Retrieval-Augmented Generation (RAG) technology almost immediately became the standard in intelligent applications. This was a result of the quickly developing field of artificial intelligence that combined large language models and external knowledge bases with different real-time access methods. RAG implementation of the traditional kind poses major difficulties: complex vector database setups, intricate embedding pathways, orchestration of infrastructure, and the necessity for pulling in the DevOps specialists.
Here are some of the main drawbacks of RAG’s traditional development:
- Infrastructure setup and configuration can take weeks.
- Vector database solutions can be extremely costly.
- There is a need for integration of multiple tools, which creates complexity.
- Developers will face a steep learning curve.
- Challenges come up regarding production deployment.
Radically new RAG development technique NyRAG, a significant advance in RAG development that simplifies the entire process into a simple, configuration-driven workflow, is now presented. Regardless of whether you are creating AI-enabled customer support bots, internal knowledge management systems, or semantic search engines, NyRAG is going to speed up your journey from idea to production.
Table of contents
What is NyRAG?
NyRAG is a Python-based open-source framework that redefines the development of Retrieval-Augmented Generation (RAG). It takes away the burden of complicated infrastructure setup and makes it possible for you to roll out smart chatbots and semantic search systems in no time at all. Sometimes, as quickly as within minutes.
Key Features of NyRAG
- No-code configuration technique
- Web crawling + document processing
- Local Docker or Vespa Cloud deployment
- Integrated chat interface
- Hybrid search with Vespa engine
How NyRAG Works: The 5-Stage Pipeline
Stage 1: Query Enhancement
Initially, an AI model produces several different searches based on your question to enhance retrieval coverage.
Stage 2: Embedding Generation
Then, the queries undergo a transformation into vector embeddings with the use of SentenceTransformer models.
Stage 3: Vespa Search
After that, the system carries out the nearest-neighbor searches on the indexed chunks.
Stage 4: Chunk Fusion
Consequently, the outputs are combined, deduplicated, and ranked according to their relevance score.
Stage 5: Answer Generation
Finally, the leading chunks are transferred to an AI model (through OpenRouter) to produce justified answers.
Getting Started with NyRAG
The Prerequisites for NyRAG are:
- Python with 3.10 version or higher
- Docker Desktop (if you are working in local mode)
- An OpenRouter API key
The commands to install NyRAG are:
- Using the pip command:
pip install nyrag- Using uv command (recommended)
uv pip install -U nyragNow, let’s try to understand the dual modes of NyRAG, namely, web crawling and document processing.
Web Crawling Mode
- Honors robots.txt
- Subdomains included by default
- URL exclusion lists
- User agents are customizable (Chrome, Firefox, Safari, Mobile)
Document Processing Mode
- Saves PDF, DOCX, TXT, Markdown
- Folder scanning in a recursive way
- Filtering based on file size and type
- Capabilities of managing intricate document architectures
Hands-On Task 1: Web-based Knowledge Base
In this task, we’ll be building a chatbot that will answer our questions using documentation from the company website.
Step 1: Setting up the environment
Follow the commands below to set up the environment for your local system
mkdir nyrag-website-demo
cd nyrag-website-demo
uv venv
source .venv/bin/activate
uv pip install -U nyrag
Step 2: Create Configuration
Using the file ‘company_docs_config.yml’, we’ll define the configurations:
name: company_knowledge_base
mode: web
start_loc: https://docs.yourcompany.com/
exclude:
- https://docs.yourcompany.com/api-changelog/*
- https://docs.yourcompany.com/legacy/*
crawl_params:
respect_robots_txt: true
follow_subdomains: true
aggressive_crawl: false
user_agent_type: chrome
rag_params:
embedding_model: sentence-transformers/all-MiniLM-L6-v2
embedding_dim: 384
chunk_size: 1024
chunk_overlap: 100Step 3: Crawl & Index
Using the commands below, we’ll crawl the website, extract the text content, split it into chunks, generate the embeddings, which are then indexed into Vespa.
export NYRAG_LOCAL=1
nyrag --config company_docs_config.yml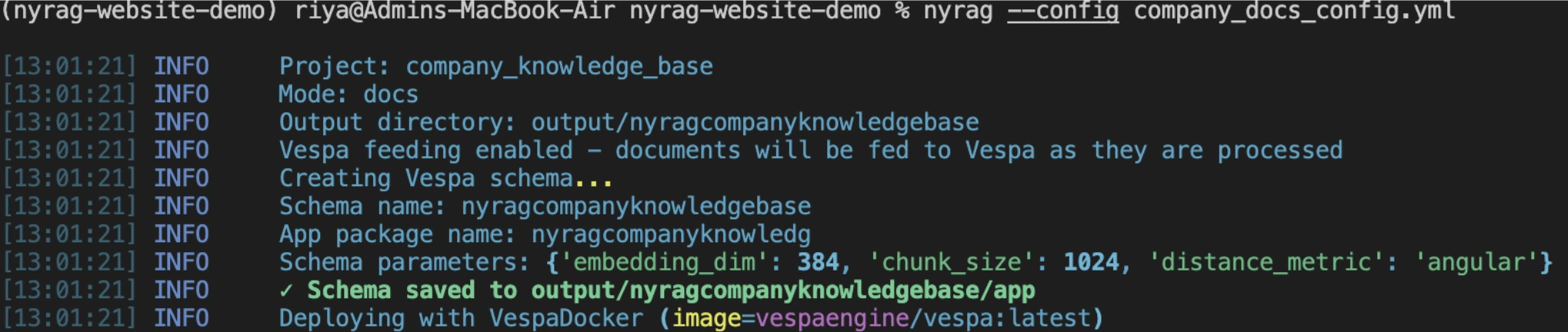
Step 4: Launch Chat Interface
Now, use the commands and launch the chat interface.
export NYRAG_CONFIG=company_docs_config.yml
export OPENROUTER_API_KEY=your-api-key
export OPENROUTER_MODEL=anthropic/claude-sonnet-4uvicorn nyrag.api:app –host 0.0.0.0 –port 8000
Step 5: Test your bot
You can try the following queries:
“How do I authenticate API requests?”

