Are you struggling to tackle complex language tasks like machine translation, text summarization, or chatbot creation? Look no further than the groundbreaking seq2seq models – the neural network architectures taking the deep learning world by storm. These innovative encoder-decoder models, built with recurrent neural networks (RNNs) like LSTMs and GRUs, have revolutionized how we process and generate sequential data.
At the core of seq2seq models lies the attention mechanism, a game-changer that allows the decoder to focus dynamically on the most relevant parts of the input sequence. This attention-based approach boosts accuracy and provides valuable insights into the model’s decision-making process. While classical seq2seq models faced hurdles with long sequences, the advent of transformers using self-attention has pushed the boundaries further. From neural machine translation to image captioning and beyond, seq2seq models have left an indelible mark on natural language processing (NLP) and computer vision. In this tutorial, we will unlock their full potential with large datasets, optimized architectures like the encoder-decoder network, and cutting-edge optimizers – endless possibilities!

Table of contents
What are Seq2Seq Models?
Seq2Seq (Sequence-to-Sequence) models are a type of neural network, an exceptional Recurrent Neural Network architecture, designed to transform one data sequence into another. They are handy for tasks where the input and output are sequences of varying lengths, which traditional neural networks struggle to handle, such as solving complex language problems like machine translation, question answering, creating chatbots, text summarization, etc.
Use Cases of the Sequence to Sequence Models
- Machine Translation: One of the most prominent applications of Seq2Seq models is translating text from one language to another, such as converting English sentences into French sentences.
- Text Summarization: Seq2Seq models can generate concise summaries of longer documents, capturing the essential information while omitting less relevant details.
- Speech Recognition: Converting spoken language into written text. Seq2Seq models can be trained to map audio signals (sequences of sound) to their corresponding transcriptions (sequences of words).
- Chatbots and Conversational AI: These models can generate human-like responses in a conversation, taking the previous sequence of user inputs and generating appropriate replies.
- Image Captioning: Seq2Seq models can describe the content of an image in natural language. The encoder processes the image (often using Convolutional Neural Networks, CNNs) to produce a context vector, which the decoder converts into a descriptive sentence.
- Video Captioning: Similar to image captioning but with videos, Seq2Seq models generate descriptive texts for video content, capturing the sequence of actions and scenes.
- Time Series Prediction involves predicting the future values of a sequence based on past observations. This application is expected in finance (stock prices), meteorology (weather forecasting), and more.
- Code Generation: This process generates code snippets or entire programs from natural language descriptions, which is helpful in programming assistants and automated software engineering tools.
Benefits of Sequence-to-Sequence Models
- Flexibility with Input and Output Sequences: Seq2Seq models can handle variable-length input and output sequences, particularly those using the encoder-decoder architecture. This makes them suitable for tasks like machine translation, where the length of the input sentence (e.g., English) and the output sequence (e.g., French) can differ significantly.
- Effective Handling of Sequential Data: Utilizing recurrent neural networks (RNNs) such as Long Short Term Memory (LSTM) and GRU in the encoder-decoder structure allows Seq2Seq models to capture long-range dependencies within the input sequence. This is crucial for understanding context and meaning in tasks like text summarization and neural machine translation.
- Attention Mechanism: Introducing the attention mechanism enhances the performance of Seq2Seq models by allowing the decoder to focus on relevant parts of the input sequence at each time step. This addresses the limitation of compressing all input information into a single context vector and significantly improves accuracy in tasks requiring nuanced understanding, such as image captioning and natural language processing (NLP) applications.
- Versatility in Application: Seq2Seq models are not limited to text-based tasks. They are also employed in speech recognition, video captioning, and time series prediction. Their ability to process and generate sequences makes them a powerful tool in various deep-learning applications.
Limitations of Sequence to Sequence Models
- Computational Complexity: Training Seq2Seq models can be computationally intensive, especially those using Long Short-Term Memory (LSTM) or GRU networks. The requirement for significant training data and large batch sizes can lead to high computational costs and longer epochs.
- Difficulty in Handling Long Sequences: While RNNs and their variants (LSTM, GRU) are designed to handle sequential data, they can struggle with long sequences due to the vanishing gradient problem, which impacts the learning of long-range dependencies. Even with attention mechanisms, this can remain challenging in tasks requiring detailed context over extended sequences.
- Dependency on Large Datasets: Seq2Seq models require extensive and diverse datasets for practical training. Insufficient or poor-quality training data can lead to overfitting and reduced generalization capacity of the model, impacting the model’s performance on unseen data.
- Performance Variability with Architecture Choices: The performance of Seq2Seq models can vary significantly based on architectural choices and hyperparameters, such as the number of layers in the encoder-decoder, the size of the hidden state, and the specific optimizer used (e.g., Adam). Fine-tuning these parameters is often necessary but can be complex and time-consuming.
