Large language models are great. We all can agree to that. They’ve been a cornerstone of modern industry and are increasingly impacting more and more domains.
With constant upgrades and improvements to the architecture and capabilities of language models, one might think – That’s it! Alas… A recent development under the name of RLM or Recursive language models, have taken the centerstage now.
What is it? How does it relate to LLMs? And how does it push the frontier of AI? We’ll find out in this article which dissects this latest technology in an accessible manner. Let’s begin by going over the issues that plague current LLMs.
Table of contents
A Fundamental Problem
LLMs have an architectural limit. It is called Token Window. This is the maximum number of tokens the model can physically read in one forward pass, determined by the transformer’s positional embeddings + memory. If the input is longer than this limit, the model can’t process it. It’s like trying to load a 5GB file into a 500MB RAM program. It leads to an overflow! Here are the token windows of some of the popular models:
| Model | Max Token Window |
| Google Gemini (latest) | 1,000,000 |
| OpenAI GPT-5 (latest) | 400,000 |
| Anthropic Claude (latest) | 200,000 |
Usually, the bigger the number, the better the model… Or is it?
Context Rot: The Hidden Failure Before the Limit
Here’s the catch. Even when a prompt fits inside the token window, model quality quietly degrades as the input grows longer. Attention becomes diffuse, earlier information loses influence, and the model starts missing connections across distant parts of the text. This phenomenon is known as context rot.
So although a model may technically accept 1 million tokens, it often cannot reason reliably across all of them. In practice, performance collapses long before the token window is reached.
Context Window

Context window is how much information the model can actually use well before performance collapses. This number changes based on the complexity of the prompt and the type of data that is processed. The effective context window of an LLM is much smaller than the token window. And unlike the token window, which is more or less definite, the context window changes with the complexity of the prompt. This is demonstrated by poor performance of large token window LLMs in reasoning tasks, as it requires retaining almost all of the information being fed concurrently.
