AI demos often look impressive, delivering fast responses, polished communication, and strong performance in controlled environments. But once real users interact with the system, issues surface like hallucinations, inconsistent tone, and answers that should never be given. What seemed ready for production quickly creates friction and exposes the gap between demo success and real-world reliability.
This gap exists because the challenge is not just the model, it is how you shape and ground it. Teams often default to a single approach, then spend weeks fixing avoidable mistakes. The real question is not whether to use prompt engineering, RAG, or fine-tuning, but when and how to use each. In this article, we break down the differences and help you choose the right path.
Table of contents
The 3 Mistakes Most Teams Make First
Before going into detail about the different methods for using generative AI effectively, let’s start with some of the reasons why issues persist in an organization when it comes to successful implementation of generative AI. Many of these errors could be avoided.
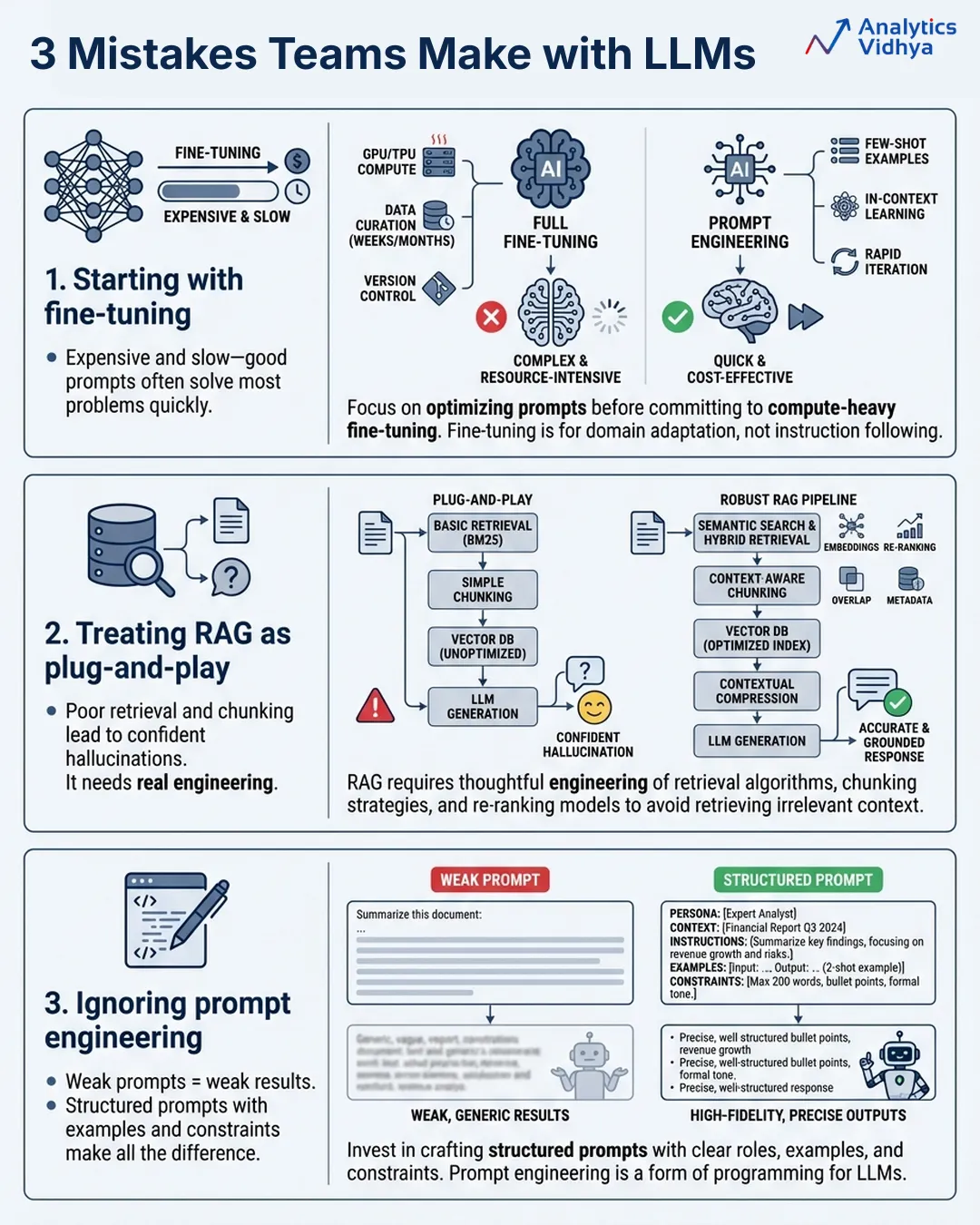
- Fine Tuning First: Fine-tuning the solution sounds great (especially training the generative AI model using your data). However, fine-tuning your model is often the most costly, time-consuming approach. You could likely have resolved 80% of the problem in as little time as an afternoon by writing a highly crafted prompt.
