Do you remember the very first AI voice conversation that you had? No doubt, it felt unreal getting live answers from a talking bot. But the one thing largely missing from the interaction was the feel of a human responding to your queries. Years on, we now see AI models have evolved largely in this matter. And one such recent example comes from the house of Google with the moniker – Gemini 3.1 Flash Live.
With this launch, Google makes one big claim – it delivers the quality of a “next generation of voice-first AI.”
So what is it? How does it work? And is it really the next big step in the domain of voice-powered generative AI? We shall try to explore all this here.
Also read: Gemini 3.1 Pro: A Hands-On Test of Google’s Newest AI
Table of contents
What is Gemini 3.1 Flash Live?
Think of Gemini 3.1 Flash Live as a more evolved, real-time, voice-first AI. If we are to go by Google’s words (in its blog), it is designed for fluid conversations, with lower latency, faster turn-taking, and a more natural back-and-forth than what many earlier AI voice systems could offer.
That distinction matters. Most people do not judge a voice AI only by whether it gives the right answer. They judge it by how it responds in motion. Does it interrupt awkwardly or pause too long? Does it lose track when the speaker changes tone or direction midway? These are the moments that make or break the experience of an AI voice model. A human will understand why you took a pause. An AI may not.
This is the gap Google appears to be targeting with Gemini 3.1 Flash Live. Google did not position it as just another model update. Instead, the company is presenting it as infrastructure for live AI agents that can listen, respond, and act in real time, without any delay. In simple terms, the goal is not merely to make AI speak, but to make it feel more present while speaking.
Google also says the model is built not just for voice, but for voice and vision-based experiences. That means developers can use it to create assistants and agents that process spoken input, understand visual context, and trigger tools during a conversation. In that sense, Gemini 3.1 Flash Live is less of a standard chatbot model and more of a foundation for the next-gen interactive AI experiences. That is, after all, the big need of the hour with AI.
Gemini 3.1 Flash Live: What Has Improved?
The upgrade with Gemini 3.1 Flash Live extends beyond an improved voice output. Google seems to have worked closely on the full live interaction layer. For instance, one critical function that it improved on was the latency, making the new AI model way faster in conversations than ever before.
Here is the full list of all such features that the new Gemini 3.1 Flash Live promises.
1. Faster, More Natural Live Interaction
The first major improvement is speed. Gemini 3.1 Flash Live is built for low-latency interaction, which is essential in voice-first systems, as even a slight delay can make a response feel artificial. Instead of waiting for one complete prompt and then replying, the Live API is designed for continuous input and output, allowing conversations to unfold more fluidly.
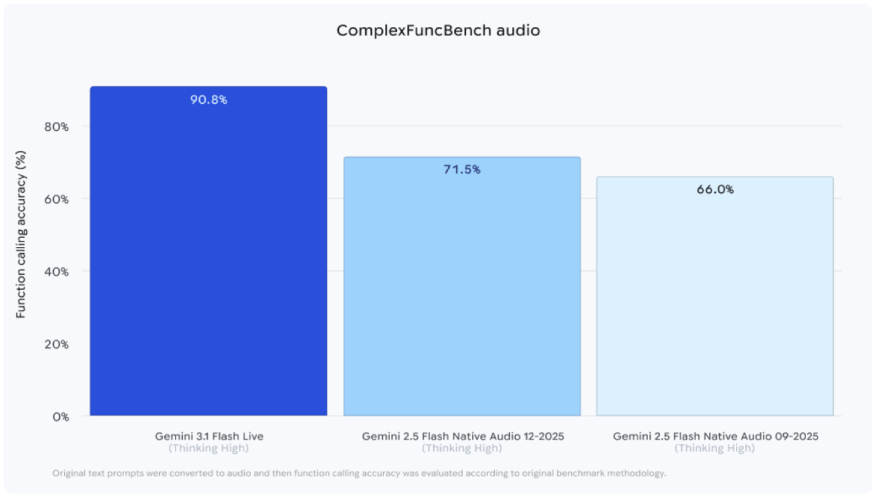
2. Better Conversational Control
Some features with the Gemini 3.1 Flash Live act on top of the model’s conversational improvements, making it feel more human-like:
- Barge-in support lets users interrupt the model mid-response.
- Proactive audio gives developers more control over when the model should respond.
- Affective dialogue allows the system to adapt its tone and response style based on the user’s expression.
Taken together, these changes suggest that Gemini 3.1 Flash Live is being shaped for more dynamic conversations that feel more natural and less scripted.
3. Stronger Multilingual and Tool Capabilities
Another key step forward is the massively enhanced accessibility. The Live API supports conversations in 70 languages, making it more practical for globally deployed voice agents.
In addition, it supports tool use, including function calling and Google Search, which means the model is not limited to speaking back. It can actually pull in external actions and information during a conversation. This matters for obvious reasons. After all, you are not just here to strike a conversation with AI over a cup of coffee, right? You need things done.