This is a problem. Long context windows and consequently token windows are desirable, but loss of context (due to their length) is unavoidable…or at least it was.
Recursive Language Models: To the rescue
Despite the name, RLMs aren’t a new model class like LLM, VLM, SLM etc. Instead it is an inference strategy. A solution to the problem of context rot in long prompts. RLMs treat long prompts as part of an external environment and allows the LLM to programmatically examine, decompose, and recursively call itself over snippets of the prompt.
This effectively makes the context window several times bigger than usual. It does so in a similar fashion:
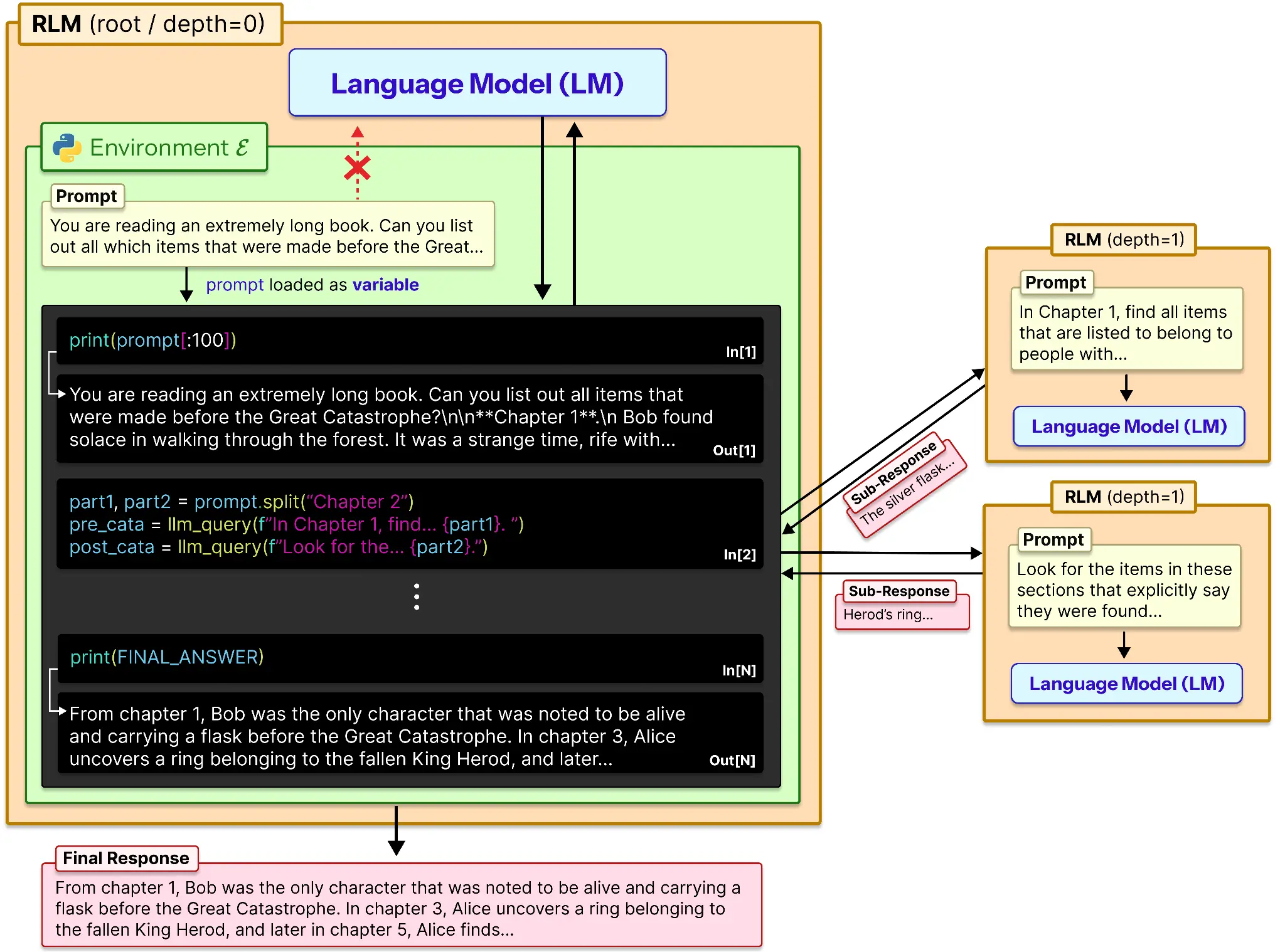
Conceptually, RLM gives an LLM external memory and a way to operate on it. Here is how it works:
- The prompt gets loaded in a variable.
- This variable is spliced depending upon the memory or a hard-coded number.
- That data gets sent to the LLM and its output is saved for reference.
- Similarly all the chunks of the prompt are processed individually and their outputs are recorded.
- This list of outputs is used to produce the final response of the model.
A sub-model like o3-mini or some other model which is handy, could be used for helping the model to summarize or reason-locally in a sub-prompt.
Isn’t this…Chunking?
At first glance, this might look like glorified chunking. But it’s fundamentally different. Traditional chunking forces the model to forget earlier pieces as it moves forward. RLM keeps everything alive outside the model and lets the LLM selectively revisit any part whenever needed. It’s not summarizing memory — it’s navigating it.
What Problems RLM Finally Solves
RLM unlocks things normal LLMs consistently fail at:
- Reasoning over massive data: Instead of forgetting earlier parts, the model can revisit any section of huge inputs.
- Multi-document synthesis: It pulls evidence from scattered sources without hitting context limits.
- Information-dense tasks: Works even when answers depend on nearly every line of the input.
- Long structured outputs: Builds results outside the token window and stitches them together cleanly.
In short: RLM lets LLMs handle scale, density, and structure that break traditional prompting.
