Artificial intelligence is rapidly evolving. New models emerge nearly every day, with each one attempting to be the best. In this sea of similar models, we see something new every now and then. One of such models is the new Mistral Small 4. It is an innovative AI model that is not only going to be another choice in the plethora of AI models, but also attempts to be the model of your choice. No more multi-modeling on hatting, coding, and multifaceted thinking. Mistral Small 4 packages them into a single formidable and effective model.
It is not just about convenience. Mistral Small 4 applies the Mixture-of-Experts (MoE) clever design to give the performance of a 119-billion-parameter model, but runs at a fraction of the power required to execute any one task. This implies that it is quick, cheap, and even image discerning. In this guide, we will dissect what makes Mistral Small 4 tick, how it compares to the competition, and we will also take you through some real-life situations in which you can use it.
Table of contents
What’s New With Mistral Small 4?
Mistral Small 4 is unique due to the fact that it incorporates three different capabilities into one single and simple model. Previously, you could have had one AI to have a conversation, another one to engage in analytical work, and a third one to write code. Mistral Small 4 is made to cope with all that effortlessly. It can also serve as a general chat assistant, a coding expert, and a reasoning engine, all over the same endpoint.
Its Mixture-of-Experts (MoE) architecture is the secret of its efficiency – a group of 128 experts. Another advantage of the model is that it does not require all of them working on all of the problems; instead, the model is smart enough to pick the top four to work on the given task. This implies that the total number of parameters in the model is huge (at 119 billion), but only a few, between 6 and 6.5 billion, will be activated by a particular request. This makes it quick and lowers the cost of operation.
The main characteristics are the following:
- Multimodal Input: It knows both images and text, owing to its Pixtral vision element.
- Long Context Window: This has the ability to handle up to 256,000 tokens of information at a time hence it is applicable in the analysis of long documents.
- Open and Accessible: The weights of the model are under Apache 2.0 license, which permits commercial use. It is open-source and works via APIs and partner platforms.