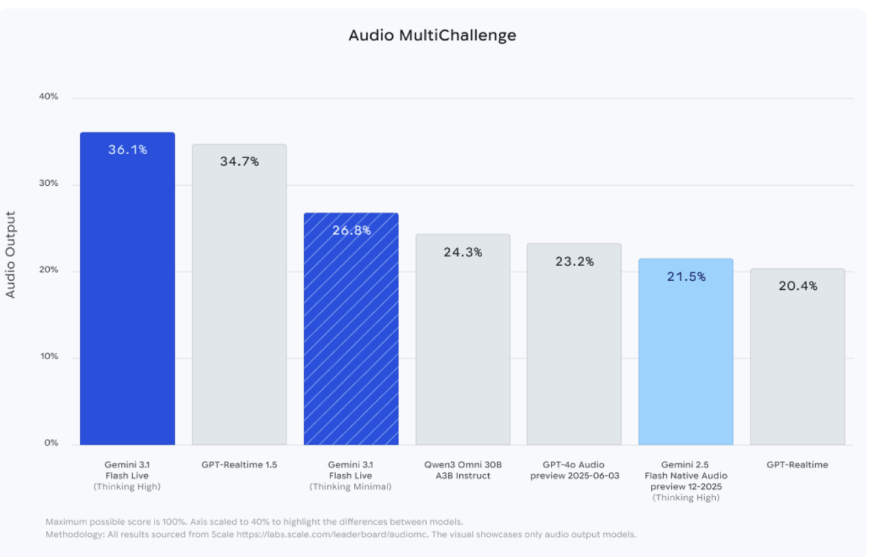
4. Built-In Transcription for Both Sides
The Live API can generate text transcripts of both user input and model output. This is especially useful in real-world deployments. It gives developers a record of the interaction, supports accessibility, and makes debugging or fine-tuning voice experiences much easier.
5. Technical Improvements Under the Hood
Google’s documentation also gives a clearer picture of the system’s real-time architecture:
- Input modalities: audio, images, and text
- Audio input format: raw 16-bit PCM, 16kHz, little-endian
- Image input: JPEG at up to 1 FPS
- Output: raw 16-bit PCM audio at 24kHz
- Protocol: stateful WebSocket connection (WSS)
In a nutshell, these specifications reinforce that Gemini 3.1 Flash Live is not a basic voice wrapper over a text model. It is being built as a persistent streaming system for live multimodal interaction.
6. More Flexible Deployment Options
Google also offers two implementation paths:
- Server-to-server, where a backend relays audio, video, or text streams to the Live API
- Client-to-server, where the frontend connects directly through WebSockets
According to Google, the client-to-server approach generally offers better performance for streaming audio and video because it removes an additional relay step. However, note that the company recommends ephemeral tokens in production rather than standard API keys for security.
What This Really Means
So, what has improved here? In simple terms: speed, interruption handling, emotional responsiveness, multilingual support, tool use, and real-time streaming architecture. That is a meaningful jump from older voice AI systems that could speak, but often struggled to sustain a conversation naturally. One caveat: the documentation here details features and technical specifications, but it does not provide benchmark scores, so this section is better framed around capabilities rather than performance metrics.
Once you know its importance, here is how to access the new Gemini model.
Gemini 3.1 Flash Live: How to Access
There are 3 basic ways in which you can access the new Gemini 3.1 Flash Live. These are:
- via Gemini API and Google AI Studio: Google says Gemini 3.1 Flash Live is available starting today through the Gemini API and Google AI Studio.
- Use the Gemini Live API for integration: Developers can integrate the new model into their applications using the Gemini Live API, which is built for real-time voice interactions.
- Build with the Google GenAI SDK: Google has shared starter code through the Google GenAI SDK, allowing developers to open a live session with the model and begin experimenting quickly.
Hands-on With Gemini 3.1 Flash Live
To test out Google’s claims, we tried our hand on the Gemini 3.1 Flash Live right inside the Google AI Studio. You can check out our conversation with the new AI model in the video below and watch it in action.
Gemini 3.1 Flash Live for Voice Interactions
In the first test, I had a regular voice conversation with the new Gemini 3.1 Flash Live to test out its tone, flow, and the speed and accuracy of its responses. You can check out the conversation in the video below:
My Take: The new Gemini model seems to perform exceptionally well in a regular, everyday conversation. It is able to give out accurate responses, understanding the context of the conversation in no time. What amazed me the most was how prompt it was with the replies, having almost no buffer time after I was done speaking.
Having said that, it was not as if the Gemini model interrupted me in any way. It was prompt to respond, yes, but only after it sensed a pause from my end for just the right amount of time that you would expect in a regular human conversation. So, as to judge Google on its claims of making AI conversations more natural, the new Gemini model definitely did the job well.
Gemini 3.1 Flash Live for Tool-calls and Tasks
In this conversation, I tested the Gemini 3.1 Flash Live for its ability to call on tools and perform real world tasks. Check out how it fared in the video below:
My Take: As you can see, I tasked the new model with finding a particular list of companies from the internet that sell a set of protein products. First, the model asked me to zero in on the kind of product that I wanted to know more about. Once we did that, it was able to scan through the e-commerce websites like Amazon to retrieve a solid list of such companies.
I even asked it to do a price comparison between the products of the companies. While it was unable to do the same due to a considerable variation in prices across platforms, it did give me an average price range of the product of my choice. At the end, it compiled all the info in a table format.
So, all in all, a job well done for simple tool calling and tasks that required it to go beyond its sandbox environment.
Conclusion
Gemini 3.1 Flash Live hints at the direction of voice AI itself. Google is clearly pushing beyond the idea of a chatbot that can speak and toward something that can listen continuously, respond faster, follow instructions more reliably, handle noisy surroundings, and carry on a conversation with a more natural rhythm. The company says the model brings a “step change” in latency, reliability, and natural-sounding dialogue, while also supporting more than 90 languages for real-time multimodal conversations.
That shift matters because users rarely judge voice AI by architecture diagrams or model names. They judge it by feel. Does it pause too long? Does it miss the tone of a sentence, or break when interrupted? Gemini 3.1 Flash Live appears designed around exactly those friction points, with improvements in acoustic nuance, instruction-following, background-noise handling, tool use, and live responsiveness.
So the larger takeaway is fairly simple: this launch is less about giving AI a better voice and more about making AI interaction itself feel less artificial.






