Artificial intelligence models have significantly impacted human life, excelling in tasks like text generation and natural language processing but falling short in real-world action and interaction, highlighting the need for autonomous systems. AI agents, capable of reasoning and acting dynamically, address this gap by operating without human intervention. When combined with powerful language models, they unlock intelligent decision-making and action-taking. Traditional models like Long Context LLMs and Retrieval-Augmented Generation (RAG) enhance context and knowledge retrieval but remain static, lacking autonomous, goal-driven behavior. Agentic RAG bridges this gap, evolving to enable dynamic, goal-oriented actions, which we will explore further in this article.

Learning Objectives
- AI Model Evolution: Progressed from traditional LLMs to RAG and Agentic RAG, enhancing capabilities.
- LLM Limitations: Traditional LLMs handle text well but can’t perform autonomous actions.
- RAG Enhancement: RAG boosts LLMs by integrating external data for more accurate responses.
- Agentic RAG Advancement: Adds autonomous decision-making, enabling dynamic task execution.
- Self-Route Hybrid: Combines RAG and Long Context LLMs for balanced cost and performance.
- Optimal Usage: Selection depends on needs like cost-efficiency, context handling, and query complexity.
Table of contents
- Learning Objectives
- Evolution of Agentic RAG, So Far
- Key Differences and Considerations between RAG and AI Agents
- Architectural Difference Between Long Context LLMs, RAGs and Agentic RAG
- A Comparative Analysis of Long Context LLMs, RAG and Agentic RAG
- Self-Route: Fusion of RAG and Long Context LLM
- Frequently Asked Questions
Evolution of Agentic RAG, So Far
When large language models (LLMs) emerged, they revolutionized how people engaged with information. However, it was noted that relying on them to solve complex problems sometimes led to factual inaccuracies, as they depend entirely on their internal knowledge base. This led to the rise of the Retrieval-Augmented Generation (RAG).
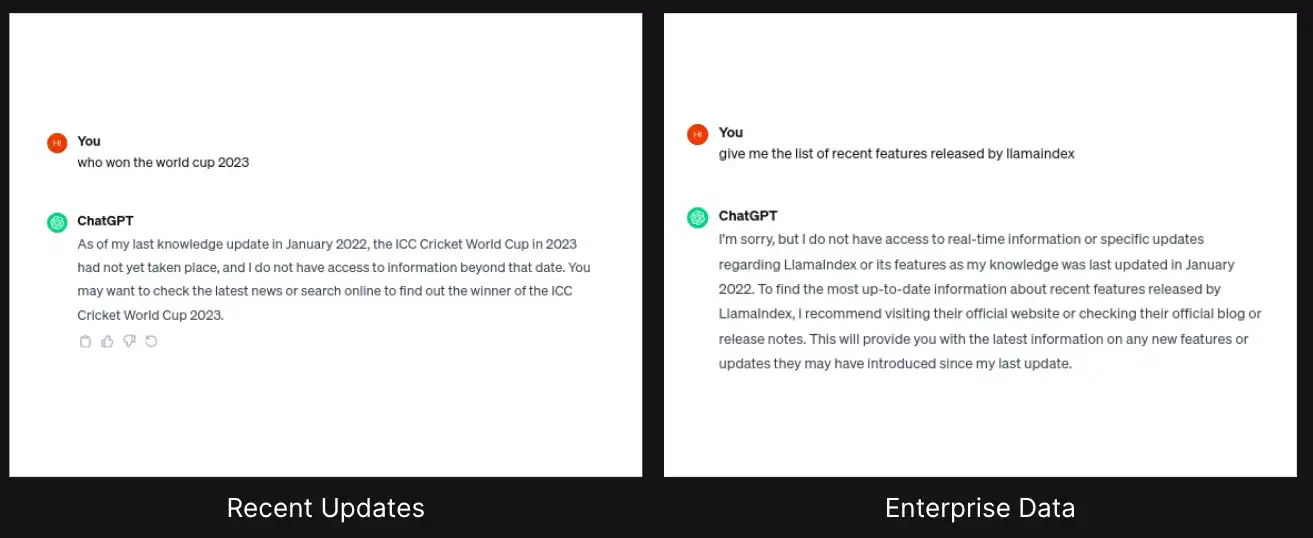
RAG is a technique or a methodology to augment the external knowledge into the LLMs.
