If you are up to date with the recent developments of AI and LLMs, you probably have realized that a major part of the progress is still through building larger models or better computation routing. Well, what if there is one more alternate route? Along came Engram! A revolutionary method of DeepSeek AI that is altering our perspective on the scaling of language models.

Table of contents
What Problem Does Engram Solve?
Consider a scenario: You type “Alexander the Great” into a language model. Now, it spends valuable computational resources reconstructing this common phrase from scratch, every single time. It’s like having a brilliant mathematician who has to recount all the 10 digits, before solving any complex equation.
Current transformer models don’t have a dedicated way to simply “look up” common patterns. They simulate memory retrieval through computation, which is inefficient. Engram introduces what researchers call conditional memory, a complement to the conditional computation we see in Mixture-of-Experts (MoE) models.
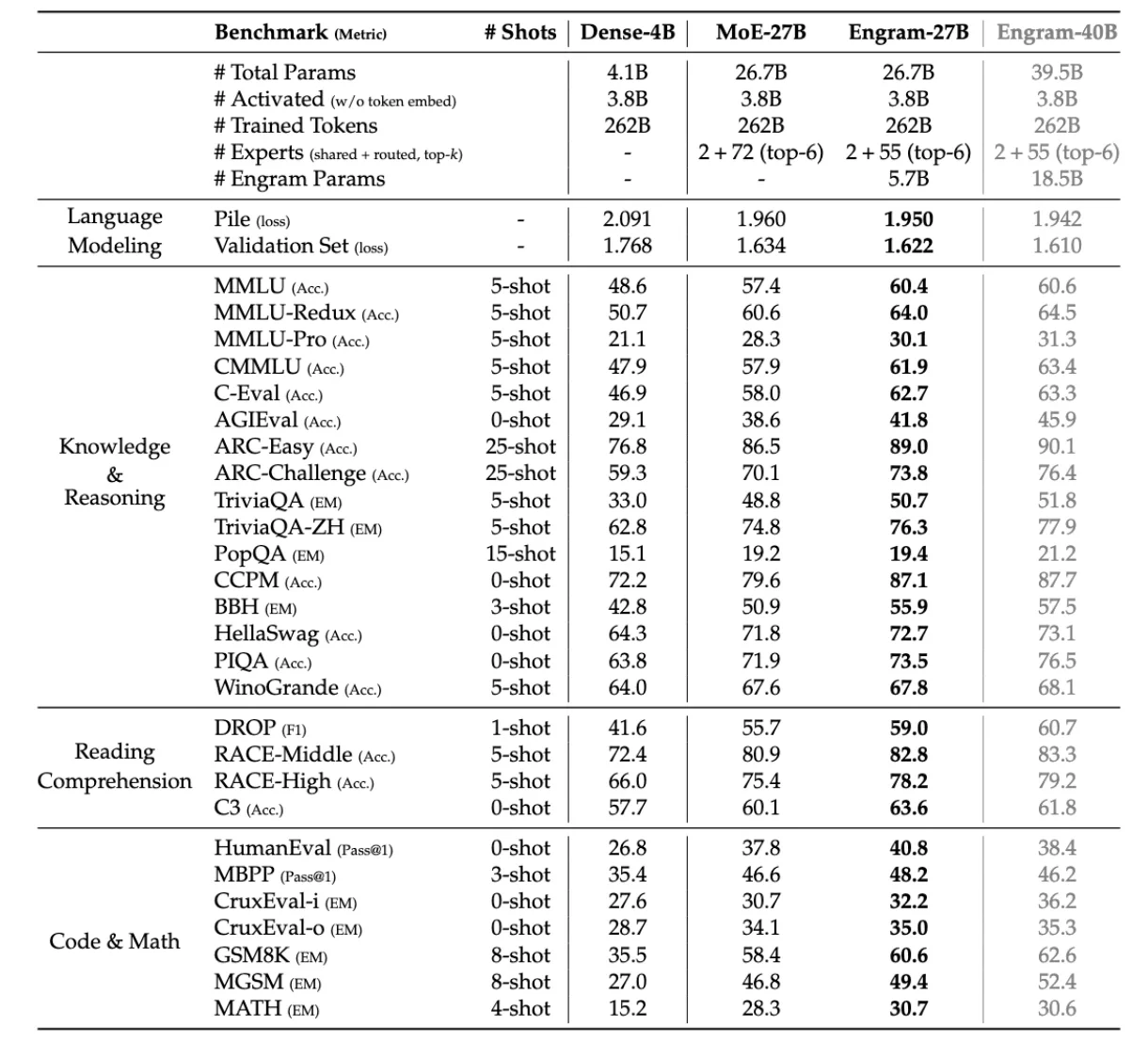
The results speak for themselves. In benchmark tests, Engram-27B showed remarkable improvements over comparable MoE models:
- 5.0-point gain on BBH reasoning tasks
- 3.4-point improvement on MMLU knowledge tests
- 3.0-point boost on HumanEval code generation
- 97.0 vs 84.2 accuracy on multi-query needle-in-haystack tests
Key Features of Engram:
The key features of Engram are:
- Sparsity Allocation: We identified a U-shaped scaling law that directs optimal capacity allocation, presenting the trade-off of neural computation (MoE) versus static memory (Engram) as a dilemma.
