LLMs aren’t limited to AI and related fields! They’re powering almost every tech, and thereby is one of the most asked about topics in interviews. This makes it essential to have a surface level familiarity of the technology.
This article is designed to mirror how LLMs show up in real interviews. We’ll start from first principles and build forward, so even if you’re new to the topic, you’ll be able to follow the logic behind each answer instead of memorizing jargon.
We’ll start by providing 10 interview questions that challenge the fundamentals of LLMs. Then we’d move on to more nuanced questions.
Common LLM Interview Questions
The most frequently asked questions on LLMs asked in an interview.
Q1. What is a Large Language Model (LLM)?
A. An LLM is a machine learning model trained on vast text to generate and interpret human language.
What that means is
- It learns patterns from massive text data
- It predicts the next token based on context
- Language understanding emerges from scale, not rules
Note: The interviewers want clarity, not a textbook definition. If you won’t add your own experience of using LLMs in this response, it might sound robotic.
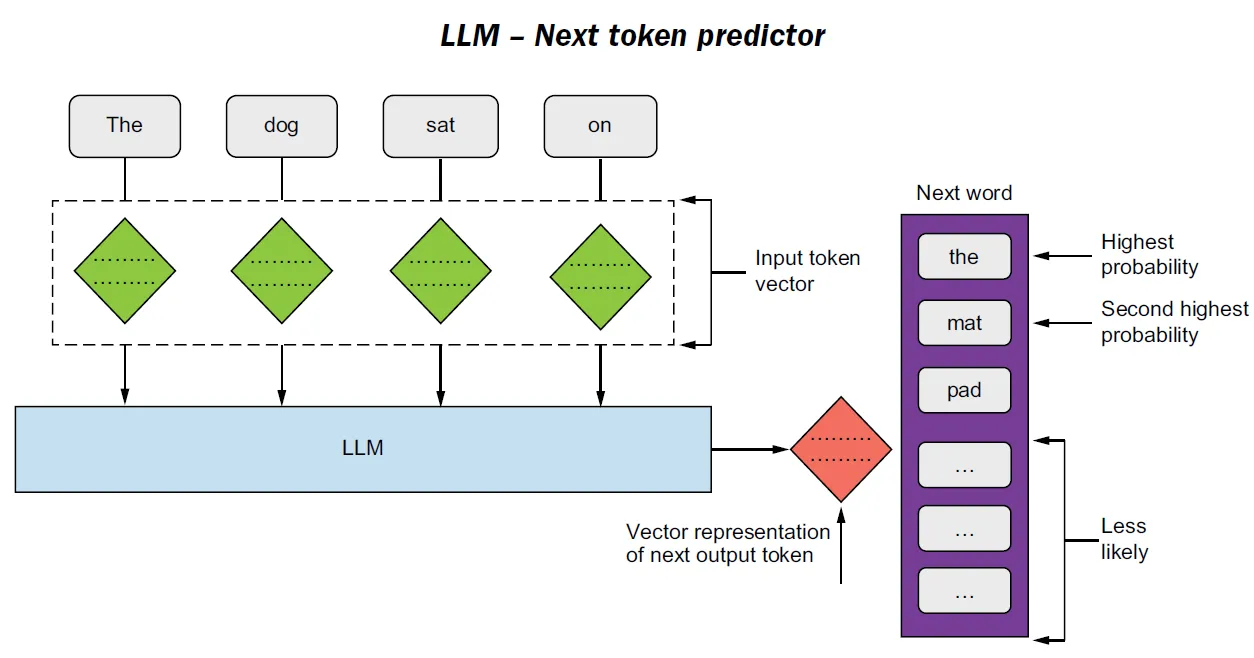
Q2. How do LLMs generate text?
A. LLMs behave like highly advanced systems for predicting the next token in a sequence. At each step, the model calculates probabilities over all possible next tokens based on the context so far.
By repeating this process many times, longer and seemingly coherent responses emerge, even though the model is only making local, step-by-step predictions.
