If you’ve spent the last year jumping between tabs, you’ve felt it. The gap between ChatGPT vs Claude isn’t about benchmarks anymore, it’s about identity. We are no longer choosing between “smart” and “smarter.” We are choosing between a multimodal powerhouse and a faithful reasoning engine.
This leaves users choosing between two very different product philosophies: OpenAI’s tool-rich, multimodal ecosystem vs Anthropic’s more reasoning-focused, safety-conscious approach. This article will help you make that choice. The real difference isn’t what these models can do. It’s where they start breaking.
Table of contents
ChatGPT: The Old Guard
ChatGPT’s influence in the AI ecosystem can’t be understated. If you’ve heard of large language models, you’ve probably heard of ChatGPT. Pioneering modern day AI-powered chatbots, OpenAI became a household name with its introduction of ChatGPT in 2022.
Beyond the initial release, ChatGPT continued to evolve through successive model upgrades like GPT-4, GPT-4 Turbo, and GPT-4o. With each iteration, OpenAI expanded its capabilities beyond simple conversation into areas like image generation, file analysis, browsing, and multimodal interaction.
This steady progression turned ChatGPT from a “chatbot” into a widely used productivity tool.
| Model | Release | What it does best |
|---|---|---|
| GPT-3.5 | 2023 | Fast conversational AI for everyday tasks like writing, explanations, and basic coding. |
| GPT-4 | 2023 | Major improvement in reasoning, coding ability, and long-form analytical tasks. |
| GPT-4 Turbo | Late 2023 | Faster and cheaper GPT-4 variant with larger context windows for documents and workflows. |
| 4o-series reasoning models (o1, o3 etc.) | 2024–2025 | Specialized models designed for deeper reasoning, mathematics, research, and complex problem solving. |
| GPT-5 family | 2025–2026 | Next-generation models focusing on stronger reasoning, improved reliability, and more advanced multimodal capabilities across tools and workflows. |
Claude: The Thinking Engine
Claude emerged as one of the strongest alternatives to ChatGPT in late 2023. Introduced as a safety-oriented LLM, the Claude family quickly gained attention for its ability to handle long documents and structured tasks with unmatched consistency.
Unlike ChatGPT, Claude doesn’t offer one-size-fits-all models. Instead, their models are spread across 3 families:
- Opus — Anthropic’s most powerful models designed for complex reasoning, deep analysis, and advanced coding tasks.
- Sonnet — Balanced models that offer strong reasoning and writing ability while remaining fast enough for everyday use.
- Haiku — Lightweight, high-speed models optimized for quick responses and high-volume applications.
Each family is designed for a different balance of capability, speed, and cost, allowing developers to choose the model that best fits their workload.
| Model Family | What it does best |
|---|---|
| Claude 2 | Early long-context model focused on document analysis, summarization, and safer conversational AI. |
| Claude 3 (Haiku / Sonnet / Opus) | Major capability jump. Haiku = fast lightweight model, Sonnet = balanced performance, Opus = strongest reasoning and analysis. |
| Claude 3.5 (Sonnet) | Improved reasoning, stronger coding ability, better instruction following and writing quality. |
| Claude 4 (Sonnet / Opus) | Frontier models designed for advanced reasoning, agentic workflows, and complex coding tasks. |
| Claude 4.6 | Refined Claude 4 generation with improved precision, stronger coding, better tool use, and more reliable long-task execution. |
Hands-On
No amount of metrics or praise would persuade someone to use a model. It’s how well it performs in a real-world task that tips the scale. For that we’d be putting the flagship models from each family to test, across the following tasks:
- Email Refinement
- Code Debugging Test
- Structured Reasoning
- Strict Instruction Following
Task 1 – Email Refinement
Purpose: Tone correction and clarity improvement in a real-world writing task.
Hi Mark,
Just following up again on the dataset you said you’d send last week. We’re still waiting on it and it’s blocking the analysis on our side. The client meeting is coming up soon and without the data we can’t really move forward.