We can directly connect the external knowledge base to LLMs, like chat GPT, and prompt the LLMs to fetch answers about the external knowledge base.
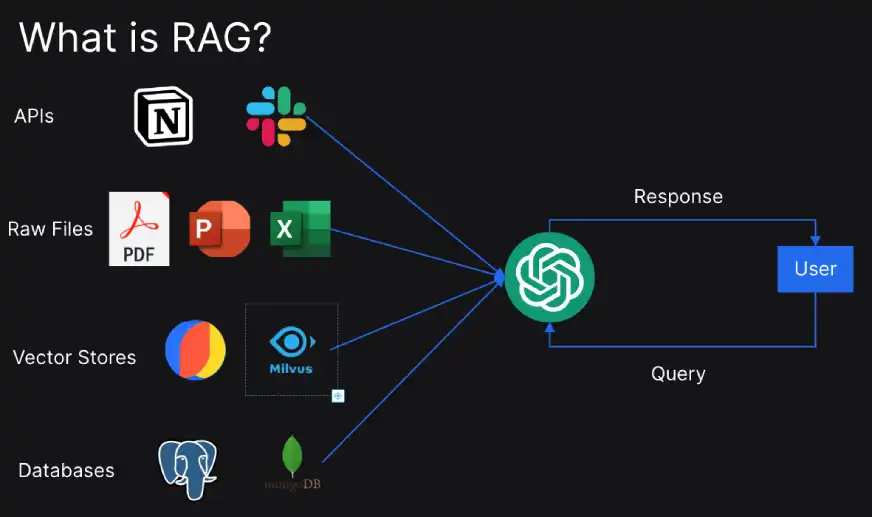
Let’s quickly understand how RAG works:
- Query Management: In the initial step, a query is processed to improve the search performance.
- Information Retrieval: Then comes the step where algorithms search the external data sources for relevant documents.
- Response Generation: In the final step, the front-end LLM utilizes information retrieved from the external database to craft accurate responses.
RAG excels at simple queries across a few documents, but it still lacks a layer of intelligence. The discovery of agentic RAG led to the development of a system that can act as an autonomous decision-maker, analyzing the initial retrieved information and strategically selecting the most effective tools for further response optimization.
Agentic RAG and Agentic AI are closely related terms that fall under the broader umbrella of Agentic Systems. Before we study Agentic RAG in detail, let’s look at the recent discoveries in the fields of LLM and RAG.
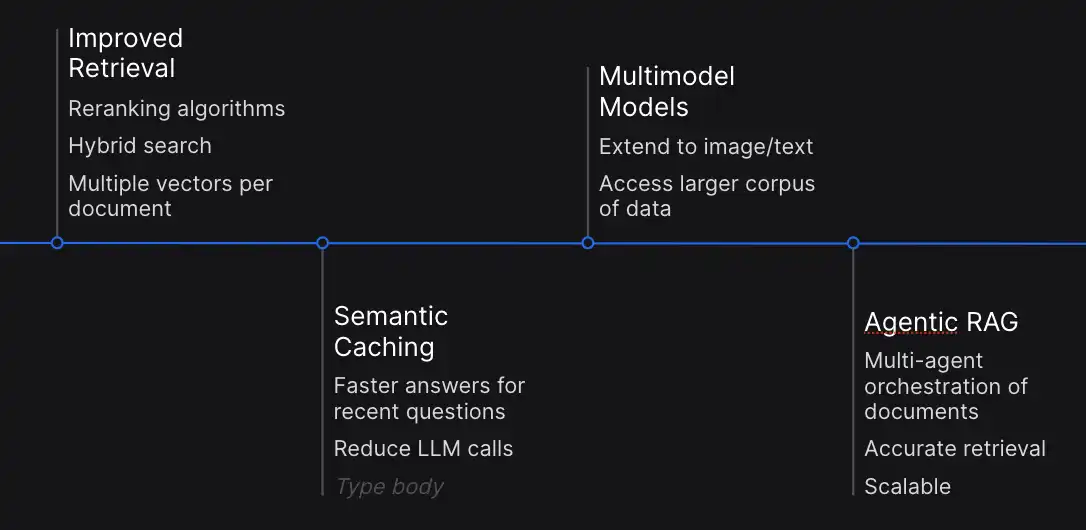
- Improved Retrieval: It is important to optimize retrieval for continuous performance. Recent developments focus on reranking algorithms and hybrid search methodologies, also employing multiple vectors per document to enhance relevance identification.