- Plug and Play: If you are treating your Retrieval-Augmented Generation (RAG) implementation as simply dropping your documents into a vector database, connecting that database to an instance of the GPT-4 model, and shipping it. Your implementation is likely going to fail due to poorly designed chunks, poor retrieval quality, and incorrect model generation based on incorrect paragraphs of text.
- Prompt Engineering as an Afterthought: Most teams approach the building of their prompts as if they are building a Google search query. In fact, developing clear instructions, examples, constraints, and output formatting in your system prompt can take a mediocre experience to a production-quality experience.
Now let’s begin to explore the potential for each approach.
Prompt Engineering: The Fastest Tool in the Kit
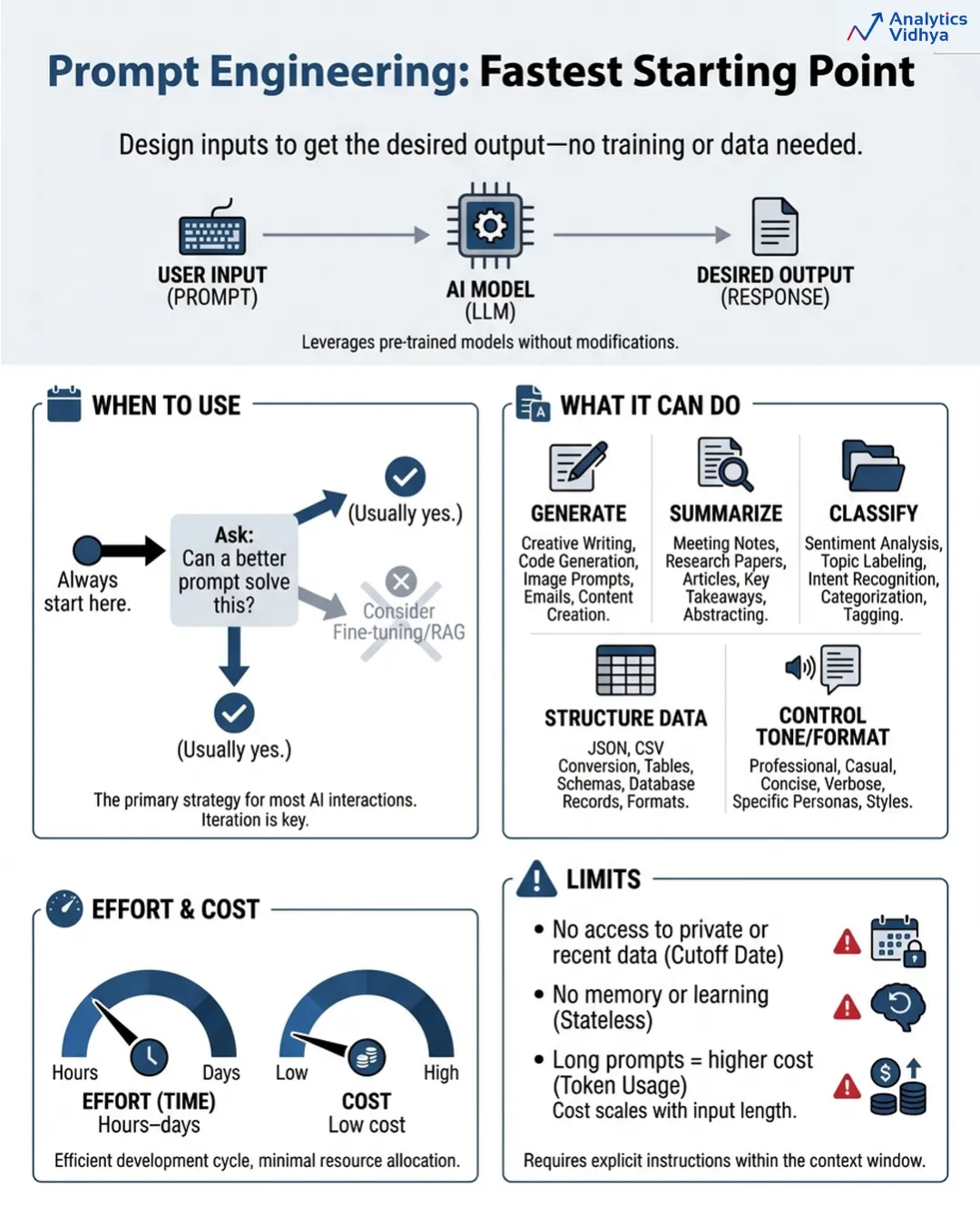
The art of prompt engineering requires you to design your model interactions so that you achieve your desired results in all situations. The system operates without any training or databases because it requires only intelligent user input.
The process seems easy to complete but actually requires more effort than first apparent. The process of prompt engineering requires all of these tasks to be executed correctly because it needs a precise model to perform specific activities.
When to use it
Your initial step should be to start with prompt engineering. Your organization should follow this guideline at all times. Before you invest in anything else, ask: can a better prompt solve this? The common situation occurs where the response to this question proves to be true more than you expect.
The system can generate content while it generates summaries and classifies information and creates structured data and controls both tone and format and executes specific tasks. The system requires better instructions because the model already possesses all necessary knowledge according to the existing standards.
The actual restrictions
- The system can only utilize existing information which the model already possesses. Your case needs access to internal documents of your organization and recent product material and information which exceeds the training date of the model design because no prompt can bridge that requirement.
- The system operates through prompts because they maintain no state information. The system operates through prompts which are not capable of learning. The system begins all operations from a blank state. The system develops high expenses when it handles extended and complicated prompts during large operations.
- The required time to complete the task ranges from a few hours to several days.
- The total expenses for the project remain at an extremely low level. The project should continue until all relevant questions achieve maximum factual accuracy.
RAG (Retrieval-Augmented Generation): Giving the Intern a Library Card
The RAG system establishes a connection between your LLM and external knowledge bases which include your documents and databases and product wikis and support tickets through which the model retrieves relevant data to create its answers. The flow looks like this:
- User asks a question
- System searches your knowledge base using semantic search (not just keyword matching, it searches by meaning)
- The most relevant chunks get pulled and inserted into the prompt
- The model generates an answer grounded in that retrieved context
The system distinguishes between two ways your AI can provide answers which are based on its recollections and its access to original factual information. The right time to use RAG occurs when your problem requires knowledge which the model needs to answer correctly. This is most real-world enterprise use cases.