Also I noticed that some of the files from the previous batch were missing columns, so we might need a corrected version of that too. Could you check that when you send the updated data?
Let me know when you can send it over.
Thanks
Ronald
Prompt
Rewrite the email below so it sounds more professional and clear.
Requirements:
• Keep the message polite but firm
• Improve grammar and clarity
• Keep the email concise
• Preserve the original intent
• Do not significantly increase the length
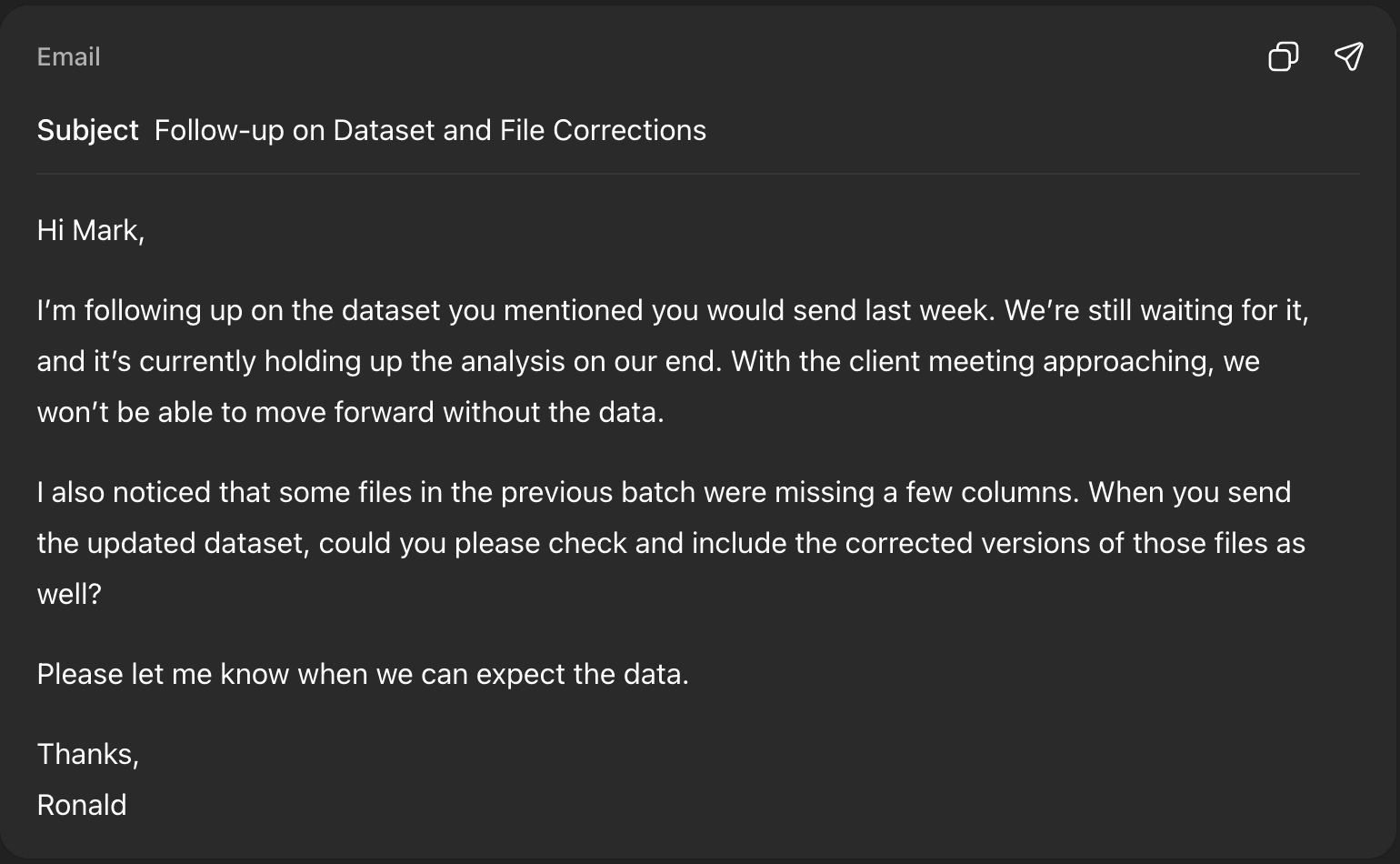
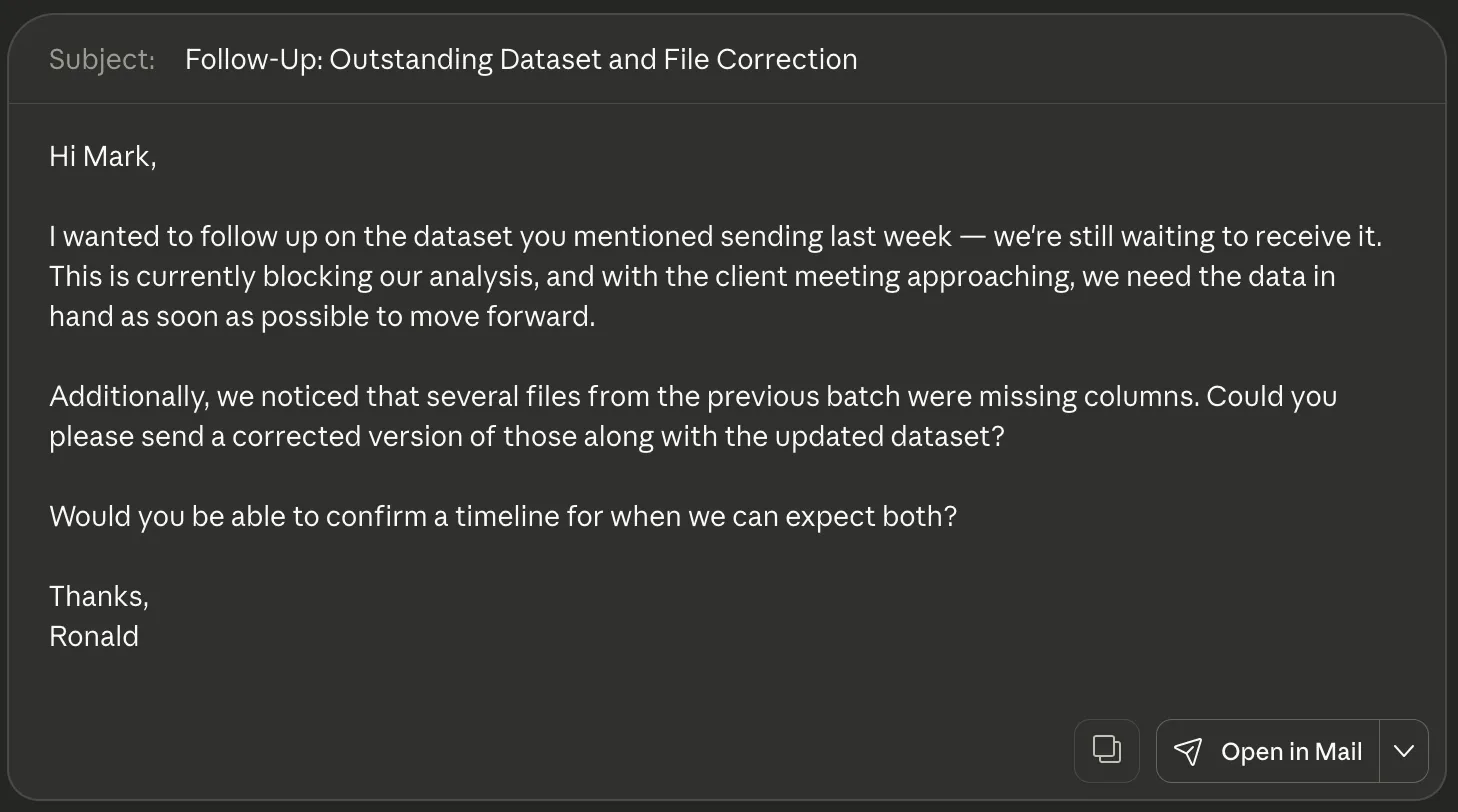
Verdict: Both the responses were great. You could pick either as the solution for this particular problem. I would prefer Claude’s response as it offers the option to send this via mail directly using the Open in Mail option (MCP integration). Otherwise, both models responded acceptably.
