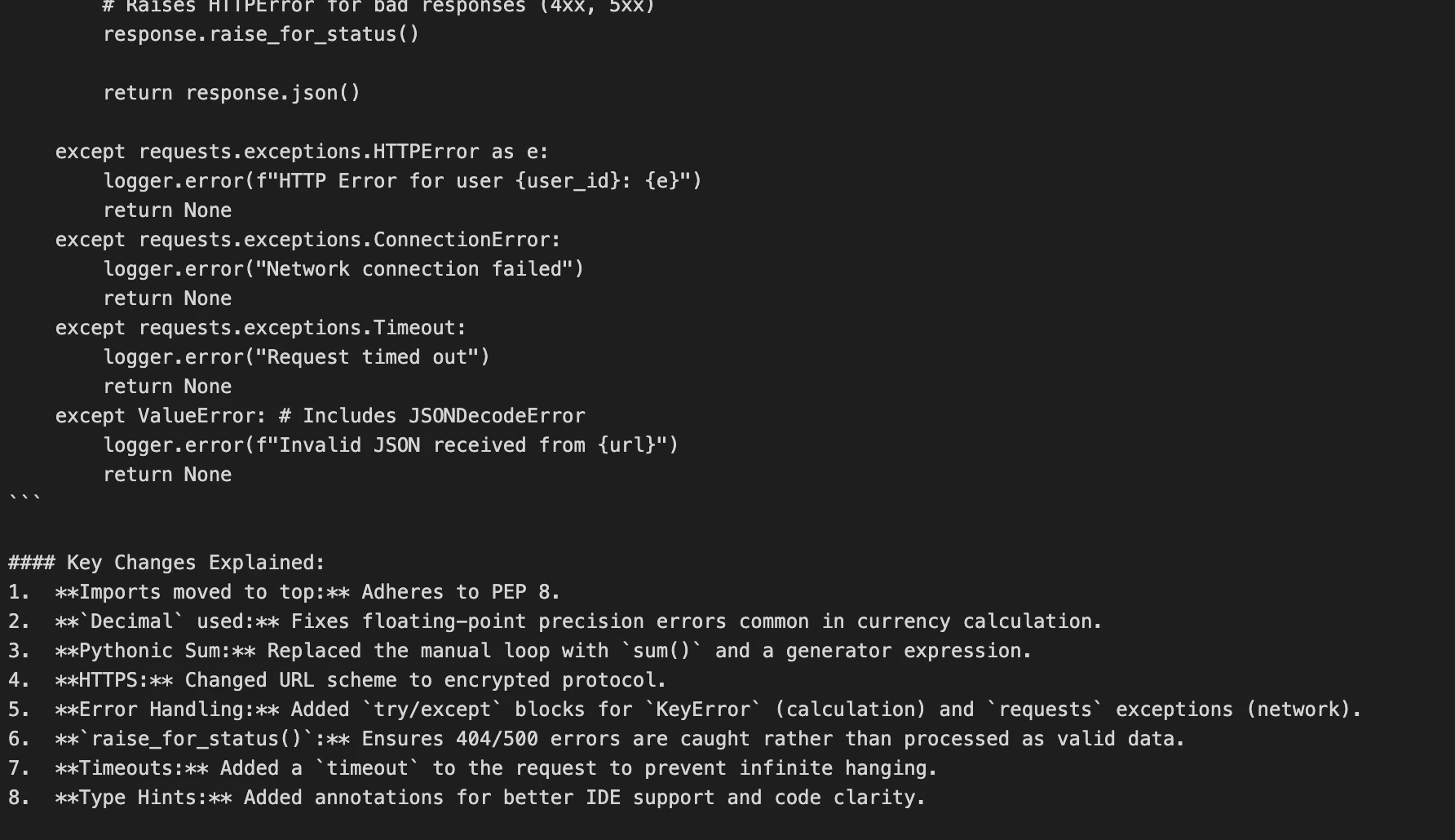
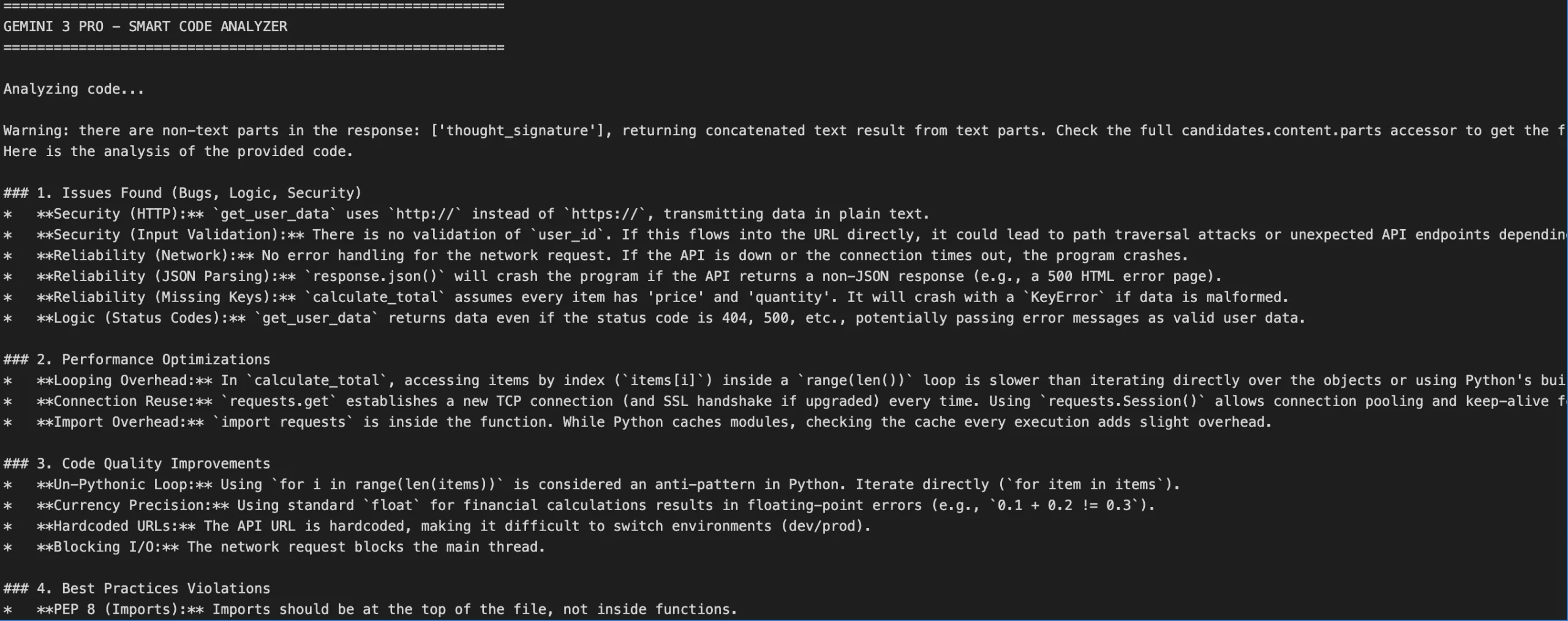
What’s Happening Here?
- We’re implementing
thinking_level ("high")since code review entails some heavy reasoning. - The prompt is brief and to the point Gemini 3 responds more effectively when prompts are direct, as opposed to elaborately using prompt engineering.
- The model reviews the code with full reasoning capacity and will provide a responsive version which includes significant revisions and insightful analysis.
Demo 2: Multi-Modal Document Intelligence
Now let’s take on a more complex use case that is analyzing an image of a document and extracting structured information.
Python Implementation
import base64
import json
from google import genai
# Initialize the Gemini API client
api_key = "api-key-here" # Replace with your actual API key
client = genai.Client(api_key=api_key)
def analyze_document_image(image_path: str) -> dict:
"""
Analyzes a document image and extracts key information.
Handles images, PDFs, and other document formats.