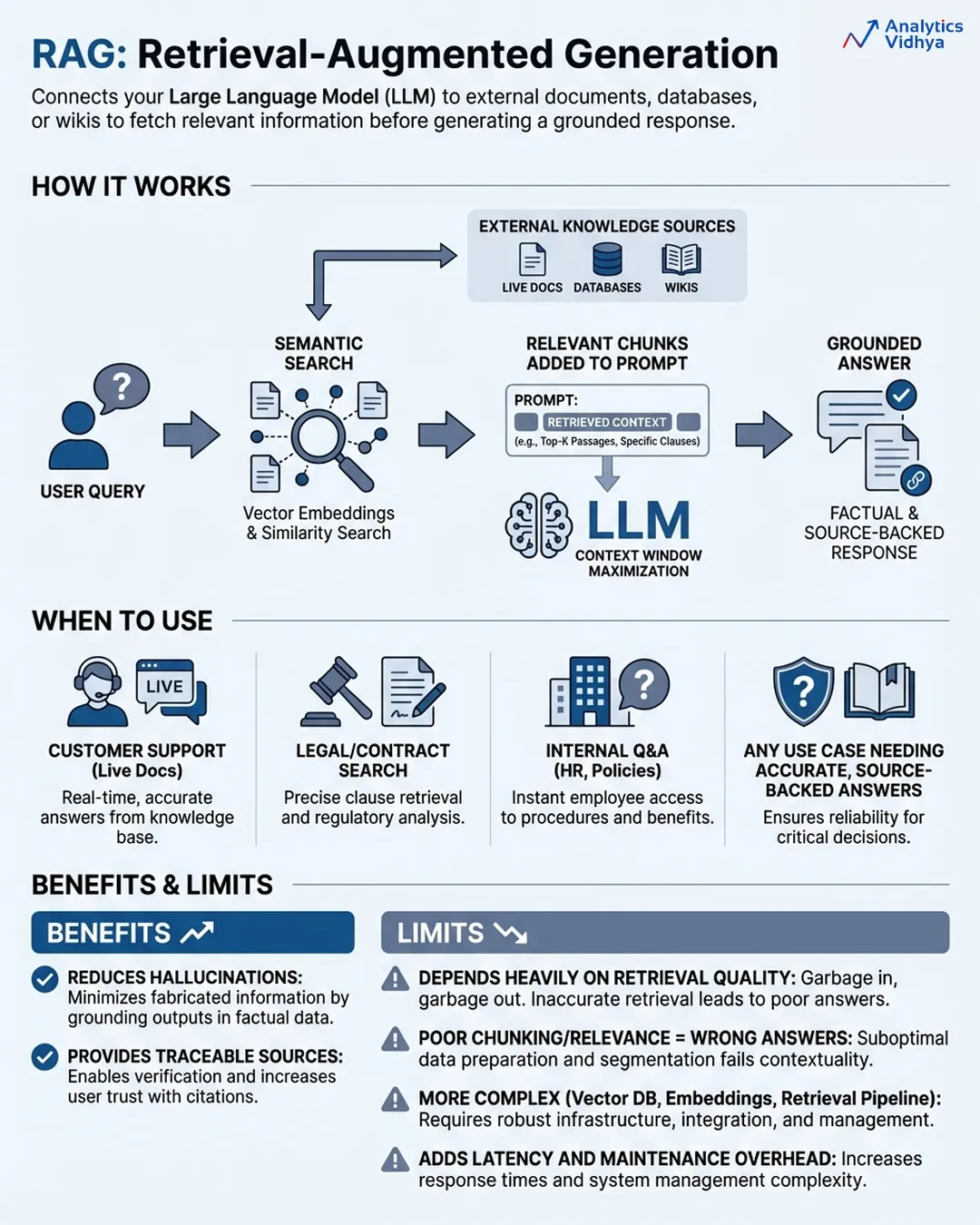
When to use it:
- Customer support bots that need to reference live product docs.
- Legal tools that need to search contracts.
- Internal Q&A systems that pull from HR policies.
- Any situation which requires information from documents to achieve pinpoint correct answers without deviation.
RAG helps you document answer origins because it allows users to track which source provided them correct information. The regulated industries find this level of transparency an important value.
The actual restrictions:
The real limits of RAG systems depend on the quality of their retrieval process because RAG systems exist through their retrieval process. The model generates a complete incorrect response because it receives incorrect fragments during the search process. Most RAG systems fail because their implementation contains three hidden problems which include improper chunking methods and incorrect model selection with insufficient relevance assessment methods.
The system creates additional delay because it requires more complex building components. You need to handle three components which include a vector database and embedding pipeline and retrieval system. The system requires continuous support because it does not function as a simple installation.
Fine-Tuning: Sending the Intern Back to School
Fine-tuning enables you to train your own model through the process of training a pre-existing base model with your specific labeled dataset which contains all the input and output examples that you need. The model’s weights are updated. The system implements modifications according to its existing structure without requiring additional instructions to function. The model undergoes transformation because the system implements its own changes.