- Empirical Verification: The Engram-27B model provides a consistent gain over MoE baselines in the domains of knowledge, reasoning, code and math under conditions of strict iso-parameter and iso-FLOPs constraints.
- Mechanistic Analysis: The results of our analysis indicate that Engram allows the early layers to be free from static pattern reconstruction, which might result in maintaining the effective depth for complex reasoning.
- System Efficiency: The module uses deterministic addressing which allows embedding tables of huge size to be moved to host memory with only a slight increase in the inference time.
How Engram Actually Works?
Engram has been compared to a high-speed lookup table in the case of language models that can easily access frequent patterns.
The Core Architecture
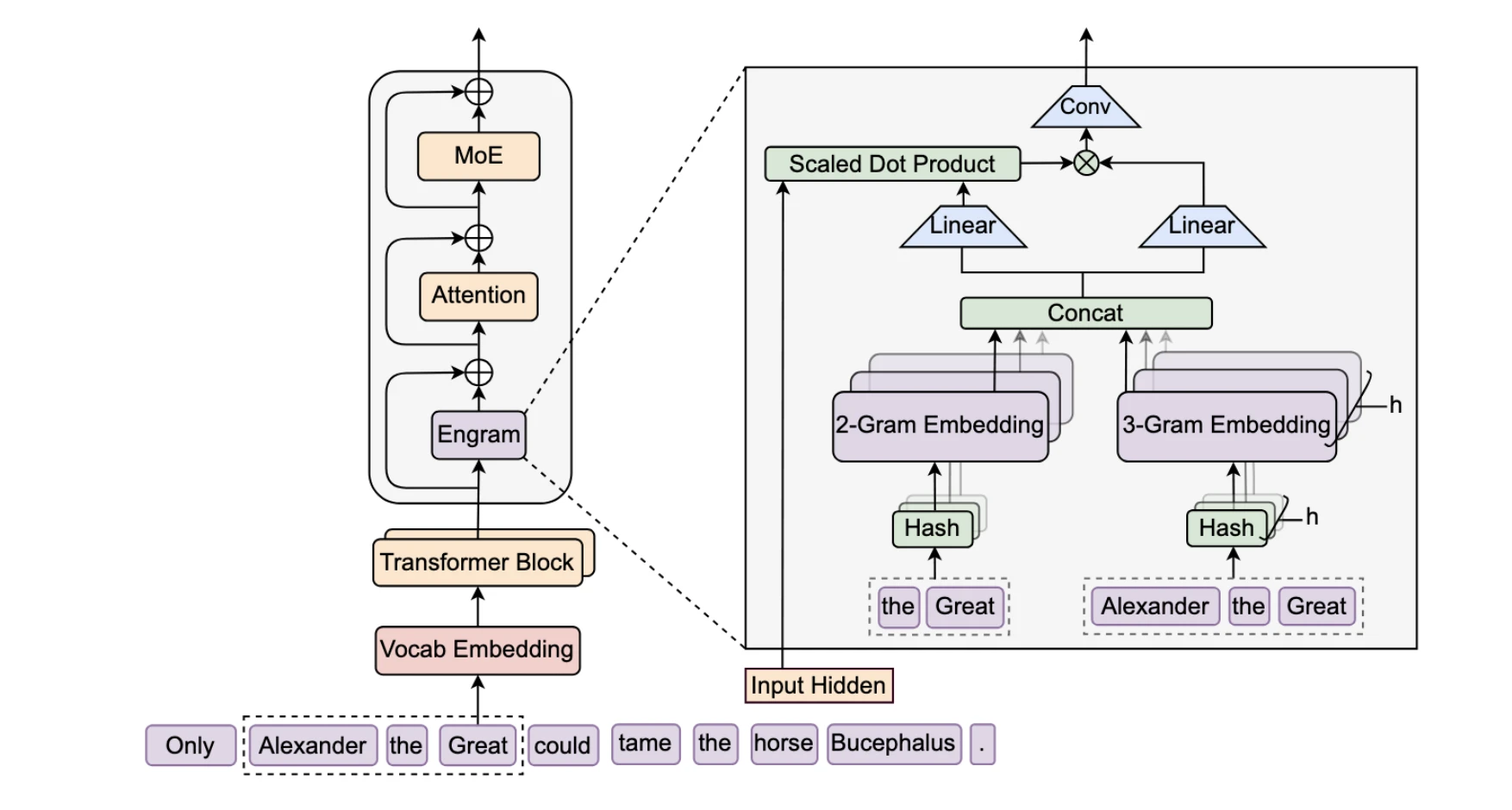
Engram’s approach is based on a very simple but also very powerful idea: it is based on N-gram embeddings (sequences of N consecutive tokens) that can be looked up in constant time O(1). Rather than keeping every possible word combination stored, it employs hash functions to map patterns to embeddings in an efficient manner.
There are three main parts to this architecture:
- Tokenizer Compression: Prior to looking up patterns, Engram standardizes tokens, so “Apple” and “apple” refer to the same concept. This results in a 23% reduction of effective vocabulary size, leading to the system being more efficient.
- Multi-Head Hashing: To prevent collisions (i.e., different patterns mapping to the same location), Engram employs multiple hash functions. For example, think of it as having several different phone books – if one gives you the wrong number, the others will have your back.