“What are the rate limits?”

“Explain the webhook configuration process.”

Comparison with other Frameworks
Let’s compare NyRAG with other frameworks to see what it’s best suited for:
| Framework | Pros | Cons | Best For |
|---|---|---|---|
| NyRAG | Zero-code, integrated pipeline | Less flexible architecture | Quick deployment |
| LangChain | Highly customizable | Requires coding | Complex workflows |
| LlamaIndex | Great documentation | Manual DB setup | Custom integrations |
| Haystack | Modular design | Steeper learning curve | Enterprise apps |
Use Cases of NyRAG
- Customer Support Chatbots: It is used to get instant responses and the most accurate ones. It also helps in lowering the number of support tickets.
- Internal Knowledge Management: It offers a faster and smoother introduction of new employees and provides a way to get information about employees through different departments.
- Research Assistants: It helps researchers in researching documents, pulling insights from them, and asking questions related to academic literature, providing concise accounts of extensive texts.
- Code Documentation Search: It increases the overall productivity of developers as both Virtual guides and API docs are indexed.
Conclusion
The division separating idea and production-ready RAG applications has become very thin. By using NyRAG, you are not simply incorporating a library; you’re obtaining a full RAG development platform that manages crawling, embedding, indexing, retrieval, and chat interfaces by default.
Whether you are making your first AI application or scaling your hundredth one, NyRAG is the provider of the success foundation. The issue is not whether RAG will change your application. Rather, it is how fast you are able to set it up.
Gen AI Intern at Analytics Vidhya
Department of Computer Science, Vellore Institute of Technology, Vellore, India
I am currently working as a Gen AI Intern at Analytics Vidhya, where I contribute to innovative AI-driven solutions that empower businesses to leverage data effectively. As a final-year Computer Science student at Vellore Institute of Technology, I bring a solid foundation in software development, data analytics, and machine learning to my role.
Feel free to connect with me at [email protected]