The result is a specialized version of the base model which has learned to use the vocabulary from your domain while generating outputs according to your specified style and following your defined behaviour rules and your specific task requirements.
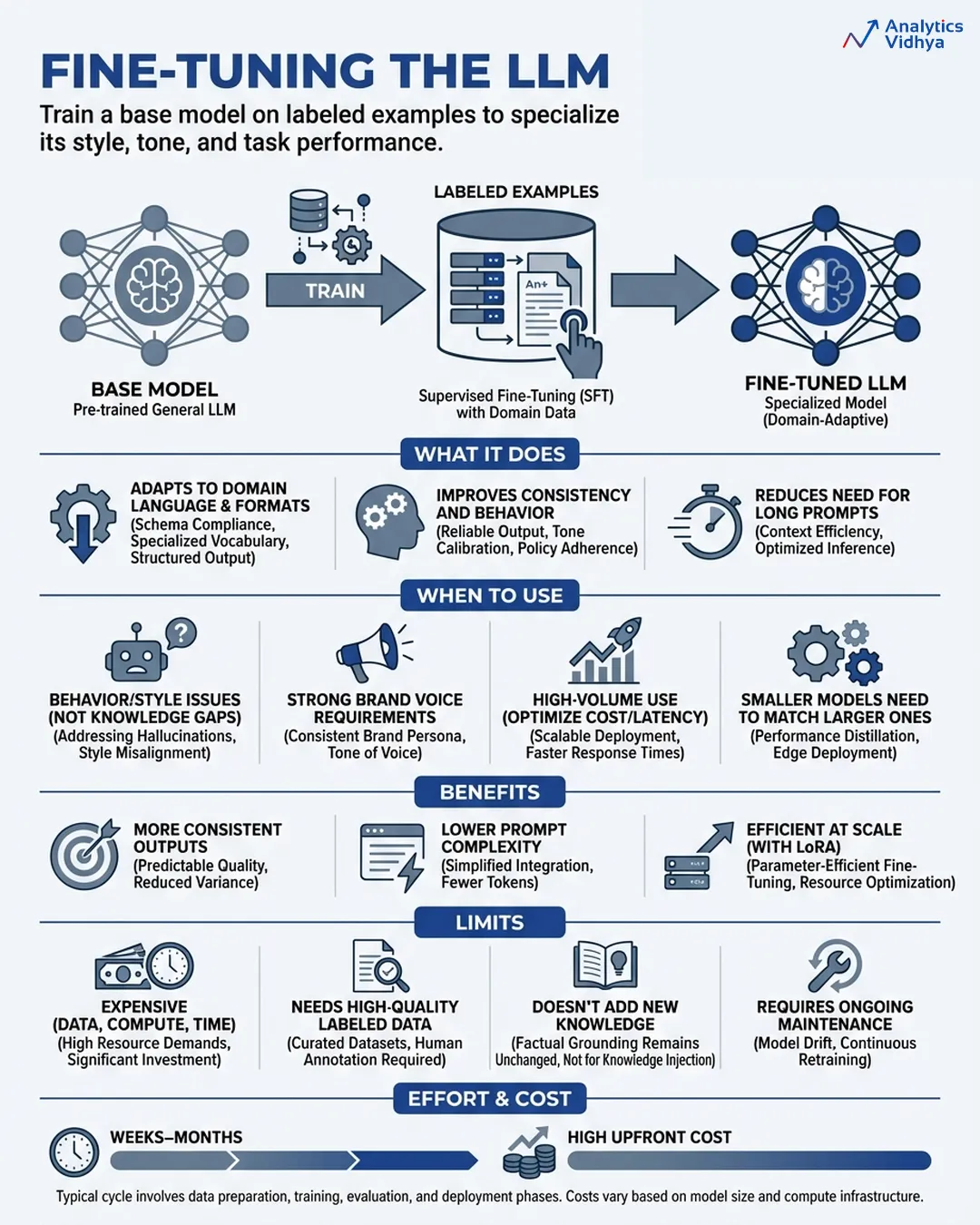
The modern method of LoRA (Low-Rank Adaptation) achieves better accessibility through its system which needs only a few parameter updates to operate because this method decreases computing expenses while maintaining most performance benefits.
