Overview
- Ever wondered how to use NLP models in Indian languages?
- This article is all about breaking boundaries and exploring 3 amazing libraries for Indian Languages
- We will implement plenty of NLP tasks in Python using these 3 libraries and work with Indian languages
Introduction
Language is a wonderful tool of communication – its powered the human race for centuries and continues to be at the heart of our culture. The sheer amount of languages in the world dwarf our ability to master them all.
In fact, a person born and brought up in part of the country might struggle to communicate with a fellow person from a different state (yes, I’m talking about India!). It’s a challenge a lot of us face in today’s borderless world.
This is a research area that Natural Language Processing (NLP) techniques have not yet managed to master. The majority of breakthroughs and state-of-the-art frameworks we see are developed in the English language. I have long wondered if we could use that and build NLP applications in vernacular languages.
Human beings by nature are diverse and multilingual, so it makes sense, right?
Since the Indian subcontinent itself has a multitude of languages, dialects and writing styles spoken by more than a billion people, we need tools to work with them. And that’s the topic of this article.
We will learn how to work with these languages using existing NLP tools, compare them relatively in terms of various parameters, and learn some challenges/limitations that this area faces.
Here’s what we’ll cover in this article:
Table of contents
What are the Languages of the Indian Subcontinent?
The Indian Subcontinent is a combination of many nations, here’s what Wikipedia says:
The Indian subcontinent is a term mainly used for the geographic region surrounded by the Indian Ocean: Bangladesh, Bhutan, India, Maldives, Nepal, Pakistan and Sri Lanka.
These nations represent great diversity in languages, cultures, cuisines etc.
Even within India itself, there are a multitude of languages that are spoken and used in day to day life which itself showcases the basic need to be able to build NLP based applications in vernacular languages.

These are some of the languages of the Indian Subcontinent that are supported by libraries we’ll see in this article (each library lists only unique languages it supports as there are many overlapping languages like hindi):
- iNLTK- Hindi, Punjabi, Sanskrit, Gujarati, Kannada, Malyalam, Nepali, Odia, Marathi, Bengali, Tamil, Urdu
- Indic NLP Library- Assamese, Sindhi, Sinhala, Sanskrit, Konkani, Kannada, Telugu,
- StanfordNLP- Many of the above languages
Text Processing for Indian Languages using Python
There are a handful of Python libraries we can use to perform text processing and build NLP applications for Indian languages. I’ve put them together in this diagram:

All of these libraries are prominent projects that researchers and developers are actively utilizing and improving for working with multiple languages. Each library has its own strengths and that’s why we will explore them one by one.
1. iNLTK (Natural Language Toolkit for Indic Languages)

As the name suggests, the iNLTK library is the Indian language equivalent of the popular NLTK Python package. This library is built with the goal of providing features that an NLP application developer will need.
Let’s explore the features of this library.
Installing iNLTK
iNLTK has a dependency on PyTorch 1.3.1, hence you have to install that first:
pip install torch==1.3.1+cpu -f https://download.pytorch.org/whl/torch_stable.html
You can then install iNLTK using pip:
pip install inltk
Language support
iNLTK currently supports 12 languages of the Indian Subcontinent:

That’s quite a diverse collection of languages!
Setting the language
iNLTK has language models trained for different languages and in order to use one, we have to download its files first. We will be working with Hindi text, so let’s set “Hindi” as our language:
from inltk.inltk import setup setup('hi')
This will download all the necessary files to make inferences for Hindi.
Tokenization
The first step we do to solve any NLP task is to break down the text into its smallest units or tokens. iNLTK supports tokenization of all the 12 languages I showed earlier:
Let’s look at the output of the above code:

The input text in Hindi is nicely split into words and even the punctuations are captured. This was a basic task – let’s now see some interesting applications of iNLTK!
Generate similar sentences from a given text input
Since iNLTK is internally based on a Language Model for each of the languages it supports, we can do interesting stuff like generate similar sentences given a piece of text!
The first parameter is the input sentence. Next, we pass the number of similar sentences we want (here it’s 5) and then we pass the language code which is ‘hi’ for Hindi.
Here’s the model’s output:

This feature of iNLTK is very useful for text data augmentation as we can just multiply the sentences in our training data by populating it with sentences that have a similar meaning.
Identify the language of a text
Knowing what language a particular text is written in can be very useful when building vernacular applications or working with multilingual data. iNLTK provides this very useful functionality as well:
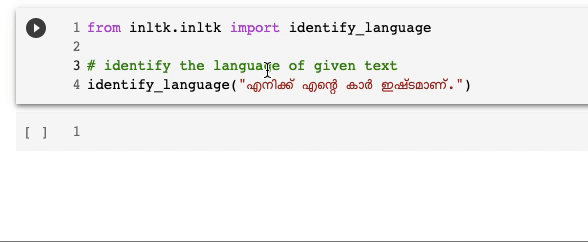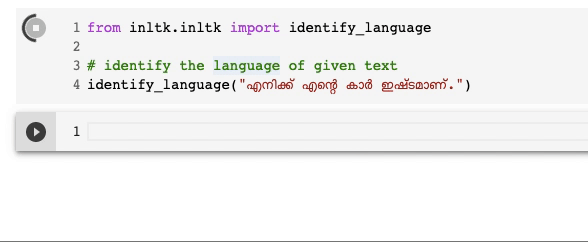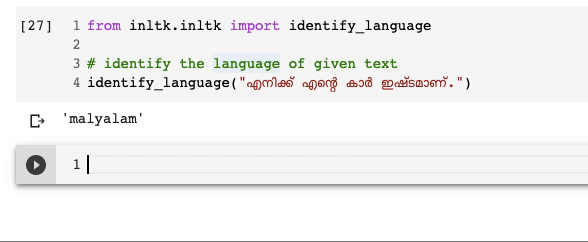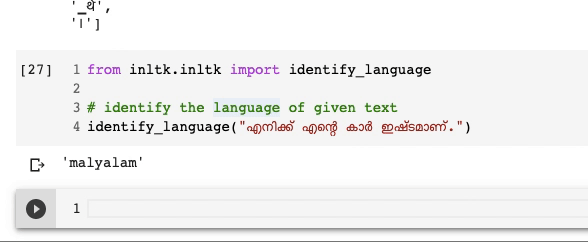
Above is an example of a sentence written in Malayalam that iNLTK correctly identifies.
Extract embedding vectors
When we are training machine learning or deep learning-based models for NLP tasks, we usually represent the text data by an embedding like TF-IDF, Word2vec, GloVe, etc. These embedding vectors capture the semantic information of the text input and are easier to work with for the models (as they expect numerical input).
iNLTK under the hood utilizes the ULMFiT method of training language models and hence it can generate vector embeddings for a given input text. Here’s an example:
We get two embedding vectors, one for each word in the input sentence:
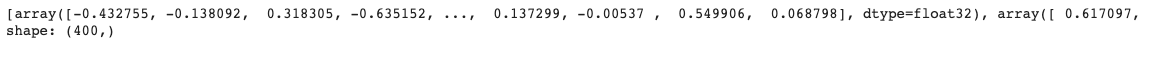
Notice that each word is denoted by an embedding of 400 dimensions.
Text completion
Text completion is one of the most exciting aspects of language modeling. We can use it in multiple situations. Since iNLTK internally uses language models, you can easily use it to auto-complete the input text.
In this example, I have taken a Bengali sentence that says “The weather is nice today”:
Here, the fourth parameter is to adjust the “randomness” of the model to make different generations (you can play with this value). The model gives a prompt output:
'আবহাওয়া চমৎকারভাবে, সরলভাবে এক-একটি সৃষ্টির দিনক্ষণ'
This roughly translates to ‘The weather is excellent, simply a day of creation’ (according to Google Translate). It’s an interestingly smooth output, isn’t it?
We can often use text generation abilities of a language model to augment the text dataset, and since we usually have small datasets for vernacular languages, this feature of iNLTK comes in handy.
Finding similarity between two sentences
iNLTK provides an API to find semantic similarities between two pieces of text. This is a really useful feature! We can use the similarity score for feature engineering and even building sentiment analysis systems. Here’s how it works:
I have given two sentences as input above. The first one roughly translates to “I like food” while the second one means “I appreciate food that tastes good” in Hindi. The model gives out a cosine similarity of 0.67 which means that the sentences are pretty close, and that’s correct.
Apart from cosine similarity, you can pass your own comparison function to the cmp parameter if you want to use a custom distance metric.