What happens during generation
- Input is converted into tokens
- The model assigns probabilities to possible next tokens
- One token is selected and appended
- The process repeats
Note: There’s no understanding, only statistical continuation. This is why models are often described as emotionless. They generate words without intent, so the responses can feel mechanical.
Q3. What problem did transformers solve compared to older NLP models?
A. Earlier NLP models struggled to retain meaning across long sequences of text. Transformers allowed for usage of attention mechanisms, which focused on specific parts of the text — over the entirety of it — based on its weightage in the context of the overall text.
What transformers changed:
- Attention replaced recurrence
- Tokens can “look at” all other tokens directly
- Training became parallelizable
This resulted in better context handling + massive scalability.
Q4. How are LLMs trained?
A. LLMs learn by predicting the next word again and again across massive amounts of text.
It consists of three stages:
- Pretraining on large, general text corpora
- Fine-tuning for specific tasks or instructions
- Alignment using human feedback (often RLHF)
The training is done in a probabilistic manner. Meaning the performance gains are measures in terms of loss%.
Q5. What role does attention play in LLMs?
A. Attention allows the model to focus selectively on the most relevant parts of input.
Why it matters:
- Not all words contribute equally
- Attention assigns dynamic importance
- Enables long-context reasoning
As every “so, like..” might not be contributing to the overall text. Without attention, performance collapses on complex language tasks.
Q6. What are the main limitations of LLMs?
A. Despite their capabilities, LLMs suffer from hallucinations, bias, and high operational costs.
- Hallucinations from guessing likely answers
- Bias from the lopsided data the model was trained on
- High compute and energy costs from large model size
LLMs optimize for likelihood, not truth. As mentioned previously, models lack an understanding of data. So the model generates text based on which words are most likely, even when they are wrong.
Q7. What are common real-world applications of LLMs?
A. LLMs are used wherever language-heavy work can be automated or assisted. Newer models are capable of assisting in non-language work data as well.
- Question answering
- Summarization
- Content generation
- Code assistance
Make sure to include the common applications only. Extracting text, creating ghibli images etc. aren’t common enough and can be classified in one of the previous categories.
Good signal to add: Tie examples to the company’s domain.
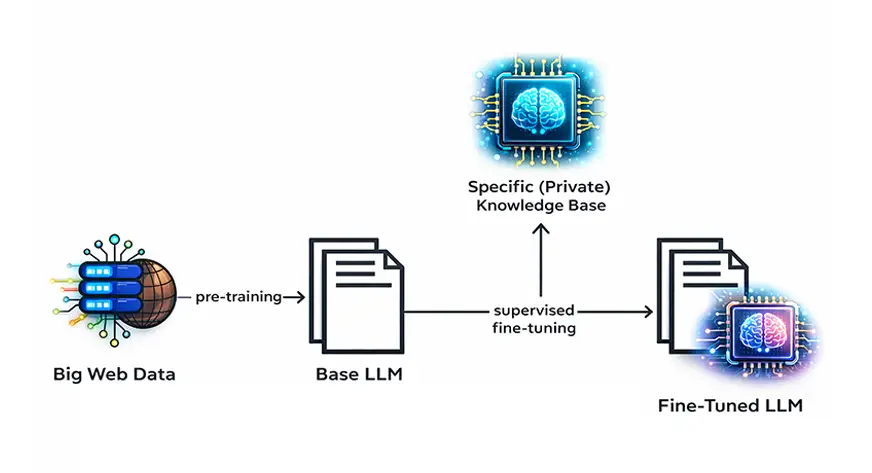
Q8. What is fine-tuning, and why is it needed?
A. Fine-tuning adjusts a general-purpose LLM to behave better for specific tasks. It’s like having a piece of clothing closely fitted to a particular measurement.
Why it matters:
- Base models are broad
- Businesses need specificity
- Fine-tuning aligns behavior with intent
Why is it needed? Because most use cases are specific. A fin-tech might not require the coding-expertise features that comes along with a model. Finetuning assures that a model that was generic initially, gets tailored to a specific use case.
Q9. What ethical risks are associated with LLMs?