- Performance Optimised: Mistral boasts of a 40 percent decrease in the amount of time taken to complete and 3 times more requests per second than its predecessor.
Under the Hood: Architecture and Specifications
Mistral Small 4 is a mixture of a text decoder and a vision encoder. On giving an image, the Pixtral vision system interprets the image and passes the information over to the text model that then produces a response. Such a design enables it to blend with visual information and textual prompts.
The following are some of the architectural details:
- Decoder Stack: 36 transformer layers, hidden size of 4096, and 32 attention heads.
- MoE Details: 128 experts, 4 of which are activated per token, with a shared expert component so that things are consistent.
- Vision Component: The Pixtral vision model contains 24 layers and images with a patch size of 14.
- Vocabulary: The model has a Tekken tokenizer with a rich vocabulary of 131,072 tokens to enable support for more than one language and complicated instructions.
Although the number of active parameters is low, the overall size of the model determines the memory requirements. The parameter model 119B has a large VRAM requirement; the 4-bit quantised version alone consumes around 60 GB, and a 16-bit version consumes almost 240 GB. This does not include the memory required in the KV cache of long-context tasks.
Benchmarks and Evaluation
Mistral Small 4 is not merely a smart design; it has figures that can support its performance arguments. Mistral focuses on the quality and efficiency, where the model is capable of delivering high-quality answers in a very narrow fashion. The resulting low latency and low cost in practice can be directly related to this emphasis on shorter outputs.
Efficiency: High Scores with Less Talk
On various benchmarks, a consistent trend exists: Mistral Small 4 contributes to or even beats the state-of-the-art models using a lot fewer words to do so.
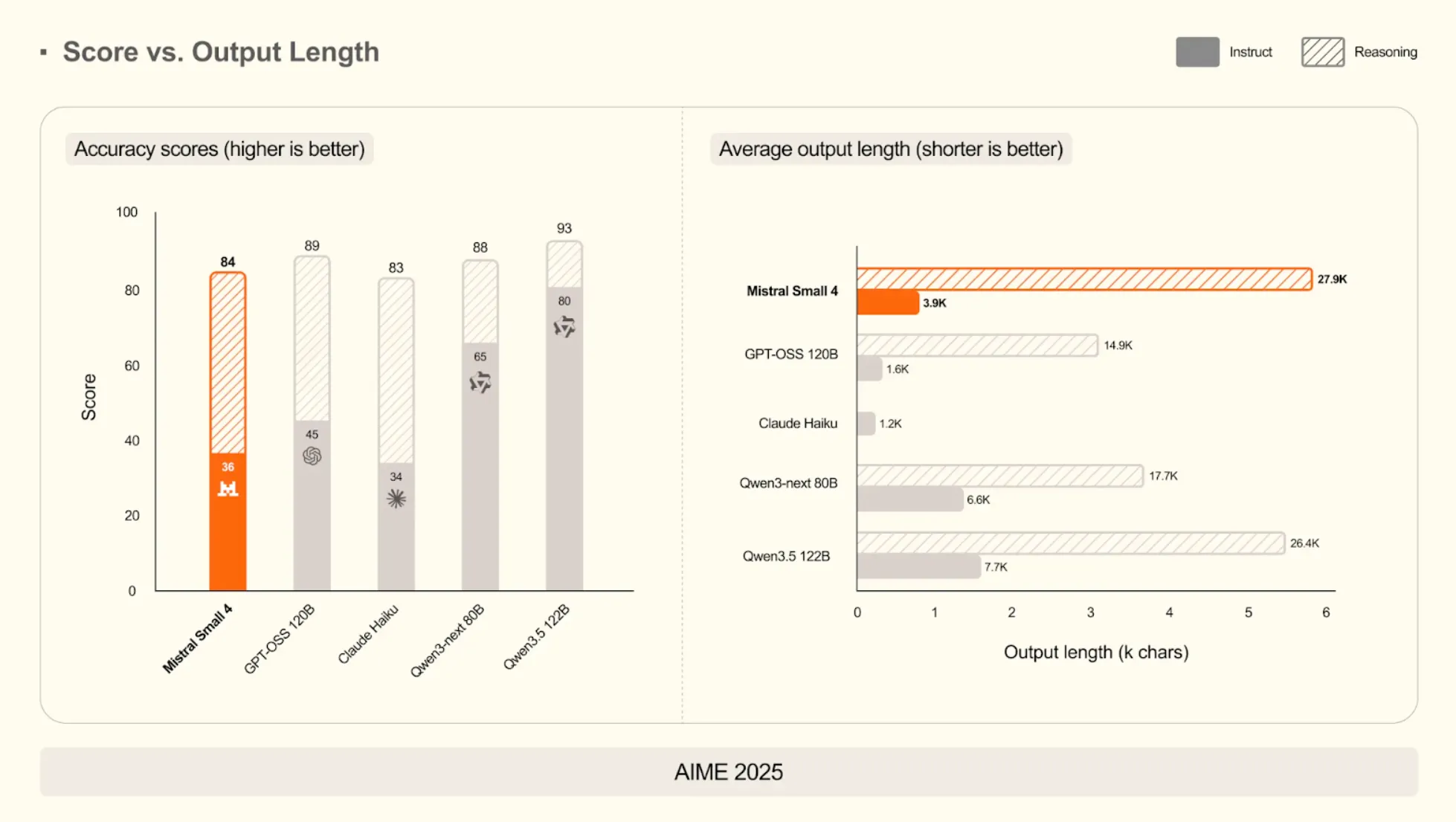
On Mathematical Reasoning (AIME 2025)
The score of the model in its reasoning mode is 93, which is equal to much bigger Qwen3.5 122B. But its average length of output in instruct mode is only 3,900 characters, which is a fraction of the almost 15,000 characters of GPT-OSS 120B.
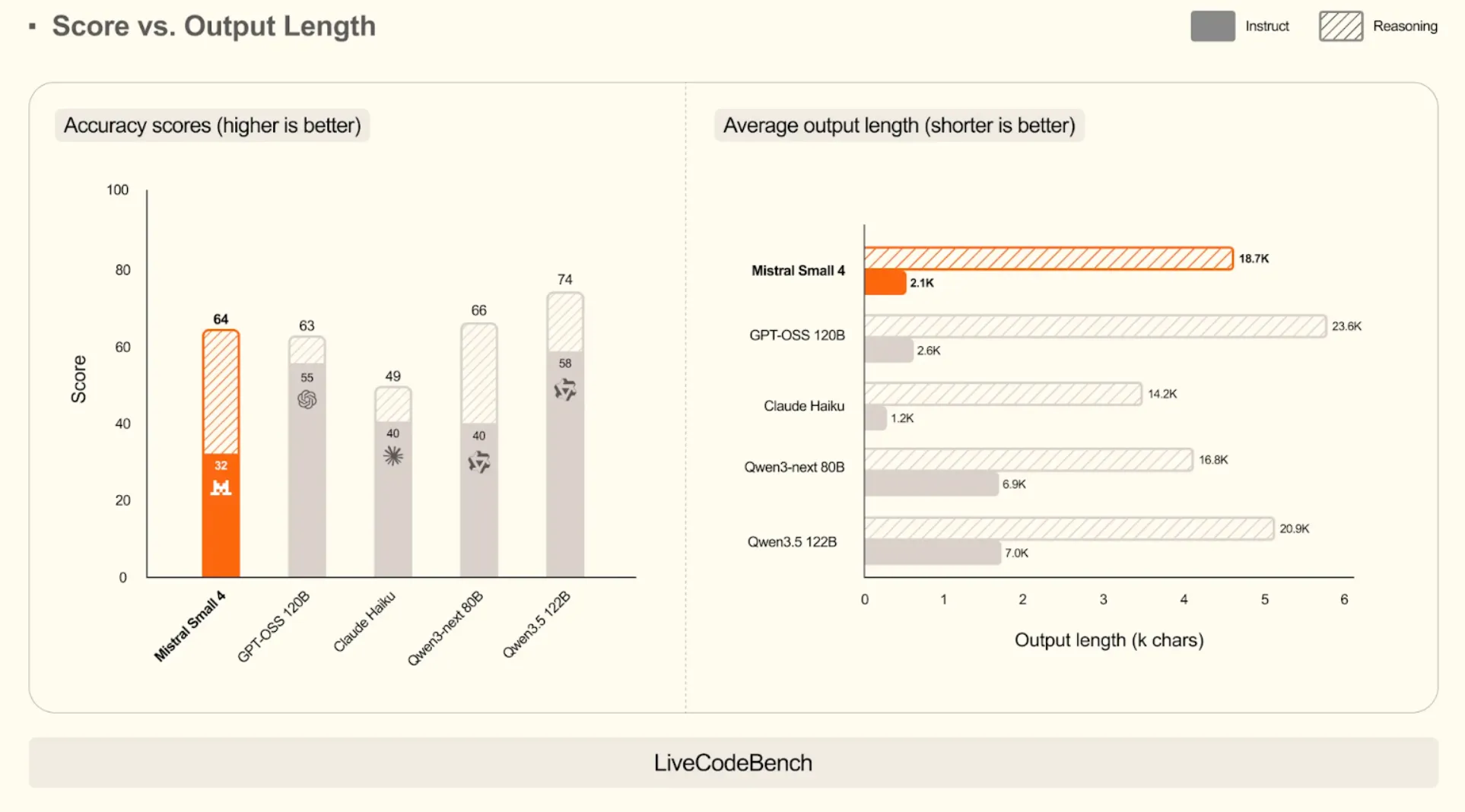
On Coding Tasks (LiveCodeBench)
The model has a competitive score of 64, marginally beating GPT-OSS 120B (63). It shows efficiency: it produces code that is more than 10 times shorter (2.1k characters vs. 23.6k characters), as it is able to produce correct code without the needless wordiness.