- Emerging Competition from Transformers: Transformers and their variants (like BERT and GPT) have been shown to outperform traditional Seq2Seq models in many tasks by eliminating the need for sequential processing and better handling of long-range dependencies. This has led to a shift in focus within natural language processing (NLP).
Encoder-Decoder Architecture
The most common architecture used to build Seq2Seq models is Encoder-Decoder architecture.

As the name implies, there are two components — an encoder and a decoder.
Encoder
- Both the encoder and the decoder are Long short-term memory (LSTM) models (or sometimes GRU models)
- The encoder reads the input sequence and summarizes the information in something called the internal state vectors or context vectors (in the case of LSTM, these are called the hidden state and cell state vectors). We discard the outputs of the encoder and only preserve the internal states. This context vector aims to encapsulate the information for all input elements to help the decoder make accurate predictions.
- The hidden states h_i are computed using the formula:
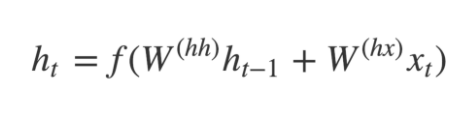

The LSTM reads the data, one sequence after the other. Thus if the input is a sequence of length ‘t’, we say that LSTM reads it in ‘t’ time steps.
1. Xi = Input sequence at time step i.
2. hi and ci = The LSTM maintains two states (‘h’ for hidden state and ‘c’ for cell state) at each time step. Combined, these are the internal states of the LSTM at time step i.
3. Yi = Output sequence at time step i. Yi is actually a probability distribution over the entire vocabulary generated by using a softmax activation. Thus, each Yi is a vector of size “vocab_size” representing a probability distribution.
Decoder
- The decoder is a long-short-term memory (LSTM) whose initial states are initialized to the final states of the Encoder LSTM. In other words, the encoder sector of the encoder’s final cell is input to the first cell of the decoder network. Using these initial states, the decoder starts generating the output sequence, and these outputs are also considered for future outputs.
- A stack of several LSTM units where each predicts an output y_t at a time step t.
- Each recurrent unit accepts a hidden state from the previous unit and produces an output and its hidden state.
- Any hidden state h_i is computed using the formula:
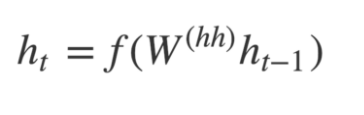
- The output y_t at time step t is computed using the formula:
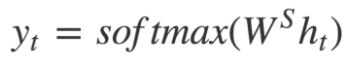
- We calculate the outputs using the hidden state at the current time step and the respective weight W(S). Softmax creates a probability vector to help us determine the final output (e.g., word in the question-answering problem).

Drawbacks of Encoder-Decoder Models
There are two primary drawbacks to this architecture, both related to length.
- Firstly, as with humans, this architecture has minimal memory. The ultimate hidden state of the Long Short Term Memory (LSTM), S or W, is tasked with encapsulating the entire sentence for translation. Typically, S or W comprises only a few hundred units (i.e., floating-point numbers). However, cramming too much into this fixed-dimensional vector increases glossiness in the neural network. Thinking of neural net”orks in terms of the “lossy compression” they must perform is sometimes quite useful.
- Second, as a general rule of thumb, the deeper a neural network is, the harder it is to train. For recurrent neural networks, the longer the sequence is, the deeper the neural network is along the time dimension. This results in vanishing gradients, where the gradient signal from the objective that the recurrent neural network learns from disappears as it travels backward. Even with RNNs specifically made to help prevent vanishing gradients, such as the LSTM, this is still a fundamental problem.

Furthermore, we have models like Attention Models and Transformers for more robust and lengthy sentences.
Attention Mechanism
The attention mechanism is crucial in many modern neural network architectures, especially in tasks involving sequences like natural language processing and computer vision. Its primary function is to allow the model to dynamically focus on different parts of the input sequence (or image) while processing the output sequence. Here are some key aspects and benefits of attention mechanisms:
Checkout this article about the Machine Learning Algorithms
Key Aspects of Attention Mechanism
- Dynamic Weighting: Instead of relying on a fixed-length context vector to encode the entire input sequence, attention mechanisms assign different weights to different parts of the input sequence based on their relevance to the current step of the output sequence. This dynamic weighting enables the model to focus more on relevant information and ignore irrelevant parts.
- Soft Alignment: Attention mechanisms create a soft alignment between the input and output sequences by computing a distribution of attention weights over the input sequence. This allows the model to consider multiple input elements simultaneously, unlike hard alignment methods that force the model to choose only one input element at each step.
- Scalability: Attention mechanisms are scalable to sequences of varying lengths. They can adapt to longer input sequences without significantly increasing the computational complexity, unlike fixed-length context vectors, which may struggle with long sequences.
