This article was published as a part of the Data Science Blogathon
Have you ever used ‘Google translate’ or ‘Grammarly’ or while typing in Gmail have you ever wondered how does it knows what word I want to type so perfectly? The answer is using a recurrent neural network (RNN), well to be precise a modification of RNN. The entire list of use cases of RNN can be an article on itself and easily found on the internet. I will try in this article (and articles following this) to give you an intuition behind the inner workings of Recurrent Neural Networks.
Prerequisites:
- Basic understanding of Neural Networks
- Awareness of basic terminologies of NLP like corpus, one hot coding, etc…
What is a Recurrent Neural Network (RNN)?
RNN’s are a variety of neural networks that are designed to work on sequential data. Data, where the order or the sequence of data is important, can be called sequential data. Text, Speech, and time-series data are few examples of sequential data.
What is the need for RNN when we have simple neural networks?
We will understand the need with the help of an example. Suppose we have few reviews of restaurants and our task is to predict whether the review is positive or negative. To feed data into any neural network we first have to represent the text in machine-understandable form.
Let us divide the sentence into separate tokens by splitting them by white space character and one hot encode each token.

Source: Author
Sentence 1: ‘Delightful place to have dinner’
For sentence 1 we see Tx (Total number of words or tokens in the sentence)=5.
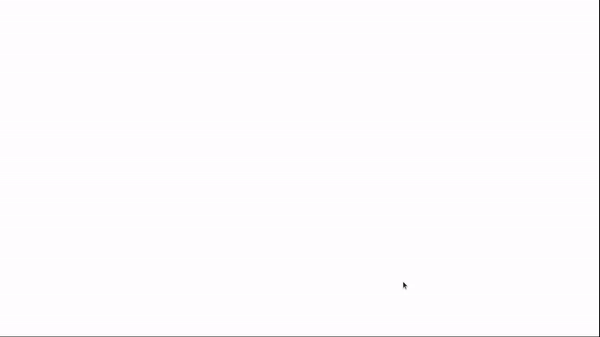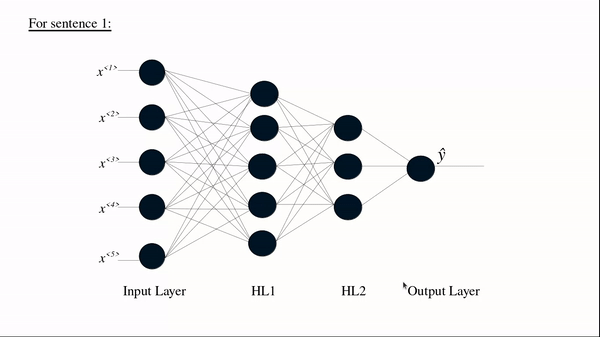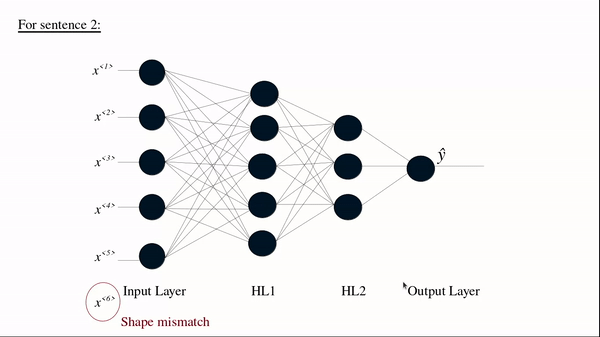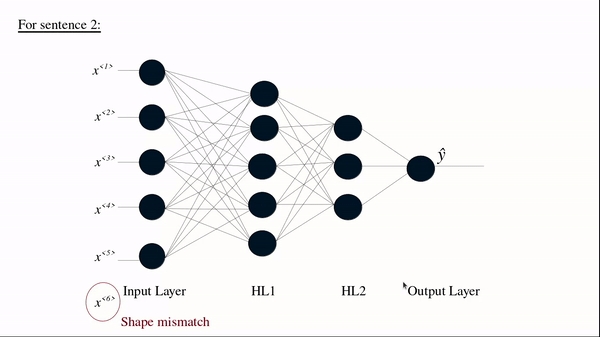
Source: Author
Sentence 2: ‘Food was nice but service wasn’t’
For sentence 2 we can see Tx=6. But the input layer in architecture for our DNN is fixed. We can see that there is no direct way to feed data into the network.
Okay, you might ask why don’t we convert each sentence to be length equal to that of the sentence with maximum length by adding zeros. That might solve the problem of varying lengths of input but another problem occurs. Our number of parameters becomes astronomically high.
Suppose the maximum length of the sentence is 20 which pretty small for most data sets available.
Let the number of words in corpus= 20k (considering a very small corpus)
Then each input will become 400k dimensional and with just 10 neurons in the hidden layer, our number of parameters becomes 4 million! To have a proper network means having billions of parameters. To overcome this we need to have a network with weight sharing capabilities.
Now we know the need for a new variety of architecture. Let’s see how RNN solves this problem.