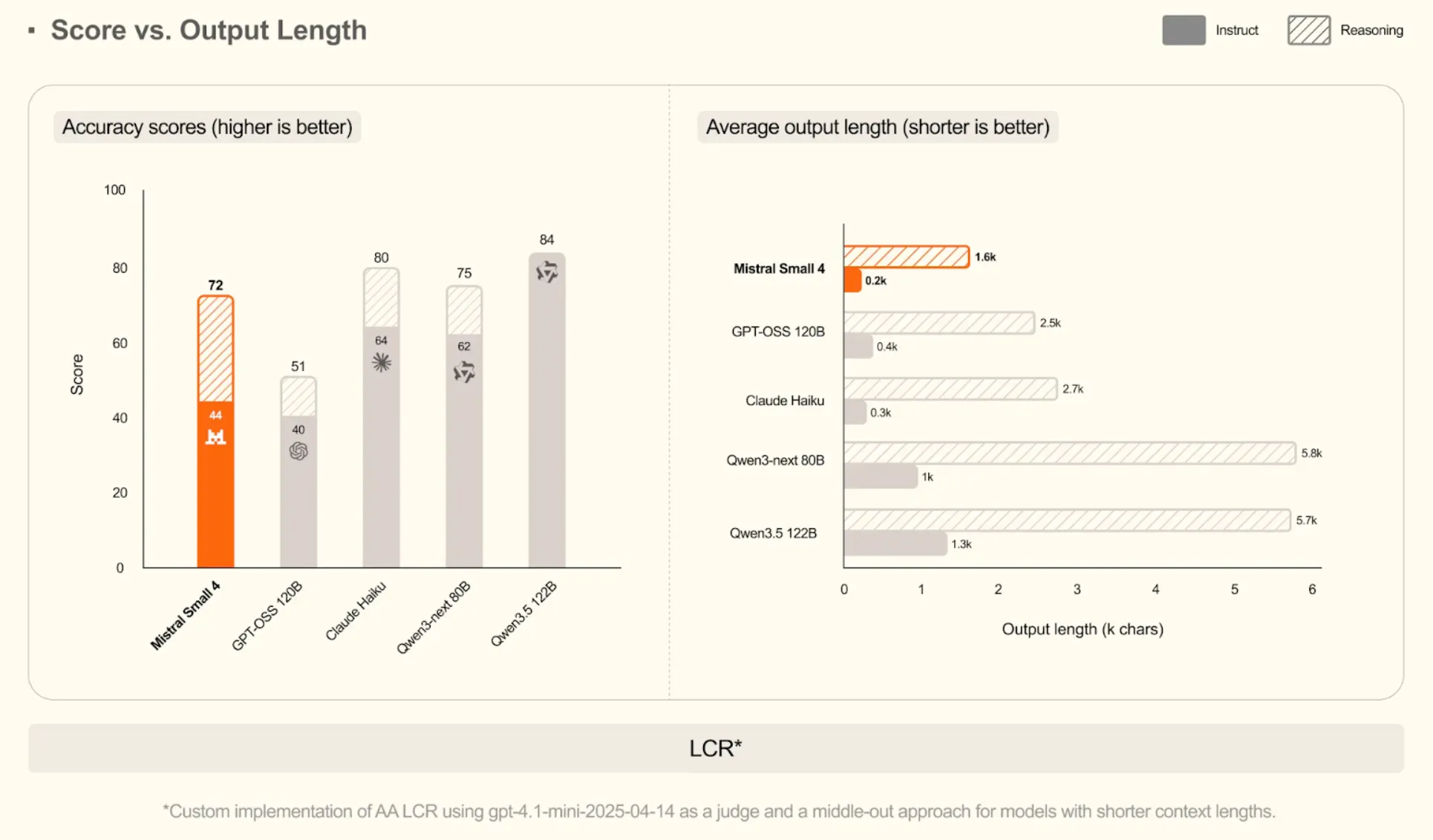
On Long-Context Reasoning (LCR)
Mistral Small 4 gets a high rating of 72. It does this at an extremely short output of only 200 characters in instruct mode. This is one of the remarkable skills of extracting answers even in the vast volumes of text.
