LLMs like ChatGPT, Claude, and Gemini, are often considered intelligent because they seem to recall past conversations. The model acts as if it got the point, even after you made a follow-up question. This is where LLM memory comes in handy. It allows a chatbot to go back to the point of what “it” or “that” means. Most LLMs are stateless by default. Therefore, each new user query is treated independently, with no knowledge of past exchanges.
However, LLM memory works very differently from human memory. This memory illusion is one of the main factors that determine how modern AI systems are perceived as being useful in real-world applications. The models do not “recall” in the usual way. Instead, they use architectural mechanisms, context windows, and external memory systems. In this blog, we will discuss how LLM memory functions, the various types of memory that are involved, and how current systems support models in remembering what is really important.
Table of contents
What is Memory in LLMs?
Memory in LLMs is a concept that enables LLMs to use previous information as a basis for creating new responses. Essentially, the term “established memory” defines how constructed memories work within LLMs, compared to established memory in humans, where established memory is used in place of established memory as a system of storing and/ or recalling experiences.
In addition, the established memory concept adds to the overall capability of LLMs to detect and better understand the context, the relationship between past exchanges and current input tokens, as well as the application of recently learned patterns to new circumstances through an integration of input tokens into established memory.
Since established memory is constantly developed and applied based on what was learned during prior interactions, information derived from established memory enables a substantially more comprehensive understanding of context, previous message exchanges, and new requests compared to the traditional use of LLMs to respond to requests in the same way as with current LLM methods of operation.
What Does Memory Mean in LLMs?
The large language model (LLM) memory enables the use of prior knowledge in reasoning. The knowledge may be connected to the current prompt. Past conversation though is pulled from external data sources. Memory does not imply that the model has non-stop awareness of all the information. Rather, it is the model that produces its output based on the provided context. Developers are constantly pouring in the relevant information into each model call, thus creating memory.
Key Points:
- The LLM memory feature allows for retaining old text and utilizing it in new text generation.
- The memory can last for a short time (only for the ongoing conversation) or a long time (input across user sessions), as we will show throughout the text.
- To humans, it would be like comparing the short-term and long-term memory in our brains.
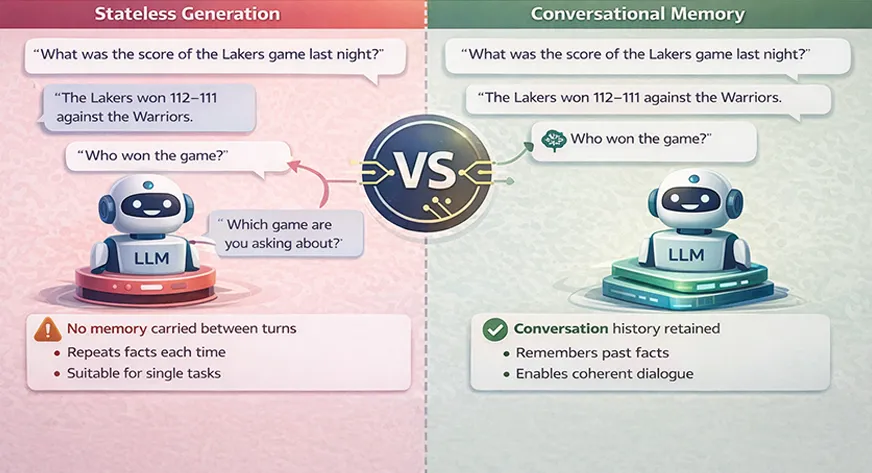
Memory vs. Stateless Generation
In a standard situation, an LLM does not retain any information between calls. For instance, “each incoming query is processed independently” if there are no explicit memory mechanisms in place. This indicates that in answering the question “Who won the game?” an LLM would not consider that “the game” was previously referred to. The model would require you to repeat all important information every single time. Such a stateless character is often suitable for single tasks, but it gets problematic for conversations or multi-step tasks.
In contrast, memory systems allow for this situation to be reversed. The inclusion of conversational memory means that the LLM’s inputs consist of the history of previous conversations, which is commonly condensed or shortened to fit the context window. Consequently, the model’s answer can rely on the previous exchanges.
Core Components of LLM Memory
The memory of LLM operates through the collaboration of various layers. The model that is formed by these elements sets the limits of the information a model can consider, the time it lasts, and the extent to which it influences the final results with certainty. The knowledge of such components empowers the engineers to create systems that are scalable and maintain the same level of importance.
Context Window: The Working Memory of LLMs
The context window defines how many tokens an LLM can process at once. It acts as the model’s short-term working memory.
Everything inside the context window influences the model’s response. Once tokens fall outside this window, the model loses access to them entirely.
Challenges with Large Context Windows
Longer context windows enrich memory capacity but pose a certain issue. They raise the expenses for computation, cause a delay, and in some cases, reduce the quality of the attention paid. The models may not be able to effectively discriminate between salient and non-salient with the increase in the context length.