The Tradeoffs
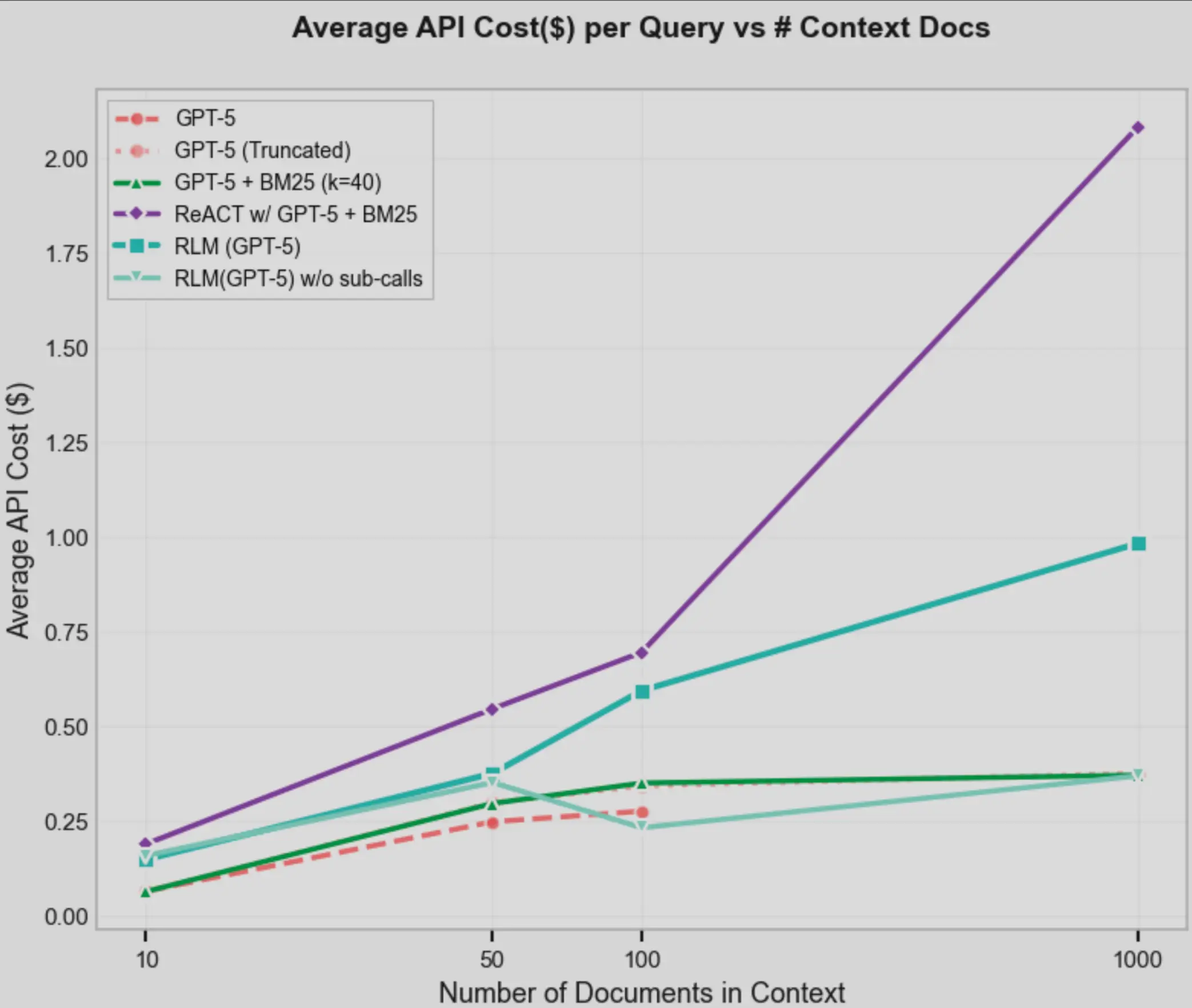
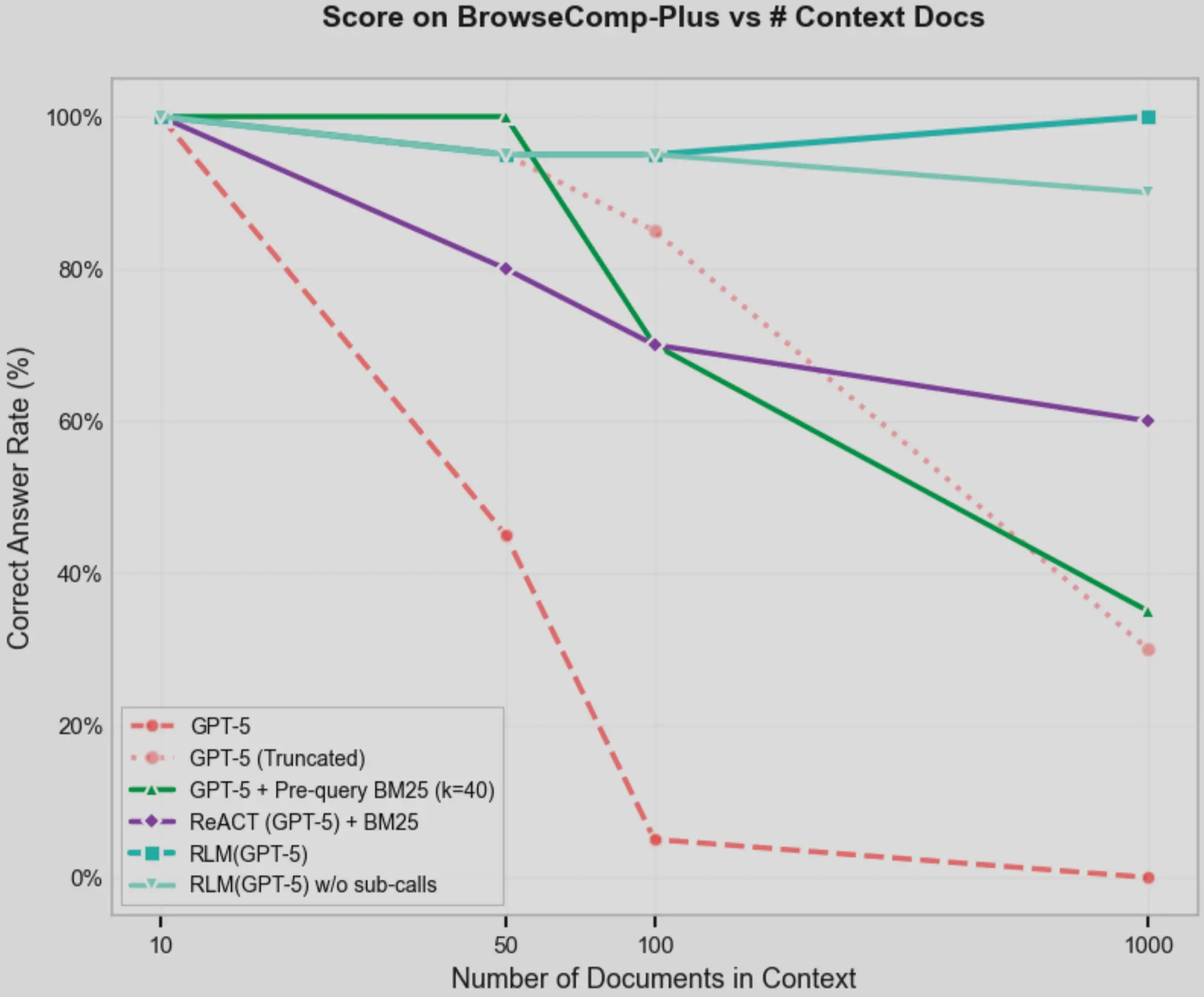
With all that RLM solves, there are a few downsides to it as well:
| Limitation | Impact |
| Prompt mismatch across models | Same RLM prompt leads to unstable behavior and excessive recursive calls |
| Requires strong coding ability | Weaker models fail to manipulate context reliably in the REPL |
| Output token exhaustion | Long reasoning chains exceed output limits and truncate trajectories |
| No async sub-calls | Sequential recursion significantly increases latency |
In short: RLM trades raw speed and stability for scale and depth.
Conclusion
Scaling LLMs used to mean more parameters and larger token windows. RLM introduces a third axis: inference structure. Instead of building bigger brains, we’re teaching models how to use memory outside their brains — just like humans do.
It’s a holistic view. It isn’t more of what was before like usual. Rather a new take on the conventional approaches of model operation.
Frequently Asked Questions
Q1. What problem do Recursive Language Models solve?
A. They overcome token window limits and context rot, allowing LLMs to reason reliably over extremely long and information-dense prompts.
Q2. Are RLMs a new type of language model?
A. No. RLMs are an inference strategy that lets LLMs interact with long prompts externally and recursively query smaller chunks.
Q3. How are RLMs different from simple chunking?
A. Traditional chunking forgets earlier parts. RLM keeps the full prompt outside the model and revisits any section when needed.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.