A Generational Leap for Mistral
Comparisons with the other models reveal that Mistral Small 4 is a huge improvement over the old models. It continuously achieves new internal standards on text and vision standards.
- Higher Reasoning: It tops the Mistral models on difficult text tests with a score of 71.2 on GPQA Diamond and 78 on MMLU Pro.
- Vision Capabilities: The model also performs better in vision tasks with a score of 60 in MMMU-Pro, which is higher than the earlier models, such as Mistral Small 3.2 and Medium 3.1.
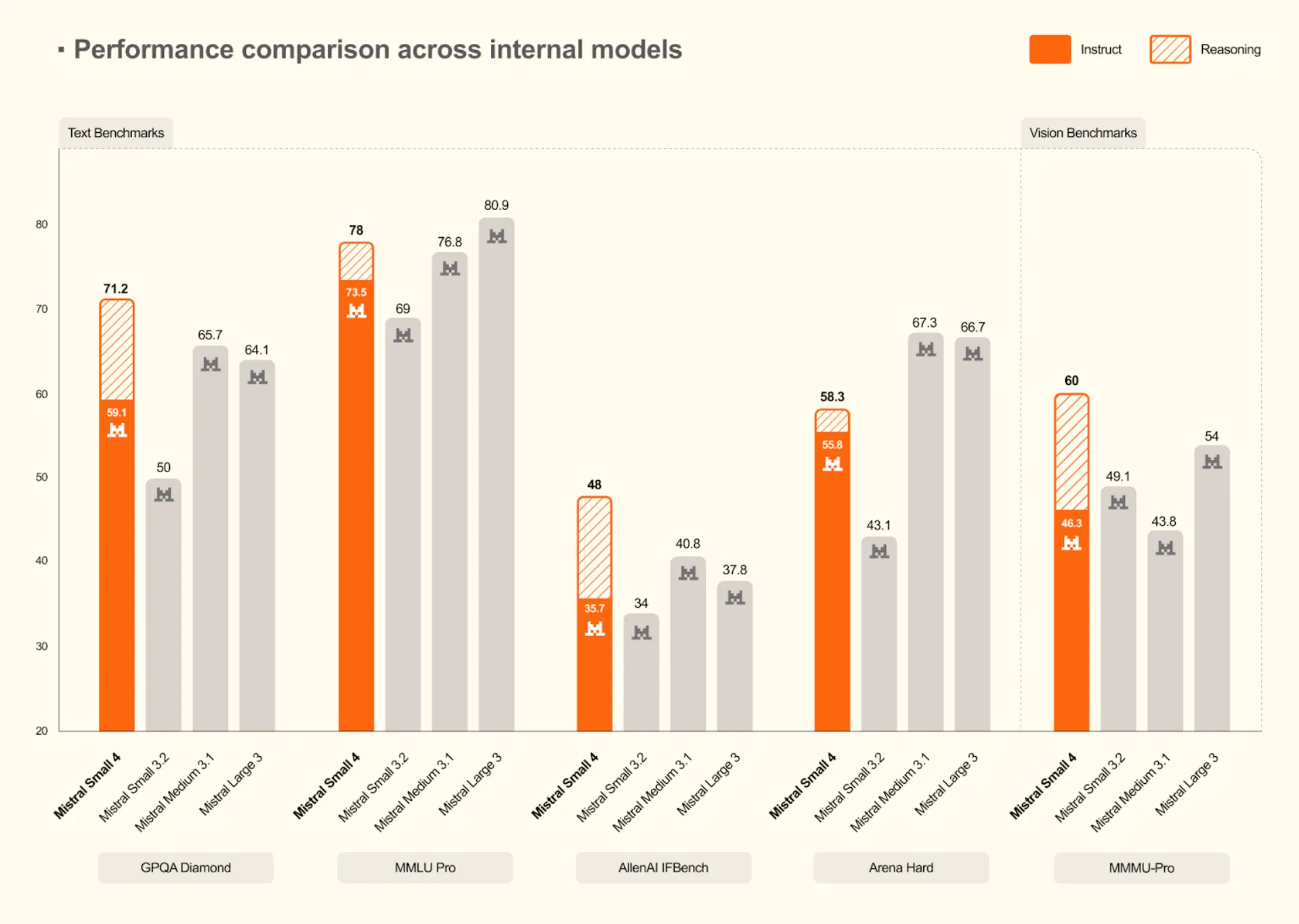
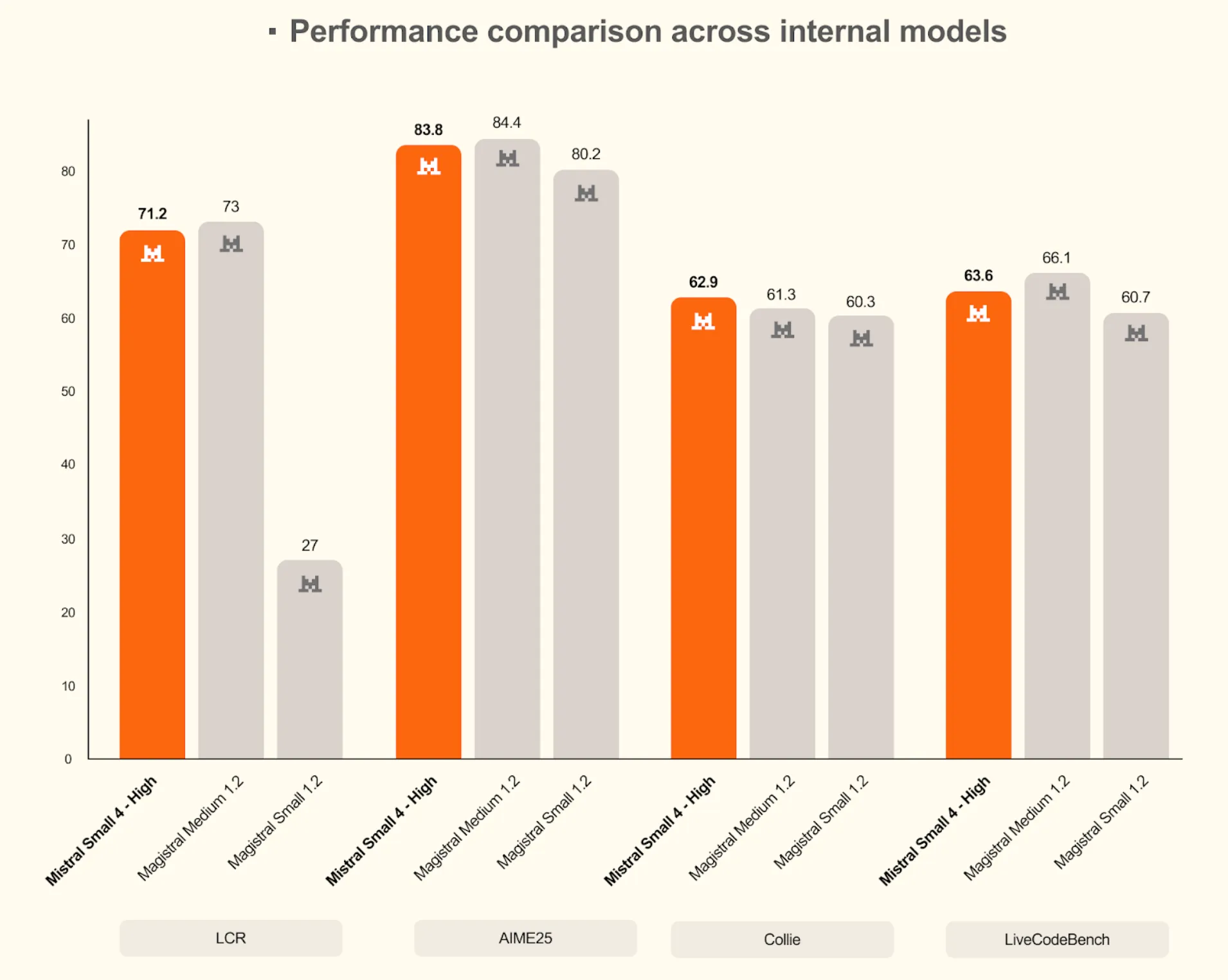
Mistral Small 4 is very competitive with, and at times performs even better than, larger internal models such as Magistral Medium 1.2 on challenging benchmarks when its high-reasoning mode is used. This fact supports the conclusion that Mistral Small 4 is as capable of meeting its claim of offering the best in reasoning and coding skills in a convenient package.
Hands-on with Mistral Small 4: Practical Tasks
Before hands on lets understand how to access the Mistral Small 4.
- First, go to https://console.mistral.ai/ and sign up using your mobile number.
- Now head over to the “Playground”.
- Then select the ‘Mistral Small Latest’ from the models list.
- You are ready to use the model.
Benchmarks and numbers tell part of the story, but the best way to understand a model is to see it perform. We tested Mistral Small 4 on three common, real-world tasks to evaluate its reasoning, coding, and writing skills.
Task 1: Structured Business Reasoning
Objective: Test the model’s ability to perform calculations, identify risks, and offer a strategic recommendation based on business data—all while maintaining a structured and concise format.
Prompt:
You are a product strategist.