Winner: Both
Task 2 – Code Debugging Test
Purpose: Tests logical reasoning and coding accuracy.
Python Script:
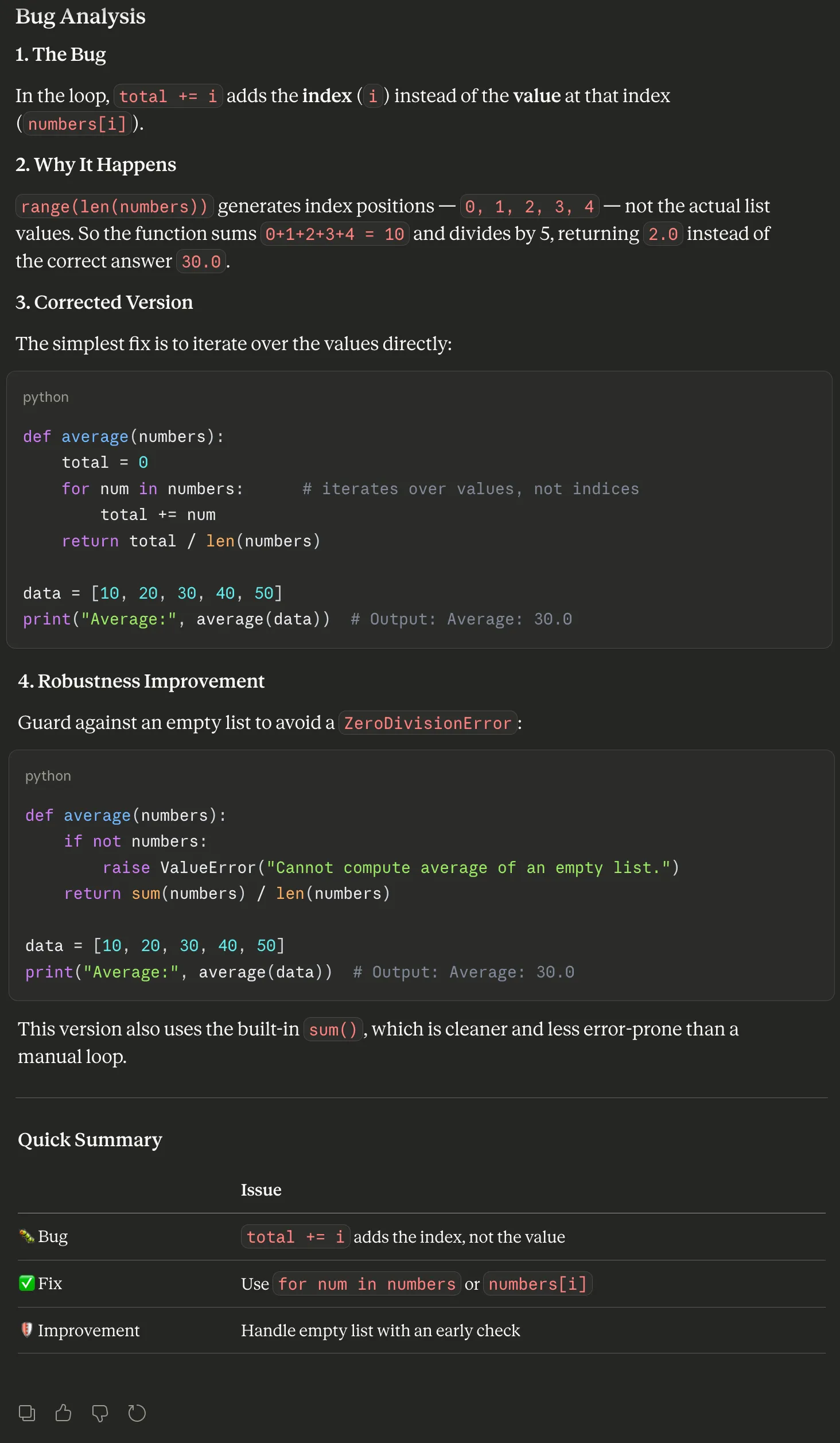
def average(numbers):
total = 0
for i in range(len(numbers)):
total += i
return total / len(numbers)
data = [10, 20, 30, 40, 50]
print("Average:", average(data))Prompt
The following Python script is supposed to calculate the average of a list of numbers.