A. LLMs introduce ethical challenges that scale as quickly as their adoption. Some of the risks are:
- Bias amplification
- Personal identification information leakage
- Misuse at scale
Ethics go beyond philosophy. When people deploy LLMs at scale, mistakes can cause catastrophic disruption. Therefore, it is essential to have guardrails in place to mitigate that from happening. AI governance is the way to go.
Q10. How do you evaluate the quality of an LLM?
A. Evaluation starts with measurable system-level performance indicators. The growth (or reduction in some cases) determines how well the model is performing. People evaluate LLMs using metrics like:
- Accuracy
- Latency
- Cost
To evaluate an LLM’s quality qualitatively, people use the following metrics:
- Factuality
- Coherence
- Usefulness
Combine automatic metrics with human evaluation.
Beyond the Basics LLM Questions
At this point, you should have a clear mental model of what an LLM is, how it works, and why it behaves the way it does. That’s the foundation most candidates stop at.
But interviews don’t.
Once you’ve shown you understand the mechanics, interviewers start probing something deeper: how these models behave in real systems. They want to know whether you can reason about reliability, limitations, trade-offs, and failure modes.
The next set of questions are here to assist with that!
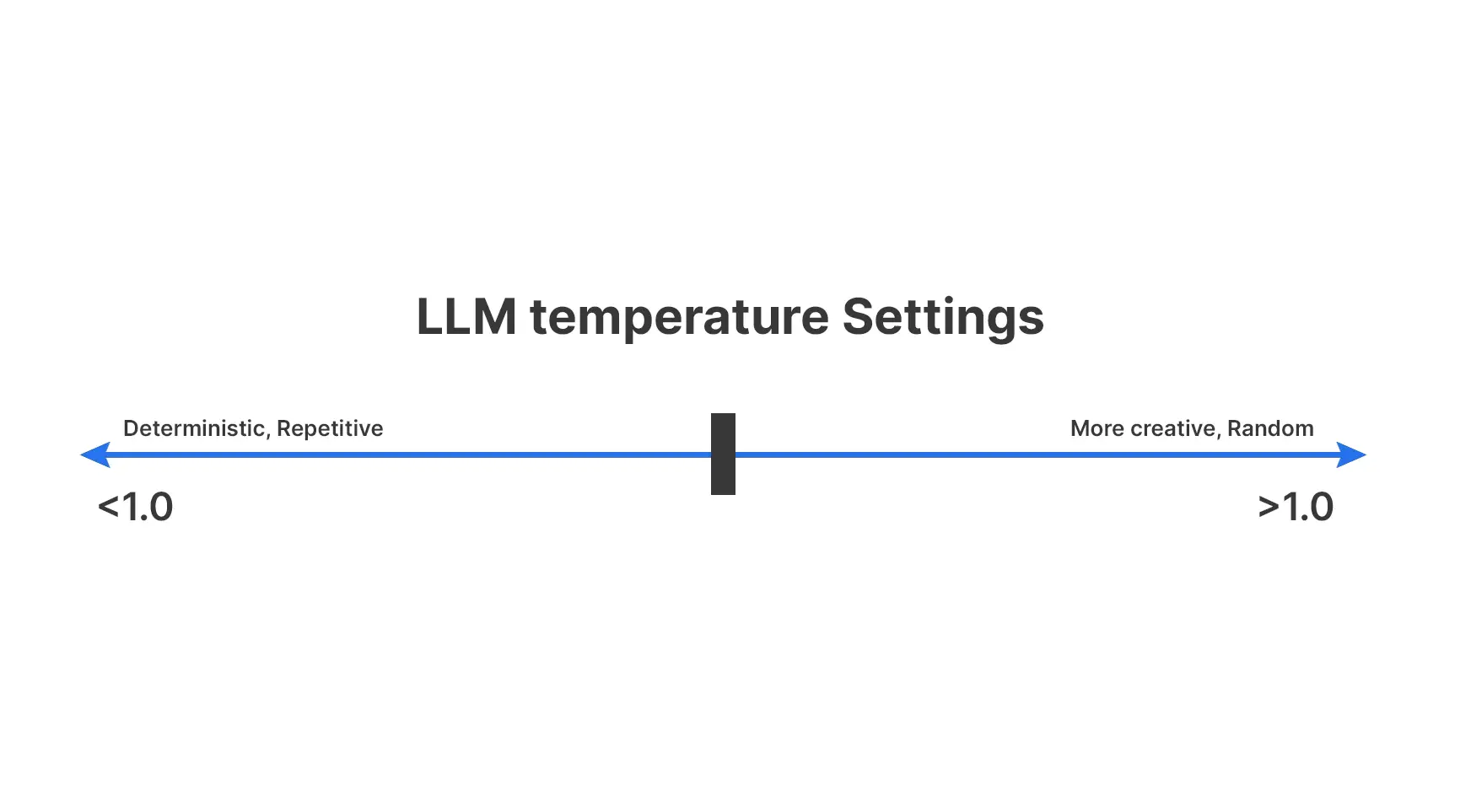
Q11. What is the role of temperature in text generation?