A SaaS company has three subscription tiers:
Basic: 12,000 users at $5/month with 18% churn
Standard: 7,500 users at $12/month with 9% churn
Premium: 2,000 users at $25/month with 3% churn
Tasks:
- Calculate monthly revenue for each tier
- Identify which tier is most at risk
- Recommend one strategic change
- Keep the answer structured and concise
Output:
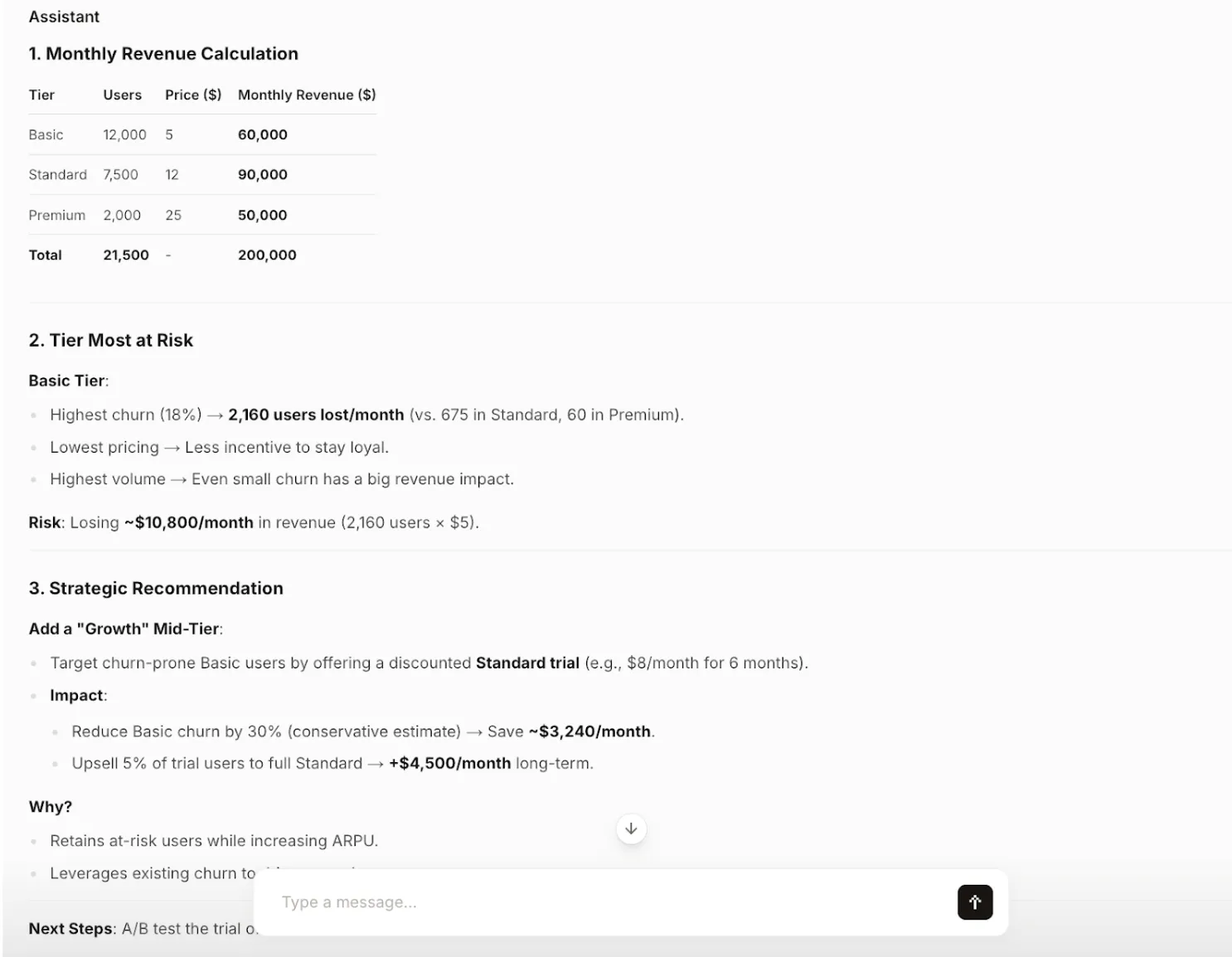
Analysis: The model correctly performs the calculations and identifies the Basic tier as the primary risk due to its high churn rate. The strategic recommendation is not only creative but also backed by clear, data-driven reasoning and includes actionable next steps. The output is perfectly structured and concise, following all instructions.
Task 2: Efficient and Clean Coding
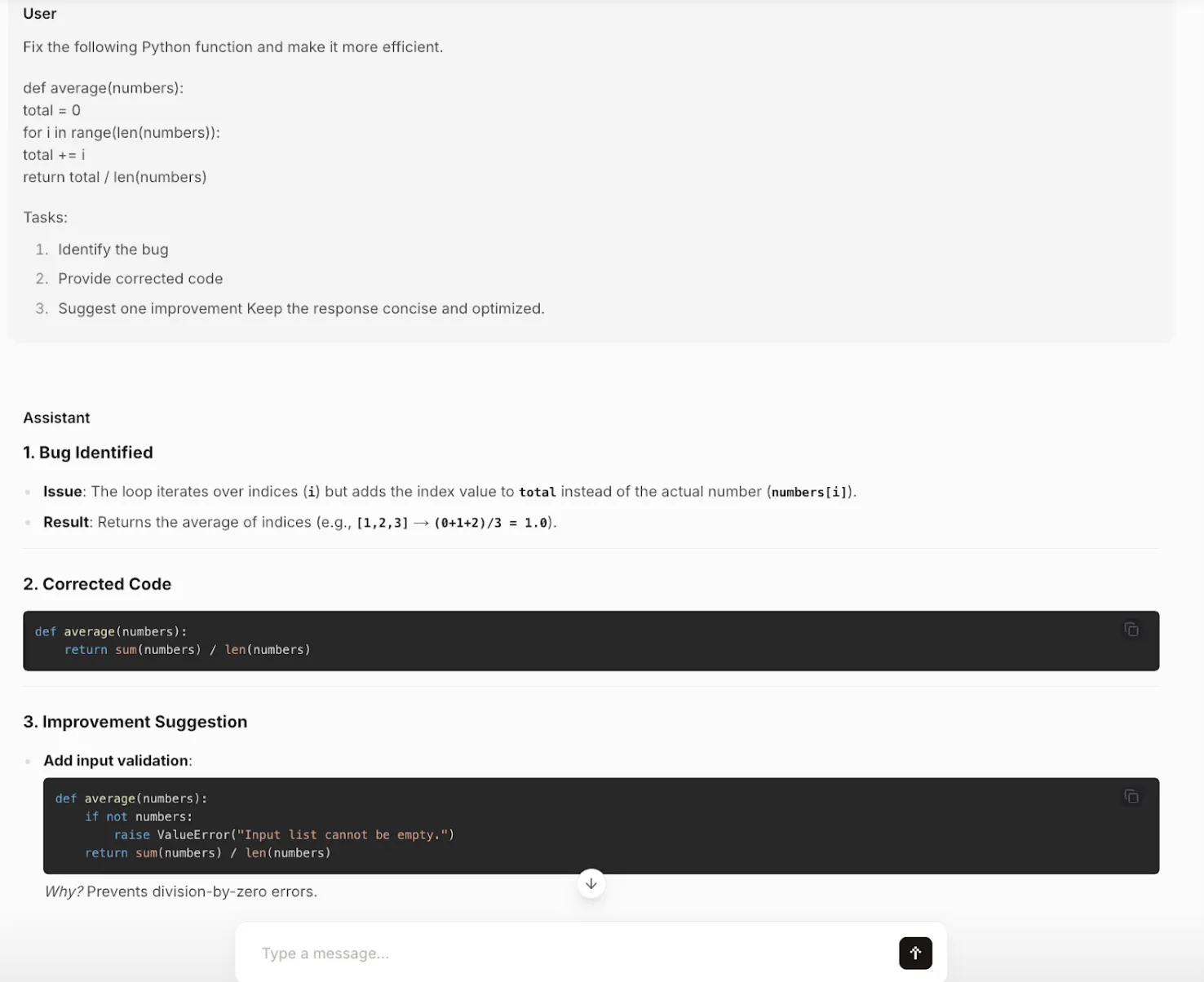
Objective: Test the model’s coding abilities, specifically its capacity to identify a logical bug, provide a corrected and more efficient solution, and suggest further improvements.
Prompt:
Fix the following Python function and make it more efficient.
def average(numbers):
total = 0
for i in range(len(numbers)):
total += i
return total / len(numbers)
Tasks:
- Identify the bug
- Provide corrected code
- Suggest one improvement
Keep the response concise and optimized.
Output:
Task 3: Professional Email Writing
Objective: Test the model’s real-world writing skills by rewriting a casual, slightly aggressive email into a professional, polite, and clear message while adhering to a word count.
Prompt:
Rewrite this email to be professional, concise, and polite:
“Hey, just following up on the dataset you said you’d send last week. We still don’t have it and it’s blocking our work. Also some files earlier had missing columns. Can you check that?”
Requirements:
- Keep it under 120 words
- Maintain a polite but firm tone
- Improve clarity
Output:
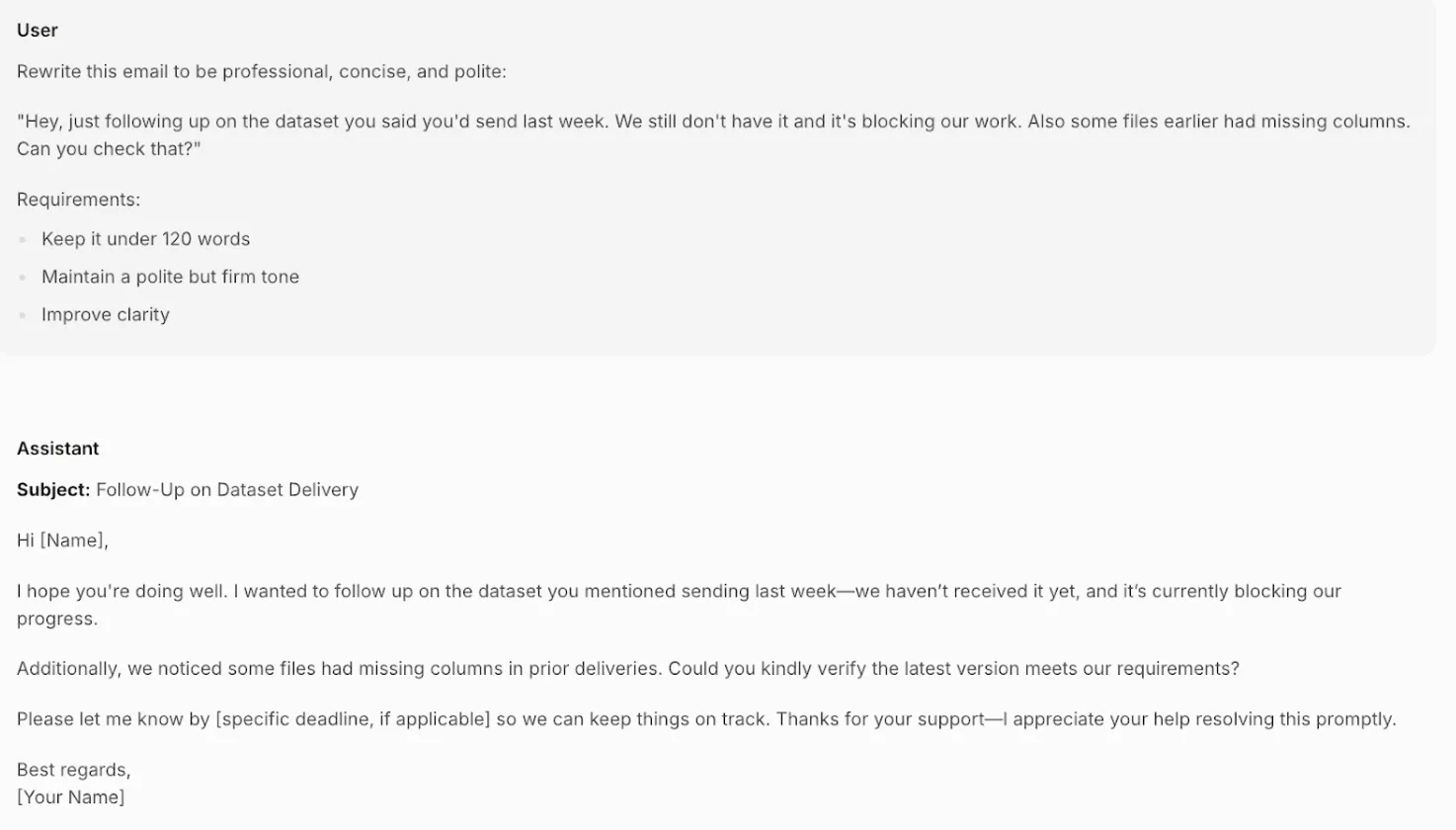