1. Identify the bug
2. Explain why it happens
3. Provide a corrected version of the program
4. Suggest one improvement to make the function more robust
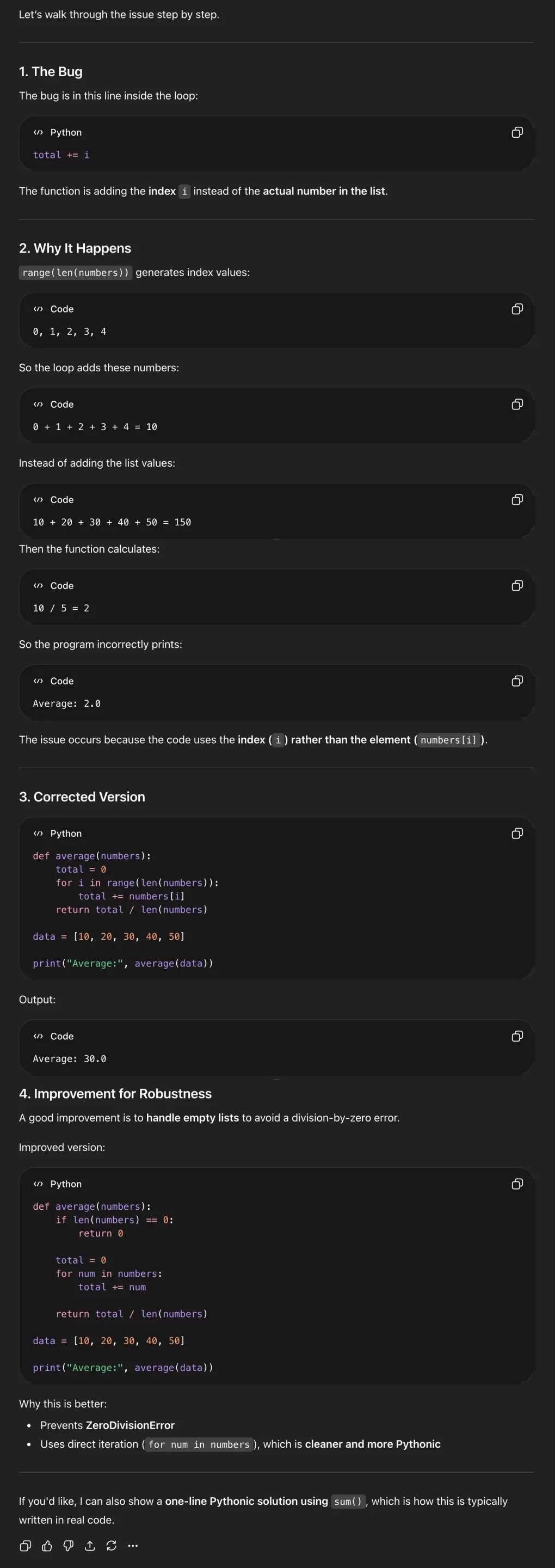
Verdict: ChatGPT took the entire token window for answering the query! The answer is too detailed for a problem this simple. But this might be preferred if the user is a beginner.
Claude took the concise route. Then answer is to the point. The recommendation are down to the exact code statements. And the recommendation are tech savvy (the inline average using sum and len method is exquisite).
If you are a beginner in the programming, you’d appreciate the detailing of ChatGPT’s response. Veteran programmers will prefer Claude’s response. I’d prefer Claude’s response.