- Semantic Caching: Semantic caching has emerged as a key strategy to mitigate computational complexity. It allows storing answers to the recent queries which can be used to answer the similar requests without repeating.
- Multimodal Integration: This expands the capabilities of LLMs and RAG beyond text, integrating images and other modalities. This integration facilitates seamless integration between textual and visual data.
Key Differences and Considerations between RAG and AI Agents
So far, we have understood the basic differences between RAG and AI agents, but to understand it intricately, let’s take a closer look at some of the defining parameters.
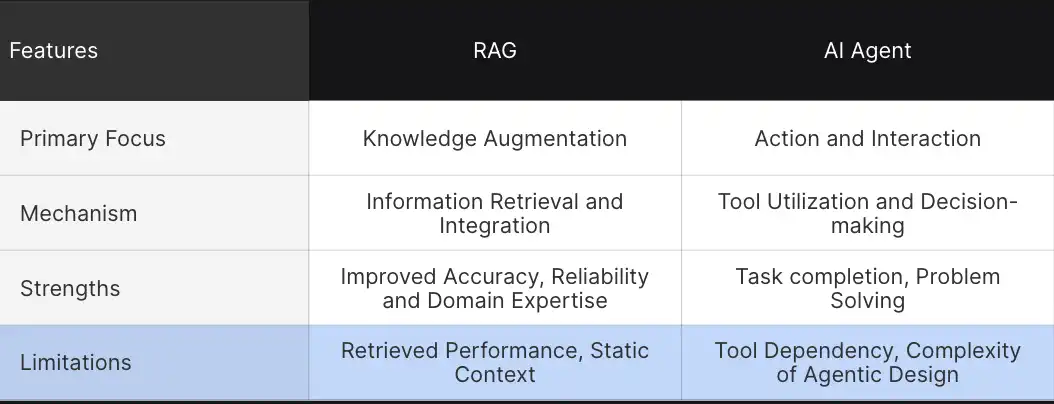
These comparisons help us understand how these advanced technologies differ in their approach to augmenting and performing tasks.
- Primary Focus: The primary goal of RAG systems is to augment knowledge, which consists of a model’s understanding by retrieving relevant information. This allows for more decision-making and improved contextual understanding. In contrast, AI agents are designed for actions and environmental interactions. Here, agents go a step ahead and interact with the tools and complete complex tasks.
- Mechanisms: RAG depends on information extraction and integration. It pulls data from external sources and integrates it into the responses, whereas AI agents function through tool utilization and autonomous decision-making.
- Strength: RAG’s strength lies in its ability to provide improved responses. By connecting LLM with external data, RAG prompts to provide more accurate and contextual information. Agents, on the other hand, are masters at task execution autonomously by interacting with the environment.
- Limitations: RAG systems face challenges like retrieval problems, static context, and a lack of autonomous intervention while generating responses. Despite countless strengths, agents’ major limitations include solely depending on tools and the complexity of agentic design patterns.
Architectural Difference Between Long Context LLMs, RAGs and Agentic RAG
So far, you have observed how integrating LLMs with the retrieval mechanisms has led to more advanced AI applications and how Agentic RAG (ARAG) is optimizing the interaction between the retrieval system and the generation model.
