ESG reporting or Environmental, Social, and Governance reporting, often feels overwhelming because the data comes from so many places and takes ages to pull together. Teams spend most of their time collecting numbers instead of interpreting what they mean. Agentic AI changes that dynamic. Instead of one chatbot answering questions, you get a coordinated group of AI helpers that work like a dedicated reporting team. They gather information, check it against relevant rules, and prepare clear draft summaries so humans can focus on insight rather than paperwork.
In this guide, we are going to present, step by step, a practical, developer-centric pipeline for ESG reporting covering:
- Data aggregation: Employ concurrent agents to obtain data from APIs and documents and then index it using vector search (e.g., OpenAI embeddings + FAISS).
- Compliance checks: Execute regulatory rules (like CSRD or EU Taxonomy) through code logic or SQL queries to highlight any problems.
- Smart Report: Direct the creation of a narrative report by using Retrieval-Augmented Generation (RAG) and LLM chains and deliver it as a PDF.
Table of contents
Step 1: Aggregating ESG Data with AI Agents
Initially, it is necessary to collect all pertinent data by parallel means. To illustrate, one agent can obtain the most recent ESG research through arXiv API, another can look for recent regulatory updates via a news API, and a third can classify the company’s internal ESG documents.
In one experiment, three specific “search agents” operated simultaneously to make inquiries to arXiv, an internal Azure AI Search index, and news sources. After that, each agent provided the central knowledge base with its data. We can emulate this process in Python by employing threads along with a vector store for document search:
import requests
import concurrent.futures
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# ESG Data Aggregation and RAG Pipeline Example
# 1. External Search Functions
# Example: search arXiv for ESG-related papers
def search_arxiv(query, max_results=3):
"""Searches the arXiv API for papers."""
url = (
f"http://export.arxiv.org/api/query?"
f"search_query=all:{query}&max_results={max_results}"
)
res = requests.get(url)
# (Parse the XML response; here we just return raw text for brevity)
return res.text[:200] # show first 200 chars of result
# Example: search news using a hypothetical API (replace with a real news API)
def search_news(query, api_key):
"""Searches a hypothetical news API (needs replacement with a real one)."""
# NOTE: This is a placeholder URL and will not work without a real news API
url = f"https://newsapi.example.com/search?q={query}&apiKey={api_key}"
try:
# Simulate a request; this will likely fail with a 404/SSL error
res = requests.get(url, timeout=5)
articles = res.json().get("articles", [])
return [article["title"] for article in articles[:3]]
except requests.exceptions.RequestException as e:
return [f"Error fetching news (API Placeholder): {e}"]
# 2. Internal Document Indexing Function (for RAG)
def build_vector_index(pdf_paths):
"""Loads, splits, and embeds PDF documents into a FAISS vector store."""
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
all_docs = []
# NOTE: PyPDFLoader requires the files 'annual_report.pdf' and 'energy_audit.pdf' to exist
for path in pdf_paths:
try:
loader = PyPDFLoader(path)
pages = loader.load()
docs = splitter.split_documents(pages)
all_docs.extend(docs)
except Exception as e:
print(f"Warning: Could not load PDF {path}. Skipping. Error: {e}")
if not all_docs:
# Return a simple object or raise an error if no documents were loaded
print("Error: No documents were successfully loaded to build the index.")
return None
embeddings = OpenAIEmbeddings()
vector_index = FAISS.from_documents(all_docs, embeddings)
return vector_index
# --- Main Execution ---
# Paths to internal ESG PDFs (must exist in the same directory or have full path)
pdf_files = ["annual_report.pdf", "energy_audit.pdf"]
# Run external searches and document indexing in parallel
print("Starting parallel data fetching and index building...")
with concurrent.futures.ThreadPoolExecutor() as executor:
# External Searches
future_arxiv = executor.submit(search_arxiv, "net zero 2030")
# NOTE: Replace 'YOUR_NEWS_API_KEY' with a valid key for a real news API
future_news = executor.submit(
search_news,
"EU CSRD regulation",
"YOUR_NEWS_API_KEY"
)
# Build vector index (will print warnings if PDFs don't exist)
future_index = executor.submit(build_vector_index, pdf_files)
# Collect results
arxiv_data = future_arxiv.result()
news_data = future_news.result()
vector_index = future_index.result()
print("\n--- Aggregated Results ---")
print("ArXiv fetched data snippet:", arxiv_data)
print("Top news titles:", news_data)
if vector_index:
print("\nFAISS Vector Index successfully built.")