- Interpretable Representations: Attention weigh’s represent the model’s decision-making process. By visualizing these weights, researchers and practitioners can gain insights into which parts of the input sequence are most relevant for generating specific parts of the output sequence.
Transformers
Transformers, a breakthrough in deep learning, have significantly impacted Seq2Seq models, particularly in natural language processing (NLP) tasks. Unlike traditional Seq2Seq models based on recurrent neural networks (RNNs), transformers rely on self-attention mechanisms to capture long-range dependencies in input sequences, making them highly effective for sequence-to-sequence tasks.
The architecture of transformer-based Seq2Seq models consists of an encoder-decoder framework, similar to traditional Seq2Seq models. However, instead of recurrent layers, transformers employ self-attention layers, enabling the model to dynamically weigh the importance of different input tokens.
Key Aspects of Transformer-based Seq2Seq Models
Key components of transformer-based Seq2Seq models include:
- Encoder: The encoder comprises multiple layers of self-attention mechanisms and feed-forward neural networks. It processes the input sequence in parallel, allowing the model to efficiently capture dependencies across the entire sequence.
- Decoder: Similar to the encoder, the decoder consists of self-attention layers and feed-forward networks. It generates the output sequence token by token, attending to relevant parts of the input sequence using the attention mechanism.
- Self-Attention Mechanism: This mechanism allows each token in the input sequence to attend to all other tokens, effectively capturing contextual information. By assigning different attention weights to each token, the model can focus on relevant information and ignore irrelevant parts.
- Positional Encoding: Since transformers do not inherently understand the sequential order of tokens, positional encodings are added to the input embeddings to provide information about token positions. This ensures that the model can differentiate between tokens based on their positions in the sequence.
- Multi-Head Attention: Transformers typically use multi-head attention mechanisms, where attention is calculated multiple times in parallel with different learned linear projections. This allows the model to capture diverse relationships between tokens.
- Feed-Forward Neural Networks: These networks are applied after the self-attention layers to perform nonlinear transformations on the encoded representations, facilitating the learning of complex patterns in the data.
Application of Seq2Seq Models
Seq2Seq (Sequence-to-Sequence) models find applications in a wide range of tasks where the input and output are sequences of varying lengths. One prominent example of Seq2Seq models in action is in machine translation, where they excel at translating text from one language to another. Let’s explore this application using an example:
Consider a scenario where we have a Seq2Seq model trained to translate English sentences into French. Here’s how the process works:
- Input Sequence(English Sentence): “How are you today?”
- Target Sequence (French Translation): “Comment vas-tu aujourd’hui ?”
Now, let’s break down how the Seq2Seq model translates the input sequence into the target sequence:
Encoder Stage:
- The input sequence “How are you today?” is fed into the encoder part of the Seq2Seq model.
- The encoder, typically composed of LSTM or GRU layers, processes the input sequence token by token, generating a fixed-size representation known as the context vector or hidden state.
- Each token in the input sequence is encoded into a high-dimensional vector representation, capturing its semantic meaning and context within the sentence.
- The final hidden state of the encoder contains the summarized information from the entire input sequence, encapsulating the sentence’s meaning.
Decoder Stage:
- The context vector generated by the encoder is passed to the decoder as the initial hidden state.
- The decoder, also composed of LSTM or GRU layers, generates the output sequence token by token.
- The decoder predicts the next token in the target sequence based on the context vector and previously generated tokens at each time step.
- The model utilizes an attention mechanism to focus on relevant parts of the input sequence while generating each token of the output sequence. This allows the model to effectively align words in the input and output sentences.
- The process continues until the decoder predicts an end-of-sequence token or reaches a maximum predefined length for the output sequence.
Checkout this article about the Attention Mechanism in Deep Learning
Output Stage:
- The model generates the target sequence token by token, producing the translated sentence “Comment vas-tu aujourd’hui ?” in French.
- Each token in the output sequence is predicted based on the information encoder-decoder’s context vector and the decoder’s internal state.
- The final output is a fluent and contextually accurate translation of the input sentence, demonstrating the Seq2Seq model’s ability to handle complex language tasks like machine translation.
Code
Here’s a simplified Python code example demonstrating how to implement a Seq2Seq model for English-to-French translation using PyTorch:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# Dumm” dataset
english_s”nt”nces = ["How are y”u today?", "What is your name?"]
french_sentences = ["Comment vas-tu aujourd'hui ?", "Quel est ton nom ?"]