Winner: Both
Task 3 – Structured Reasoning
Purpose: Tests multi-step reasoning and decision-making.
Dataset
| Tier | Users | Monthly Price | Churn Rate |
|---|---|---|---|
| Basic | 12,000 | $5 | 18% |
| Standard | 7,500 | $12 | 9% |
| Premium | 2,000 | $25 | 3% |
Prompt
You are a product strategist evaluating subscription tiers.
Using the dataset above:
1. Calculate the estimated monthly revenue for each tier.
2. Analyze the churn rates.
3. Recommend whether any tier should be discontinued.
4. Provide a clear step-by-step explanation for your decision.
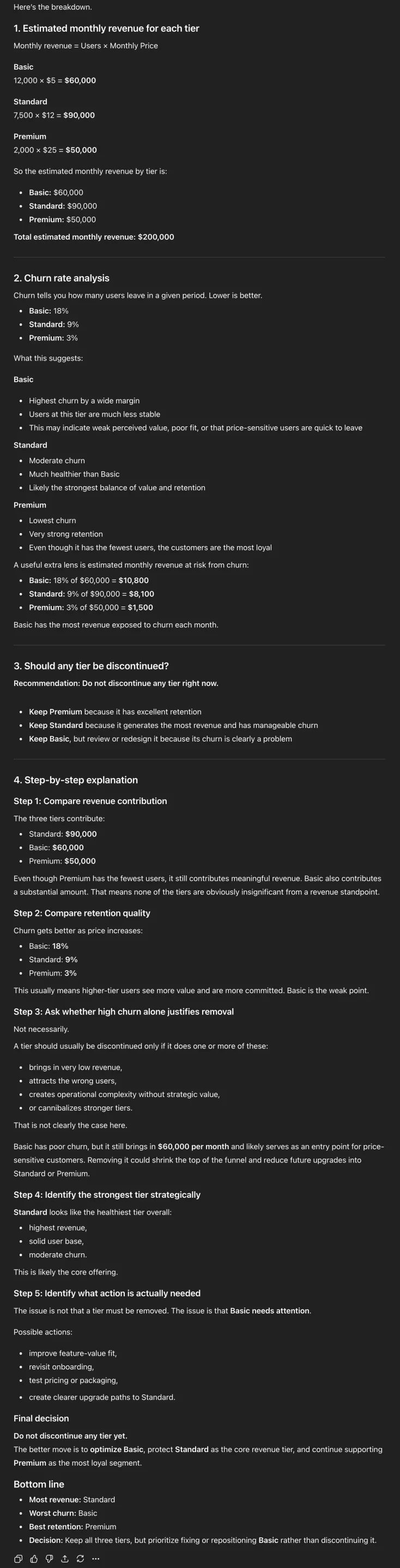

Verdict: ChatGPT gave us another ridiculously verbose response. The step-by-step explanation part is unnecessarily long. But this time, the preferred response is a lot more obvious.
Claude not only answered the query in its characteristic brief manner, but also added illustrations within the response. This greatly enhances the readability of the response, which otherwise is text heavy.
Winner: Claude
Task 4 – Strict Instruction Following
Purpose: Does the model drift when you pile on constraints.
Prompt
Write a product launch announcement for a new note-taking app.