# Example continuation: Initialize the RAG chain
# llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# qa_chain = RetrievalQA.from_chain_type(
# llm=llm,
# retriever=vector_index.as_retriever()
# )
# print("RAG setup complete. Ready to query internal documents.")
else:
print("RAG setup skipped due to failed vector index creation.")Output:


Here, we used a thread pool to simultaneously call different sources. One thread fetches arXiv papers, another calls a news API, and another builds a vector store of internal documents. The vector index uses OpenAI embeddings stored in FAISS, enabling natural-language search over the documents.
Querying the Aggregated Data
With the data collected, agents can query it via natural language. For example, we can use LangChain’s RAG pipeline to ask questions against the indexed documents:
# Create a retriever from the FAISS index
retriever = vector_index.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# Initialize an LLM (e.g., GPT-4) and a RetrievalQA chain
llm = ChatOpenAI(temperature=0, model="gpt-4")
qa_chain = RetrievalQA(llm=llm, retriever=retriever)
# Ask a natural language question about ESG data
answer = qa_chain.run("What were the Scope 2 emissions for 2023?")
print("RAG answer:", answer)This RAG approach lets the agent retrieve relevant document segments (via similarity search) and then generate an answer. In one demonstration, an agent converted plain-English queries to SQL to fetch numeric data (e.g. “Scope 2 emissions in 2024”) from the emissions database. We can similarly embed a SQL query step if needed, for example using SQLite in Python:
import sqlite3
# Example: store some emissions data in SQLite
conn = sqlite3.connect(':memory:')
cursor = conn.cursor()
cursor.execute("CREATE TABLE emissions (year INTEGER, scope2 REAL)")
cursor.execute("INSERT INTO emissions VALUES (2023, 1725.4)")
conn.commit()
# Simple SQL query for numeric data
cursor.execute("SELECT scope2 FROM emissions WHERE year=2023")
scope2_emissions = cursor.fetchone()[0]
print("Scope 2 emissions 2023 (from DB):", scope2_emissions) In practice, you could integrate a LangChain SQL Agent to convert natural language to SQL automatically. Regardless of source, all these data points – from PDFs, APIs, and databases – feed into a unified knowledge base for the reporting pipeline.
Step 2: Automated Compliance Checks
The compliance assurance process is next in line after the raw metrics have been gathered. The mixture of code logic and LLM support can help in this regard. For instance, we can map the rules of the domain (such as the EU Taxonomy criteria) and then perform checks:
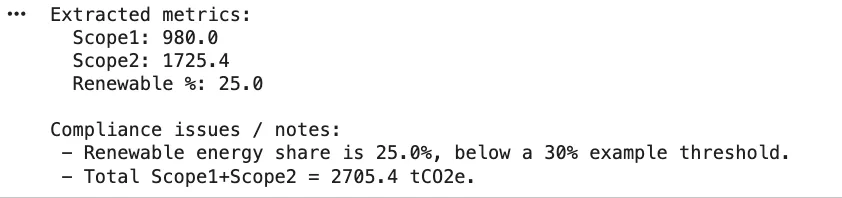
# Example ESG metrics extracted from data aggregation
metrics = {
"scope1_tCO2": 980,
"scope2_tCO2": 1725.4,
"renewable_percent": 25, # percent of energy from renewables
"water_usage_liters": 50000,
"reported_water_liters": 48000
}
# Simple rule-based compliance checks
def run_compliance_checks(metrics):
"""
Runs basic checks against predefined ESG compliance rules.
"""
issues = []
# Example rule 1: EU Taxonomy requires >= 30% renewable energy
if metrics["renewable_percent"] < 30:
issues.append("Renewables below EU taxonomy threshold (30%).")
# Example rule 2: Consistency check (tolerance of 1000 liters)
if abs(metrics["water_usage_liters"] - metrics["reported_water_liters"]) > 1000:
issues.append("Water usage mismatch between operations data and financial report.")
return issues
# Execute the checks
compliance_issues = run_compliance_checks(metrics)
print("Compliance issues found:", compliance_issues)This simple function identifies any rules that have been violated. In real life, you would perhaps get rules from a knowledge base or configuration. Compliance checks are frequently divided into roles in agent-based systems. The Criteria/Mapping agents link the data that has been extracted to the specific disclosure fields or the criteria of the taxonomy while the Calculation agents carry out the numeric checks or conversions. To cite an example, one of the agents could check if a particular activity conforms to the “Do No Significant Harm” criteria set by the Taxonomy or could derive total emissions by means of text-to-SQL queries.