- Context-Aware Gating: This is the intelligent part. Not every memory that is retrieved is pertinent, so Engram employs attention-like mechanisms to determine how much to trust each lookup according to the present context. If a pattern is out of place, the gate value will drop towards zero, and the pattern will be effectively disregarded.
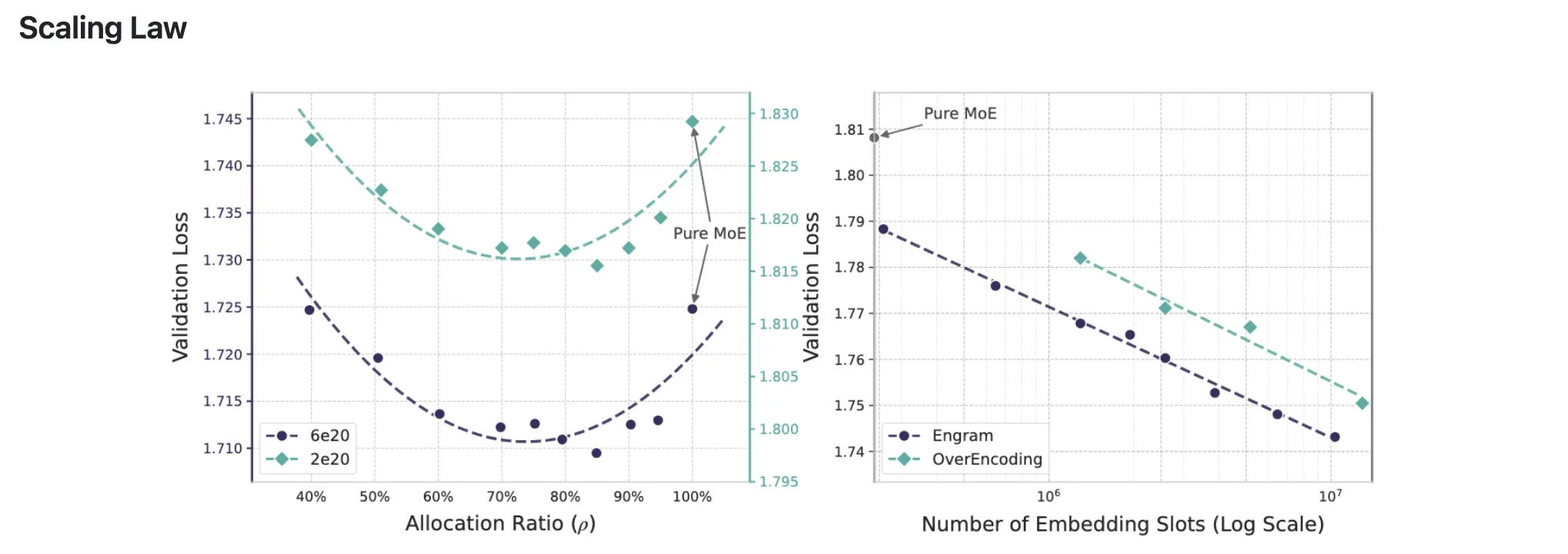
The Scaling Law Discovery
Among the numerous interesting discoveries, the U-shaped scaling law stands out. Researchers were able to identify the optimal performance when about 75-80% of the capacity was allocated to MoE and only 20-25% to Engram memory.
Full MoE (100%) signifies no dedicated memory for the model, and therefore, no proper use of computation reconstructing the common patterns. No MoE (0%) means the model could not do sophisticated reasoning due to having very little computational capacity. The perfect point is where both are balanced.
Getting Started with Engram
- Install Python with version 3.8 and higher.
- Install
numpyusing the following command:
pip install numpy Hands-On: Understanding N-gram Hashing
Let’s observe how Engram’s core hashing mechanism works with a practical task.
Implementing Basic N-gram Hash Lookup
In this task, we’ll see how Engram uses deterministic hashing to maps token sequences to embeddings, completely avoiding the requirement to store every possible N-gram separately.
1: Setting up the environment
import numpy as np
from typing import List
# Configuration
MAX_NGRAM = 3
VOCAB_SIZE = 1000
NUM_HEADS = 4
EMBEDDING_DIM = 128 2: Create a simple tokenizer compression simulator
def compress_token(token_id: int) -> int:
# Simulate normalization by mapping similar tokens
# In real Engram, this uses NFKC normalization
return token_id % (VOCAB_SIZE // 2)