Additionally, there are many interesting features that the library provides and I urge you to check out iNLTK’s documentation page for more information.
2. Indic NLP Library
I find the Indic NLP Library quite useful for performing advanced text processing tasks for Indian languages. Just like iNLTK was targeted towards a developer working with vernacular languages, this library is for researchers working in this area.
Here is what the official documentation says about Indic NLP’s objective:
This library provides the following set of functionalities:
- Text Normalization
- Script Information
- Tokenization
- Word Segmentation
- Script Conversion
- Romanization
- Indicization
- Transliteration
- Translation
We’ll explore all of them one by one in this article. But first, let’s have a look at the different languages this library supports out of the box and which functionality is available for what language:
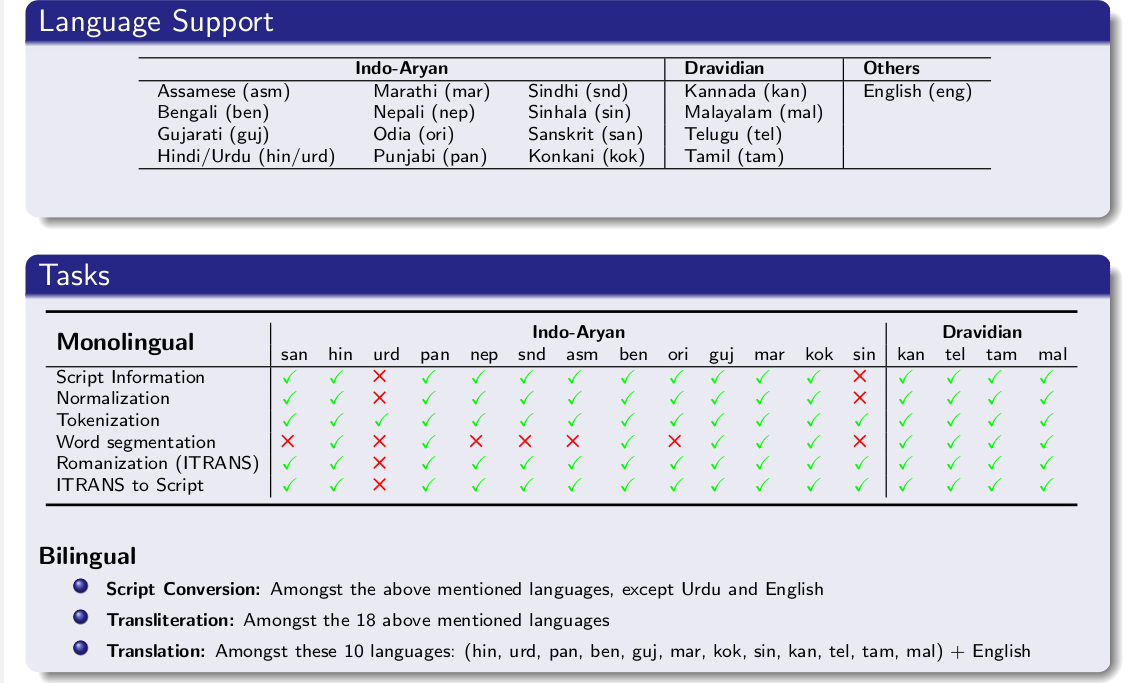
As you can see, the Indic NLP Library supports a few more languages than iNLTK, including Konkani, Sindhi, Telugu, etc. Let’s explore the library further!
Installing the Indic NLP Library
You can install the library using pip:
pip install indic-nlp-library
# download the resource
git clone https://github.com/anoopkunchukuttan/indic_nlp_resources.git
Apart from its API, this library also provides certain scripts that are useful for NLP. You can clone the GitHub folder itself to get them:
# download the repo
git clone https://github.com/anoopkunchukuttan/indic_nlp_library.git
Now that all the files are downloaded, you can set the path so that Python knows where to find these on your computer:
The above steps might take some time due to the size of the resources. Once you are done with these steps, you are ready to start!
Splitting input text into sentences
Indic NLP Library supports many basic text processing tasks like normalization, tokenization at the word level, etc. But sentence level tokenization is what I find interesting because this is something that different Indian languages follow different rules for.
Here is an example of how to use this sentence splitter
Here is the output:
तो क्या विश्व कप 2019 में मैच का बॉस टॉस है? यानी मैच में हार-जीत में टॉस की भूमिका अहम है? आप ऐसा सोच सकते हैं। विश्वकप के अपने-अपने पहले मैच में बुरी तरह हारने वाली एशिया की दो टीमों पाकिस्तान और श्रीलंका के कप्तान ने हालांकि अपने हार के पीछे टॉस की दलील तो नहीं दी, लेकिन यह जरूर कहा था कि वह एक अहम टॉस हार गए थे।
Now, what if I tell you that you can do the same for all 15 Indian languages that Indic NLP Library supports? Fascinating, isn’t it?
Transliteration among various Indian Language Scripts
Transliteration is when you convert a word written in one language such that it is written using the alphabet of the second language. Note that this is very different from “Translation” wherein you also convert the word itself to the second language so that it’s “meaning” is maintained.
Here is an example to illustrate the difference:

Here is how you can perform transliteration using the Indic NLP Library:
In the above example, we have a sentence written in Hindi and we want to transliterate it to Telugu. This is the output of the model:
This is a near-perfect transliteration!
Converting Indian Languages to Roman Script
This is a feature that will be very helpful when working with social media data of non-native English speakers as they have a tendency to mix and interchange language every now and then in their posts.
English follows Roman Script for the alphabet, hence we can “Transliterate” any Indian language text to English using this library:
Here is what the model gives as output:
aaja mausama achchaa hai. isalie hama aaja khela sakate hai !
Very cool, isn’t it? This is something most of us can relate to as a lot of times we type our local language using English alphabets (I’m looking at all you texting people!).
Understanding the phonetics of a character
Phonetics of a character describe the speech property of that character (like how will it sound, how much tongue should be rolled to pronounce it, etc.)
Here is an example of a phonetic property that defines how the character “k” is spoken:

The Indian Sub-Continent languages have strong phonetics for their alphabet and that’s why in the Indic NLP Library, each character has a phonetic vector associated with it that defines its properties.
How is this useful? Well, you can basically take the character of a new language and just learn almost everything about it – from whether it is a vowel or consonant to how is the tongue rolled to pronounce that word?
Here is an example where we take the simple Hindi character ‘आ’ :
Here is the output:

How similar do two characters sound?
Many languages have multiple characters that have a similar sound or are spoken similarly but used in different settings in words. Can you think of any off the top of your head?
In English, it would be the characters “k” and “c”. While growing up, I’d often wonder why it was written as “school” but pronounced as “skool”? That’s exactly what I’m talking about here.
Similarly, in Hindi, we have characters ‘क’ and ‘ख’ that are confused a lot due to their sound being very similar.
Let’s find how phonetically similar these characters are using the Indic NLP Library:
I have also used a third character ‘भ’ for comparison purposes. Let’s see what output the model gives:

As expected, there is a higher similarity between ‘क’ and ‘ख’ than ‘क’ and ‘भ’.
Splitting words into Syllables

We can use the Indic NLP Library to split words of Indian Languages into their syllables. This is really useful because languages have unique rules that govern what makes a syllable.
For example, when we consider the case of Indian Languages in general and Hindi, in particular, you’d notice that the concept of matras is very important when considering syllables. Here’s an example in Hindi:

This type of syllabification is known as Orthographic Syllabification. Let’s see how we can do this in Python:
We have given the Hindi word ‘जगदीशचंद्र’ as input and here’s the output:
ज ग दी श च ंद्र
Notice how the various syllables have been properly identified! If you want to learn more about Orthographic Syllabification, you can read the paper – Orthographic Syllable as a basic unit for SMT between Related Languages.
Now that we have learned a fair bit of NLP tasks that we can perform with Indian Languages, let’s go to the next step with StanfordNLP.
3. StanfordNLP

StanfordNLP is an NLP library right from Stanford’s Research Group on Natural Language Processing.
The most striking feature of this library is that it supports around 53 human languages for text processing!
Out of these languages, StanfordNLP supports Hindi and Urdu that belong to the Indian Sub-Continent.
StanfordNLP is good for generating features of Computational Linguistics like Named Entity Recognition (NER), Part of Speech (POS) tags, Dependency Parsing, etc. Let’s see a glimpse of this library!
Installing StanfordNLP
1. Install the StanfordNLP library:
pip install stanfordnlp
2. We need to download a language’s specific model to work with it. Launch a Python shell and import StanfordNLP:
import stanfordnlp
3. Then download the language model for Hindi (“hi”):
stanfordnlp.download('hi')
This can take a while depending on your internet connection. These language models are pretty huge (the English one is 1.96GB).
Note: You need Python 3.6.8/3.7.2 or later to use StanfordNLP.
Extracting Part of Speech (POS) Tags for Hindi
StanfordNLP comes with built-in processors to perform five basic NLP tasks:
- Tokenization
- Multi-Word Token Expansion
- Lemmatization
- Parts of Speech Tagging
- Dependency Parsing
Let’s start by creating a text pipeline:
nlp = stanfordnlp.Pipeline(processors = "pos")Now, we will first take a piece of Hindi text and run the StanfordNLP pipeline on it:
hindi_doc = nlp("""केंद्र की मोदी सरकार ने शुक्रवार को अपना अंतरिम बजट पेश किया. कार्यवाहक वित्त मंत्री पीयूष गोयल ने अपने बजट में किसान, मजदूर, करदाता, महिला वर्ग समेत हर किसी के लिए बंपर ऐलान किए. हालांकि, बजट के बाद भी टैक्स को लेकर काफी कन्फ्यूजन बना रहा. केंद्र सरकार के इस अंतरिम बजट क्या खास रहा और किसको क्या मिला, आसान भाषा में यहां समझें""")
Once you have done this, StanfordNLP will return an object containing the POS tags of the input text. You can use the below code to extract the POS tags:
Once we call the extract_pos(hindi_doc) function, we will able to see the correct POS tags for each word in the input sequence along with their explanations:

An interesting fact about StanfordNLP is that its POS tagger performs accurately for a majority of words. It is even able to pick the tense of a word (past, present or future) and whether the word is in base or plural form.
If you want to read more about StanfordNLP and how you can use it for other tasks, feel free to this article.
India nlp library in python
Natural Language Processing (NLP) libraries for Indian languages in Python! Here are two excellent options:
1. Indic NLP Library:
- Focus: Built specifically for handling common text processing and NLP tasks in Indian languages.
- Strengths:
- Wide range of functionalities, including text normalization, script identification, tokenization, word segmentation, script conversion (romanization, indicization, transliteration), and translation.
- Designed to leverage the commonalities between Indic languages for a general solution.
- Installation:
pip install indic-nlp-library - Documentation: While an official documentation website might not be readily available, you can find comprehensive information and examples on the project’s GitHub repository: [GitHub indic nlp library]
2. iNLTK (Natural Language Toolkit for Indic Languages):
- Focus: Inspired by the popular NLTK library, iNLTK provides features tailored for NLP tasks in Indian languages.
- Strengths:
- Intuitive and easy-to-use API for tasks like text processing, tokenization, sentence similarity, and word embedding generation.
- Good fit for developers familiar with NLTK.
- Installation:
pip install inltk - Documentation: You can find detailed documentation for iNLTK online, though it might not be as actively maintained as the Indic NLP Library: [inltk documentation] (Consider searching for up-to-date information if needed.)
Choosing the Right Library:
The best choice depends on your specific needs:
- If you require a comprehensive set of features specifically designed for Indic languages, the Indic NLP Library is a strong contender.
- If you’re already comfortable with NLTK and prefer a familiar API, iNLTK could be a good option.pen_spark
Conclusion
You’d have already noticed in this article that there are useful libraries to perform NLP on Indian languages, but even then these libraries have a long way to go in terms of functionality when compared with the likes of spaCy, NLTK and other NLP libraries that majorly support European languages. After Reading this Article you will get full understanding on india languages nlp.
Good news is that the research in multilingual NLP has only risen over the last couple of years and in no time you should be able to see a plethora of options to choose from.
Have you worked with Indian languages before? Do you think there is a library that should be on this list? If yes, mention in the comments below!
Sanad is a Senior AI Scientist at Analytics Vidhya, turning cutting-edge AI research into real-world Agentic AI products. With an MS in Artificial Intelligence from the University of Edinburgh, he’s worked at top research labs tackling multilingual NLP and NLP for low-resource Indian languages. Passionate about all things AI, he loves bridging the gap between deep research and practical, impactful products.







Great post and useful to all working with Indic. One remark. The breakup of जगदीशचंद्र in orthographic syllabification is incorrect. ज ग दी श च ंद्र- The nasal should affix itself to च ज ग दी श चं द्र as per the rules of akshar or the Indic syllable. The split is not correct and may lead to errors if deployed in areas such as TTS.
Hi Raymond, Thanks for pointing it out, you are right. Authors of the Indic NLP Library do mention this as one of the two exceptions to the Orthographic Syllabification process: "The characters "anusvaara" and "chandrabindu" are part of the OS to the left if they represents nasalization of the vowel/consonant or start a new OS if they represent a nasal consonant."
Great effort in making such great stuff in understanding of Indian languages using NLP
Awesome Article . Keep up the Good work Man !! Which version of Python you used for this ? I am facing couple of errors while trying this - setup('hi') RuntimeError: This event loop is already running output = get_similar_sentences('मैं आज बहुत खुश हूं', 5, 'hi') AttributeError: 'LSTM' object has no attribute '_flat_weights_names' I did have torch torch==1.4.0 version.