A. Temperature controls how much randomness an LLM allows when choosing the next token. This directly influences whether outputs stay conservative and predictable or become diverse and creative.
For temperature the rule of thumb is as follows:
- Low temperature favors safer, common tokens
- Higher temperature increases variation
- Very high values can hurt coherence
Temperature tunes style, not correctness. It determines how much emphasis should be given towards a problem.
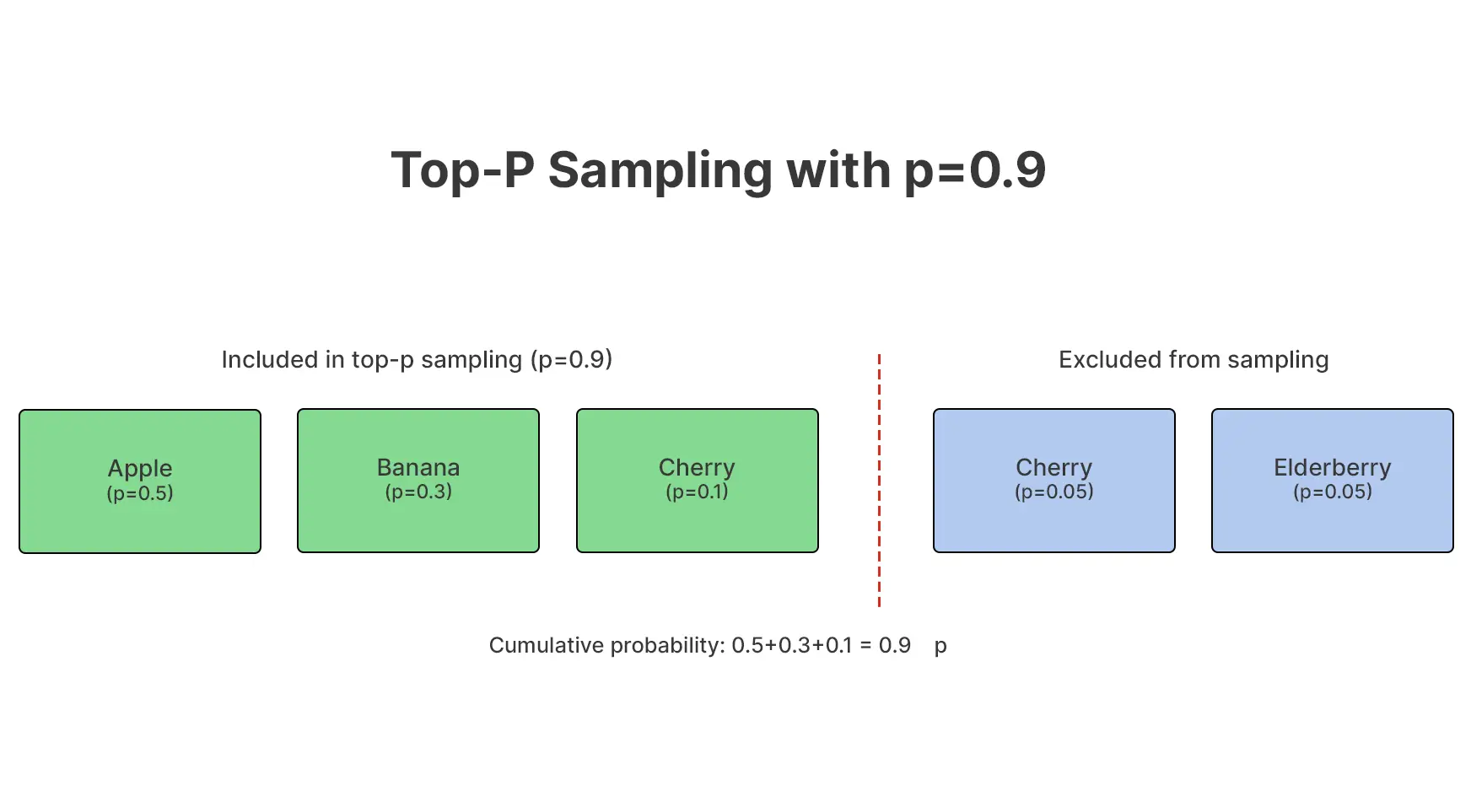
Q12. What is top-p (nucleus) sampling, and why is it used?