Visualizing the RNN

Source: Author
Recurrent means repeating and the idea in RNN is to have layers that repeat over a period of time. In RNN given a sentence, we first tokenize and one hot encode each word of a sentence. Then we input each token to RNN over time.
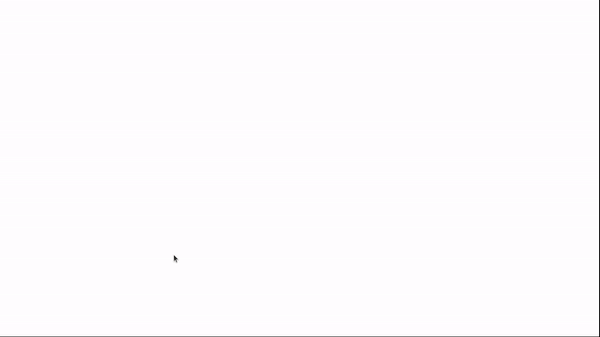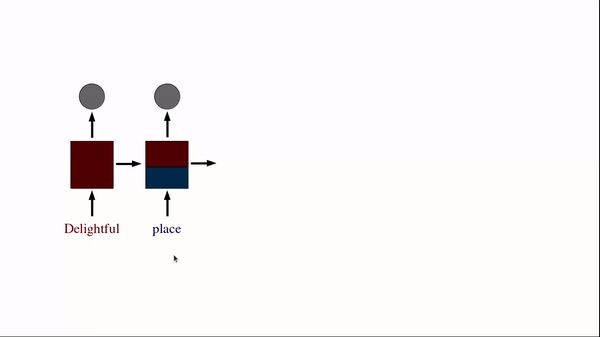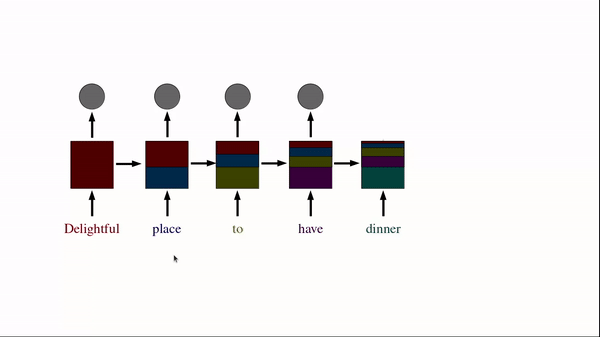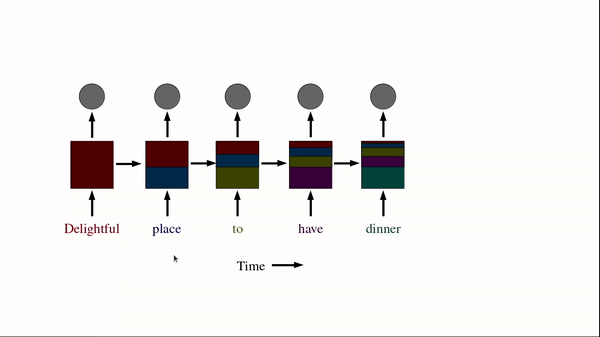
Source: Author
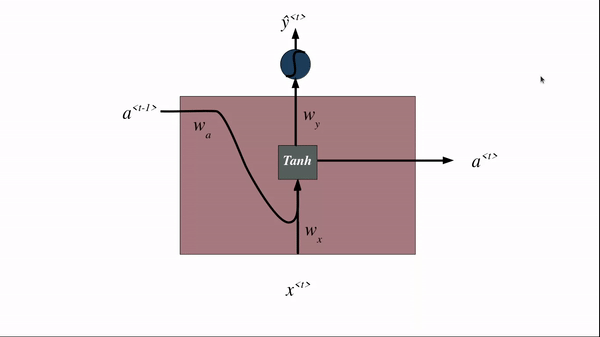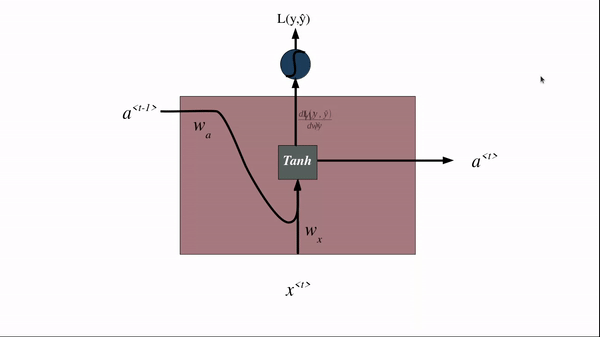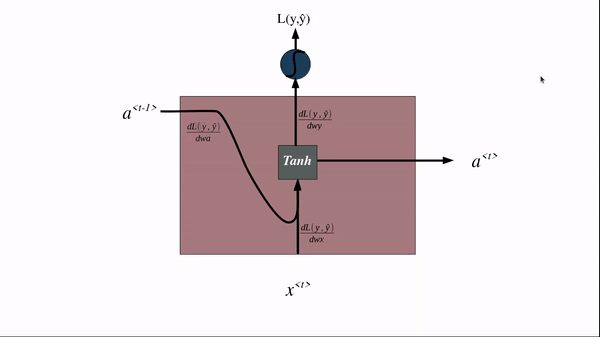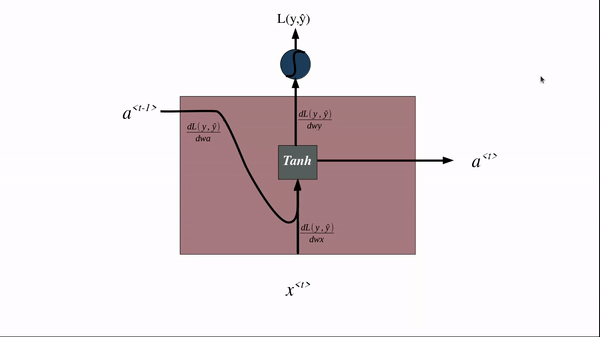
We can see in the above image where RNN being unrolled over time. Unrolling means we are using the same RNN block at each point of time and the output of the previous time step becomes the input for the current time step. Let us visualize what an RNN block for a single time step looks like…
.gif)
Source: Author
Hidden state stores information about all the previous inputs in a weighted manner. Most recent inputs get higher values and older inputs get lower values. The hidden state of the previous time step gets concatenated with the input of the current time step and is fed into the tanh activation. The tanh activation scales all the values between -1 to 1 and this becomes the hidden state of the current time step. Based on the type of RNN if we want to predict output at each step, this hidden state is fed into a softmax layer and we get the output for the current time step. The current hidden state becomes the input to the RNN block of the next time step. This process goes on until the end of the sentence.
.gif)
Source: Author
Now we have a prediction at each time step. We compare it with actual labels and compute the loss for each time step. This concludes a single forward propagation step in an RNN.
