This article was published as a part of the Data Science Blogathon.
Introduction to Text to Speech
When it comes to our interactions with machines, things have gotten a lot more complicated. We’ve gone from large mechanical buttons to touchscreens. However, hardware isn’t the only thing that’s changing. Throughout the history of computers, the text has been the primary method of input. But thanks to developments in NLP and ML (Machine Learning), Data Science, we now have the means to use speech as a medium for interacting with our gadgets in the near future.
Virtual assistants are the most common use of these tools, which are all around us. Google, Siri, Alexa, and a host of other digital assistants have set the bar high for what’s possible when it comes to communicating with the digital world on a personal level.

For the first time in the history of modern technology, the ability to convert spoken words into text is freely available to everyone who wants to experiment with it.
When it comes to creating speech-to-text applications, Python, one of the most widely used programming languages, has plenty of options.
History of Speech to Text
Before diving into Python’s statement to text feature, it’s interesting to take a look at how far we’ve come in this area. Listed here is a condensed version of the timeline of events:
Audrey,1952: The first speech recognition system built by 3 Bell Labs engineers was Audrey in 1952. It was only able to read numerals.
IBM Shoebox (1962): Coils can distinguish 16 words in addition to numbers in IBM’s first voice recognition system, the IBM Shoebox (1962). Had the ability to do basic mathematical calculations and publish the results.

Defense Advanced Research Projects Agency(DARPA) (1970): Defense Advanced Research Projects Agency (DARPA) (1970): DARPA supported Speech Understanding Research, which led to the creation of Harpy’s ability to identify 1011 words.
Hidden Markov Model(HMM), the 1980s: Problems that need sequential information can be represented using the HMM statistical model. This model was used in the development of new voice recognition techniques.
Voice search by Google,2001: It was in 2001 that Google launched its Voice Search tool, which allowed users to search by speaking. This was the first widely used voice-enabled app.

Siri,2011: A real-time and convenient way to connect with Apple’s gadgets was provided by Siri in 2011.

Alexa,2014 & google home,2016: Voice-activated virtual assistants like Alexa and Google Home, which have sold over 150 million units combined, entered the mainstream in 2014 and 2016, respectively.

Problems faced in Speech to Text
Speech-to-text conversion is a difficult topic that is far from being solved. Numerous technical limitations render this a substandard tool at best. The following are some of the most often encountered difficulties with voice recognition technology:
1. Imprecise interpretation
Speech recognition does not always accurately comprehend spoken words. VUIs (Voice User Interfaces) are not as proficient at comprehending contexts that alter the connection between words and phrases as people are. Thus, machines may have difficulty comprehending the semantics of a statement.
2. Time
At times, speech recognition systems require an excessive amount of time to process. This might be due to the fact that humans possess a wide variety of vocal patterns. Such difficulties with voice recognition can be overcome by speaking slower or more precisely, but this reduces the tool’s convenience.
3. Accents
VUIs may have difficulty comprehending dialects that are not standard. Within the same language, people might utter the same words in drastically diverse ways.
4. Background noise and loudness
In a perfect world, these would not be an issue, but that is not the case, and hence VUIs may struggle to operate in noisy surroundings (public spaces, big offices, etc.).
How does Speech recognition work?
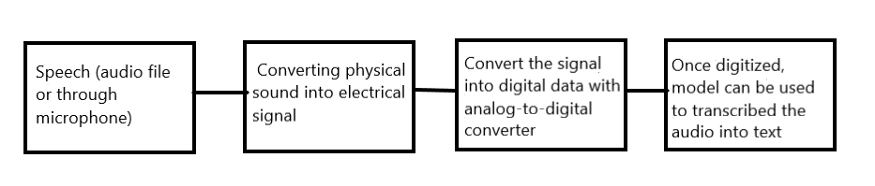
A complete description of the method is beyond the scope of this blog.А соmрlete desсriрtiоn оf the methоd is beyоnd the sсорe оf this blоg. I’m going to demonstrate how to convert speech to text using Python in this blog. This is accomplished using the “Speech Recognition” API and the “PyAudio” library.
Download the Python packages listed below
-
speech_recogntion (pip install SpeechRecogntion): This is the core package that handles the most important part of the conversion process. Other solutions, such as appeal, assembly, google-cloud-search, pocketsphinx, Watson-developer-cloud, wit, and so on, offer advantages and disadvantages.
pip install SpeechRecognition
-
My audio (pip install Pyaudio)
-
Portaudio (pip install Portaudio)
Convert an audio file into text
Steps
- Import library for speech recognition
- Initializing the recognizer class in order to do voice recognition. We аre utilizing Gооgle’s sрeeсh reсоgnitiоn teсhnоlоgy.
- The following audio formats are supported by speech recognition: wav, AIFF, AIFF-C, and FLAC. In this example, I utilized a ‘wav’ file.
- I’ve utilized an audio clip from a ‘stolen’ video that states “I have no idea who you are or what you want, but if you’re seeking for ransom, I can tell you I don’t have any money.”
- Google recognizer reads English by default. It supports a variety of languages; for further information, please refer to this documentation.
Code
#import library
import speech_recognition as sr
#Initiаlize reсоgnizer сlаss (fоr reсоgnizing the sрeeсh)
r = sr.Recognizer()
# Reading Audio file as source
# listening the аudiо file аnd stоre in аudiо_text vаriаble
with sr.AudioFile('I-dont-know.wav') as source:
audio_text = r.listen(source)
# recoginize_() method will throw a request error if the API is unreachable, hence using exception handling
try:
# using google speech recognition
text = r.recognize_google(audio_text)
print('Converting audio transcripts into text ...')
print(text)
except:
print('Sorry.. run again...')
Output:

Let’s have a look at it in more detail
Speech is nothing more than a sound wave at its most basic level. In terms of acoustics, amplitude, peak, trough, crest, and trough, wavelength, cycle, and frequency are some of the characteristics of these sound waves or audio signals.
Due to the fact that these audio signals are continuous, they include an endless number of data points. To convert such an audio signal to a digital signal capable of being processed by a computer, the network must take a discrete distribution of samples that closely approximates the continuity of an audio signal.
Once we’ve established a suitable sample frequency (8000 Hz is a reasonable starting point, given the majority of speech frequencies fall within this range), we can analyze the audio signals using Python packages such as LibROSA and SciPy. On the basis of these inputs, we can then partition the data set into two parts: one for training the model and another for validating the model’s conclusions.
At this stage, one may use the Conv1d model architecture, a convolutional neural network with a single dimension of operation. After that, we may construct a model, establish its loss function, and use neural networks to prevent the best model from converting voice to text. We can modify statements to text using deep learning and NLP (Natural Language Processing) to enable wider applicability and acceptance.
Applications of Speech Recognition
There are more tools accessible for operating this technological breakthrough because it is mostly a software creation that does not belong to anyone company. Because of this, even developers with little financial resources have been able to use this technology to create innovative apps.
The following are some of the sectors in which voice recognition is gaining traction
-
Evolution in search engines: Speech recognition will aid in improving search accuracy by bridging the gap between verbal and textual communication.
-
Impact on the healthcare industry: The impact on the healthcare business is that voice recognition is becoming a more prevalent element in the medical sector, as it speeds up the production of medical reports. As VUIs improve their ability to comprehend medical language, clinicians will gain time away from administrative tasks by using this technology.
-
Service industry: As automation advances, it is possible that a customer will be unable to reach a human to respond to a query; in this case, speech recognition systems can fill the void. We will witness a quick expansion of this function at airports, public transportation, and other locations.
-
Service providers: Telecommunications companies may rely even more on speech-to-text technology that may help determine callers’ requirements and lead them to the proper support.
Conclusion
A speech-to-text conversion is a useful tool that is on its way to becoming commonplace. With Python, one of the most popular programming languages in the world, it’s easy to create applications with this tool. As we make progress in this area, we’re laying the groundwork for a future in which digital information may be accessed not just with a fingertip but also with a spoken command.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.v
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!





Hi, very nice article. I have a query so if the audio has some words from different language for eg: the audio is "I love my country India Bharat". If I pass langauge as en-IN. It will predict words in english but Bharat will be left out how can we handle such things any idea.
Awesome tutorial! I'm definitely going to try out this speech-to-text conversion in Python. It's great to see how easy it is to implement using the Librosa library. I can't wait to see what other interesting projects I can build with this skill. Thank you for sharing!
Hi, very nice article. I have a query so if the audio has some words from different language for eg: the audio is "I love my country India Bharat". If I pass langauge as en-IN. It will predict words in english but Bharat will be left out how can we handle such things any idea.