When to use it
Fine-tuning earns its place when you have a behaviour problem, not a knowledge problem.
- Your brand voice is highly specific and prompting alone can’t hold it consistently at scale.
- Your specific task requires you to use a smaller model that costs less while performing at the same level as a larger general model.
- The model requires complete understanding of all domain-specific terms and particular reasoning methods and their associated formats.
- You need to remove all costly prompt instructions because your system handles a large volume of inference requests.
- You need to reduce unwanted behaviors which include specific types of hallucinations and inappropriate refusals and incorrect output patterns.
The tool becomes suitable for your needs when you intend to develop a more compact model. A fine-tuned GPT-3.5 or Sonnet system can perform at a similar level as GPT-4o when used for specific tasks while needing less processing power during inference.
The real limits
- Fine-tuning requires substantial cash resources and time resources and data resources for its execution. The process demands hundreds to thousands of top-notches labeled samples together with extensive computational resources during the learning phase and continuous upkeep whenever the fundamental model receives enhancements. Bad training data doesn’t just fail to help, it actively hurts.
- Fine-tuning doesn’t give the model new knowledge. The process modifies model operations. The model will not acquire product knowledge through internal documents because they have become outdated. The system exists to accomplish that goal.
- Training runs will require weeks to complete while data quality will need months to complete its iteration cycles and the overall expenses will be much higher than typical team budgets.
- The time needed for work completion ranges from weeks to months. The initial investment will be substantial while the inference expenses will exceed base model costs by six times. The solution should be used when organizations need to establish consistent performance across their operations after completing both prompt engineering and RAG implementation.
The Decision Framework
There are few things to keep in mind while deciding which optimization method to go for first:
- Is it a communication issue? → Start by doing prompt engineering first, including examples and explicit formatting. Ship in days or less.
- Is it an issue of knowledge? → Incorporate RAG. Overlay a clean retrieval on top of existing documents. Make sure the answer from the model includes proof from outside sources.
- Is it a behaviour issue? → Think about fine-tuning the model. The model continues to misbehave due to prompting or data alone being insufficient.