Analysis: The model transforms the original message perfectly. It replaces the blunt, accusatory tone with a professional and polite one (“I hope you’re doing well,” “Could you kindly verify”). It clearly states the problem (blocked progress) and adds a placeholder for a deadline, making the request firm but respectful. The email is well under the word limit and demonstrates a nuanced understanding of professional communication.
How Does It Compare to Its Peers?
Mistral Small 4 gets into the competitive market. This is a brief overview of the performance comparison between it and other models in the parameter range of approximately 120B.
- vs. GPT-OSS 120B: Mistral claims Small 4 as a straight rival, asserting that it is as successful as GPT-OSS on critical metrics and generates shorter and more efficient results. This translates to reduced latency and cost in production.
- vs. Qwen3.5-122B-A10B: Both of these models are large context windows and high-performance oriented. The Apache 2.0 open license offered by Mistral can be one of the reasons why the business will consider it to have the right of commercial use.
- vs. NVIDIA Nemotron 3 Super 120B: NVIDIA has been prone to providing detailed documentation on training data on its base models. A user who values the openness of the training corpus may fall on the side of Nemotron, but Mistral gives more specific advice on deployment hardware.
The idea here is that although the active parameters make the compute cost per token smaller, they are still large models. According to the hardware recommendations of Mistral itself, to run it productively in scenarios with long context tasks is a multi-GPU affair.
Conclusion
Mistral Small 4 is not just another big model. It is a well-considered framework designed to address a real-world issue, namely the difficulty of managing multiple specialized AI models. It brings chat, reasoning, and coding together into one, efficient endpoint, and that is a very attractive offer to the developers and businesses. With good performance and multimodal capabilities along with its open-weights approach, it is a tough competitor in the AI world.
