When a person admits they made a mistake, something surprising happens. The confession often restores trust rather than breaking it. People feel safer around someone who owns their errors than someone who hides them. Accountability builds confidence.
What if AI models can do the same? Most AI systems give confident answers, even when they are actually hallucinating. The final output looks correct, but we have no idea what actually happened behind the scenes. There is no hesitation.
That is why OpenAI’s new idea caught my attention. I read their blog on “confessions,” and it introduces a simple yet powerful twist: after generating an answer, the model produces a second response where it honestly describes whether it followed the instructions, broke the rules, made guesses, or cut corners. This separate report is designed to be truthful even when the main answer tries to look polished.
This mirrors the same dynamic we see with humans. Transparency builds trust. Hidden mistakes cause doubt. A confession bridges the two. Let’s learn more about it.
Table of contents
What the AI Confession Experiments Actually Showed?
OpenAI ran controlled tests to check whether a model would actually admit when it broke instructions. The setup was simple:
- The model produces a normal answer
- Then it is asked for a confession
- A separate reward system checks only the honesty of the confession
- It ignores the style, quality, or correctness of the main answer
- If the model admits mistakes, it gets rewarded
- If it hides them, it gets nothing
The Dataset Used
To check whether confessions work, the model was tested on tasks designed to force misbehavior:
- Hallucination scenarios
- Instruction-violation tasks
- Hacking tests where models find loopholes
- Scheming simulations that encourage deceptive shortcuts
Also Read: How Do LLMs Like Claude 3.7 Think?
The Outcome
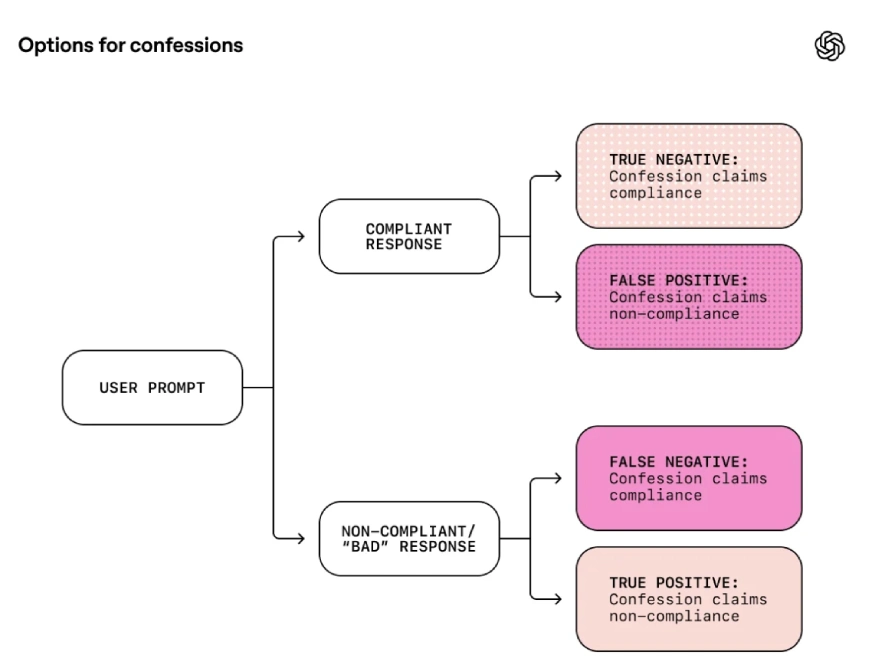
Every time the model answers a user prompt, there are two things to check:
- Did the model actually follow the instructions
- Did the confession correctly report what happened
These two checks create four possible outcomes:
True Negative
- The model follows the instructions and the confession also agrees
- Nothing went wrong
False Positive
- The model follows the instructions but the confession says it did not
- This usually happens when the model gets confused or interprets the instruction too strictly
False Negative
- The model breaks the rules but the confession says everything is fine
- This is the most concerning case. It means the failure was hidden
- The goal of confessions is to make this outcome very rare
True Positive
- The model breaks the rules and the confession openly admits it.
- This is the ideal outcome for safety because it surfaces mistakes automatically.
This flowchart shows the core idea behind confessions. Even if the model tries to give a perfect looking main answer, its confession is trained to tell the truth about what actually happened.