# Tokenization
english_vocab = set(' '.join(english_sentences).split())
french_vocab = set(' '.join(french_sentences).split())
# Create word-to-index and index-to-word dictionaries
eng_word2index = {word: i for i, word in enumerate(english_vocab)}
eng_index2word = {i: word for word, i in eng_word2index.items()}
fre_word2index = {word: i for i, word in enumerate(french_vocab)}
fre_index2word = {i: word for word, i in fre_word2index.items()}
# Convert sentences to tensor sequences
def sentence_to_tensor(sentence, vocab):
tensor = [vocab[word] for word in sentence.split()]
return torch.tensor(tensor, dtype=torch.long)
def sentences_to_tensor(sentences, vocab):
return [sentence_to_tensor(sentence, vocab) for sentence in sentences]
# Prepare data tensors
input_tensors = sentences_to_tensor(english_sentences, eng_word2index)
target_tensors = sentences_to_tensor(french_sentences, fre_word2index)
# Define Seq2Seq model
class Seq2Seq(nn.Module):
def init(self, input_size, output_size, hidden_size):
super(Seq2Seq, self).__init__()
self.hidden_size = hidden_size
self.encoder = nn.LSTM(input_size, hidden_size)
self.decoder = nn.LSTM(output_size, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input_tensor, target_tensor):
encoder_output, encoder_hidden = self.encoder(input_tensor)
decoder_output, = self.decoder(targettensor, encoder_hidden)
output = self.fc(decoder_output)
return output
# Instantiate the model
input_size = len(english_vocab)
output_size = len(french_vocab)
hidden_size = 256
model = Seq2Seq(input_size, output_size, hidden_size)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training loop
epochs = 100
for epoch in range(epochs):
optimizer.zero_grad()
total_loss = 0
for input_tensor, target_tensor in zip(input_tensors, target_tensors):
output = model(input_tensor.unsqueeze(0).unsqueeze(0), target_tensor.unsqueeze(0).unsqueeze(0))
loss = criterion(output.squeeze(0), target_tensor)
total_loss += loss.item()
loss.backward()
optimizer.step()
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch + 1}/{epochs}], Loss: {total_loss / len(input_tensors):.4f}')
# Inference
def translate_sentence(sentence, model):
input_tensor = sentence_to_tensor(sentence, eng_word2index).unsqueeze(0).unsqueeze(0)
with torch.no_grad():
output = model(input_tensor, torch.zeros(1, 1, len(french_vocab)))
output_ids = output.argmax(-1).squeeze(0).numpy()
translation = ' '.join([fre_index2word[i] for i in output_ids])
return translation
# Test translation
test_sentence = "How are you today?"
translated_sentence = translate_print(f'English: {test_sentence}')nprint(f'French: {translated_sentence}')French: {translated_sentence}')
Conclusion
This tutorial has served as a comprehensive guide for Seq2Seq models. Encoder-decoder architectures power them, and recurrent neural networks like Long Short Term Memory (LSTM) and GRU have emerged as indispensable tools in natural language processing (NLP) and beyond. With optimized architectures, large datasets, and cutting-edge techniques, the potential of Seq2Seq models remains vast. Their versatility drives machine learning and artificial intelligence innovation, from language translation to code generation.
As researchers and practitioners continue to explore and refine these models, Seq2Seq remains at the forefront of advancements in deep learning, paving the way for more sophisticated and intelligent systems.
If you want to learn more about artificial intelligence, machine learning algorithms, Language models, and Python, follow Analytics Vidhya’s Blog.
Frequently Asked Questions
Q1. Which transformer architecture is best?
A. Determining the “best” transformer architecture depends on the task and dataset. Models like BERT, GPT, and T5 each excel in different areas. For instance, BERT is excellent for natural language understanding tasks, while GPT is renowned for text generation, and T5 offers a unified framework for various NLP tasks.
Q2. How does the attention mechanism improve seq2seq models?
A. The attention mechanism enhances Seq2Seq models by dynamically allowing the decoder to focus on relevant parts of the input sequence. Instead of compressing all input information into a single context vector, attention assigns different weights to different parts of the sequence, enabling the model to capture dependencies effectively and significantly improving accuracy.
Q3. How do Seq2Seq models handle variable-length input sequences?
A. Seq2Seq models handle variable-length input sequences using techniques like padding and masking. The padding ensures that all sequences in a batch have the same length, while masking prevents the model from attending to padding tokens. This allows the model to process sequences of varying lengths without losing important information.
Q4. Is ChatGPT seq2seq?
A. ChatGPT, like its predecessor GPT, is a transformer-based model, not a Seq2Seq model. While both architectures are used for natural language processing tasks, GPT generates text autoregressively, while Seq2Seq models typically perform tasks like translation and summarization by encoding and decoding sequences.
Q5. Is seq2seq supervised or unsupervised?
A. Seq2Seq models are typically supervised learning models. During training, they require input-output pairs, where the input sequence and corresponding output sequence are provided. The model learns to map input sequences to output sequences based on the training data, optimizing its parameters to minimize a predefined loss function.






Hi Prasoon Very well explained LSTM and Seq2Seq Congrats