A. Top-p sampling limits token selection to the smallest set whose cumulative probability exceeds a threshold, allowing the model to adaptively balance coherence and diversity instead of relying on a fixed cutoff.
Why teams prefer it
- Adjusts dynamically to confidence
- Avoids low-quality tail tokens
- Produces more natural variation
It controls which options are considered, not how many.
Q13. What are embeddings, and why are they important?
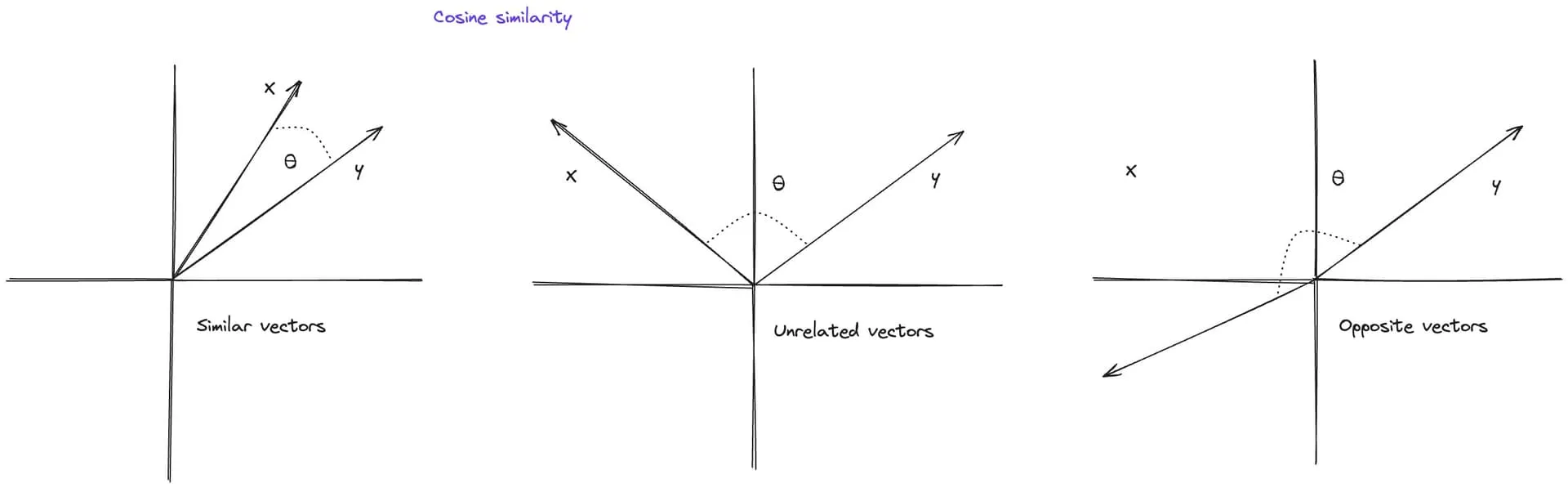
A. Embeddings convert text into dense numerical vectors that capture semantic meaning, allowing systems to compare, search, and retrieve information based on meaning rather than exact wording.