Requirements:
• Exactly 120 words
• Use a confident but not hype-heavy tone
• Mention only 3 features
• Include the phrase: designed for focused work
• End with a single-sentence call to action

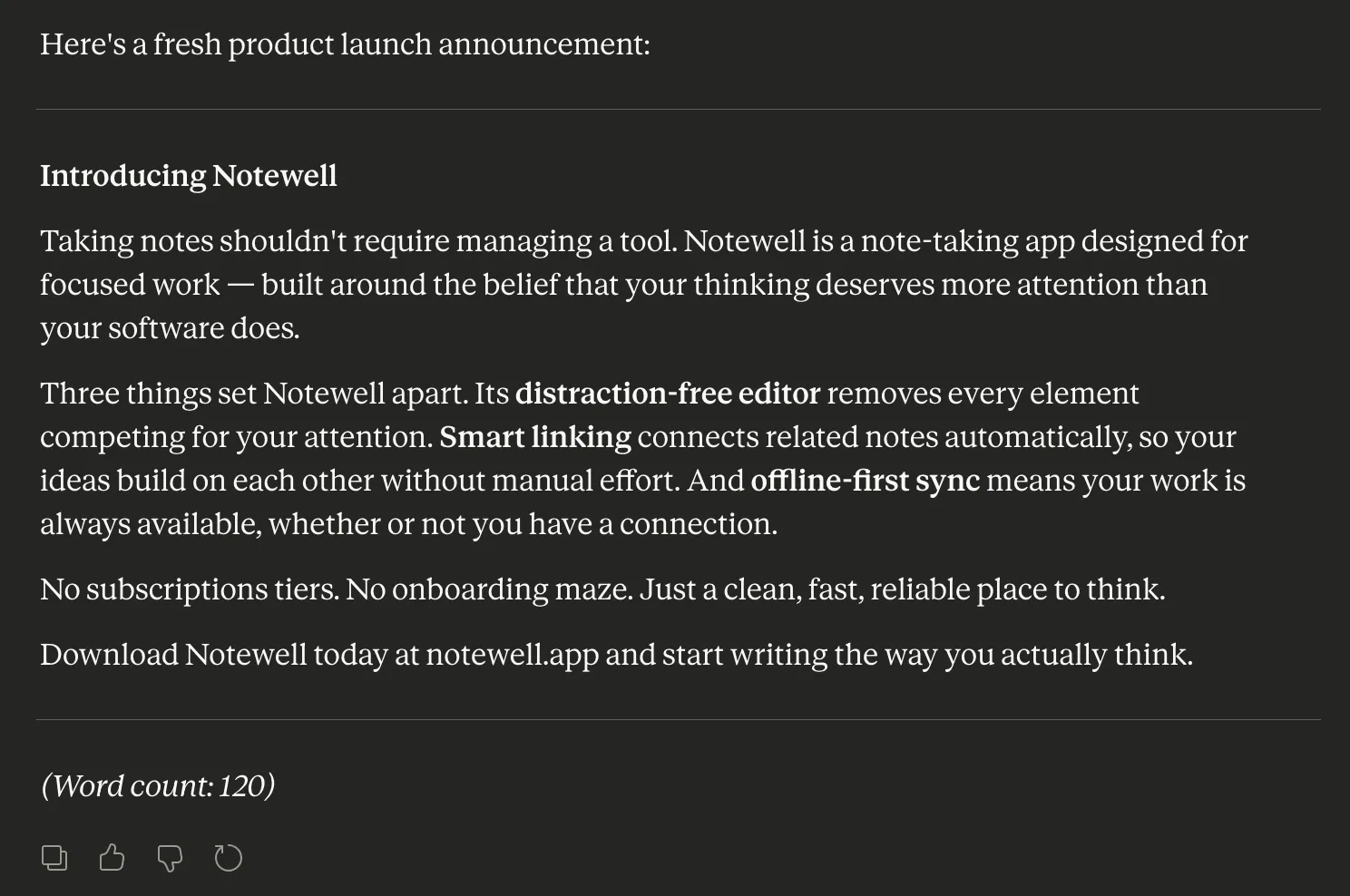
Verdict: Awful response by ChatGPT. A paragraph without any text emphasis or formatting makes it a chore to read it. It is hard to realise the important parts of the text from just a glance.
Claude gave a structured response with clear text highlighting that makes it easy to use it as an email as well as a presentation (wider usage scope).
Winner: Claude
Final Verdict
Scoring them across tasks:
| Task | ChatGPT | Claude |
|---|---|---|
| Email Refinement | ✓ | ✓ |
| Code Debugging | ✓ | ✓ |
| Structured Reasoning | – | ✓ |
| Strict Instruction Following | – | ✓ |
| Overall Score | 2 | 4 |
Claude came out as the winner in our tasks. But this test wasn’t definitive! This is because the models families aren’t 1:1 and thereby have some architectural differences. The most obvious case for this is the lack of image generation capabilities in Claude models. Now if I were to compare the models in that regard, ChatGPT would be the default winner.