Now, backed by these learnings, let’s explore the architectural differences to understand how these technologies build upon each other.
| Feature | Long Context LLMs | RAG ( Retrieval Augmented Generation) | Agentic RAG |
| Core Components | Static knowledge base | LLM+ External data source | LLM+ Retrieval module + Autonomous Agent |
| Information Retrieval | No external retrieval | Queries external data sources during responses | Queries external databases and select appropriate tool |
| Interaction Capability | Limited to text generation | Retrieves and integrates context | Autonomous decisions to take actions |
| Use Cases | Text summarization, understanding | Augmented responses and contextual generation | Multi-tasking, end-to-end task generation |
Architectural Differences
- Long Context LLMs: Transformer-based models such as GPT -3 are usually trained on a large amount of data and rely on a static knowledge base. Their architecture is compatible for text generation and summarization, where they do not require external information to generate responses. However, they lack the susceptibility to provide updated or specialized knowledge. Our area of focus is the Long Context LLM models. These models are designed to handle and process much longer input tokens compared to traditional LLMs.
Models such as GPT-3 or earlier models are often limited to the number of input tokens. Long context models address such limitations by extending the context window size, making them better at:- Summarizing larger documents
- Maintaining coherence over long dialogues
- Processing documents with extensive context
- RAG (Retrieval Augmented Generation): RAG has emerged as a solution to overcome LLMs’ limitations. The retrieval component allows LLMs to be connected to external data sources, and the augmentation component allows RAG to provide more contextual information than a standard LLM. However, RAG still lacks autonomous decision-making capabilities.
- Agentic RAG: Next is Agentic RAG, which incorporates an additional intelligence layer. It can retrieve external information and includes an autonomous reasoning module that analyzes the retrieved information and implements strategic decisions.
These architectural distinctions help explain how each system allows knowledge, augmentation, and decision-making differently. Now comes the point where we need to determine the most suitable—LLMs, RAG, and Agentic RAG. To pick one, you need to consider specific requirements such as Cost, Performance, and Functionality. Let’s study them in greater detail below.
A Comparative Analysis of Long Context LLMs, RAG and Agentic RAG
- Long-context LLMs: There have always been efforts to enable LLMs to handle long contexts. While recent LLMs like Gemini 1.5, GPT 4, and Claude 3 achieve significantly larger context sizes, there is no or little change in cost related to long-context prompting.
- Retrieval-Augmented Generation: Augmenting LLMs with RAG achieved suboptimal performance compared to LC. However, its significantly lower computational cost makes it a viable solution. The graph shows that the cost difference between LLMs and RAG for the reference models is around 83%. Thus, RAGs can’t be made obsolete. So, there is a need for a technique that uses the fusion of these two to make the model fast and cost-effective simultaneously.
But, before we move onto understanding the new fusion technique, let’s first look at the result it has produced.
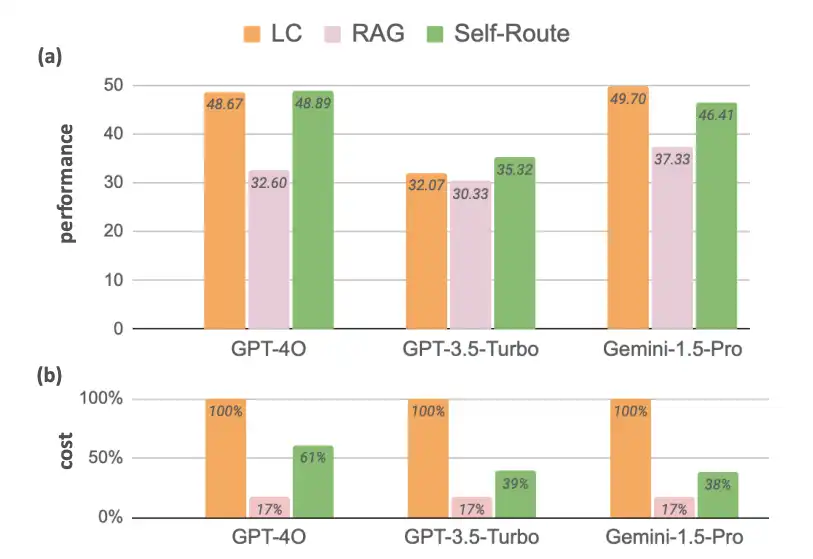
Self-Route: Self-Route is an Agentic Retrieval-Augmented Generation (RAG), designed to achieve a balanced trade-off between cost and performance. For queries that can be answered without routing, it uses fewer tokens, and only resorting to LC for more complex queries.