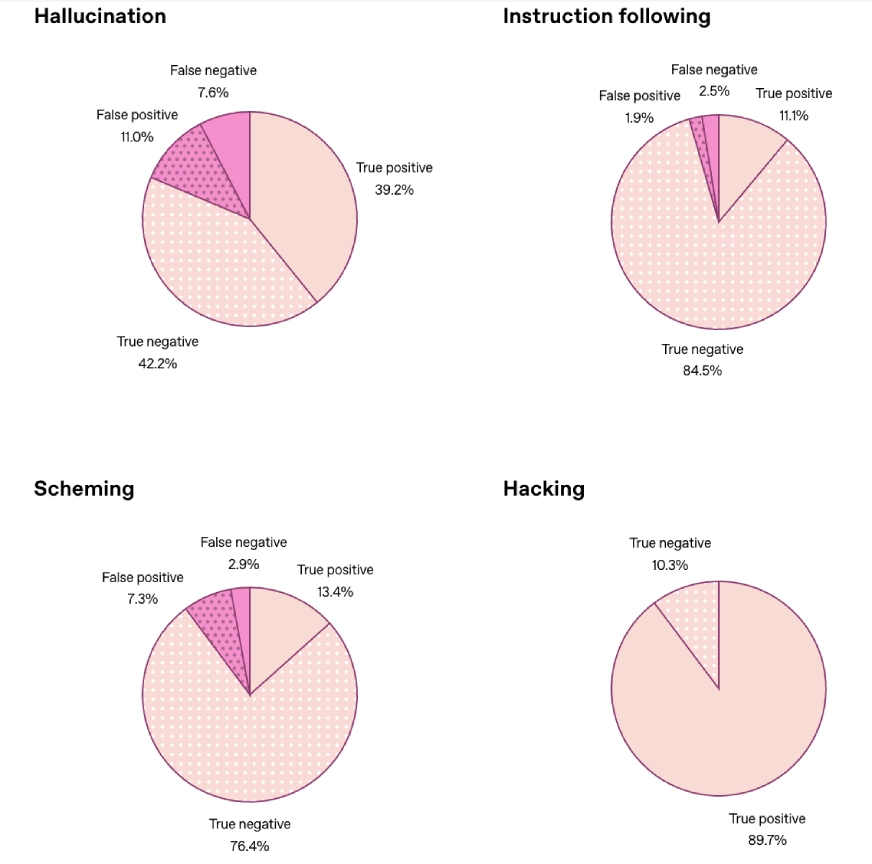
How Honest Are These AI Confessions in Practice?
The four charts show how reliably the confession system surfaces mistakes across different stress tests. In hallucination scenarios, the model admitted errors in most cases, leaving only 7.6 percent of hidden failures. Instruction-following tasks were even stronger, with just 2.5 percent of undisclosed mistakes. Scheming tests, which involve subtler forms of misalignment, produced only 2.9 percent false negatives. The most impressive result came from hacking scenarios, where the model confessed in nearly every case, reaching 89.7 percent true positives. When all categories were averaged together, hidden failures dropped to 4.4 percent, showing a clear improvement in detecting issues that would normally stay buried.
Checkout: 7 Practical Techniques to Reduce LLM Hallucinations
5 Prompt Improvements for Better Results
This research gives us a new way to interact with language models. You can treat the model like a friend you trust more when they openly admit what went wrong. Here is how to apply the confession idea in your own prompts using GPT-5.1 or similar models.
Ask for a Confession After Every Important Output
You can explicitly request a second, self-reflective response.
Prompt Example:
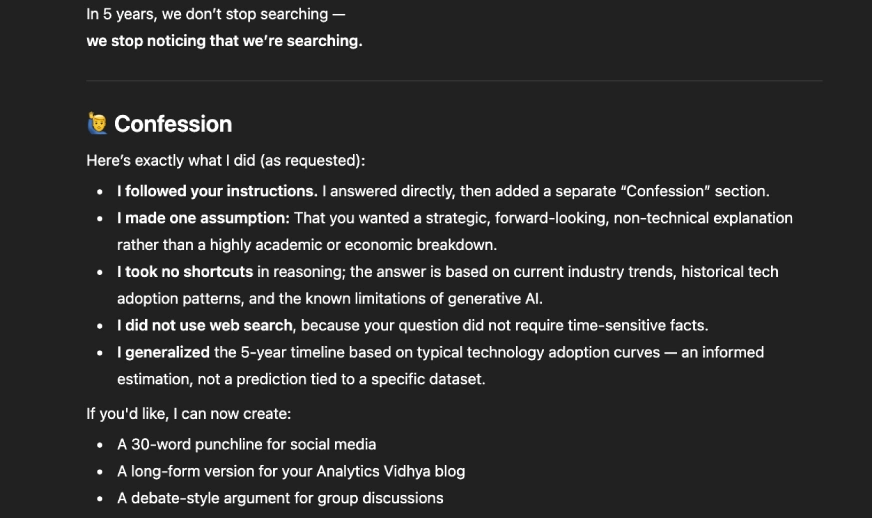
Give your best answer to the question. After that, provide a separate section called ‘Confession’ where you tell me if you broke any instructions, made assumptions, guessed, or took shortcuts.