Therefore, the choice of model solely depends on the use case.
Choose ChatGPT if you:
- want a broader tool ecosystem
- want to work with images
- use AI heavily for coding
- prefer faster, more flexible responses
Choose Claude if you:
- work with long documents often
- care about structured writing
- want stronger step-by-step reasoning
- prefer a more careful model personality
Note: ChatGPT Plus and Claude Plus were used for the tasks.
Cost of Intelligence
Both the Anthropic and OpenAI offers models that can be accessed for free. But the free experience is subpart. From long wait times to small usage limits the paid versions are almost a necessity for a good experience.
| Feature | ChatGPT Plus ($20/mo) | Claude Pro ($20/mo) |
|---|---|---|
| Model Access | Full GPT-5.4 & Reasoning (o1/o3) | Claude 4.6 (Opus & Sonnet) |
| Message Caps | High (~150 msgs / 3hrs) | Tight (5x Free tier; roughly 45 msgs / 5hrs) |
| The Wall | Drops to GPT-5.2 Instant (fast but weaker) | Hard lockout or extreme wait times |
| Unique Perk | Multimodal Suite: Sora (Video) & DALL-E | Developer Tools: Claude Code & MCP Integration |
The Limitations
The ChatGPT and Claude models have a lot of good about them. But they aren’t without their flaws. Here are some of the most noticeable problems that Claude and ChatGPT models have:
ChatGPT Limitations
Free tier gets capped fast
Flagship-model access on free accounts is limited, and once you hit the cap, chats fall back to a smaller model.
Too much product sprawl
ChatGPT has become a broad ecosystem, but that also means model names, plan benefits, and tool access can feel messy and shift over time.
Privacy is not the cleanest by default
For individual services, OpenAI may use your content to improve models unless you turn that off in data controls.
Power features are tier-dependent
The product does a lot, but the best experience is increasingly gated behind paid plans and higher usage tiers.
Claude Limitations
No native image generation
Claude can understand images, but it does not generate image or video outputs as a native product capability.
Free usage feels restrictive
Claude’s free plan is governed by a conversation budget, which can make usage limits feel tighter and less predictable.
Best features are pushed into paid plans
Research, broader model access, and higher-usage workflows sit behind Pro or Max, so the free experience can feel narrow.
Smaller overall product surface
Claude is excellent at reasoning and writing, but it still offers a less expansive consumer feature set than ChatGPT’s tool-heavy ecosystem.
Conclusion
If you’ve made all the way here, you must have realized the both OpenAI and Anthropic’s model offerings are quite good. The choice of model is the one that matches how you work.
- Claude specialises in coding and reasoning, which makes it ideal for programmers and scientists.
- ChatGPT is a jack-of-all-trades good at a several tasks, and is therefore suitable for the general public.
Consider the limitations of the model while making the choice.
Read more: How to Switch from ChatGPT to Claude Without Losing Any Context or Memory
Frequently Asked Questions
Q1. What is the difference between ChatGPT and Claude?
A. ChatGPT focuses on tools and multimodal capabilities, while Claude prioritizes structured reasoning, clarity, and consistent instruction following.
Q2. Which is better for coding: ChatGPT or Claude?
A. Both are strong for coding. ChatGPT offers detailed explanations, while Claude gives concise, precise solutions preferred by experienced developers.
Q3. Should I use ChatGPT or Claude for everyday tasks?
A. Use ChatGPT for versatility and tools. Choose Claude for structured writing, long documents, and reliable step-by-step reasoning.
I specialize in reviewing and refining AI-driven research, technical documentation, and content related to emerging AI technologies. My experience spans AI model training, data analysis, and information retrieval, allowing me to craft content that is both technically accurate and accessible.