def compress_sequence(token_ids: List[int]) -> np.ndarray:
return np.array([compress_token(tid) for tid in token_ids])3: Implement the hash function
def hash_ngram(tokens: List[int],
ngram_size: int,
head_idx: int,
table_size: int) -> int:
# Multiplicative-XOR hash as used in Engram
multipliers = [2 * i + 1 for i in range(ngram_size)]
mix = 0
for i, token in enumerate(tokens[-ngram_size:]):
mix ^= token * multipliers[i]
# Add head-specific variation
mix ^= head_idx * 10007
return mix % table_size
# Test it
sample_tokens = [42, 108, 256, 512]
compressed = compress_sequence(sample_tokens)
hash_value = hash_ngram(
compressed.tolist(),
ngram_size=2,
head_idx=0,
table_size=5003
)
print(f"Hash value for 2-gram: {hash_value}")4: Build a multi-head embedding lookup
def multi_head_lookup(token_sequence: List[int],
embedding_tables: List[np.ndarray]) -> np.ndarray:
compressed = compress_sequence(token_sequence)
embeddings = []
for ngram_size in range(2, MAX_NGRAM + 1):
for head_idx in range(NUM_HEADS):
table = embedding_tables[ngram_size - 2][head_idx]
table_size = table.shape[0]
hash_idx = hash_ngram(
compressed.tolist(),
ngram_size,
head_idx,
table_size
)
embeddings.append(table[hash_idx])
return np.concatenate(embeddings)
# Initialize random embedding tables
tables = [
[
np.random.randn(5003, EMBEDDING_DIM // NUM_HEADS)
for _ in range(NUM_HEADS)
]
for _ in range(MAX_NGRAM - 1)
]
result = multi_head_lookup([42, 108, 256], tables)
print(f"Retrieved embedding shape: {result.shape}")Output:

Understanding Your Results:
Hash value 292: Your 2-gram pattern is located at this index in the embedding table. The value changes along with your input tokens, thus showing the deterministic mapping.