For example, if an 8000-token context window model is used, then it will be able to understand only the latest 8000 tokens out of the dialogue, documents, or instructions combined. Everything that goes beyond this must be either shortened or discarded. The context window comprises all that you transmit to the model: system prompts, the entire history of the conversation, and any relevant documents. With a bigger context window, more interesting and complex conversations can take place.
Parametric vs Non-Parametric Memory in LLMs
When we say memory in LLM, it can be thought of in terms of where it is stored. We make a difference between two kinds of memory: parametric and non-parametric. Now we’ll discuss it in brief.
- Parametric memory means the knowledge that was saved in the model weights during the training phase. This could be a mixture of various things, such as language patterns, world knowledge, and the ability to reason. This is how a GPT model could have worked with historical facts up to its training cutoff date because they are stored in the parametric memory.
- Non-parametric memory is maintained outside of the model. It consists of databases, documents, embeddings, and conversation history that are all added on-the-fly. Non-parametric memory is what modern LLM systems heavily depend on to provide both accuracy and freshness. For example, a knowledge base in a vector database is non-parametric. As it can be added to or corrected at any point in time, the model can still access information from it during the inference process.
Types of LLM Memory
LLM memory is a term used to refer to the same concept, but in different ways. The most common way to tell them apart is by the short-term (contextual) memory and the long-term (persistent) memory. The other perspective takes terms from cognitive psychology: semantic memory (knowledge and facts), episodic memory (events), and procedural memory (acting). We will describe each one.
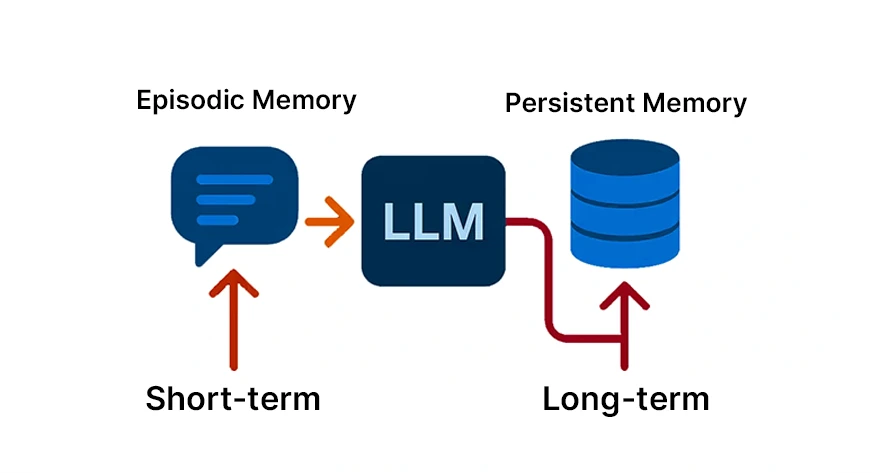
Contextual Memory or Short-Term Memory
Short-term memory, also known as contextual, is the memory that contains the information that is currently being talked about. It is the digital counterpart of your short-term recall. This type of memory is usually kept in the present context window or a conversation buffer.
Key Points:
- The recent questions of the user and the answers of the model are saved in memory during the session. There is no long-lasting memory. Normally, this memory is removed after the conversation, unless it is stored.
- It is very fast and does not consume much memory. It does not need a database or complicated infrastructure. It is simply the tokens in the current prompt.
- It increases coherence, i.e., the model “understands” what was recently discussed and can accurately refer to it using terms such as “he” or “the previous example”.
For instance, a support chatbot could remember that the customer had earlier inquired about a faulty widget, and then, within the same conversation, it could ask the customer if he had tried rebooting the widget. That is short-term memory going into action.

Persistent Memory or Long-Term Memory
Persistent memory is a feature that consistently exists in modern computing systems and traditionally retains information through various user sessions. Among the different types of system retains are user preferences, application data, and previous interactions. As a matter of fact, developers must rely on external sources like databases, caches, or vector stores for a temporary solution, as models do not have the ability to store these internally, thus, long-term memory simulation.
For instance, an AI writing assistant that could forget that your preferred tone is “formal and concise” or which projects you wrote about last week. When you return the next day, the assistant still remembers your preferences. To implement such a feature, developers usually adopt the following measures:
- Embedding stores or vector databases: They keep documents or facts in the form of high-dimensional vectors. The large language model (LLM) is capable of conducting a semantic search on these vectors to obtain memories that are relevant.
- Fine-tuned models or memory weights: In certain setups, the model is periodically fine-tuned or updated to encode the new information provided by the user long-term. This is akin to embedding memory into the weights.
- External databases and APIs: Structured data (like user profiles) is stored in a database and fetched as needed.