Now packed with this understanding, let’s move on to understand Self-Route.
Self-Route: Fusion of RAG and Long Context LLM

Self-Route is an Agentic AI design pattern that utilizes LLMs itself to route queries based on self-reflection, under the assumption that LLMs are well-calibrated in predicting whether a query is answerable given provided context.
- RAG-and-Route-Step: In the first step, users provide a query and the retrieved chunks to the LLM and ask it to predict whether the query is answerable and, if so, generate the answer. This is the same as Standard RAG, except that the LLM is given the option to decline answering the prompt.
- Long Context Prediction Step: For the queries that are deemed unanswerable, the second step is to provide the full context to the long context LLMs to obtain the final generated response.
Self-Route proves to be an effective strategy when performance and cost must be balanced. This makes it an ideal system for applications that require dealing with a diverse set of queries.
Key Takeaways
- When to Use RAG ( Retrieval Augmented Generation)?
- There is a need for lower computational costs.
- Query exceeds the model’s context window size, making RAG most efficiently.
- When to use Long Context LLMs (LC)?
- Handling long context is required.
- Sufficient resources are available to support higher computational cost.
- When to use Self-route?
- A balanced solution is required – some queries can be answered using RAG, and LC handles more complex one.
Conclusion
We have discussed the evolution of Agentic RAG, specifically comparing Long Context LLMs, Retrieval-Augmented Generation (RAG), and the more advanced Agentic RAG. While Long Context LLMs excel at maintaining context over extended dialogues or large documents, RAG improves upon this by integrating external knowledge retrieval to enhance contextual accuracy. However, both fall short in terms of autonomous action-taking.
With the evolution of agentic RAG, we have introduced a new intelligence layer by enabling decision-making and autonomous actions, bridging the gap between static information processing and dynamic task execution. The article also presents a hybrid approach called “Self-Route,” which combines the strengths of RAG and Long Context LLMs, balancing performance and cost by routing queries based on complexity.
Ultimately, the choice between these systems depends on specific needs, such as cost-efficiency, context size, and the complexity of queries, with Self-Route emerging as a balanced solution for diverse applications.
Also, to understand the Agent AI better, explore: The Agentic AI Pioneer Program
Frequently Asked Questions
Q1. What is Retrieval Augmented Generation (RAG)?
Ans. RAG is a methodology that connects a large language model (LLM) with an external knowledge base. It enhances the LLM’s ability to provide accurate responses by retrieving and integrating relevant external information into its answers.
Q2. How do Long-context LLMs differ from traditional LLMs?
Ans. Long Context LLMs are designed to handle much longer input tokens compared to traditional LLMs, allowing them to maintain coherence over extended text and summarize larger documents effectively.
Q3. What are AI Agents, and how do they differ from RAG?
Ans. AI Agents are autonomous systems that can make decisions and take actions based on processed information. Unlike RAG, which augments knowledge retrieval, AI Agents interact with their environment to complete tasks independently.
Q4. When should I use Long-context LLMs?
Ans. Long Context LLMs are best used when you need to handle extensive content, such as summarizing large documents or maintaining coherence over long conversations, and have sufficient resources for higher computational costs.
Q5. Why would I use RAG over Long-context LLMs?
Ans. RAG is more cost-efficient compared to Long Context LLMs, making it suitable for scenarios where computational cost is a concern and where additional contextual information is needed to answer queries.
Hi, I'm Sushant Thakur, an Instructional Designer. I'm actively involved in writing blogs and articles that explore the latest trends in Generative AI technologies and their real-world applications. Follow me for insights on how Gen AI is shaping industries and enhancing learning experiences.