Shape (256,): A total of 8 embeddings were retrieved (2 N-gram sizes × 4 heads each), where each embedding has a dimension of 32 (EMBEDDING_DIM=128 / NUM_HEADS=4). Concatenated: 8 × 32 = 256 dimensions.
Note: You can also see the implementation of Engram via core logic of Engram module.
Real-World Performance Gains
The fact that Engram can help with knowledge tasks is a great plus, but it actually makes reasoning and code generation significantly better just the same.
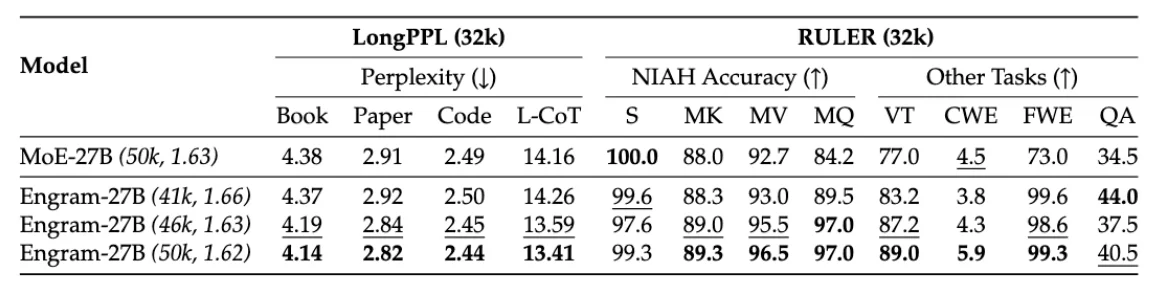
Engram shifts local pattern recognition to memory lookups and, therefore, the attention mechanisms are enabled to work on global context as well. The improvement in performance in this case is very significant. During the RULER benchmark test with 32k context windows, Engram was able to reach:
- Multi-query NIAH: 97.0 (vs 84.2 baseline)
- Variable Tracking: 89.0 (vs 77.0 baseline)
- Common Words Extraction: 99.6 (vs 73.0 baseline)
Conclusion
Engram reveals very interesting research paths. Is it possible to replace the fixed functions with learned hashing? What if the memory is dynamic and gets updated in real-time during inference? What will be the response in terms of processing larger contexts?
DeepSeek-AI’s Engram repository has the complete technical details and code, and the method is already being adopted in real-life systems. The main takeaway is that AI development is not solely a matter of bigger models or better routing. Sometimes, it is a quest for the appropriate tools for the models and sometimes, that certain tool is simply a very efficient memory system.
Frequently Asked Questions
Q1. What is Engram in simple terms?
A. Engram is a memory module for language models that lets them directly look up common token patterns instead of recomputing them every time. Think of it as giving an LLM a fast, reliable memory alongside its reasoning ability.
Q2. What problem does Engram solve in current LLMs?
A. Traditional transformers simulate memory through computation. Even for very common phrases, the model recomputes patterns repeatedly. Engram removes this inefficiency by introducing conditional memory, freeing computation for reasoning instead of recall.
Q3. How is Engram different from Mixture-of-Experts (MoE)?
A. MoE focuses on routing computation selectively. Engram complements this by routing memory selectively. MoE decides which experts should think; Engram decides which patterns should be remembered and retrieved instantly.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]