Args:
image_path: Path to the document image file
Returns:
Dictionary containing extracted document information as JSON
"""
# Read and encode the image
with open(image_path, "rb") as img_file:
image_data = base64.standard_b64encode(img_file.read()).decode()
# Determine the MIME type based on file extension
mime_type = "image/jpeg" # Default
if image_path.endswith(".png"):
mime_type = "image/png"
elif image_path.endswith(".pdf"):
mime_type = "application/pdf"
elif image_path.endswith(".gif"):
mime_type = "image/gif"
elif image_path.endswith(".webp"):
mime_type = "image/webp"
# Call the Gemini API with multimodal content
response = client.models.generate_content(
model="gemini-3-pro-preview",
contents=[
{
"text": """Extract and structure all information from this document image.
Return the data as JSON with these fields:
- document_type: What type of document is this?
- key_entities: List of important names, dates, amounts, etc.
- main_content: Brief summary of the document's purpose
- action_items: Any tasks or deadlines mentioned
- confidence: How confident you are in the extraction (high/medium/low)
Return ONLY valid JSON, no markdown formatting."""
},
{
"inline_data": {
"mime_type": mime_type,
"data": image_data
}
}
]
)
# Parse the JSON response
try:
result = json.loads(response.text)
return result
except json.JSONDecodeError:
return {
"error": "Failed to parse response",
"raw": response.text
}
# Example usage with a sample document
print("=" * 70)
print("GEMINI 3 PRO - MULTI-MODAL DOCUMENT INTELLIGENCE")
print("=" * 70)
document_path = "Gemini-3-Pro-Model-Card.pdf" # Change this to your actual document path
try:
print(f"\nAnalyzing document: {document_path}")
print("Processing...\n")
document_info = analyze_document_image(document_path)
print("Extracted Document Information:")
print("-" * 70)
print(json.dumps(document_info, indent=2))
except FileNotFoundError:
print(f"Error: Document file '{document_path}' not found.")
print("Please provide a valid path to a document image (JPG, PNG, PDF, etc.)")
print("\nExample:")
print(' document_info = analyze_document_image("invoice.pdf")')
print(' document_info = analyze_document_image("contract.png")')
print(' document_info = analyze_document_image("receipt.jpg")')
except Exception as e:
print(f"Error processing document: {str(e)}")
print("\n" + "=" * 70)Output:
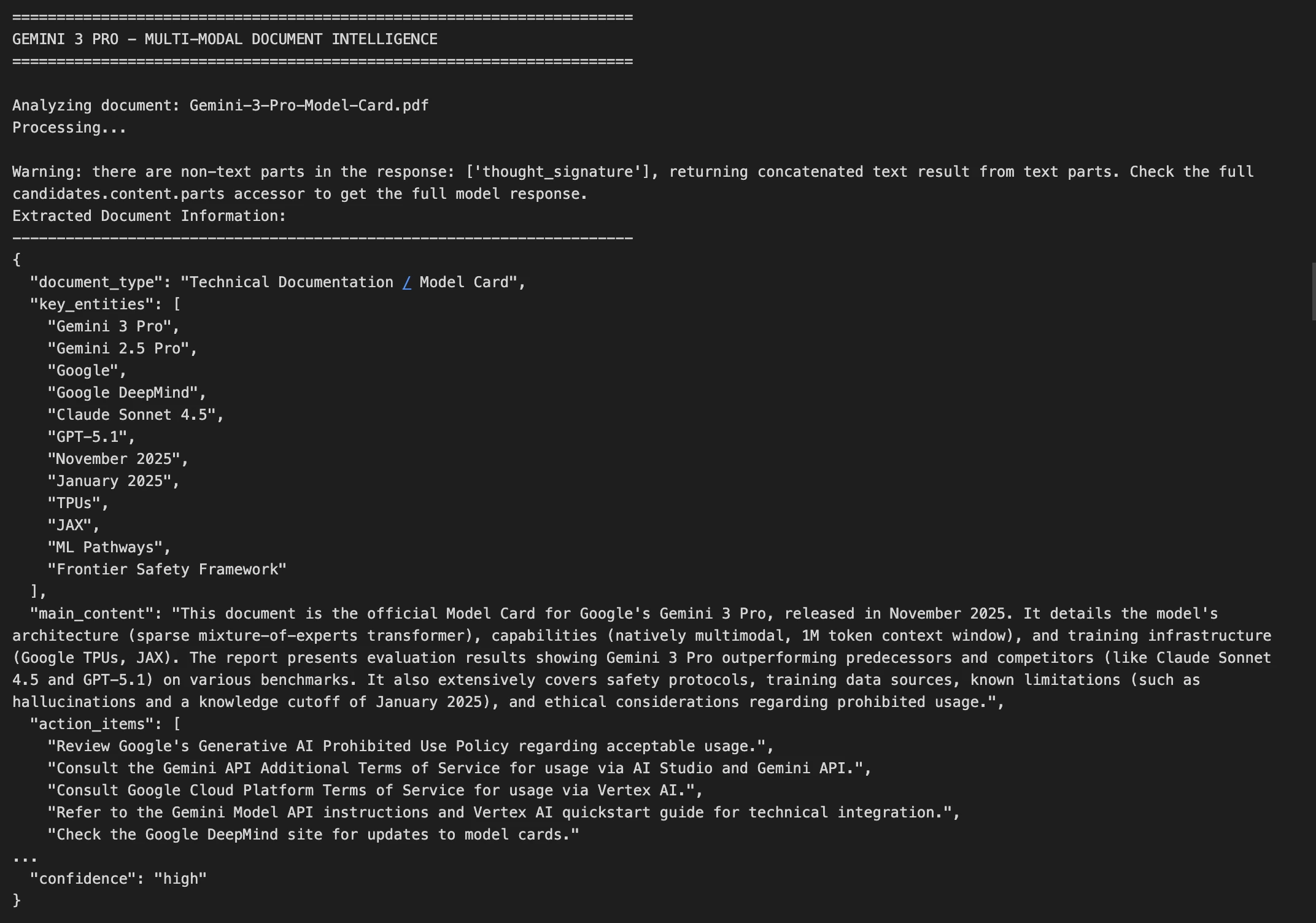
Key Techniques Here:
- Image processing: We are encoding the picture in base64 format for delivery