Text-to-SQL Example (Optional)
LangChain provides SQL tools to automate this step. For instance, one can create a SQL Agent that examines your database schema and generates queries. Here’s a sketch using LangChain’s SQLDatabase :
from langchain.agents import create_sql_agent
from langchain.sql_database import SQLDatabase
# Set up a SQLite DB (same as above)
db = SQLDatabase.from_uri("sqlite:///:memory:", include_tables=["emissions"])
# Create an agent that can answer questions using the DB
sql_agent = create_sql_agent(llm=llm, db=db, verbose=False)
query_result = sql_agent.run("What is the total Scope 2 emissions for 2023?")
print("SQL Agent result:", query_result)This agent will introspect the emissions table and produce a query to calculate the answer, verifying it before returning a result. (In practice, ensure your database permissions are locked down, as executing model-generated SQL has risks.)
Step 3: Generative Smart Reporting with RAG Agents
After validation, the final stage is to compose the narrative report. Here a synthesis agent takes the cleaned data and writes human-readable disclosures. We can use LLM chains for this, often with RAG to include specific figures and citations. For example, we might prompt the model with the key metrics and let it draft a summary:
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Prepare a prompt template to generate an executive summary
prompt_template = """
Write a concise executive summary of the ESG report using the data below.
Include key figures and context:
{summary_data}
"""
template = PromptTemplate(
input_variables=["summary_data"],
template=prompt_template
)
# Example data to include in the summary
findings = f"""
- Scope 1 CO2 emissions: {metrics['scope1_tCO2']} tCO2e
- Scope 2 CO2 emissions: {metrics['scope2_tCO2']} tCO2e
- Renewable energy share: {metrics['renewable_percent']}%
"""
chain = LLMChain(llm=ChatOpenAI(temperature=0.2), prompt=template)
summary_text = chain.run({"summary_data": findings})
print("Generated summary:\n", summary_text)Output:
=== ANSWER ===
In the **Sustainability Annual Report 2024**, the reported emissions are as follows:
- **Scope 1 Emissions**: 980 tCO2e
- **Scope 2 Emissions**: 1,725.4 tCO2e
The total emissions amount to **2,705.4 tCO2e**.
A notable compliance gap is identified in the **Energy Audit Summary - 2024**, where the renewable energy share is reported at **28%**, which is below the regulatory target of **30%**. This indicates a need for improvement in renewable energy utilization to meet compliance standards.
Additionally, the report highlights a recommendation to add **500 kW** of rooftop solar to enhance renewable energy capacity.
Alternatively, you can build a chained RetrievalQA or agent that pulls from the indexed documents and data, then calls the LLM to write each section. For example, using LangChain’s RetrievalQA as above, you could ask the agent to “Summarize Scope 1 and 2 emissions and highlight any compliance gaps.” The key is that every answer can cite sources or methods, enabling an evidence trail .
Step 4: Compiling the Final Report
After drafting, it would be possible to combine and format the sections as it is done in a very simple way by using fpdf. PDF will be used to write the summary.
from fpdf import FPDF
pdf = FPDF()
pdf.add_page()
pdf.set_font("Arial", size=14)
pdf.multi_cell(0, 10, summary_text)
pdf.output("esg_report_summary.pdf")
print("PDF report generated.")Output:

In a complete pipeline, one could make many sections (like cultures, emissions, energy, water, etc.) and put them together. Agents could even assist in human-in-the-loop editing: the draft answers are shown in a chat UI for domain experts to evaluate and improve. Once approved, a synthesis agent can create the final PDF or text deliverable, along with tables and figures being as necessary.
In the end, this agentic workflow reduces the time spent on manual reporting from weeks to hours: agents fill in the questionnaire items from the data in batches, mark any issues, let human review, and then produce a full report. Every answer comes with inline references and calculation steps for clarity. The outcome is an ESG report ready for audit which was generated by code and AI, not a human hand.
Conclusion
An end-to-end ESG workflow can run far smoother when multiple AI agents share the load. They pull information from research sources, news feeds, and internal files at the same time, check the data against relevant rules, and help shape the final report using context-aware generation. The code examples show how each part stays clean and modular, making it easy to plug in real APIs, expand the rule set, or adjust the logic when regulations shift. The real win is time: teams spend less energy chasing data and more on understanding what it means. With this pipeline, you have a clear blueprint for building your own agent-driven ESG reporting system.
Frequently Asked Questions
Q1. How does an agentic ESG pipeline reduce manual reporting time?
A. It splits the workload across autonomous agents that pull data, check compliance, and draft sections in parallel. Most of the grunt work disappears, leaving humans to review and refine instead of assembling everything by hand.
Q2. Do I need specialized infrastructure to run these agents?
A. Not really. A typical setup uses Python, LangChain, vector search tools like FAISS, and an LLM API. You can scale up later with workflow orchestrators or cloud functions if needed.
Q3. Can this system adapt to changing ESG regulations?
A. Yes. Compliance rules live in code or configuration, so you can update or add new rule modules without touching the rest of the pipeline. Agents automatically apply the latest logic during checks.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]