Although it does not wave a magic wand to make the use of powerful hardware unnecessary, its architectural efforts, as well as its emphasis on output efficiency, are a substantial move towards improvement. To individuals who are interested in constructing the advanced yet affordable AI applications, Mistral Small 4 will certainly be a case to be followed and to develop with.
Frequently Asked Questions
What is the biggest advantage of Mistral Small 4?
Its key strength is to integrate the power of a chat model, a reasoning model, and a coding model in a single, efficient endpoint. This ensures easier development and less overhead in operation.
Is Mistral Small 4 truly open source?
Yes, its weights are released under the Apache 2.0 license, which permits commercial use. This makes it a strong option for businesses looking to build on an open-weight foundation.
What kind of hardware do I need to run it myself?
The minimum hardware suggested by Mistral is four H100 GPUs or similar. They recommend a more elaborate, disaggregated configuration in the case of high-throughput, long-context workloads.
Can it understand images?
Yes, it is multimodal and is capable of taking text input and image input, where its Pixtral vision stack would analyze the image.
How does its performance compare to other large models?
Mistral asserts to outperform or even exceed similar models such as GPT-OSS 120B on a number of benchmarks, and has the added advantage of producing shorter and more efficient outputs, potentially resulting in reduced latency and cost.
Harsh Mishra is an AI/ML Engineer who spends more time talking to Large Language Models than actual humans. Passionate about GenAI, NLP, and making machines smarter (so they don’t replace him just yet). When not optimizing models, he’s probably optimizing his coffee intake. 🚀☕