- Maximum quality option: For text documents we apply
media_resolution_highto provide perfect OCR - Ordered result: We ask for a JSON format which is easy to connect with other systems
- Fault handling: We do it the way that JSON parsing errors are not noticeable
Advanced Features: Beyond Basic Prompting
Thought Signatures: Maintaining Reasoning Context
Gemini 3 pro introduces an amazing feature known as thought signatures, which has encrypted representations of the internal reasoning that model does. These model signatures hold context across the API calls when using function calling or multi-turn conversations.
If your preference is to use the official Python or Node.js SDKs method then this thought signatures is being handled automatically and invisibly but if you’re making raw API call then you need to return the though Signature exactly as it’s received.
Context Caching for Cost Optimization
Do you plan on sending similar requests multiple times? Take advantage of context caching which can cache the first 2,048 tokens of your prompt, and save money on subsequent requests. This is fantastic anytime you are processing a bunch of documents and can reuse a system prompt in between.
Batch API: Process at Scale
For workloads that are not time-sensitive, the Batch API can save you up to 90%. This is ideal for workloads where there are lots of documents to process or if you are going to run a large analysis overnight.
Conclusion
Google Gemini 3 Pro marks a inflection point in what’s possible with AI APIs. The combination of advanced reasoning, massive context windows, and affordable pricing means you can now build systems that were previously impractical.
Start small: Build a chatbot, analyze some documents, or automate a routine task. Then, as you get comfortable with the API, explore more complex scenarios like autonomous agents, code generation, and multimodal analysis.
Frequently Asked Questions
Q1. What makes Google Gemini 3 Pro a major upgrade for developers?
A. Its advanced reasoning, multimodal support, and huge context window enable smarter and more capable applications.
Q2. How do I control the model’s depth of reasoning?
A. Set thinking_level to low for fast/simple tasks or high for complex analysis.
Q3. How can I reduce API costs when processing many similar requests?
A. Use context caching or the Batch API to reuse prompts and run workloads efficiently.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]