Vector Databases & Retrieval-Augmented Generation (RAG)
A major method for executing long-term memory is vector databases along with retrieval-augmented generation (RAG). RAG is a technique that places the generation phase of the LLM along with the retrieval phase, dynamically combining them in an LLM manner.
In a RAG system, when the user submits a query, the system first utilizes the retriever to scan an external knowledge store, usually a vector database, for pertinent data. The retriever identifies the closest entries to the query and fetches those corresponding text segments. The next step is to insert those retrieved segments into the context window of the LLM as supplementary context. The LLM provides the answer based on the user’s input as well as the retrieved data. RAG offers significant advantages:
- Grounded answers: It combats hallucination by relying on actual documents for answers.
- Up-to-date info: It grants the model access to fresh information or proprietary data without going through the entire retraining process.
- Scalability: The model is not required to hold everything in memory at once; it retrieves only what is necessary.
For example, let us take an AI that summarizes research papers. RAG could enable it to get relevant academic papers, which would then be fed to the LLM. This hybrid system merges transitional memory with lasting memory, yielding tremendously powerful results.

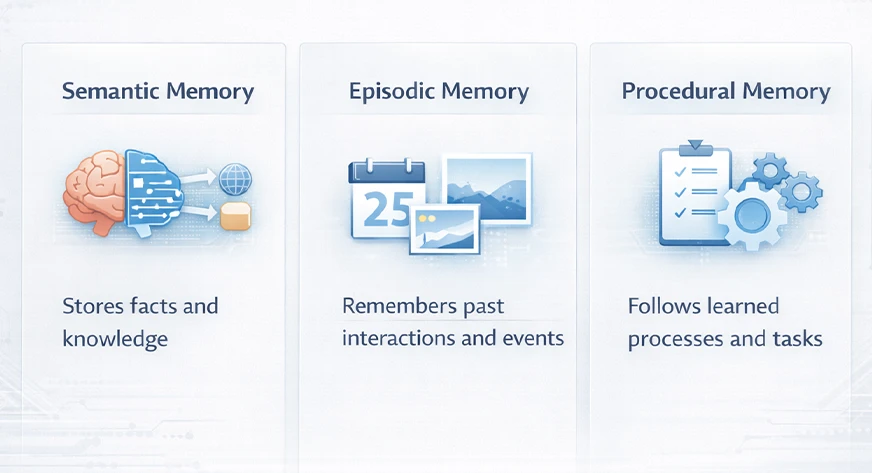
Episodic, Semantic & Procedural Memory in LLMs
Cognitive science terms are frequently used by researchers to characterize LLM memory. They frequently categorize memory into three types: semantic, episodic, and procedural memory:
- Semantic Memory: This represents the inventory or storage of facts and general knowledge pertaining to the model. One practical aspect of this is that it comprises external knowledge bases or document stores. The LLM may have gained extensive knowledge during the training phase. However, the latest or most detailed facts are in databases.
- Episodic Memory: It comprises individual events or dialogue history. An LLM uses its episodic memory to keep track of what just took place in a conversation. This memory provides the answer to inquiries like “What was spoken earlier in this session?”
- Procedural Memory: This is the set of rules the model has received on how to act. In the case of LLM, procedural memory contains the system prompt and the rules or heuristics that the model is given. For example, instructing the model to “Always respond in bullet points” or “Be formal” is equivalent to setting the procedural memory.
How LLM Memory Works in Real Systems
In developing an LLM system with memory capabilities, the developers incorporate the context and the external storage in the model’s architecture as well as in the prompt design.
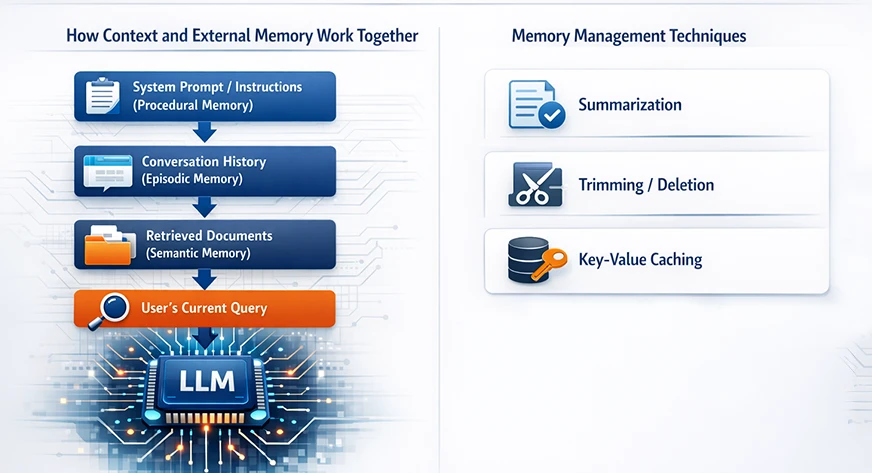
How Context and External Memory Work Together
The memory of large language models is not regarded as a unitary element. Rather, it results from the combined interactivity of attention, embeddings, and external retrieval systems. Typically, it contains:
- A system prompt or instructions (part of procedural memory).