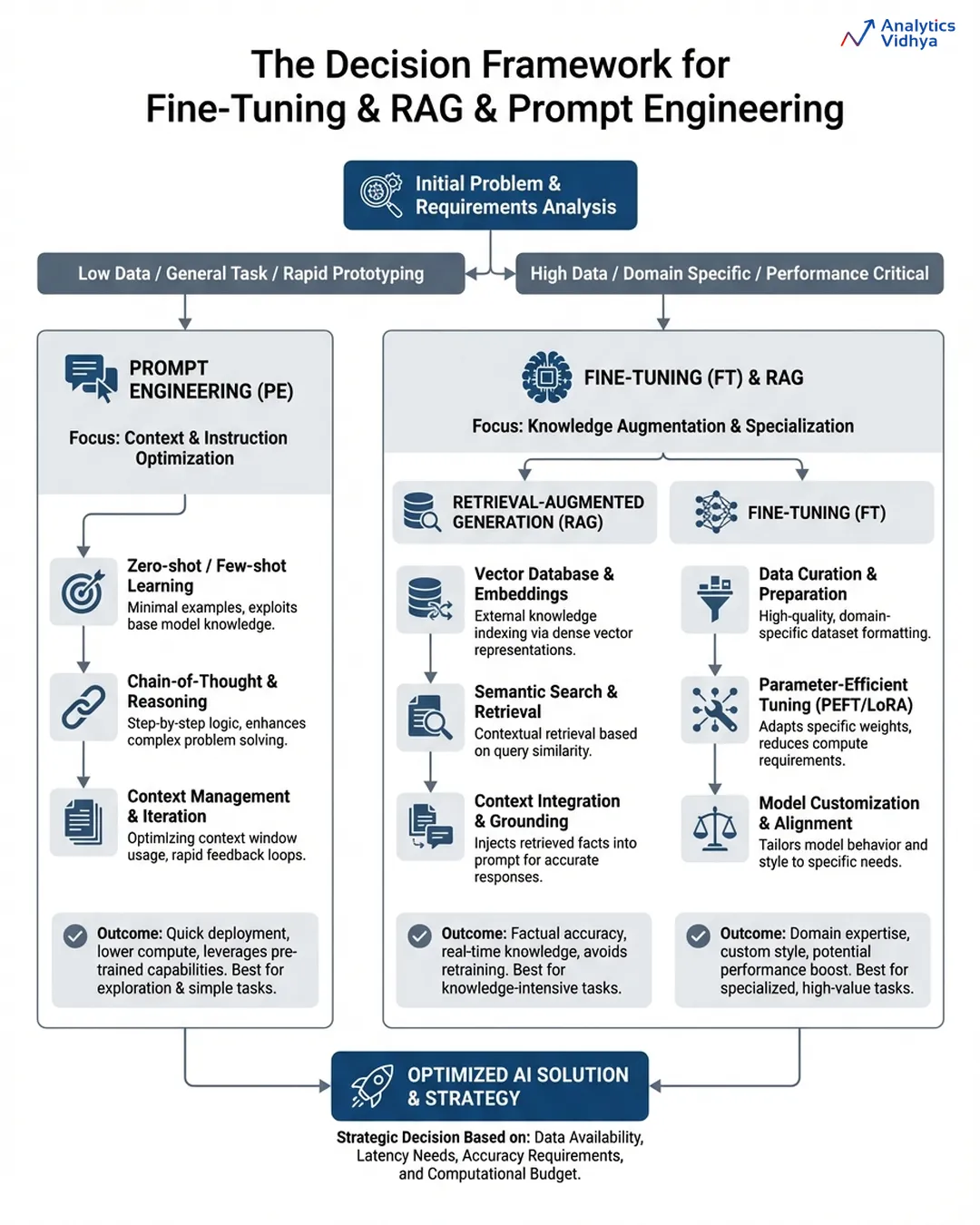
You will find that most production systems will incorporate all three types of solutions layered together, and the sequence in which they were used is important: prompt engineering is done first, RAG is implemented once knowledge is the limiting factor, and fine-tuning is applied when there are still issues with consistent behaviour across large scale.
Summary Comparison
Let’s try to understand a differentiation between all three based on some important parameters:
| Prompt Engineering | RAG | Fine-Tuning | |
| Solves | Communication | Knowledge gaps | Behavior at scale |
| Speed | Hours | Days–Weeks | Months |
| Cost | Low | Medium | High |
| Updates easily? | Yes | Yes | No — retrain needed |
| Adds new knowledge? | No | Yes | No |
| Changes model behavior? | Temporarily | No | Permanently |
Now, let’s see a detailed comparison via an infographic:

You can use this infographic for future reference.
Conclusion
The biggest mistake in AI product development is choosing tools before understanding the problem. Start with prompt engineering, as most teams underinvest here despite its speed, low cost, and surprising effectiveness when done well. Move to RAG only when you hit limits with knowledge access or need to incorporate proprietary data.
Fine-tuning should come last, only after other approaches fail and behavior breaks at scale. The best teams are not chasing complex architectures, they are the ones who clearly define the problem first and build accordingly.
Frequently Asked Questions
Q1. When should you use prompt engineering first?
A. Start with prompt engineering to solve communication and formatting issues quickly and cheaply before adding complexity.
Q2. When is RAG the right choice?
A. Use RAG when your system needs accurate, up-to-date, or proprietary knowledge beyond what the base model already knows.
Q3. When should you consider fine-tuning?
A. Choose fine-tuning only when behavior remains inconsistent at scale after prompts and RAG fail to fix the problem.
Data Science Trainee at Analytics Vidhya
I am currently working as a Data Science Trainee at Analytics Vidhya, where I focus on building data-driven solutions and applying AI/ML techniques to solve real-world business problems. My work allows me to explore advanced analytics, machine learning, and AI applications that empower organizations to make smarter, evidence-based decisions.
With a strong foundation in computer science, software development, and data analytics, I am passionate about leveraging AI to create impactful, scalable solutions that bridge the gap between technology and business.
📩 You can also reach out to me at [email protected]