The backpropagation of an RNN occurs in the exact reverse manner of forwarding propagation.
Source: Author
The crux of the idea is same weights are used in all the time steps hence the number of parameters is independent of input length and each of the weights gets updated during backpropagation through time.
I hope that gave you some idea of the inner workings of RNN’s. Let’s look at the various types of RNN along with their uses.
Types of RNN
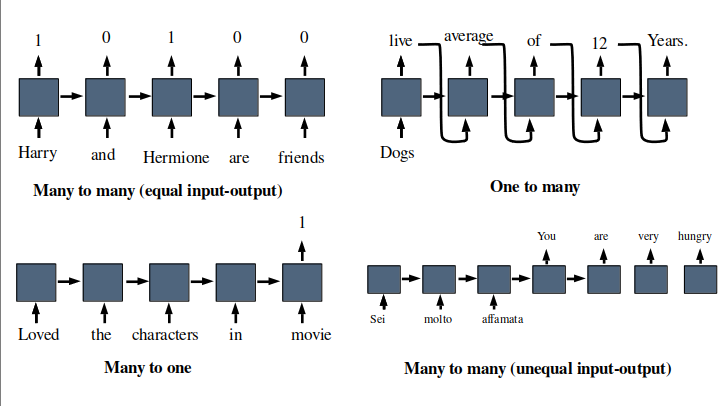
Source: Author
Many to many (Equal input-output): Named entity recognition, Part of speech recognition.
Many to one: Sentiment classification, Movie rating prediction
One to many: Novel sequence generation, Image captioning.
Many to many(Unequal input-output): Machine translation, Speech recognition.
Limitations of RNN

Source: imgflip.com
Recurrent Neural Networks suffer from short-term memory. If a sequence is long enough, they’ll have a hard time carrying information from earlier time steps to later ones. So if you are trying to process a paragraph of text to do predictions, RNN’s may leave out important information from the beginning.
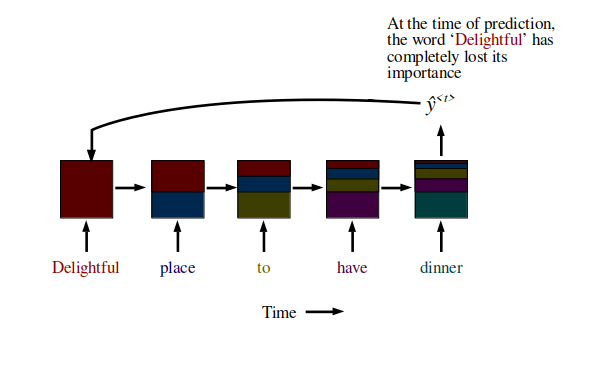
Source: Author
The next article will see and understand how LSTM’s and GRU’s tackle these problems. Before I end this article here are few implementation details about building an RNN.
- For the first RNN block, since we have no previous hidden state available, it is common to input a vector of zeros.
- While inputting texts of varying lengths we pad each text to make each sequence of equal lengths.
- To specify the start and end of a sentence we can and tokens.
I hope after reading this some doubts regarding RNN might have cleared. Do reach out in the comments if you still have any doubts.
You can connect with me at: https://www.linkedin.com/in/baivab-dash
Have a nice day.