- The conversation history (contextual/episodic memory).
- Any retrieved external documents (semantic/persistent memory).
- The user’s current query.
All this information is then merged into one prompt that is within the context window.
Memory Management Techniques
The model can be easily defeated by raw memory, even if the architecture is good. Engineers employ various methods to control the memory so that the model remains efficient:
- Summarization: Instead of keeping entire transcripts of lengthy discussions, the system can do a summary of the earlier parts of the conversation at regular intervals.
- Trimming/Deletion: The most basic approach is to get rid of messages that are old or not relevant. For instance, when you exceed the initial 100 messages in a chat, you can get rid of the oldest ones if they are no longer needed. Hierarchical Organization: Memory can be organized by topic or time. For example, the older conversations can be categorized by topic and then kept as a story, while the new ones are kept verbatim.
- Key-Value Caching: On the model’s side, Transformers apply a method named KV (key-value) caching. KV caching doesn’t enhance the model’s knowledge, but it makes the long context sequence generation faster by reusing previous computations.
Challenges & Limitations of LLM Memory
The addition of memory to large language models is a significant advantage, but it also comes with a set of new difficulties. Among the top problems are the cost of computation, hallucinations, and privacy issues.
Computational Bottlenecks & Costs
Memory is both highly effective and very costly. Both the long context windows and memory retrieval are the main reasons for requiring more computation. To give a rough example, doubling the context length approximately quadruples the computation for the attention layers of the Transformer. In reality, every additional token or memory lookup utilizes both GPU and CPU power.
Hallucination & Context Misalignment
Another issue is the hallucination. This situation arises when the LLM gives out wrong information that is nevertheless convincing. For instance, if the external knowledge base has old and outdated data, the LLM may present an old fact as if it were new. Or, if the retrieval step fetches a document that is only loosely related to the topic, the model may end up interpreting it into an answer that is entirely different.
Privacy & Ethical Considerations
Keeping conversation history and personal data creates serious concerns regarding privacy. If an LLM retains user preferences or information about the user that is of a personal or sensitive nature, then such data must be treated with the highest level of security. Actually, the designers have to follow the regulations (such as GDPR) and the practices that are considered best in the industry. This means that they have to get the user’s consent for memory, holding the minimum possible data, and making sure that one user’s memories are never mixed with another’s.

Also Read: What is Model Collapse? Examples, Causes and Fixes
Conclusion
LLM memory is not just one feature but rather a sophisticated system that has been designed with great care. It mimics smart recall by merging context windows, external retrieval, and architectural design decisions. The models still maintain their basic core of being stateless, but the current memory systems give them an impression of being persistent, contextual, and adaptive.
With the advancements in research, LLM memory will increasingly become more human-like in its efficiency, selectivity, and memory characteristics. A deep comprehension of the working of these systems will enable the developers to create AI applications that will be able to remember what is important, without the drawbacks of precision, cost, or trust.
Frequently Asked Questions
Q1. Do LLMs actually remember past conversations?
A. LLMs do not remember past conversations by default. They are stateless systems that generate responses only from the information included in the current prompt. Any apparent memory comes from conversation history or external data that developers explicitly pass to the model.
Q2. What is LLM memory?
A. LLM memory refers to the techniques used to provide large language models with relevant past information. This includes context windows, conversation history, summaries, vector databases, and retrieval systems that help models generate coherent and context-aware responses.
Q3. What is the difference between memory and a context window in LLMs?
A. A context window defines how many tokens an LLM can process at once. Memory is broader and includes how past information is stored, retrieved, summarized, and injected into the context window during each model call.
Q4. How does RAG help with LLM memory?
A. Retrieval-Augmented Generation (RAG) improves LLM memory by retrieving relevant documents from an external knowledge base and adding them to the prompt. This helps reduce hallucinations and allows models to use up-to-date or private information without retraining.
Q5. Are LLMs stateless or stateful?
A. Most LLMs are stateless by design. Each request is processed independently unless external memory systems are used. Statefulness is simulated by storing and re-injecting conversation history or retrieved knowledge with every request.
Hello! I'm Vipin, a passionate data science and machine learning enthusiast with a strong foundation in data analysis, machine learning algorithms, and programming. I have hands-on experience in building models, managing messy data, and solving real-world problems. My goal is to apply data-driven insights to create practical solutions that drive results. I'm eager to contribute my skills in a collaborative environment while continuing to learn and grow in the fields of Data Science, Machine Learning, and NLP.