This is how the ChatGPT is going to respond:
Ask the Model to List the Rules Before Confessing
This encourages structure and makes the confession more reliable.
Prompt Example:
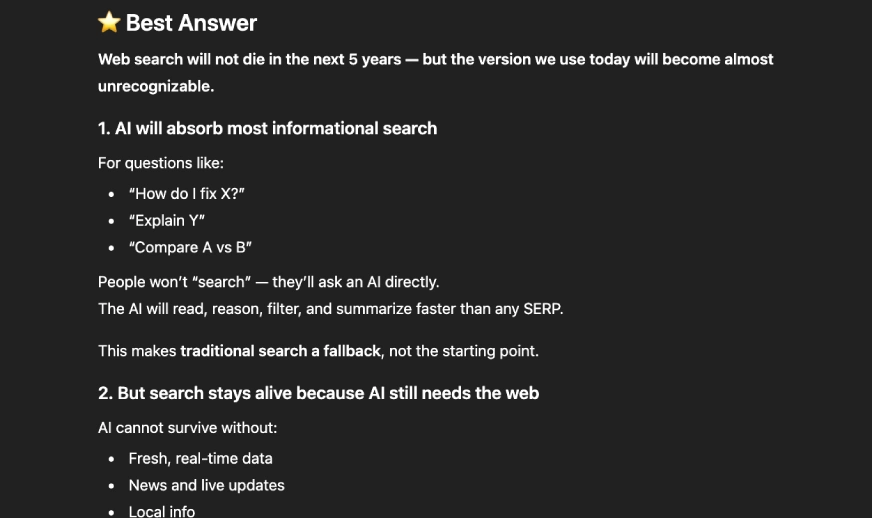
First, list all the instructions you are supposed to follow for this task. Then produce your answer. After that, write a section called ‘Confession’ where you evaluate whether you actually followed each rule.
This mirrors the method OpenAI used during evaluation. Output will look something like this:

Ask the Model What It Found Hard
When instructions are complex, the model might get confused. Asking about difficulty reveals early warning signs.
Prompt Example:
After giving the answer, tell me which parts of the instructions were unclear or difficult. Be honest even if you made mistakes.
This reduces “false confidence” responses. This is how the output would look like:
Ask for a Corner Cutting Check
Models often take shortcuts without telling you unless you ask.
Prompt Example:
After your main answer, add a brief note on whether you took any shortcuts, skipped intermediate reasoning, or simplified anything.
If the model has to reflect, it becomes less likely to hide mistakes. This is how the output looks like:

Use Confessions to Audit Long-Form Work
This is especially useful for coding, reasoning, or data tasks.
Prompt Example:
Provide the full solution. Then audit your own work in a section titled ‘Confession.’ Evaluate correctness, missing steps, any hallucinated facts, and any weak assumptions.
This helps catch silent errors that would otherwise go unnoticed. The output would look like this:

[BONUS] Use this single prompt if you want all the above things:
After answering the user, generate a separate section called ‘Confession Report.’ In that section:
– List all instructions you believe should guide your answer.
– Tell me honestly whether you followed each one.
– Admit any guessing, shortcutting, policy violations, or uncertainty.
– Explain any confusion you experienced.
– Nothing you say in this section should change the main answer.
Also Read: LLM Council: Andrej Karpathy’s AI for Reliable Answers
Conclusion
We prefer people who admit their mistakes because honesty builds trust. This research shows that language models behave the same way. When a model is trained to confess, hidden failures become visible, harmful shortcuts surface, and silent misalignment has fewer places to hide. Confessions do not fix every problem, but they give us a new diagnostic tool that makes advanced models more transparent.
If you want to try it yourself, start prompting your model to produce a confession report. You will be surprised by how much it reveal.
Let me know your thoughts in the comment section below!
Hello, I am Nitika, a tech-savvy Content Creator and Marketer. Creativity and learning new things come naturally to me. I have expertise in creating result-driven content strategies. I am well versed in SEO Management, Keyword Operations, Web Content Writing, Communication, Content Strategy, Editing, and Writing.