What embeddings enable
- Semantic search
- Clustering similar documents
- Retrieval-augmented generation
They let machines work with meaning mathematically.
Q14. What is a vector database, and how does it work with LLMs?
A. A vector database stores embeddings and supports fast similarity search, making it possible to retrieve the most relevant context and feed it to an LLM during inference.
Why this matters
- Traditional databases match keywords
- Vector databases match intent
- Retrieval reduces hallucinations
This turns LLMs from guessers into grounded responders.
Q15. What is prompt injection, and why is it dangerous?
A. Prompt injection occurs when user input manipulates the model into ignoring original instructions, potentially leading to unsafe outputs, data leakage, or unintended actions.
Typical risks
- Overriding system prompts
- Leaking internal instructions
- Triggering unauthorized behavior
LLMs follow patterns, not authority. It’s like altering the hardwired protocols that were set in stone for an LLM.
Q16. Why are LLM outputs non-deterministic?
A. LLM outputs vary because generation relies on probabilistic sampling rather than fixed rules, meaning the same input can produce multiple valid responses.
Key contributors
- Temperature
- Sampling strategy
- Random seeds
It’s not a definite set of steps that are followed that leads to a conclusion. On the flipside, its a path to a destination, which can vary.
Quick comparison
| Concept | What it controls | Why it matters |
| Temperature | Randomness of token choice | Affects creativity vs stability |
| Top-p | Token selection pool | Prevents low-quality outputs |
| Embeddings | Semantic representation | Enables meaning-based retrieval |
| Vector DB | Context retrieval | Grounds responses in data |
Q17. What is quantization in LLM deployment?
A. Quantization reduces model size and inference cost by lowering numerical precision of weights, trading small accuracy losses for significant efficiency gains.
Why teams use it
- Faster inference
- Lower memory usage
- Cheaper deployment
It optimizes feasibility, not intelligence.
Q18. What is Retrieval-Augmented Generation (RAG)?
A. RAG is a technique where an LLM pulls information from an external knowledge source before generating an answer, instead of relying only on what it learned during training.
What actually happens
- The system converts the user query into an embedding.
- The system retrieves relevant documents from the vector database.
- The system injects that context into the prompt.
- The LLM answers using both the prompt and retrieved data
Why it matters
Once LLMs are trained, they can’t be updated. RAG gives them access to live, private, or domain-specific knowledge without retraining the model. This is how chatbots answer questions about company policies, product catalogs, or internal documents without hallucinating.
Q19. What is model fine-tuning vs prompt engineering?
A. Both aim to shape model behavior, but they work at different levels.
| Aspect | Prompt Engineering | Fine-tuning |
| What it changes | What you ask the model | How the model behaves internally |
| When it happens | At runtime | During training |
| Cost | Cheap | More expensive |
| Speed to apply | Fast | Slow |
| Stability | Breaks easily when prompts get complex | Much more stable |
| Best used when | You need quick control over one task | You need consistent behavior across many tasks |
What this really means: If you want the model to follow rules, style, or tone more reliably, you fine-tune. If you want to guide one specific response, you prompt. Most real systems use both.
Q20. Why do LLMs sometimes hallucinate?
A. Hallucinations happen because LLMs aim to produce the most likely continuation of text, not the most accurate one.
Why it occurs
- The model does not check facts
- It fills gaps when knowledge is missing
- It is rewarded for sounding confident and fluent
If the model does not know the answer, it still has to say something. So it guesses in a way that looks plausible. That is why systems that use retrieval, citations, or external tools are much more reliable than standalone chatbots.
Conclusion
Large language models can feel intimidating at first, but most interviews don’t test depth. They test clarity. Understanding the basics, how LLMs work, where people use them, and where they fall short often gives you enough to respond thoughtfully and confidently. With these common questions, the goal isn’t to sound technical. It’s to sound informed.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.





